پردازش زبان طبیعی (Natural Language Processing) که به اختصار NLP نامیده میشود، شاخهای از علوم کامپیوتر و هوش مصنوعی (AI) است که با بهرهگیری از یادگیری ماشین (Machine Learning)، به کامپیوترها این توانایی را میدهد که زبان انسان را درک کرده و با آن تعامل برقرار کنند.
پردازش زبان طبیعی (NLP)، ترکیبی از زبانشناسی محاسباتی (مدلسازی قاعدهمند زبان انسان)، آمار، یادگیری ماشین و یادگیری عمیق است. این فناوری به کامپیوترها و دستگاههای دیجیتال توانایی میدهد تا متن و گفتار را تشخیص دهند و همچنین درک و تولید کنند.
پژوهشها در حوزه NLP، راه را برای شکوفایی هوش مصنوعی مولد (Generative AI) باز کردهاند. ما این تأثیر را هم در تواناییهای ارتباطی شگفتانگیز مدلهای زبانی بزرگ (LLMs) و هم در قابلیت درک دستورات متنی توسط مدلهای تولید تصویر، میبینیم.
امروزه، پردازش زبان طبیعی به بخشی جداییناپذیر از زندگی روزمره ما تبدیل شده است. این فناوری، قدرت اصلی پشت ابزارهایی است که هر روز استفاده میکنیم، از موتورهای جستجو گرفته تا چتباتهای خدمات مشتری و دستیارهای صوتی هوشمند مانند الکسای آمازون، سیری اپل و کورتانای مایکروسافت.
علاوه بر این، پردازش زبان طبیعی (NLP) نقش مهمی در راهکارهای سازمانی دارد. کسبوکارها از NLP برای بهینهسازی و خودکارسازی فرآیندها، افزایش بهرهوری کارکنان و سادهسازی عملیات خود استفاده میکنند.

مزایای پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی (NLP) به ما امکان میدهد با زبان روزمره خود با ماشینها تعامل کنیم، که این موضوع ارتباط و همکاری انسان و کامپیوتر را بسیار سادهتر کرده است. این فناوری قدرتمند، مزایای بیشماری در صنایع و کاربردهای گوناگون دارد. مهمترین این مزایا عبارتند از:
- خودکارسازی وظایف تکراری
- بهبود تحلیل دادهها و استخراج بینشهای کلیدی
- تجربه جستجوی پیشرفته و هوشمند
- تولید محتوای خودکار
خودکارسازی وظایف تکراری
پردازش زبان طبیعی (NLP) به ویژه در خودکارسازی کامل یا جزئی وظایفی مانند پشتیبانی مشتری، ورود دادهها و مدیریت اسناد، کاربرد فراوانی دارد.
برای مثال، چتباتهای مبتنی بر NLP میتوانند پرسشهای متداول مشتریان را مدیریت کنند، در نتیجه اپراتورهای انسانی برای رسیدگی به مسائل پیچیدهتر آزاد میشوند. در حوزه پردازش اسناد، ابزارهای NLP میتوانند بهطور خودکار محتوا را دستهبندی کنند، اطلاعات کلیدی را استخراج نمایند و متن را خلاصه کنند. این فرآیند، زمان و خطاهای ناشی از ورود دستی اطلاعات را کاهش میدهد.
همچنین، پردازش زبان طبیعی فرآیند ترجمه ماشینی را آسانتر میکند و متن را با حفظ معنا، مفهوم زمینه (Context) و نکات ظریف زبانی از یک زبان به زبان دیگر برمیگرداند.
بهبود تحلیل دادهها
پردازش زبان طبیعی (NLP) با استخراج دانش از دادههای متنی بدون ساختار (Unstructured Text Data) مانند نظرات مشتریان، پستهای شبکههای اجتماعی و مقالات خبری، تحلیل داده را متحول میکند.
این فناوری با استفاده از تکنیکهای متنکاوی (Text Mining)، میتواند الگوها، روندها و احساساتی را شناسایی کند که تشخیص آنها در مجموعه دادههای بزرگ دشوار است. برای نمونه، تحلیل احساسات (Sentiment Analysis) ویژگیهای ذهنی مانند نگرش، عاطفه، کنایه یا سردرگمی را از متن استخراج میکند.
این توانایی به کسبوکارها کمک میکند تا ترجیحات مشتریان، شرایط بازار و افکار عمومی را بهتر درک کنند. ابزارهای NLP همچنین میتوانند حجم عظیمی از متن را دستهبندی و خلاصهسازی کنند. این کار، شناسایی اطلاعات کلیدی و تصمیمگیری دادهمحور را برای تحلیلگران بسیار آسانتر و کارآمدتر میسازد.
جستجوی پیشرفته
پردازش زبان طبیعی (NLP) با درک قصد و نیت کاربر از عبارات جستجو شده، عملکرد سیستمهای جستجو را بهبود میبخشد و نتایجی دقیقتر و مرتبطتر ارائه میدهد.
