

دههها، پردازش تصویر بر الگوریتمهای سنتی استوار بود که نیازمند استخراج دستی ویژگیها (Manual Feature Engineering) از سوی متخصصان بودند. این وابستگی، عملکرد سیستمها را در برابر تغییرات نور، زاویه و بافت محدود میکرد و مانعی بزرگ در مسیر تحقق بینایی کامپیوتر (Computer Vision) هوشمند بود. با ظهور فناوری یادگیری عمیق، این مسیر تغییر کرد و امروزه پردازش تصویر با Deep Learning به استاندارد جدید تبدیل شده است.
ظهور یادگیری عمیق (Deep Learning) و بهویژه شبکههای عصبی کانولوشنی (CNN)، این مسیر را کاملاً دگرگون کرد. CNNها با الهام از سیستم بینایی بیولوژیک، به طور خاص برای پردازش دادههای تصویری طراحی شدهاند. برخلاف شبکههای سنتی مانند MLP که تصاویر را به صورت ناکارآمد و پیکسل به پیکسل تحلیل میکنند، CNNها تصاویر را در قالب بخشهای مجزا و با استفاده از فیلترهای خودآموز تحلیل میکنند تا الگوهای پیچیده و سلسلهمراتبی (مانند لبهها، بافتها، و در نهایت اشیا) را به صورت خودکار استخراج کنند.
در کنار CNNها، شبکههای مولد متخاصم (GAN) نسل جدیدی از مدلهای هوش مصنوعی را معرفی کردند که قادرند تصاویر کاملاً واقعی و ساختگی را تولید یا آنها را ترمیم و تبدیل کنند. این شبکهها با یک رقابت داخلی (بین مولد و تمیزدهنده) کار میکنند و مرزهای خلاقیت ماشینی را جابجا کردهاند.
در این مقاله جامع، ما تمرکز خود را بر این دو فناوری انقلابی قرار میدهیم: ابتدا معماری CNN را موشکافی میکنیم و سپس، به دنیای هیجانانگیز GAN و کاربردهای آن در تولید و تبدیل تصاویر خواهیم پرداخت.
گذار از پردازش تصویر کلاسیک به پردازش تصویر با Deep Learning
۱. مشکل اصلی روشهای کلاسیک: مهندسی دستی ویژگیها
روشهای سنتی پردازش تصویر (مانند فیلترهای Sobel و Canny برای لبهیابی یا الگوریتمهای SIFT و HOG برای استخراج ویژگی)، بر پایهی الگوریتمهای ریاضی مبتنی بودند که توسط انسانها طراحی میشدند. این رویکرد دو مشکل اساسی داشت:
- دستی بودن (Manual Engineering): برای انجام هر وظیفهای (مانند تشخیص شیء)، متخصص باید بهصورت دستی ویژگیهای مورد نیاز (مثلاً گوشههای تیز، دایرههای صاف یا بافت خاص) را تعریف و کدنویسی میکرد. این فرآیند زمانبر و نیازمند دانش عمیق انسانی بود.
- شکنندگی (Fragility): این الگوریتمها نسبت به تغییرات محیطی مانند تغییر زاویه دید، نورپردازی ضعیف، یا نویز پسزمینه، بسیار حساس بودند. اگر شرایط تصویر اندکی متفاوت بود، سیستم اغلب کارایی خود را از دست میداد.
۲. راهحل Deep Learning: یادگیری سلسلهمراتبی ویژگیها
انقلاب Deep Learning در این بود که نیاز به مهندسی دستی ویژگیها را بهطور کامل حذف کرد. شبکههای عصبی عمیق، بهویژه شبکههای عصبی کانولوشنی (CNN)، توانایی دارند که ویژگیهای تصویر را بهصورت خودکار، سلسلهمراتبی و بدون نظارت مستقیم انسان یاد بگیرند. این توانایی، قلب تپنده پردازش تصویر با Deep Learning محسوب میشود:
- یادگیری الگوهای پایه: در اولین لایههای شبکه، سیستم الگوهای بسیار ساده (مانند خطوط افقی، عمودی و رنگها) را یاد میگیرد.
- ترکیب الگوها: در لایههای میانی، شبکه این الگوهای ساده را ترکیب میکند تا شکلهای پیچیدهتر (مانند گوشهها، دایرهها یا بافتهای مشخص) را شناسایی کند.
- تشخیص سطح بالا: در لایههای عمیق و نهایی، ویژگیهای پیچیده ترکیب شده تا اشیای سطح بالا (مانند چهره کامل انسان، خودرو یا حیوان) را تشخیص دهند.
این توانایی در یادگیری خودکار ویژگیها، دلیل اصلی برتری Deep Learning در بینایی کامپیوتر است.
۳. اهمیت پیشپردازش (Preprocessing) در عملکرد مدلهای هوش مصنوعی
با وجود قدرت خارقالعاده Deep Learning، کیفیت داده ورودی همچنان عاملی حیاتی است. اینجاست که تکنیکهای کلاسیک پردازش تصویر، نقش پیشپردازش را ایفا میکنند:
- نقش پیشپردازش: عملیاتی مانند نرمالسازی نوری، حذف نویز (با فیلترهای سنتی) یا ترمیم آرتیفکتها، دادههای خام را به کیفیتی میرسانند که مدلهای هوش مصنوعی بتوانند الگوهای دقیقتری را یاد بگیرند.
