

مدلهای زبانی بزرگ یا Large Language Models (LLM) یکی از مهمترین پیشرفتهای دنیای هوش مصنوعی (AI) و پردازش زبان طبیعی (NLP) به شمار میآیند. این مدلها با استفاده از شبکههای عصبی و مدلهای یادگیری عمیق و تحلیل حجم عظیمی از دادههای متنی، قادرند وظایف پیچیدهای مانند تولید متن، ترجمه ماشینی، خلاصهسازی محتوا، پاسخ به پرسشها و تغییر سبک نوشتار را انجام دهند.
به طور کلی، یک مدل زبانی بزرگ (LLM) میتواند با درک و پردازش زبان انسانی، تعامل موثری با کاربران برقرار کند. برخی از این مدلها تکزبانه هستند و برخی دیگر چندزبانه عمل میکنند و امکان پردازش همزمان چند زبان را فراهم میآورند. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر این مدلها میپردازیم.
ویژگیهای کلیدی LLMها:
- درک دقیق زبان طبیعی و تولید متن روان
- قابلیت پشتیبانی از زبانهای مختلف
- استفاده گسترده از معماری ترانسفورمرها (Transformers)
- توانایی یادگیری و سازگاری با دادههای جدید
- کاربرد در حوزههای متنوع از جستجوگرها تا چتباتها
چرا به این مدلها، مدلهای زبانی بزرگ میگوییم؟
شاید از خود بپرسید کلمه «بزرگ» در عبارت مدلهای زبانی بزرگ دقیقاً به چه معناست؟ آیا صرفاً به حجم کدنویسی آنها اشاره دارد؟ خیر! بزرگی این مدلها در دو فاکتور اصلی خلاصه میشود: تعداد پارامترها و حجم دادههای آموزشی.
برای درک بهتر، بیایید به اعداد نگاهی بیندازیم: مدل GPT-3 دارای ۱۷۵ میلیارد پارامتر است. برای آموزش چنین مدلی، از صدها ترابایت داده متنی (معادل کل کتابخانه دیجیتال جهان و بخش بزرگی از اینترنت) استفاده شده است. این مقیاس خیرهکننده به مدل اجازه میدهد تا نه تنها کلمات، بلکه ظرافتهای زبانی، طنز، منطق و حتی کدنویسی را فرابگیرد. در واقع، بزرگی این مدلها همان چیزی است که باعث میشود خروجی آنها به طرز عجیبی شبیه به نوشتههای انسانی باشد.

تاریخچه مدلهای زبانی بزرگ
اولین مدلهای پردازش زبان طبیعی در دهه 80 میلادی توسعه یافتند ولی تا سال 2010، خبری از LLM نبود! این مدلها در دهه اخیر اهمیت زیادی پیدا کردند و به یکی از مهمترین حوزههای تبلیغاتی تبدیل شدند. این مدلها میتوانند زبان انسان را به راحتی پردازش و درک نمایند. آنها از اطلاعات درک شده برای تولید یک خروجی خاص استفاده میکنند. ترجمه جملههای ماشینی، تولید متن، پاسخگویی به سوالات مختلف و تعاملات انسانی را میتوان به عنوان مهمترین حوزههای استفاده از این مدلها در نظر گرفت.
قبل از سال 2017، نسخههای زیادی از این مدلهای زبانی در بازار موجود نبودند. مدلهایی همچون IBM alignment models، n-gram model و web as corpus تنها مدلهای پردازش زبان طبیعی بزرگ در دنیا به حساب میآمدند. زمانی که شبکههای عصبی در حوزه پردازش تصویر به پیشرفت مطلوبی رسیدند، کارشناسان تصمیم گرفتند تا آنها را روی مدلهای زبانی هم پیاده سازی کنند. گوگل یکی از اولین شرکتهایی به حساب میآید که در این زمینه تحقیق انجام داد و در سال 2016 موفق شد تا مدل ترجمه خود را با استفاده از یک LLM پیاده سازی نماید. این یک نقطه عطف در تاریخ هوش مصنوعی بود.