موتورهای جستجوی مبتنی بر NLP، به جای تکیه صرف بر تطبیق کلمات کلیدی (keyword matching)، معنای کلمات و عبارات را تحلیل میکنند؛ این ویژگی، یافتن اطلاعات را حتی زمانی که جستجوها، مبهم یا پیچیده باشند، آسانتر میسازد. این رویکرد تجربه کاربری را چه در جستجوهای وب، چه در بازیابی اسناد یا سیستمهای داده سازمانی، به شکل قابل توجهی ارتقا میدهد.
تولید محتوای قدرتمند
پردازش زبان طبیعی (NLP) به مدلهای زبان پیشرفته قدرت میدهد تا برای اهداف مختلف، متنی شبیه به نوشته انسان (human-like) تولید کنند.
مدلهای از پیش آموزشدیده (Pre-trained Models)، مانند GPT-4، میتوانند بر اساس دستورات (Prompts) کاربر، مقاله، گزارش، متن تبلیغاتی، توضیحات محصول و حتی نوشتههای خلاقانه بنویسند. ابزارهای مبتنی بر NLP همچنین به خودکارسازی وظایفی مانند نوشتن پیشنویس ایمیل، تهیه پستهای شبکههای اجتماعی یا اسناد حقوقی کمک میکنند.
NLP با درک عمیق مفهوم زمینه (Context)، لحن (Tone) و سبک (Style)، تضمین میکند که محتوای تولید شده منسجم، مرتبط و همراستا با پیام مورد نظر باشد. به این ترتیب، ضمن حفظ کیفیت، در زمان و انرژی لازم برای تولید محتوا صرفهجویی میشود.
اگر قصد دارید دانش خود را در زمینه پردازش زبان طبیعی به سطح حرفهای برسانید، پیشنهاد میکنیم در دوره پردازش زبان طبیعی (NLP) و LLM دیتایاد شرکت کنید تا با جدیدترین مدلهای زبانی آشنا شوید.
رویکردهای پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی (NLP) قدرت زبانشناسی محاسباتی (Computational Linguistics) را با الگوریتمهای یادگیری ماشین و یادگیری عمیق (Deep Learning) ترکیب میکند. زبانشناسی محاسباتی از علم داده (Data Science) برای تحلیل زبان و گفتار بهره میبرد و شامل دو نوع تحلیل اصلی است: تحلیل نحوی (Syntactical Analysis) و تحلیل معنایی (Semantical Analysis).
تحلیل نحوی (Syntactical Analysis)
این رویکرد ساختار دستوری (Syntax) جمله را بررسی میکند. تحلیل نحوی با اعمال قواعد گرامری، ارتباط کلمات در یک عبارت را مشخص کرده و اطمینان میدهد که ساختار جمله صحیح است.
تحلیل معنایی (Semantical Analysis)
این تحلیل از خروجی تحلیل نحوی استفاده میکند تا معنای واقعی کلمات را استخراج کند. هدف تحلیل معنایی، درک مقصود و مفهوم نهفته در متن و تفسیر آن در چارچوب ساختار جمله است.
این تحلیلها از طریق فرآیندی به نام تجزیه (Parsing) انجام میشوند که دو شکل اصلی دارد:
- تجزیه وابستگی (Dependency Parsing): این روش به روابط میان کلمات نگاه میکند؛ برای مثال، اسمها و فعلها را شناسایی کرده و ارتباط آنها با یکدیگر را مشخص میکند.
- تجزیه ساختاری (Constituency Parsing): این روش یک درخت تجزیه (Parse Tree) یا درخت نحوی (Syntax Tree) میسازد. این درخت، نمایشی منظم از ساختار دستوری (Syntactic Structure) یک جمله است.
درختهای تجزیه، اساس کار مترجمهای ماشینی و سیستمهای تشخیص گفتار هستند. در حالت ایدهآل، این تحلیلها باعث میشوند خروجی نهایی (چه متن و چه گفتار) هم برای مدلهای NLP و هم برای انسانها قابل فهم باشد.
اهمیت یادگیری خودنظارتی
در این میان، یادگیری خودنظارتی (Self-Supervised Learning) برای NLP بسیار مفید است. به این دلیل که پردازش زبان طبیعی برای آموزش مدلهای هوش مصنوعی، به حجم عظیمی از دادههای برچسبگذاریشده (Labeled Data) نیاز دارد.
از آنجایی که این مجموعهدادهها نیازمند فرآیند زمانبر برچسبزنی (Annotation) دستی توسط انسان هستند، جمعآوری دادههای کافی میتواند بسیار دشوار و پرهزینه باشد. رویکردهای خودنظارتی از نظر زمانی و هزینه بسیار مقرونبهصرفهتر هستند، زیرا جایگزین بخشی یا تمام دادههای آموزشیِ برچسبگذاریشده به روش دستی میشوند.