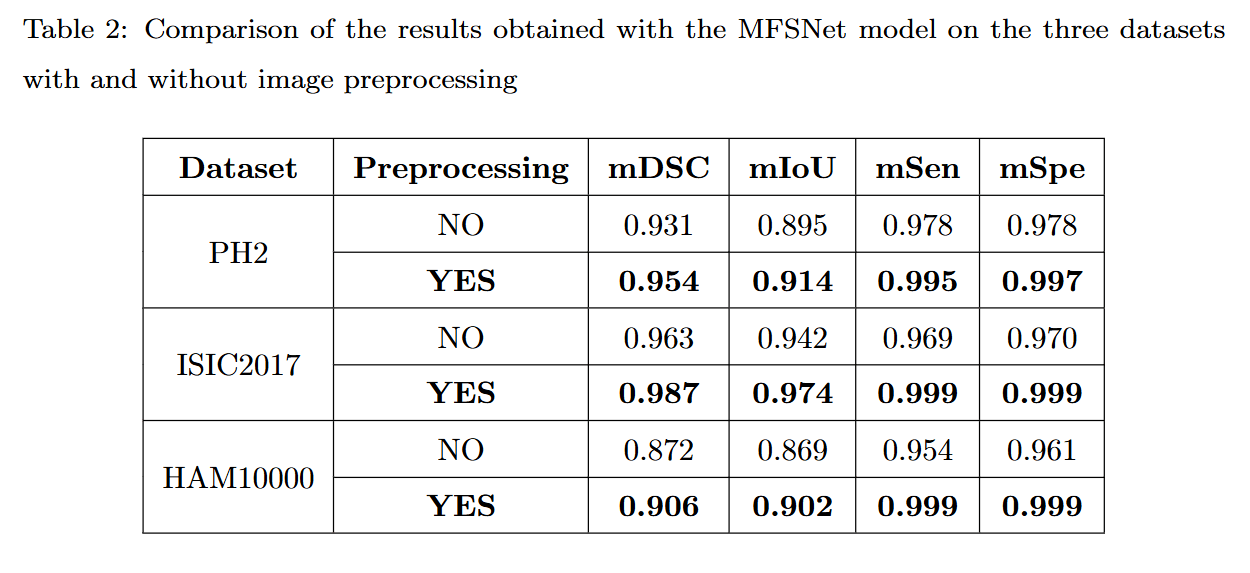
- مطالعه موردی (تصویربرداری پزشکی): در یک مطالعه تخصصی که به مسئله بخشبندی تصاویر پزشکی (Medical Image Segmentation) میپردازد، نویسندگان از تکنیک ترمیم تصویر (Image Inpainting) در پیشپردازش خود برای حذف نویز از تصاویر درموسکوپی استفاده کردهاند.

- تأثیر کمی: این فرآیند پیشپردازش ساده، منجر به افزایش ۳ درصدی عملکرد در دقت مدل بخشبندی شده است. این میزان بهبود، بهویژه در کاربردهای زیستپزشکی که دقت تشخیص امری حیاتی است، یک پیشرفت قابل توجه محسوب میشود. نتایج کمی (quantitative results) به دست آمده برای این مسئله، در حالت با پیشپردازش و بدون آن، برای سه دیتاست مختلف در ادامه نمایش داده شده است.
نتیجه این گذار، پایان تکیه بر استخراج دستی ویژگیها و آغاز دوران یادگیری خودکار بود. دیگر لازم نیست مهندسان برای هر سناریو، ویژگیهای خاصی را تعریف کنند؛ بلکه شبکههای عصبی عمیق، این قابلیت را دارند که از حجم عظیم دادهها، الگوهای مورد نیاز را استخراج کنند و عملکردی به مراتب پایدارتر و دقیقتر ارائه دهند. این تحول، هسته اصلی پردازش تصویر با Deep Learning را تشکیل میدهد. در این میان، شبکههای عصبی کانولوشنی (CNN) به عنوان موتور محرک اصلی این انقلاب شناخته میشوند. در بخش بعد، به طور عمیق وارد جزئیات ساختاری این شبکهها خواهیم شد تا درک کنیم چگونه فیلترها و لایههای آنها، بینایی کامپیوتر را از یک فرآیند شکننده به یک فناوری هوشمند تبدیل کردهاند.