اگر در مورد مفاهیم و تعاریف هوش مصنوعی به دنبال یک مقاله جامع و همه جانبه میگردید، مقاله هوش مصنوعی چیست؟ بهترین گزینه برای مطالعه شماست.
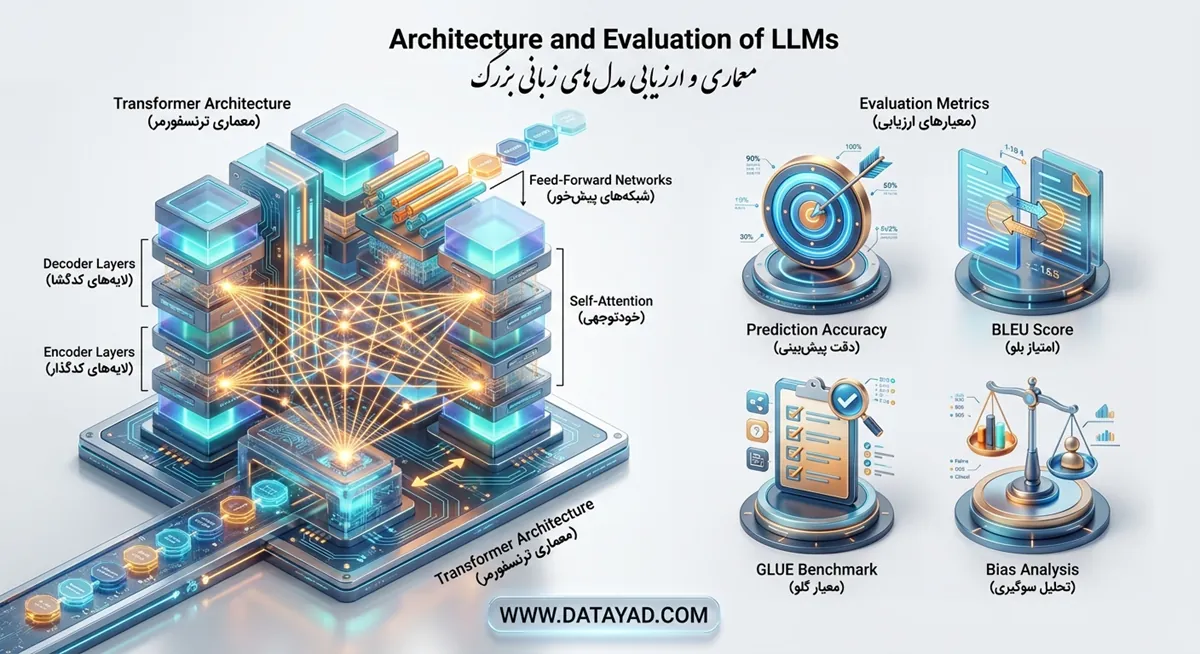
معماری LLM ها
مدلهای زبانی بزرگ معمولا بر پایه یک شبکه عصبی و یادگیری عمیق بنا میشوند. همانطور که گفته شد، تا قبل از رشد شبکههای عصبی خبری از مدلهای پردازش زبانی بزرگ نبود! ترنسفورمر (transformer) را میتوان به عنوان مهمترین ابزار به کار رفته برای طراحی و توسعه این مدلها معرفی نمود. مکانیزم Self Attention از جمله مهمترین مفاهیم مطرح شده در این معماری به حساب میآیند. این مفاهیم به مدل ما اجازه میدهند تا وابستگیهای طولانی مدت را در دادههای متنی کشف نماید.
از جمله مولفههای کلیدی موجود در شبکههای ترنسفورمر باید به مواردی همچون درک همزمان بخشهای مختلف یک جمله، پردازش غیرخطی دادهها و نرمال سازی اطلاعات اشاره نمود. این مولفهها توانستهاند روی سرعت و میزان بازدهی مدلهای پردازش زبان طبیعی تا حد قابل توجهی تاثیر گذار باشند.
درک این مراحل برای تحلیل عملکرد مدلهای زبانی ضروری است. با این حال، قدرت واقعی زمانی به دست میآید که بتوانید این مفاهیم را در عمل پیادهسازی کنید. دوره آموزش مدلهای زبانی بزرگ دیتایاد به شما این امکان را میدهد که از دانش تئوریک فراتر رفته و توانایی ساخت و استفاده از این مدلها را در دنیای واقعی کسب کنید.