سه رویکرد متفاوت در پردازش زبان طبیعی عبارتند از:
پردازش زبان طبیعی قاعدهمند (Rules-based NLP)
نخستین کاربردهای پردازش زبان طبیعی، سیستمهایی قاعدهمند بودند. این رویکرد بر اساس مجموعهای از قواعد ساده «اگر-آنگاه» (if-then) کار میکرد که مستقیماً توسط انسان برنامهریزی میشدند.
این سیستمها تنها میتوانستند به دستورات (Prompts) بسیار مشخصی پاسخ دهند. نمونهای از آن، نسخه اولیه Moviefone بود که از قابلیتهای ابتدایی تولید زبان طبیعی (NLG) استفاده میکرد. از آنجایی که در NLP قاعدهمند هیچ خبری از یادگیری ماشین یا هوش مصنوعی نبود، عملکرد این رویکرد بسیار محدود بود و قابلیت مقیاسپذیری نداشت.
پردازش زبان طبیعی آماری (Statistical NLP)
پردازش زبان طبیعی آماری گام بعدی در این حوزه بود. این رویکرد بهجای قواعد ثابت، از مدلهای آماری و یادگیری ماشین استفاده میکند.
مدلهای آماری بهطور خودکار عناصر دادههای متنی و صوتی را استخراج، دستهبندی و برچسبگذاری میکنند، سپس به هر معنای ممکن برای آن عناصر، یک احتمال آماری اختصاص میدهند. این رویکرد امکان تحلیلهای زبانشناختی پیچیدهتری مانند برچسبگذاری اجزای کلام (Part-of-Speech Tagging) را فراهم کرد.
NLP آماری، تکنیک حیاتی «نمایش برداری» (Vector Representation) را معرفی کرد. در این روش، عناصر زبان (مانند کلمات) به بردارها (اعداد) تبدیل میشوند تا بتوان زبان را با روشهای ریاضی و آماری (مانند رگرسیون یا مدلهای مارکوف) مدلسازی کرد. این رویکرد، زیربنای توسعه ابزارهای اولیهای مانند غلطیابهای املایی و سیستم پیامرسان T9 (مخفف Text on 9 keys) در تلفنهای دکمهای بود.
پردازش زبان طبیعی مبتنی بر یادگیری عمیق (Deep Learning NLP)
مدلهای یادگیری عمیق، امروزه استاندارد اصلی در حوزه پردازش زبان طبیعی (NLP) هستند. این مدلها توانایی پردازش حجم عظیمی از دادههای بدون ساختار را دارند و به دقتی روزافزون دست یافتهاند.
میتوان یادگیری عمیق را نسخه تکاملیافته NLP آماری در نظر گرفت، با این تفاوت کلیدی که از مدلهای مبتنی بر شبکههای عصبی (Neural Networks) بهره میبرد. این رویکرد خود شامل چندین زیرشاخه از مدلها میشود:
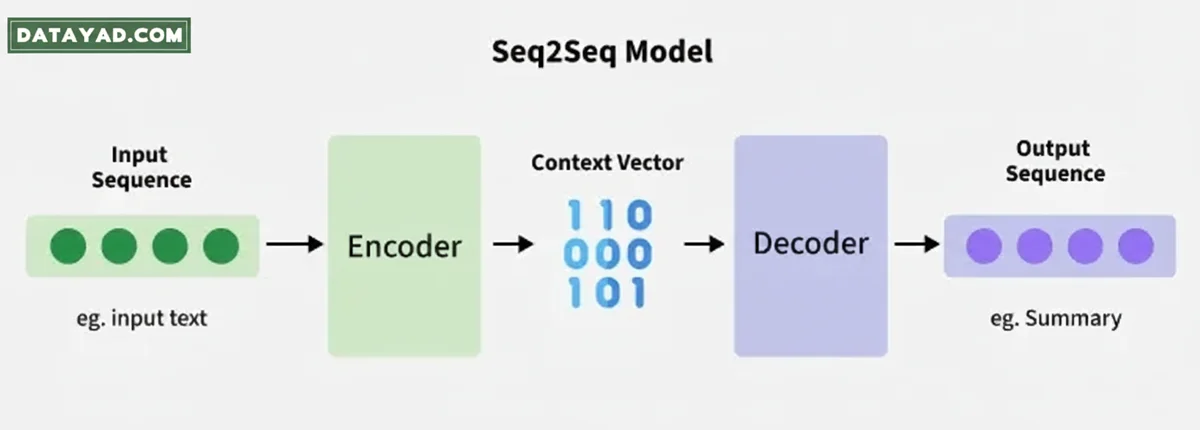
مدلهای توالی به توالی (Sequence-to-Sequence یا seq2seq):
ین مدلها بر پایه شبکههای عصبی بازگشتی (RNN) ساخته شدهاند و عمدتاً در حوزه ترجمه ماشینی کاربرد دارند. روش کار آنها به این صورت است که یک عبارت را از یک دنباله (مثلاً زبان آلمانی) دریافت کرده و آن را به عبارتی معادل در دنبالهای دیگر (مانند زبان انگلیسی) تبدیل میکنند.