شبکههای عصبی کانولوشن (CNN): ساختار و نحوه یادگیری ویژگیهای تصویر
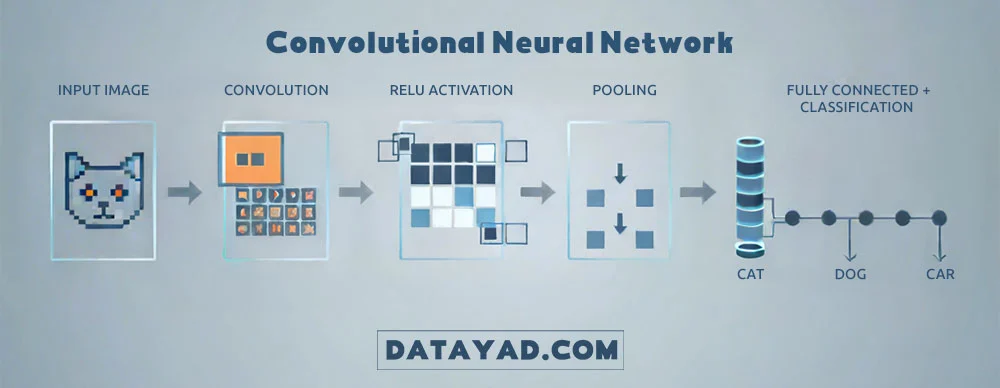
شبکه عصبی کانولوشن (Convolutional Neural Network یا CNN) موتور محرک اصلی انقلاب Deep Learning در پردازش تصویر است. این معماری به گونهای طراحی شده که با تقلید از سیستم بینایی انسان، توانایی یادگیری الگوهای مکانی تصویر را داشته باشد. در واقع، CNNها ستون فقرات پردازش تصویر با Deep Learning را تشکیل میدهند.
یک CNN از چندین نوع لایه مختلف تشکیل شده که هر کدام وظیفه خاصی در استخراج ویژگیها از تصویر ورودی دارند.
۱. لایه کانولوشن (Convolutional Layer): استخراج ویژگی
لایه کانولوشن مهمترین و اساسیترین بخش یک CNN است. وظیفه این لایه، استخراج خودکار ویژگیها (مانند لبهها، بافتها و گوشهها) از تصویر ورودی است.
- فیلتر (Kernel): لایه کانولوشن از مجموعهای از ماتریسهای کوچک به نام فیلتر یا کرنل استفاده میکند. این فیلترها روی تصویر ورودی اسلاید میکنند و با انجام یک عملیات ضرب داخلی (Dot Product) بین مقادیر پیکسلهای تصویر و مقادیر خود فیلتر، یک مقدار خروجی تولید میکنند.
- نقشه ویژگی (Feature Map): نتیجه حاصل از عبور فیلتر از روی کل تصویر، یک نقشه ویژگی است. این نقشه نشان میدهد که یک ویژگی خاص (که فیلتر آن را شناسایی کرده) در کدام قسمتهای تصویر وجود دارد.
- یادگیری فیلتر: برخلاف روشهای کلاسیک که فیلترها ثابت بودند (مثلاً فیلتر سوبل)، در CNNها، مقادیر داخل این فیلترها به صورت خودکار و در طول فرآیند آموزش یاد گرفته میشوند.
۲. لایه تجمعی (Pooling Layer): کاهش ابعاد
لایه تجمعی (که اغلب بهصورت Max Pooling استفاده میشود) در فواصل منظم بین لایههای کانولوشن قرار میگیرد و دو هدف اصلی دارد:
- کاهش ابعاد (Dimensionality Reduction): با خلاصه کردن اطلاعات نقشه ویژگی، اندازه ماتریسها را کاهش میدهد. این امر محاسبات را سریعتر میکند.
- ثبات (Robustness): با کاهش جزئیات، شبکه نسبت به تغییرات کوچک در مکان پیکسلهای شیء (Shift Invariance) مقاومتر میشود. یعنی اگر شیء کمی جابجا شود، شبکه همچنان آن را تشخیص میدهد.
در Max Pooling، فیلتر روی ورودی حرکت کرده و تنها بزرگترین مقدار را از منطقه تحت پوشش خود به خروجی منتقل میکند.
۳. لایه کاملا متصل (Fully Connected Layer): طبقه بندی نهایی
در انتهای معماری CNN، VVپس از آن که چندین لایه کانولوشن و تجمعی، ویژگیهای پیچیده را استخراج کردند، از لایههای کاملاً متصل استفاده میشود:
- ساختار: در این لایهها، هر نورون به تمامی نورونهای لایه قبلی متصل است.
- وظیفه: وظیفه این بخش، استفاده از ویژگیهای استخراج شده برای انجام طبقه بندی نهایی است. لایههای FC احتمال تعلق تصویر ورودی را به هر یک از کلاسهای ممکن (مثلاً ۹۸٪ گربه، ۲٪ سگ) محاسبه میکنند.