نحوه ارزیابی مدل زبانی بزرگ
روند ارزیابی مدلهای NLP با مدلهای زبانی بزرگ یکسان نیست! برای ارزیابی مدلهای زبانی بزرگ ما باید به سراغ چندین معیار مختلف برویم. در لیست زیر، میتوانید چند مورد از این معیارهای کلیدی را مشاهده کنیم.
- دقت پیش بینی: مدل باید بتواند به درستی کلمات بعدی شما را پیش بینی نماید. ناتوانی مدل در انجام این کار نشان دهنده ضعف شدید آن میباشد.
- BLEU: این فاکتور برای ارزیابی کیفیت تولید متن در پروسههای مختلف در نظر گرفته میشود. فرآیندهای کلیدی و مهمی همچون خلاصه سازی و ترجمه از جمله مباحثی به حساب میآیند که شما باید آنها را در نظر داشته باشید.
- GLUE: این معیار، مجموعهای از آزمونهای مختلف را طراحی میکند. این آزمونها برای سنجش کیفیت درک زبان طبیعی مورد استفاده قرار میگیرند.
- Bias: یک مدل زبانی بزرگ باید نسبت به دادههای آموزشی بی طرف باشد و حساسیت زیادی روی آنها نشان ندهد. این فاکتور میزان بی طرفی مدل را به صورت دقیق مورد بررسی قرار میدهد.
البته که مدلهای زبانی بزرگ را میتوان با استفاده از تکنیکهای دیگری هم زیر سوال برد ولی مباحث موجود در این لیست از جمله سادهترین و سر راستترین تکنیکهای مطرح شده در این زمینه به حساب میآیند.
چگونه مدلهای زبانی بزرگ آموزش میبینند؟
تاکنون افراد زیادی از ما سوال پرسیدهاند که مدلهای زبانی بزرگ دقیقا چگونه آموزش میبینند؟ برای آموزش صحیح و اصولی این مدلها ما باید چه مراحلی را پشت سر بگذاریم؟ مدلهای LLM به گونهای طراحی شدهاند تا با استفاده از دادههای متنوعی آموزش ببینند. از جمله مطرحترین تکنیکهای یادگیری موجود در این زمینه باید به مواردی همچون یادگیری نظارت نشده، نیمه نظارت شده و یادگیری تقویتی اشاره نمود. البته، استفاده از یادگیری تقویتی در این پروسه کمی نادر است.
کارشناسان فرآیند را با جمع آوری اطلاعات شروع میکنند. آنها باید دیتای مورد نیاز برای آموزش یا Train مدلهای زبانی را به صورت کامل در اختیارش قرار دهند. پس از جمع آوری اطلاعات، نوبت به پردازش دادهها میرسد. منابع متنی زیادی هستند که میتوانند در این فرآیند به کار روند. کتابها، مقالات و وب سایتهای مختلف دائما در حال تولید محتوای متنی هستند.
زمانی که تمیز کردن اطلاعات به اتمام رسید، نوبت به پیش آموزش مدلهای زبانی بزرگ میرسد.در این شرایط، کارشناسان مدل را روی مجموعه دادههای بزرگ آموزش میدهند. آنها از تکنیکهایی همچون Self-Supervised Learning استفاده مینمایند. این تکنیک به مدل اجازه میدهد تا به صورت دقیق بر اساس منابع آموزش ببیند.
در سومین مرحله کارشناسان باید نسبت به تنظیم دقیق LLMها اقدام نمایند. مدل باید بتواند بهینه شود. مدلی که نتواند به سوالات پاسخ دهد یا در بهترین حالت ممکن ترجمه را انجام دهد، هیچ کاربردی ندارد! کارشناسان با استفاده از تکنیکهای Fine Tuning میتوانند مدل را برای حالات مختلف بهینه سازند.