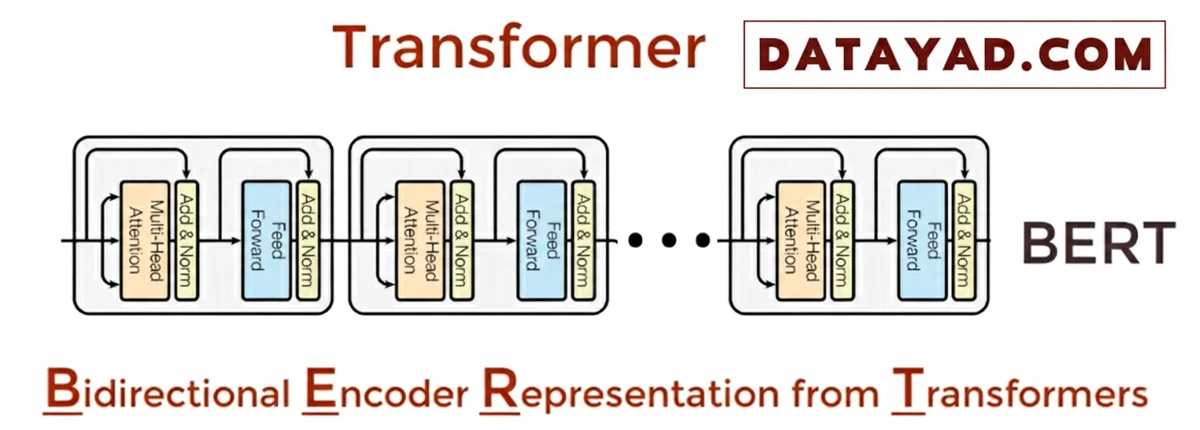
مدلهای ترنسفورمر (Transformer Models):
این مدلها از توکنسازی (Tokenization) (یعنی در نظر گرفتن موقعیت هر توکن، که میتواند کلمه یا بخشی از آن باشد) و مکانیزم Self-Attention استفاده میکنند. مکانیزم Self-Attention وابستگیها و روابط بین بخشهای مختلف زبان را درک میکند.
مدل های ترنسفورمر را میتوان با بهرهگیری از یادگیری خودنظارتی بر روی پایگاهدادههای متنی عظیم، به شکلی بسیار کارآمد آموزش داد. یک نقطه عطف در تاریخ این مدلها، مدل BERT گوگل بود که به اساس و پایه نحوه عملکرد موتور جستجوی گوگل تبدیل شد و همچنان نیز باقی است.
مدلهای مدل خود همبسته (Autoregressive):
این نوع از مدلهای ترنسفورمر به طور خاص برای پیشبینی کلمهی بعدی در یک توالی آموزش دیدهاند؛ قابلیتی که یک جهش عظیم رو به جلو در توانایی تولید متن محسوب میشود.
نمونههایی از مدلهای زبان بزرگ Autoregressive عبارتند از: GPT، لاما (Llama)، کلاد (Claude) و مدل open-source میسترال (Mistral).
مدلهای بنیادی (Foundation Models):
این مدلها، ساختارهایی از پیشآموزشدیده و بهینهسازیشده هستند که میتوانند راهاندازی پروژههای NLP را تسریع کنند و عملکرد قابل اعتمادتری ارائه دهند
علاوه بر این، آنها Retrieval-Augmented Generation (RAG) را امکانپذیر میسازند. RAG چارچوبی است که با اتصال مدل به منابع دانش خارجی، کیفیت پاسخها را به طور چشمگیری بهبود میبخشد. این مدلها همچنین قابلیت تشخیص اسامی خاص (Named Entity Recognition – NER) را دارند، که به معنای شناسایی و استخراج اطلاعات کلیدی (مانند نام افراد، سازمانها یا مکانها) از یک متن است.
انواع کار هایی که در پردازش زبان طبیعی میتوان انجام داد
در قلب پردازش زبان طبیعی (NLP)، طیف گستردهای از وظایف (Tasks) قرار دارند که کامپیوترها را قادر میسازند تا زبان انسان را تحلیل، درک و تولید کنند. این وظایف، زیربنای اصلی پروژههای هوش مصنوعی و یادگیری ماشین هستند.
اگر میپرسید NLP چه کارهایی انجام میدهد؟ در اینجا مهمترین وظایف پردازش زبان طبیعی را بر اساس سطح تحلیل بررسی میکنیم:
وظایف بنیادی: درک لغات و ساختار زبان
این دسته از وظایف پردازش زبان طبیعی بر روی تجزیه و تحلیل ساختاری و لغوی جملات متمرکز هستند:
- تشخیص اسامی خاص (Named Entity Recognition – NER): این وظیفه کلیدی در پردازش زبان طبیعی، عباراتی که به موجودیتهای نامگذاری شده اشاره دارند (مانند نام افراد، شرکتها، مکانها و تاریخها) را شناسایی و دستهبندی میکند. NER برای استخراج دادههای مهم از حجم انبوه متون، حیاتی است.