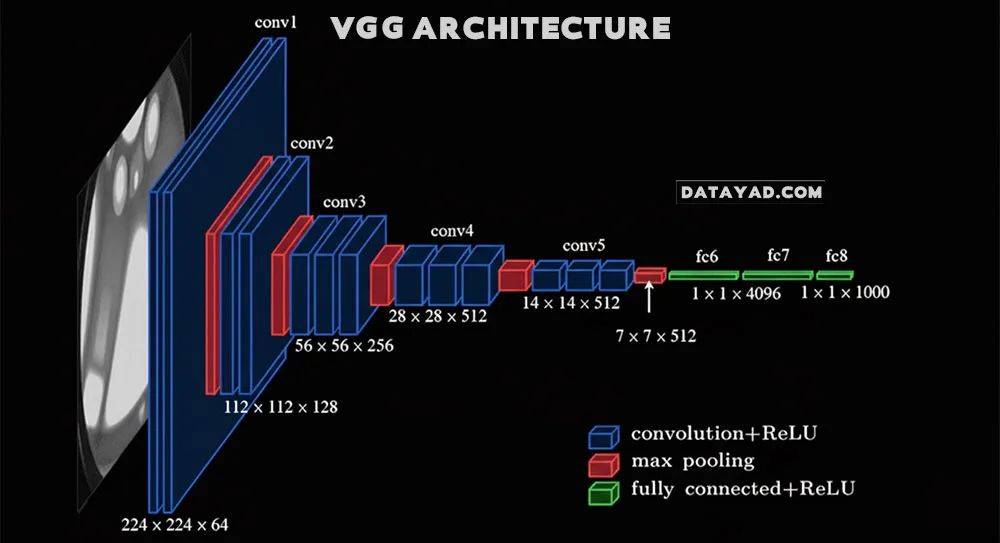
۴. معماریهای معروف CNN در پردازش تصویر با Deep Learning
توانایی CNNها در یادگیری خودکار ویژگیها، منجر به توسعه مدلهای موفقی شده است که امروزه به عنوان ستون اصلی بینایی کامپیوتر شناخته میشوند:
- ResNet: برای حل مشکل افت دقت در شبکههای بسیار عمیق طراحی شد و یکی از پراستفادهترین مدلها در طبقه بندی و تشخیص شیء است.
- VGG: شبکهای با ساختار بسیار یکنواخت و استفاده مکرر از فیلترهای کوچک (۳x۳) که به دلیل سادگی و عمق خود، بسیار تأثیرگذار بود.
- U-Net: یک معماری خاص که به طور گسترده در بخشبندی تصویر (Segmentation)، بهویژه در کاربردهای پزشکی، استفاده میشود.
معماریهای CNN مسئول توانایی “دیدن” و “درک” هستند. اما حوزه خلاقیت و تولید محتوای بصری به دست فناوری دیگری است که در ادامه به آن میپردازیم: شبکههای مولد متخاصم (GAN).
هوش مصنوعی مولد برای تصویر: شبکههای مولد متخاصم (GAN)
اگر شبکههای CNN انقلاب درک و تحلیل تصویر را رقم زدند، شبکههای مولد متخاصم (Generative Adversarial Networks یا GAN) آغازگر عصر تولید و خلاقیت ماشینی در دادههای بصری بودند. GANها یک مدل هوش مصنوعی کاملاً متفاوت از شبکههای طبقهبندیکننده مانند CNN هستند و هدف اصلی آنها تولید دادههای جدید و ساختگی (Synthetic) است که کاملاً شبیه به دادههای واقعی به نظر برسند. این قابلیت تولید محتوا، یک بعد جدید و هیجانانگیز را به پردازش تصویر با Deep Learning افزود.
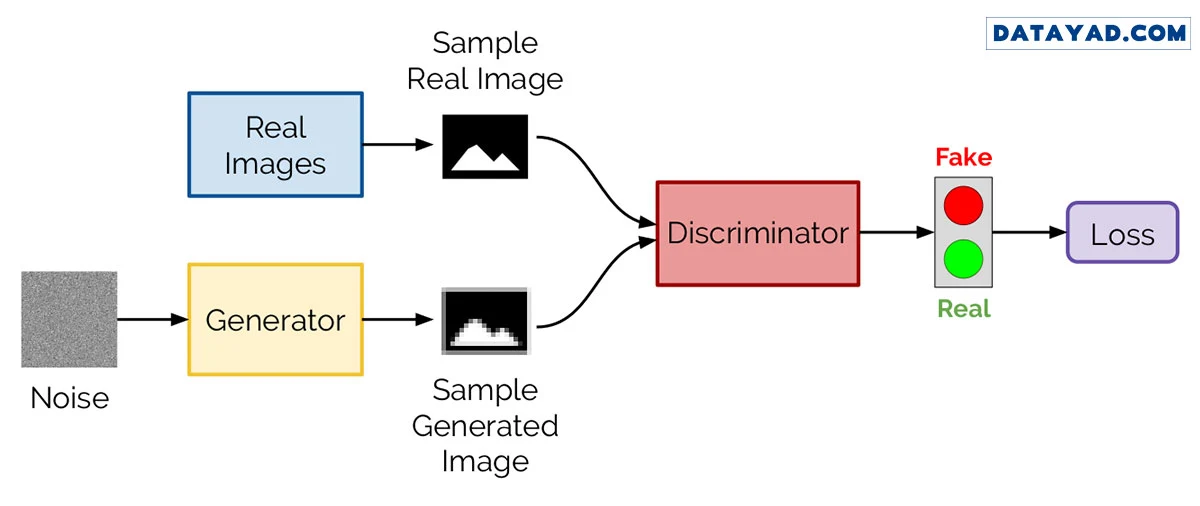
۱. ساختار بازی دو نفره: مولد و تمیزدهنده
معماری GAN بر اساس یک مفهوم رقابتی (بازی با حاصل جمع صفر) طراحی شده است که از دو شبکه عصبی مستقل تشکیل میشود که به صورت متخاصم با یکدیگر آموزش میبینند:
- شبکه مولد (Generator): وظیفه این شبکه، تولید تصاویر ساختگی (جعلی) از یک ورودی نویز تصادفی است. هدف آن فریب دادن شبکه تمیزدهنده است.