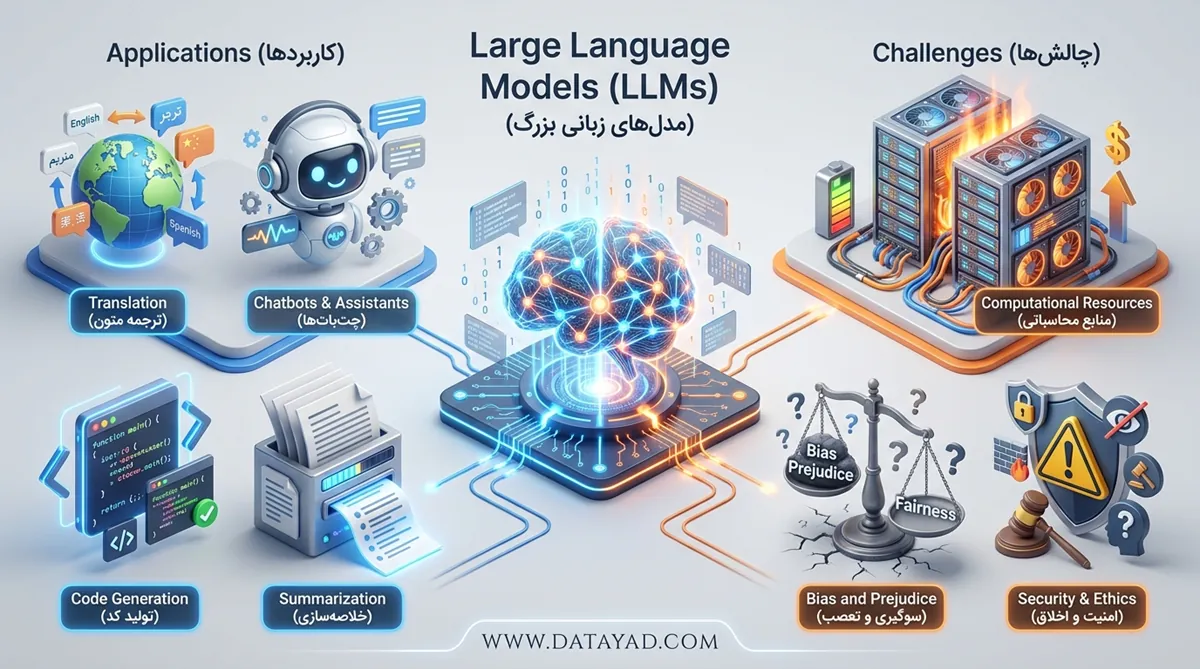
کاربردهای LLM ها در هوش مصنوعی
مدلهای زبانی بزرگ در دنیای هوش مصنوعی، کاربردهای گستردهای دارند. ما میتوانیم این مدلها را در موقعیتها و پروژههای زیادی مورد استفاده قرار دهیم. مثلا ترجمه متون مختلف یکی از همین کاربردهای کلیدی به حساب میآید. همه ما تا کنون حداقل یک بار از ابزارهایی همچون Google Translate استفاده کردهایم. این ابزار با استفاده از یک مدل زبانی بزرگ (LLM) توانسته به درک مطلوبی از فرهنگهای مختلف برسد.
جدا از این مسئله، چت باتها و دستیارهای مجازی هم از مدلهای زبانی بزرگ در پشت صحنه خود استفاده میکنند. شاید به نظر برسد که پردازش زبان طبیعی (NLP) تنها الگوریتم به کار رفته در طراحی چت باتهایی همچون ChatGPT یا Alexa باشد ولی در ساخت این ابزارها، ما میتوانیم الگوریتمهای زیادی را مشاهده کنیم.
از جمله دیگر کاربرد مدلهای زبانی بزرگ باید به مواردی همچون تولید کدهای برنامه نویسی، تحلیل احساسات و خلاصه سازی متون بزرگ اشاره نمود. تقریبا همه مدلهای هوش مصنوعی بزرگ که با پردازش زبان و متن سر و کار دارند، نسخههای مختلف این ابزار را به کار گرفتهاند.