- برچسبگذاری اجزای گفتار (Part-of-Speech Tagging – POS Tagging): هدف این فرآیند، تعیین نقش دستوری هر کلمه در جمله است (اسم، فعل، صفت، قید). POS Tagging گامی اساسی برای هر نوع تحلیل متن پیشرفته است، زیرا درک میکند که کلمه چگونه در ساختار نحوی جمله عمل میکند.
وظایف معنایی: رمزگشایی مفهوم و نیت کاربر
این بخش از کاربردهای پردازش زبان طبیعی به عمق معنایی متن میپردازد و قصد نویسنده را درک میکند:
- تحلیل احساسات (Sentiment Analysis): شاید پرکاربردترین وظیفه پردازش زبان طبیعی در حوزه تجارت باشد. هدف آن، تعیین لحن و دیدگاه نهفته در متن (مثبت، منفی یا خنثی) است. از بررسی نظرات مشتریان تا تحلیل ترندهای بازار، تحلیل احساسات نقش حیاتی ایفا میکند.
- ابهامزدایی مفهوم کلمه (Word Sense Disambiguation – WSD): این فرآیند برای کلماتی که چندین معنی دارند، معنای صحیح را بر اساس زمینه متن انتخاب میکند. این کار به سیستمهای پردازش زبان طبیعی کمک میکند تا تفاوت ظریف معنایی کلمات همنویسه را درک کنند.
- مرجعگزینی/حل و فصل مرجع (Coreference Resolution): این وظیفه حیاتی، تشخیص میدهد که آیا دو یا چند عبارت متنی (مانند ضمیر و اسم) به یک موجودیت واحد اشاره دارند یا خیر. این کار برای ترجمه دقیق و خلاصهسازی هوشمند متون بلند ضروری است.
وظایف پیشرفته و کاربردی
این وظایف پیشرفته، معمولاً خروجی نهایی سیستمهای هوش مصنوعی مبتنی بر NLP هستند:
- خلاصهسازی متن (Text Summarization): وظیفه تولید یک نسخه کوتاه و جامع از یک سند طولانی است. این فرآیند به دو شکل استخراجی (انتخاب مهمترین جملات) و انتزاعی (ایجاد جملات جدید با درک محتوا) انجام میشود.
- ترجمه ماشینی (Machine Translation – MT): تبدیل خودکار متن از یک زبان به زبان دیگر با حفظ حداکثری معنا. پیشرفتهای اخیر در مدلهای یادگیری ماشین (مانند ترنسفورمرها)، دقت این فرآیند را به شکل چشمگیری افزایش داده است.
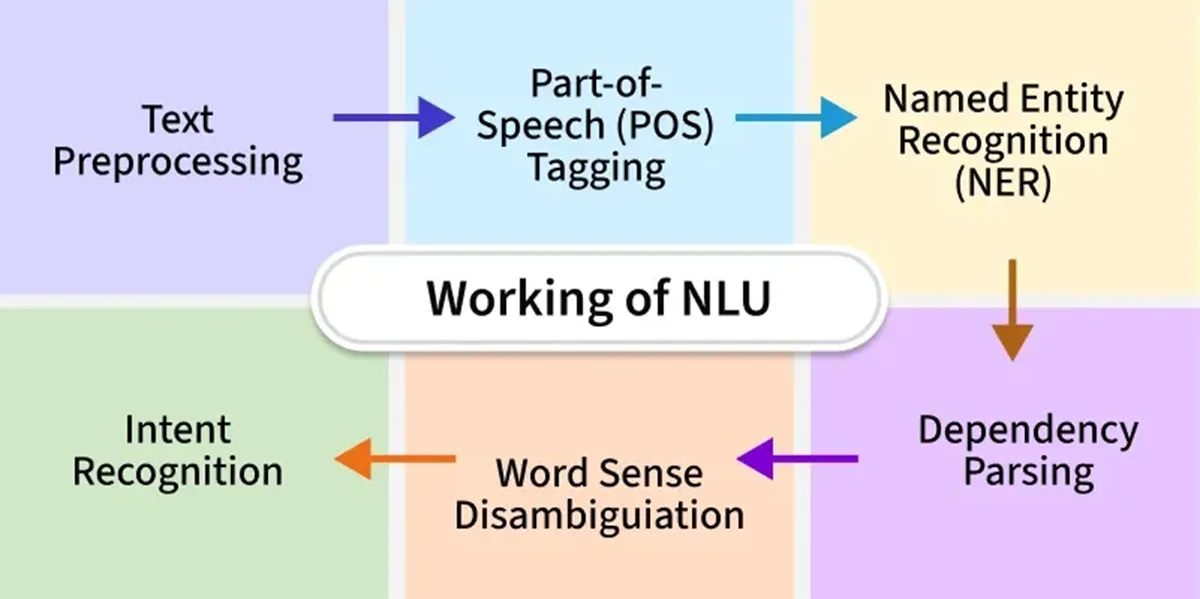
نحوه عملکرد پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) با ترکیب تکنیکهای محاسباتی مختلف، زبان انسان را به شیوهای قابل پردازش برای ماشینها تحلیل، درک و تولید میکند.