- شبکه تمیزدهنده (Discriminator): وظیفه این شبکه، یک وظیفه طبقهبندی ساده است: تشخیص اینکه آیا تصویر ورودی واقعی (از مجموعه دادههای آموزشی) است یا ساختگی (تولید شده توسط مولد).
آنالوژی دزد و پلیس: مولد شبیه به جاعل اسکناس است که تلاش میکند پول تقلبی بسازد و تمیزدهنده شبیه به پلیس است که سعی میکند پول تقلبی را شناسایی کند. با گذشت زمان، جاعل حرفهایتر میشود و پلیس تیزبینتر، تا زمانی که مولد بتواند تصاویری تولید کند که تمیزدهنده نتواند آنها را تشخیص دهد.
۲. فرآیند آموزش و رسیدن به تعادل
آموزش GAN یک فرآیند تکراری و نوبتی است که در نهایت به یک تعادل (Nash Equilibrium) ختم میشود:
گام ۱: آموزش تمیزدهنده: ابتدا، تمیزدهنده با استفاده از تصاویر واقعی (برچسب: واقعی) و تصاویر تولید شده توسط مولد (برچسب: ساختگی) آموزش میبیند تا دقت آن در تشخیص تقلبیها افزایش یابد.
گام ۲: آموزش مولد: در این گام، مولد آموزش میبیند تا تصاویری تولید کند که تمیزدهنده آنها را واقعی تشخیص دهد. در این مرحله، وزنهای تمیزدهنده ثابت میماند.
نتیجه نهایی: این دو شبکه بهصورت متقابل یکدیگر را بهتر میکنند تا جایی که مولد تصاویری تولید میکند که حتی تمیزدهنده خبره هم قادر به تشخیص ساختگی بودن آنها نیست.
۳. انواع پیشرفته GAN و کاربردهای تخصصی
مدل پایه GAN به تنهایی دارای محدودیتهایی است (مانند تولید تصاویر نامرتبط). برای حل این مشکلات، مدلهای پیشرفتهتری توسعه یافتهاند که قابلیت کنترل بیشتری بر خروجی دارند:
- Conditional GAN (CGAN): این مدل به مولد اجازه میدهد تا بر اساس یک شرط ورودی (مانلاً یک برچسب متنی یا یک دسته بندی)، تصویر تولید کند. مثلاً: “یک گربه با چشمهای سبز بساز.”
- CycleGAN: این مدل برای تبدیل تصویر به تصویر (Image-to-Image Translation) بدون نیاز به جفت داده (Unpaired Data) استفاده میشود. مثال معروف آن تبدیل یک عکس از اسب به گورخر یا فصل تابستان به زمستان است.
- StyleGAN: این مدلها به دلیل توانایی تولید چهرههای انسانی کاملاً واقعی و ساختگی با قابلیت کنترل دقیق بر جزئیات (مانلاً مدل مو، رنگ پوست و…) مشهور هستند.
اکنون که معماری و اصول کار CNN (برای تحلیل) و GAN (برای تولید) را آموختیم، درک میکنیم که چگونه این دو مدل، دو قطب اصلی پردازش تصویر با Deep Learning را تشکیل میدهند. این دو فناوری، پایهای برای توسعه تکنیکها و کاربردهای پیشرفته در حوزههای مختلف فراهم میسازند. در بخش بعد، به سراغ مهمترین این کاربردها خواهیم رفت تا ببینیم چگونه این مدلها به صورت عملی در دنیای واقعی مورد استفاده قرار میگیرند.
کاربردهای Deep Learning در پردازش تصویر
قابلیتهای حوزه پردازش تصویر با Deep Learning فراتر از بهبود کیفیت یک عکس ساده رفته و شامل وظایف پیچیدهای مانند حذف اشیا ناخواسته از آن و یا حتی ساختن تصاویر کاملاً جدید است. برای مثال، میتوان با کمک این تکنیکها، پسزمینه را از تصویر یک شخص حذف کرد، به طوری که تنها سوژه در پیشزمینه باقی بماند.
اگر به دنبال یادگیری قدم به قدم این تکنیکها از مقدماتی تا پیشرفته هستید، میتوانید با شرکت در دوره پردازش تصویر دیتایاد تمام مباحث را به صورت عملی آموزش ببینید.
این تواناییها نتیجه الگوریتمها و مدلهای پیشرفتهای نظیر CNN و GAN هستند که هر کدام برای دستیابی به نتایج متفاوتی به کار میروند. در این بخش، بر روی برخی از متداولترین فعالیتها و چگونگی انجام آنها با تکیه بر قدرت Deep Learning در پردازش تصویر تمرکز خواهیم کرد.