چالشها و محدودیتهای مدل های زبانی بزرگ
با وجود پیشرفتهای گسترده در حوزه توسعه مدلهای زبانی بزرگ، این صنعت همچنان با چالشهای زیادی مواجه است. این چالشها توانستهاند محدودیتهای زیادی را سر راه مدلهای مطرح شده در این زمینه قرار دهند. به عنوان مثال، LLMها به منابع محاسباتی زیادی نیاز دارند. این مدلها به راحتی آموزش ندیده و برای دنبال کردن این پروسه شما باید سخت افزار مطلوبی را در اختیار داشته باشید.
جدا از این مسئله، گاهی اوقات سوگیری و تعصب در این مدلها ایجاد میشود. برخی از متون تولید شده توسط انسان، تعصبات قومی، نژادی و ملی را به همراه دارد. در صورتی که یک مدل زبانی بزرگ با استفاده از چنین متونی آموزش داده شود، با چالشهای گستردهای مواجه خواهد شد. طبیعتا بررسی دادههای آموزشی و تنظیم اصولی آنها اهمیت زیادی خواهد داشت.
دیگر چالشی که هنگام توسعه مدلهای زبانی بزرگ ما باید آنها را در نظر بگیریم که مشکلات امنیتی و اخلاقی اشاره دارد. گاهی اوقات این مدلهای زبانی برای تولید اطلاعات مخرب مورد استفاده قرار میگیرند. تولید اطلاعات نادرست و به کارگیری این مدلها برای آسیب زدن به سایر افراد توانسته چالشهای گستردهای را سر راه کارشناسان قرار دهد.
چگونه میتوان امنیت LLM ها را تامین نمود؟
همانطور که مشاهده نمودید، تامین امنیت مدلهای زبانی بزرگ (LLM) کار دشواری به حساب میآید. توسعه دهندگان هم باید مراقب باشند تا مدل سوگیری نکند و هم باید مطمئن شوند که کاربران نمیتوانند به راحتی LLMها را هک کنند. برای تامین امنیت مدلهای زبانی، در اولین مرحله ما باید دادههای آموزشی را فیلتر کنیم. حذف دادههای مضر و تعصبی میتواند نتایج مطلوبی را برای شما به همراه داشته باشد.
جدا از این مسئله، هنگام ایجاد مدل نهایی ما باید از الگوریتمهای نظارتی استفاده کنیم. الگوریتمهای نظارت و کنترل خروجی به گونهای طراحی شدهاند تا جلوی محتوای خطرناک را بگیرند. البته، بسته به مشخصات و جزئیات پروژهای که شما روی آن کار میکنید سطح بازدهی هم تغییر مییابد. در آخرین مرحله شما باید به سراغ شفافیت بروید و مطمئن شوید که همه تصمیمات مدل به صورت کامل توضیح پذیر هستند. عدم توجه به این نکات سطح امنیت را کاهش میدهد.
برای جلوگیری از این مسئله، شما باید بتوانید نحوه استفاده از مدلهای زبانی بزرگ را حدس بزنید. شناسایی کلمات کلیدی مخرب و مضر از جمله مباحثی کلیدی و مهمی به حساب میآید که روند انجام فعالیتهای مختلف را تحت تاثیر خود قرار میدهد. با استفاده از این تکنیکها، شما نظارت کاملی روی فرآیند خروجی خواهید داشت و در این زمینه به نتایج مطلوبی میرسید.
مقایسه GPT و BERT
مدلهای زبانی بزرگ میتوانند دسته بندیهای زیادی داشته باشند. GPT و BERT دو مدل بزرگ و کلیدی به حساب میآیند که تفاوتهای زیادی را در خود جای دادهاند. مدل GPT به گونهای طراحی شده است تا مولد باشد. این مدل متن را به صورت خودبازگشتی تولید نموده و میتواند کاربردهای گستردهای داشته باشد. طراحی چت باتهای اختصاصی و سیستمهای مدیریت چتروم از جمله مهمترین کاربردهای این مدل به حساب میآیند.
مدل BERT یک مدل دوسویه است که میتواند کاربردهای گستردهای داشته باشد. این مدل توسط شرکت گوگل توسعه یافته و در اختیار کاربران قرار میگیرد. این مدل دوسویه برای درک متن بهینه شده و وظایفی همچون پاسخ دهی به سوالات و تحلیلی احساسات را بر عهده گرفته است. به خاطر داشته باشید که این دو مدل از نظر ساختاری تفاوتهای زیادی را در خود جای دادهاند.