در ادامه، یک نمای کلی از یک پایپلاین (pipeline) معمول در پردازش زبان طبیعی و مراحل آن ارائه میشود:
پیشپردازش متن (Text Preprocessing)
پیشپردازش متن در NLP، با تبدیل متن خام به فرمتی که برای ماشینها قابل فهمتر باشد، آن را برای تحلیل آماده میکند. این فرآیند شامل مراحل زیر است:
- توکنسازی (Tokenization): در این مرحله، متن به واحدهای کوچکتری مانند کلمات، جملات یا عبارات شکسته میشود. این کار به تجزیه متنهای پیچیده به بخشهای قابل مدیریت کمک میکند.
- یکسانسازی حروف (Lowercasing): این گام با تبدیل تمام حروف به یک حالت یکسان (مثلاً حروف کوچک در انگلیسی)، متن را استاندارد میکند تا کلماتی مانند “Apple” و “apple” یکسان در نظر گرفته شوند.
- حذف کلمات توقف (Stop Word Removal): در این مرحله، کلمات پرتکراری که معنای قابل توجهی به متن اضافه نمیکنند (مانند «است»، «را»، «در» و «به») فیلتر و حذف میشوند.
- یافتن ریشه کلمات (Stemming & Lemmatization): این روشها کلمات را به شکل ریشه یا پایه خود کاهش میدهند (برای مثال، «میروم» به «رو» تبدیل میشود). این کار با گروهبندی اشکال مختلف یک کلمه، تحلیل زبان را آسانتر میسازد.
- پاکسازی متن (Text Cleaning): در این مرحله، عناصر ناخواستهای مانند علائم نگارشی، کاراکترهای خاص و اعدادی که ممکن است تحلیل را مختل کنند، حذف میشوند.
پس از اتمام این مراحل، متن پاک، استاندارد و آماده است تا توسط مدلهای یادگیری ماشین به طور مؤثری تفسیر شود.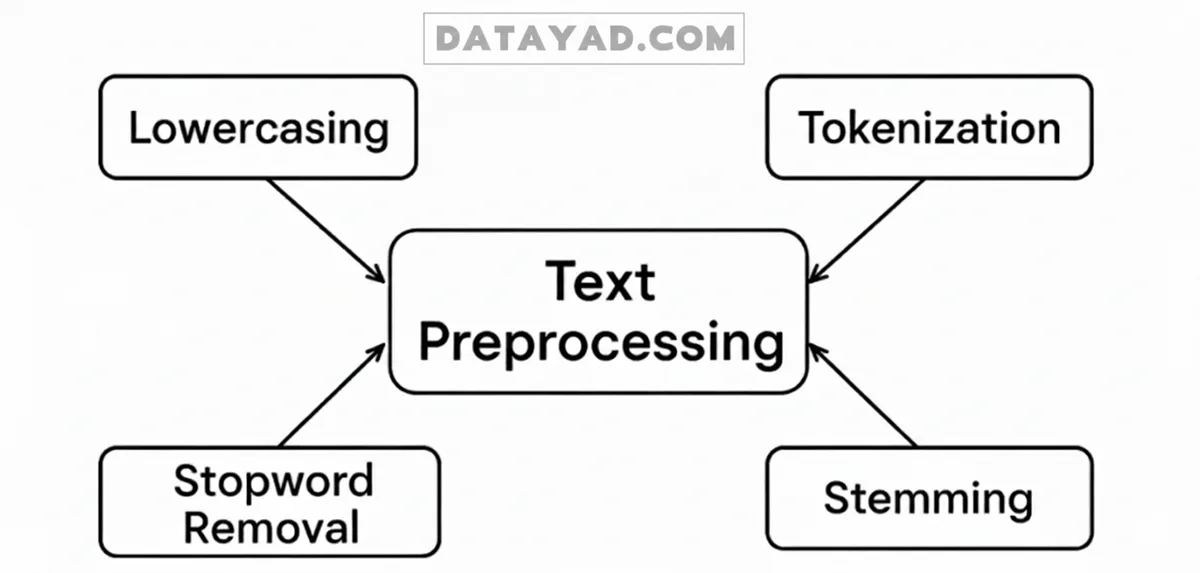
استخراج ویژگی (Feature Extraction)
استخراج ویژگی، فرآیند تبدیل متن پاکشده به نمایشهای عددی (بردار) است که ماشینها بتوانند آنها را تحلیل و تفسیر کنند. این کار شامل تبدیل متن به دادههای ساختاریافته است.