بهبود کیفیت تصویر (Image Enhancement)
یکی از متداولترین وظایف در پردازش تصویر، بهبود کیفیت تصویر است. این تکنیک کاربردهای حیاتی در حوزههایی مانند بینایی کامپیوتر (Computer Vision)، سنجش از دور (Remote Sensing) و نظارت تصویری (surveillance) دارد. یک رویکرد رایج برای این کار، تنظیم کنتراست (contrast) و روشنایی (brightness) تصویر است.
کنتراست به تفاوت روشنایی بین روشنترین و تاریکترین نواحی یک تصویر گفته میشود. با افزایش کنتراست، تفاوت بین این نواحی بیشتر شده و جزئیات تصویر واضحتر دیده میشوند. روشنایی نیز به سطح کلی نور یا تاریکی یک تصویر اشاره دارد. با افزایش روشنایی، میتوان یک تصویر را روشنتر کرد تا دیدن آن آسانتر شود.
تنظیم کنتراست و روشنایی در اکثر نرمافزارهای ویرایش تصویر میتواند به صورت خودکار یا دستی انجام شود.

با این حال، تنظیم کنتراست و روشنایی، عملیاتی ابتدایی محسوب میشوند. گاهی اوقات، حتی یک تصویر با کنتراست و روشنایی عالی، هنگامی که بزرگنمایی (upscale) میشود، به دلیل تراکم پیکسلی (pixel density) پایین، تار به نظر میرسد.
برای حل این مشکل، از یک مفهوم نسبتاً جدید و بسیار پیشرفتهتر به نام (Image Super-Resolution) استفاده میشود. در این تکنیک، یک تصویر با رزولوشن بالا (high-resolution) از روی نسخهی کمکیفیت آن ساخته میشود. امروزه، از تکنیکهای یادگیری عمیق (Deep Learning) به طور گسترده برای انجام این کار استفاده میشود.

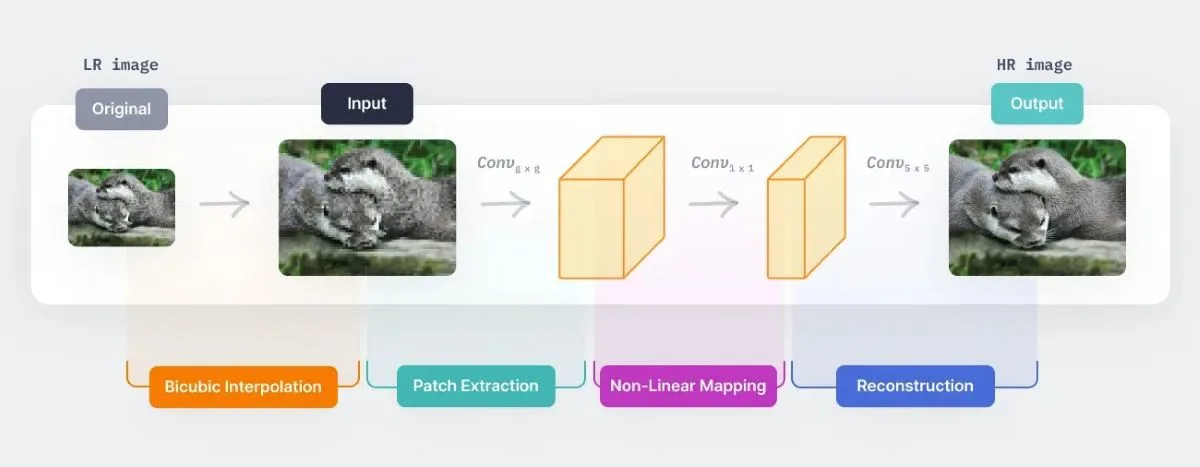
برای مثال، یکی از اولین نمونههای استفاده از یادگیری عمیق برای این مسئله، مدل SRCNN است. در این مدل، ابتدا تصویر کمکیفیت با استفاده از روش سنتی درونیابی دو مکعبی (Bicubic Interpolation) بزرگنمایی شده و سپس به عنوان ورودی به یک مدل CNN داده میشود.
در ادامه، فرآیند نگاشت غیرخطی (non-linear mapping) در CNN، بخشهای همپوشان (overlapping patches) را از تصویر ورودی استخراج میکند و یک لایه کانولوشن (convolution layer) بر روی این تکهها اعمال میشود تا در نهایت، تصویر بازسازیشده با رزولوشن بالا به دست آید.
چارچوب کلی این مدل در تصویر زیر به صورت بصری نمایش داده شده است.
بازسازی تصویر (Image Restoration)
کیفیت تصاویر ممکن است به دلایل مختلفی دچار افت یا تخریب شود، به خصوص عکسهای قدیمی که در دوران پیش از فراگیر شدن فضای ذخیرهسازی ابری (cloud storage) گرفته شدهاند.
برای مثال، تصاویری که از روی نسخههای چاپیِ گرفتهشده با دوربینهای فوری قدیمی اسکن میشوند، اغلب دارای خراشیدگی هستند.