این مدلهای زبانی بزرگ بر پایه شبکههای ترنسفورمر تولید شدهاند. مدل جی پی تی به گونهای طراحی شده تا از یک مجموعه متن بزرگ درس را فرا گیرد و متن روان و معنادار تولید نماید. این در حالی است که مدل BERT کلمات تصادفی را با یک ماسک جایگزین میکند تا فرآیند یادگیری کمی چالش برانگیز تر شود. مدل BERT درک عمیقی از متن به دست آورده و میتواند بازدهی مطلوبی را نیز در اختیار شما بگذارد.
آینده مدلهای زبانی در پردازش زبان طبیعی
مدلهای زبانی بزرگ دنیای هوش مصنوعی را متحول نمودهاند. قطعا آینده این مدلها روشن بوده و کارشناسان فعال در این حوزه میتوانند به یک بازار کار فوق العاده دسترسی داشته باشند. بهبود کارایی و کاهش مصرف انرژی با ابداع روشهای کارآمد استفاده از این مدلها اهمیت زیادی خواهد داشت.
جدا از این مسئله، مدلهای مطرح شده در این زمینه مقیاس بزرگی دارند و امکان استفاده از آنها برای کاربران ساده و سازمانهای کوچک وجود ندارد! در نتیجه، کارشناسان همواره باید به دنبال توسعه مدلهای کوچکی باشند که میتوانند قدرت عملکرد مطلوبی را از خود به نمایش بگذارند. این مسئله در دستگاههای شخصی هم به کار میرود.
به خاطر داشته باشید که مدلهای زبانی بزرگ میتوانند تعاملات انسان و ماشین را نیز سادهتر نمایند. مدلهای طبیعیتر و قابل اعتماد تر خیلی راحت با زندگی انسان پیوند خورده و میتوانند حجم قابل توجهی از فرآیندهای مختلف را بهینه سازند. از همین رو، مدلهای زبانی بزرگ ابزاری کلیدی به حساب میآیند که توانستهاند دنیای هوش مصنوعی را متحول نمایند.
آیا LLM ها میتوانند به درک واقعی یک زبان برسند؟
درک واقعی یک زبان، مسئلهای چالش برانگیز به حساب میآید که همه مدلها به آن علاقه دارند. تاکنون هیچکدام از مدلهای زبانی بزرگ ایجاد شده در دنیای ما نتوانسته به درک واقعی یک زبان برسد. این مدلها به گونهای طراحی شدهاند تا با شناسایی الگوهای آماری و ارتباطات موجود در دادههای متنی نسبت به تحلیل آن اقدام نمایند. این در حالی است که درک واقعی یک زبان یا فرهنگ میتواند روند استفاده از این مدلها را متحول نماید. پس میتوان به این نتیجه رسید که مدلهای زبانی بزرگ همچنان درکی از زبان انسان ندارند.
تحقیقات گستردهای در این زمینه انجام میشود و کارشناسان به دنبال ایجاد مدلهایی هستند که به راحتی زبان انسان را درک میکنند. البته که تا ایجاد چنین مدلهایی ما همچنان فاصله زیادی داریم! به خاطر داشته باشید که درک واقعی یک زبان میتواند نیاز مدلهای هوش مصنوعی پردازش زبان از استفاده از دادههای قدیمی و الگوریتمهای کلاسیک را به صورت کامل رفع کند. این مسئله همواره روی سطح بازدهی و کیفیت عملکرد مدلهای پردازش زبان طبیعی تاثیر میگذارد.
سوالات متداول در مورد مدلهای زبانی بزرگ
مدلهای زبانی بزرگ چه نقشی در پردازش زبان طبیعی دارند؟
پردازش زبان طبیعی (NLP) یکی از مهمترین شاخههای هوش مصنوعی به حساب میآید که توانایی تعامل انسان و ماشین را ایجاد میکند. مدلهای زبانی بزرگ با یادگیری حجم زیادی از دادههای متنی، میتوانند فعالیتهای مختلفی همچون درک متن، تحلیل احساسات و ترجمه را به اتمام برسانند. به خاطر داشته باشید که این مدلها همواره روی سطح بازدهی پروژههای مختلف تاثیر میگذارند.