- تکنیکهای کلاسیک NLP مانند Bag of Words (BoW) و TF-IDF، حضور و اهمیت کلمات در یک سند را به صورت کمی اندازهگیری میکنند.
- روشهای پیشرفتهتر شامل جاسازی کلمات (Word Embeddings) مانند Word2Vec یا GloVe هستند. این روشها کلمات را به صورت بردارهای متراکم (Dense Vectors) نمایش میدهند و روابط معنایی بین کلمات را ثبت میکنند.
- در نهایت، (Contextual Embeddings) (مانند BERT) با در نظر گرفتن زمینهای که کلمات در آن ظاهر میشوند، این فرآیند را یک گام فراتر برده و نمایشهایی غنیتر و دقیقتر ایجاد میکنند.
تحلیل متن (Text Analysis)
تحلیل متن، فرآیند تفسیر و استخراج اطلاعات معنادار از دادههای متنی با استفاده از تکنیکهای محاسباتی مختلف است. این فرآیند شامل وظایف زیر میشود:
- برچسبگذاری اجزای کلام (POS Tagging): شناسایی نقش دستوری کلمات در جمله.
- تشخیص اسامی خاص (NER): تشخیص موجودیتهای مشخصی مانند اسامی افراد، مکانها و تاریخها.
- تجزیه وابستگی (Dependency Parsing): تحلیل روابط دستوری بین کلمات برای درک ساختار جمله.
- تحلیل احساسات (Sentiment Analysis): تعیین لحن عاطفی متن و ارزیابی اینکه آیا مثبت، منفی یا خنثی است.
- مدلسازی موضوع (Topic Modeling): شناسایی مضامین یا موضوعات اصلی در یک متن یا در مجموعهای از اسناد (corpus).
درک زبان طبیعی (Natural Language Understanding – NLU) زیرشاخهای از NLP است که بر تحلیل معنای نهفته در جملات تمرکز دارد. NLU نرمافزار را قادر میسازد تا معانی مشابه را در جملات مختلف پیدا کرده یا کلماتی با معانی متفاوت را پردازش کند.
از طریق این تکنیکها، تحلیل متن در NLP، دادههای متنی بدون ساختار را به بینشهای ارزشمند تبدیل میکند.
آموزش مدل
سپس، دادههای پردازششده برای آموزش مدلهای یادگیری ماشین به کار میروند. این مدلها الگوها و روابط درون دادهها را یاد میگیرند. در طول فرآیند آموزش، مدل پارامترهای خود را به منظور به حداقل رساندن خطا و بهبود عملکرد، تنظیم میکند. پس از آموزش، مدل میتواند برای پیشبینی یا تولید خروجی بر روی دادههای جدید و دیدهنشده مورد استفاده قرار گیرد. اثربخشی مدلسازی NLP به طور مداوم از طریق ارزیابی (evaluation)، اعتبارسنجی (validation) و تنظیم دقیق (fine-tuning) بهبود مییابد تا دقت و کارایی آن در کاربردهای دنیای واقعی افزایش یابد.
ابزارهای رایج در NLP
محیطهای نرمافزاری مختلفی در طول این فرآیندها مفید هستند. برای مثال:
- Natural Language Toolkit (NLTK): مجموعهای از کتابخانهها و برنامهها عمدتاً برای زبان انگلیسی است که با زبان پایتون (Python) نوشته شده است. این ابزار از قابلیتهایی مانند دستهبندی متن، توکنسازی، ریشهیابی و برچسبگذاری پشتیبانی میکند.
- TensorFlow و PyTorch: کتابخانههای نرمافزاری رایگان و متنباز (Open-Source) برای یادگیری ماشین هستند که برای آموزش مدلهای پیچیده یادگیری عمیق در کاربردهای NLP استفاده میشوند.
چالشهای پردازش زبان طبیعی (NLP)
حتی پیشرفتهترین مدلهای پردازش زبان طبیعی (NLP) نیز کامل نیستند، درست همانطور که گفتار انسان همیشه بدون خطا نیست. مانند هر فناوری هوش مصنوعی دیگری، پردازش زبان طبیعی با چالشها و نقاط ضعف بالقوهای همراه است.
زبان انسان سرشار از ابهام است. همین موضوع، نوشتن نرمافزاری که بتواند معنای دقیق دادههای متنی یا صوتی را تشخیص دهد، برای برنامهنویسان بسیار دشوار میکند. یادگیری زبان برای خود انسانها سالها زمان میبرد و این فرآیند یادگیری برای بسیاری هرگز متوقف نمیشود. با این حال، برنامهنویسان باید به اپلیکیشنهای مبتنی بر NLP بیاموزند که این بیقاعدگیها و پیچیدگیها را شناسایی و درک کنند تا بتوانند ابزارهایی دقیق و کاربردی ارائه دهند.