حوزهی بازسازی تصویر از این جهت شگفتانگیز است که تکنیکهای پیشرفتهی آن میتوانند به طور بالقوه اسناد تاریخی آسیبدیده را ترمیم کنند. الگوریتمهای قدرتمند بازسازی تصویر مبتنی بر یادگیری عمیق، ممکن است بتوانند بخشهای بزرگی از اطلاعاتِ از دست رفته در اسناد پارهشده را آشکار سازند.
برای مثال، تکنیک ترمیم تصویر (Image Inpainting) در این دسته قرار میگیرد و به فرآیند پر کردن پیکسلهای از دست رفته در یک تصویر گفته میشود. این کار را میتوان با استفاده از الگوریتمهای سنتز بافت (texture synthesis) انجام داد که بافتهای جدیدی را برای پر کردن بخشهای خالی تولید میکنند. با این حال، امروزه مدلهای مبتنی بر یادگیری عمیق به دلیل قابلیتهای بالایشان در بازشناسی الگو (pattern recognition)، به انتخاب اصلی در این زمینه تبدیل شدهاند.

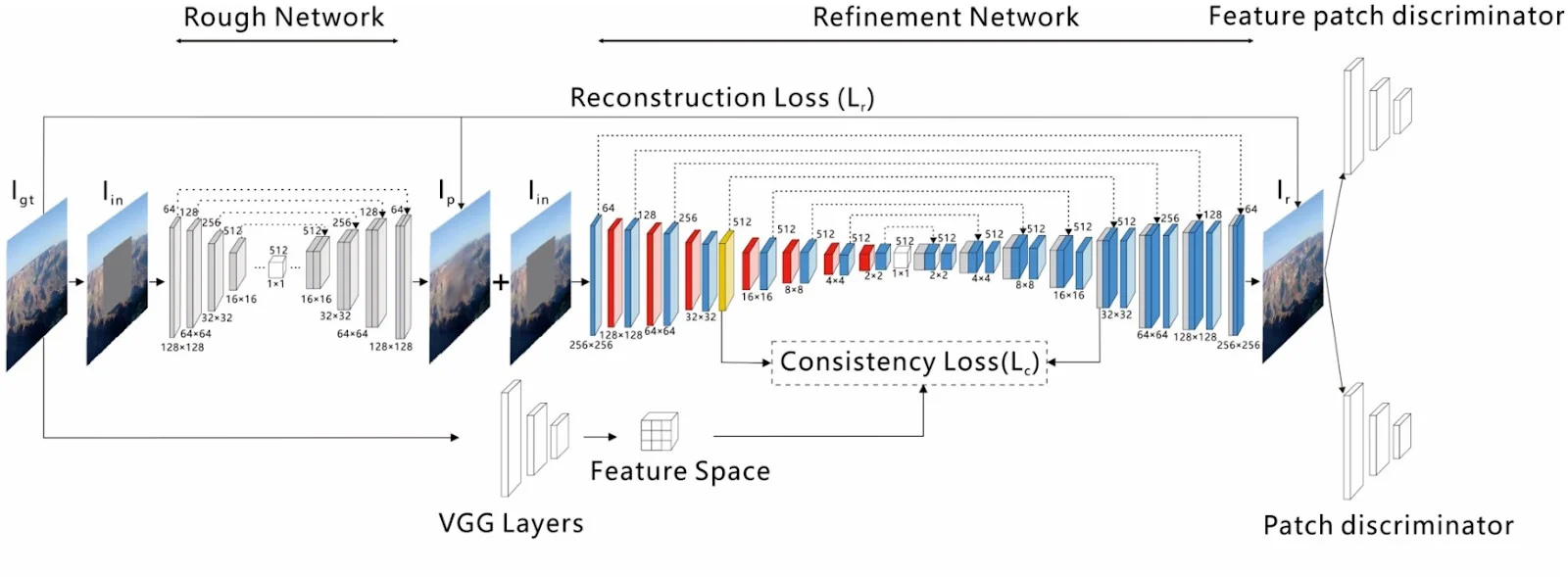
به عنوان نمونه، در یک مقاله، چارچوبی برای ترمیم تصویر (مبتنی بر اتو انکودر U-Net) ارائه شده است که از یک رویکرد دو مرحلهای استفاده میکند: یک مرحله تخمین اولیه (coarse estimation) و یک مرحله پالایش (refinement).
ویژگی اصلی این شبکه، لایه توجه معنایی منسجم (Coherent Semantic Attention ) است که نواحی پنهان (occluded regions) در تصویر ورودی را از طریق بهینهسازی تکراری (iterative optimization) پر میکند.
معماری مدل پیشنهادی در تصویر زیر نمایش داده شده است.
 در ادامه، نمونهای از نتایج بهدستآمده توسط نویسندگان این مقاله و سایر مدلهای رقیب، نمایش داده شده است.
در ادامه، نمونهای از نتایج بهدستآمده توسط نویسندگان این مقاله و سایر مدلهای رقیب، نمایش داده شده است.