چگونه LLM ها آموزش میبینند؟
همانطور که در این صفحه مشاهده کردید، فرآیند آموزش مدلهای زبانی بزرگ از چندین مرحله خاص تشکیل شده است. جمع آوری اطلاعات، پردازش اطلاعات، پیش آموزش و تنظیم دقیق را میتوان به عنوان مهمترین مراحل استفاده از مدلهای زبانی بزرگ در نظر گرفت. به خاطر داشته باشید که پیاده سازی این ابزار روی سرورهای بزرگ هم اهمیت زیادی خواهد داشت.
مهمترین مدلهای زبانی بزرگ کدامها هستند؟
مدل زبانی بزرگ (LLM) را میتوان در دسته بندیهای زیادی تقسیم نمود. از جمله مطرحترین و بهترین مدلهای ایجاد شده در این زمینه باید به مواردی همچون BERT، GPT و Claude اشاره کرد. به خاطر داشته باشید که این الگوریتمهای پر اهمیت هم بازدهی مطلوبی را به همراه دارند و هم خروجیهای متنوعی دارند.
چالشهای استفاده از LLM ها چیست؟
به خاطر داشته باشید که مدلهای زبانی بزرگ چالشهای زیادی را سر راه کاربران به همراه دارند. هزینههای محاسباتی بالا، تعصب، عدم درک واقعی از معنا و سوگیری را میتوان از جمله مهمترین چالشهای مطرح شده در این زمینه معرفی نمود. هر کدام از این چالشها، به نحوی خاص روند استفاده از مدلهای زبانی را تحت تاثیر خود قرار میدهند. خوشبختانه برای حل هرکدام از این چالشها، یک سری راهکار مطرح میشود. انتخاب بهترین راهکار در این زمینه اهمیت زیادی دارد.
چطور به یک متخصص مدلهای زبانی بزرگ (LLM) تبدیل شویم؟
دنیای هوش مصنوعی با سرعت عجیبی در حال حرکت است و تقاضا برای متخصصانی که بتوانند فراتر از یک کاربر ساده عمل کنند، روز به روز بیشتر میشود. اگر میخواهید از مرحله تئوری عبور کرده و وارد دنیای ساخت پروژههای واقعی شوید، باید نقشه راه درستی را دنبال کنید.
ما در دیتایاد، دوره جامع آموزش پردازش زبان طبیعی (NLP) و مدلهای زبانی بزرگ را با رویکردی کاملاً پروژه محور طراحی کردهایم. در این دوره، شما از بیس و پایه با مفاهیم یادگیری عمیق و معماری ترنسفورمرها آشنا میشوید و تا تخصصیترین پروژهها پیش خواهید رفت. برخی از ویژگیهای برجسته این دوره عبارتند از:
- آموزش از صفر تا تخصص: یادگیری مفاهیم بنیادی تا پیادهسازی معماریهای پیچیده.
- کار با مدلهای Open Source: تسلط بر پیادهسازی و مدیریت مدلهای Open Source.
- آموزش Fine-tuning: یاد میگیرید که چطور یک مدل بزرگ را برای نیازهای خاص و دادههای اختصاصی خود بهینه کنید.
- کار با APIهای پیشرفته: تسلط بر استفاده حرفهای از سرویسهای OpenAI و سایر غولهای هوش مصنوعی.
- اجرای پروژههای واقعی: از جمله ساخت سیستم خلاصهساز هوشمند کامنتها و طراحی چتباتهای اختصاصی با دانش سفارشی.
اگر به دنبال این هستید که بدانید دقیقاً چه چیزهایی را باید یاد بگیرید و این مسیر را از کجا به صورت اصولی شروع کنید، پیشنهاد میکنیم به صفحه دوره LLM و NLP دیتایاد مراجعه کنید. این دوره کلید ورود شما به بازار کار فوق حرفهای هوش مصنوعی است.




