برخی از ریسکهای مرتبط با این حوزه عبارتند از:
سوگیری در دادههای آموزشی
همانند هر سیستم هوش مصنوعی، اگر دادههای آموزشی یک مدل حاوی سوگیری (Bias) باشند، نتایج و پاسخهای آن نیز جانبدارانه و نادرست خواهند بود. این خطر زمانی جدیتر میشود که کاربران یک سیستم پردازش زبان طبیعی، گروه متنوعی از افراد باشند، بهویژه در حوزههای حساسی مانند خدمات دولتی، مراقبتهای بهداشتی و منابع انسانی (HR). برای مثال، مجموعهدادههای آموزشی که از سطح وب جمعآوری میشوند، بهشدت در معرض انواع سوگیریها قرار دارند.
تفسیر نادرست
در این حوزه نیز، اصل «ورودی بیکیفیت، خروجی بیکیفیت» (Garbage In, Garbage Out) کاملاً صادق است. وظیفه تبدیل گفتار به متن (Speech-to-Text)، تبدیل قابل اعتماد دادههای صوتی به متن است. اما اگر ورودی گفتاری شامل مواردی مانند گویش ناآشنا، صحبت نامفهوم و زیر لب، اصطلاحات عامیانه (Slang)، کلمات همآوا، گرامر نادرست، جملات ناقص، تلفظ اشتباه یا نویز پسزمینه زیاد باشد، سیستمهای NLP ممکن است در درک آن دچار سردرگمی شوند.
پویایی و تکامل زبان
زبان یک پدیده پویا است. کلمات جدید پیوسته ساخته یا وارد زبان میشوند و قواعد دستوری نیز میتوانند به مرور زمان تکامل یابند یا عمداً نادیده گرفته شوند. در چنین مواردی، مدل NLP یا باید بهترین حدس خود را بزند یا اعتراف کند که نامطمئن است، که هر دو حالت یک چالش جدی محسوب میشود.
درک لحن و مفاهیم پنهان
هنگامی که انسانها صحبت میکنند، نحوه بیان کلمات (لحن) یا حتی زبان بدنشان میتواند معنایی کاملاً متفاوت از خودِ کلمات را منتقل کند. مواردی مانند اغراق برای تاثیرگذاری، تاکید بر روی کلمات برای نشان دادن اهمیت، یا کنایه و طعنه (sarcasm) میتوانند باعث سردرگمی مدلهای NLP شوند و تحلیل معنایی را دشوارتر و کماعتبارتر کنند.
کاربردهای پردازش زبان طبیعی بر اساس صنایع مختلف
امروزه کاربردهای پردازش زبان طبیعی تقریباً در هر صنعتی یافت میشوند.
صنعت مالی (Finance)
در معاملات مالی، گاهی ثانیهها میتوانند تفاوت بین موفقیت و شکست را رقم بزنند. پردازش زبان طبیعی (NLP) میتواند فرآیند استخراج اطلاعات از صورتهای مالی، گزارشهای سالانه و نظارتی، اخبار و حتی شبکههای اجتماعی را به شدت تسریع کند.
حوزه سلامت و پزشکی (Healthcare)
بینشها و دستاوردهای جدید پزشکی گاهی سریعتر از آن پدیدار میشوند که متخصصان بتوانند خود را با آنها بهروز نگه دارند. ابزارهای مبتنی بر پردازش زبان طبیعی و هوش مصنوعی میتوانند به تسریع تحلیل پروندههای سلامت (EHR) و مقالات تحقیقاتی پزشکی کمک کرده و امکان اتخاذ تصمیمات آگاهانهتر یا کمک به تشخیص و پیشگیری از بیماریها را فراهم آورند.
صنعت بیمه (Insurance)
NLP میتواند با تحلیل پروندههای خسارت (Claims)، الگوهایی را شناسایی کند که به کشف موارد نگرانکننده یا ناکارآمدیها در فرآیند رسیدگی به خسارت کمک میکنند. این امر منجر به بهینهسازی بیشتر فرآیندها و تلاشهای کارکنان میشود.
حوزه حقوقی (Legal)
تقریباً هر پرونده حقوقی نیازمند بررسی حجم عظیمی از اسناد، اطلاعات پیشینه و رویههای قضایی است. پردازش زبان طبیعی (NLP) میتواند به خودکارسازی فرآیند کشف اسناد حقوقی (e-Discovery) کمک کرده، سازماندهی اطلاعات را تسهیل نماید، بازبینی را سرعت بخشد و اطمینان حاصل کند که تمام جزئیات مرتبط برای بررسی، ثبت و ضبط شدهاند.
اکنون درک کاملی از پردازش زبان طبیعی دارید. برای تسلط بر پیادهسازی این مفاهیم و کار با جدیدترین مدلهای LLM و پردازش زبان طبیعی، دوره جامع LLM و NLP بهترین راهنما و مسیر عملی برای شماست.