بخش بندی تصویر (Image Segmentation)
بخش بندی تصویر، فرآیند تقسیم یا بخشبندی یک تصویر به چندین ناحیه یا سگمنت است. هر بخش، نمایانگر یک شیء متفاوت در تصویر است و معمولاً از بخش بندی به عنوان یک گام پیشپردازش (preprocessing) برای تشخیص اشیا (object detection) استفاده میشود.
برای بخش بندی، الگوریتمهای مختلفی وجود دارد، اما یکی از متداولترین رویکردها استفاده از آستانهگذاری (thresholding) است. برای مثال، آستانهگذاری باینری، فرآیند تبدیل یک تصویر به تصویر باینری است که در آن هر پیکسل یا سیاه است یا سفید. مقدار آستانه (threshold value) به گونهای انتخاب میشود که تمام پیکسلهای با سطح روشنایی کمتر از آستانه، سیاه شوند و تمام پیکسلهای با روشنایی بالاتر از آستانه، سفید شوند. این کار باعث میشود اشیاء در تصویر بخش بندی شوند، زیرا اکنون توسط نواحی مجزای سیاه و سفید نمایش داده میشوند.

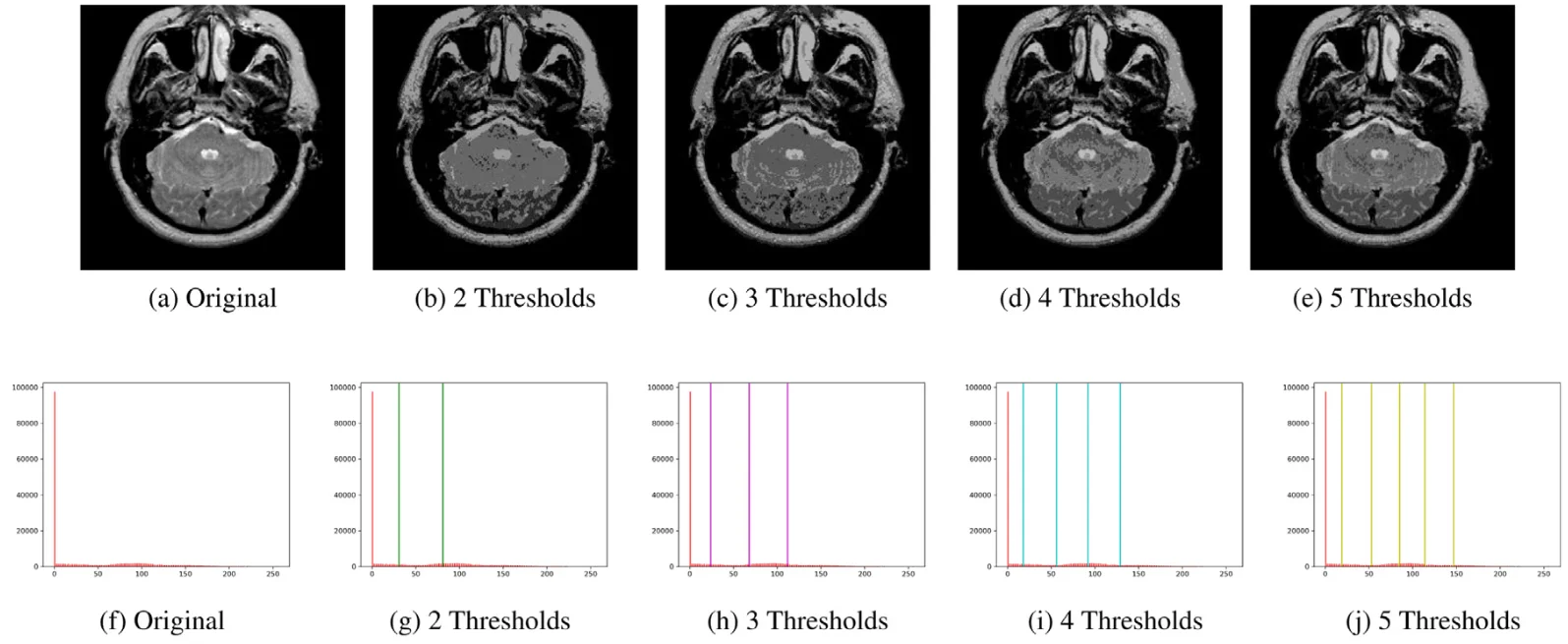
در آستانهگذاری چندسطحی (multi-level thresholding)، همانطور که از نامش پیداست، بخشهای مختلف تصویر بسته به تعداد سطوح تعریفشده، به طیفهای متفاوتی از رنگ خاکستری تبدیل میشوند.
برای مثال، در یک مقاله از این روش برای پردازش تصویر پزشکی و تصویربرداری پزشکی — بهطور خاص برای بخش بندی MRI مغز — استفاده شده است که نمونهای از آن در تصویر زیر قابل مشاهده است.
تکنیکهای مدرن از الگوریتمهای بخش بندی خودکار مبتنی بر یادگیری عمیق برای حل مسائل بخش بندی باینری و چندبرچسبی (multi-label) استفاده میکنند.
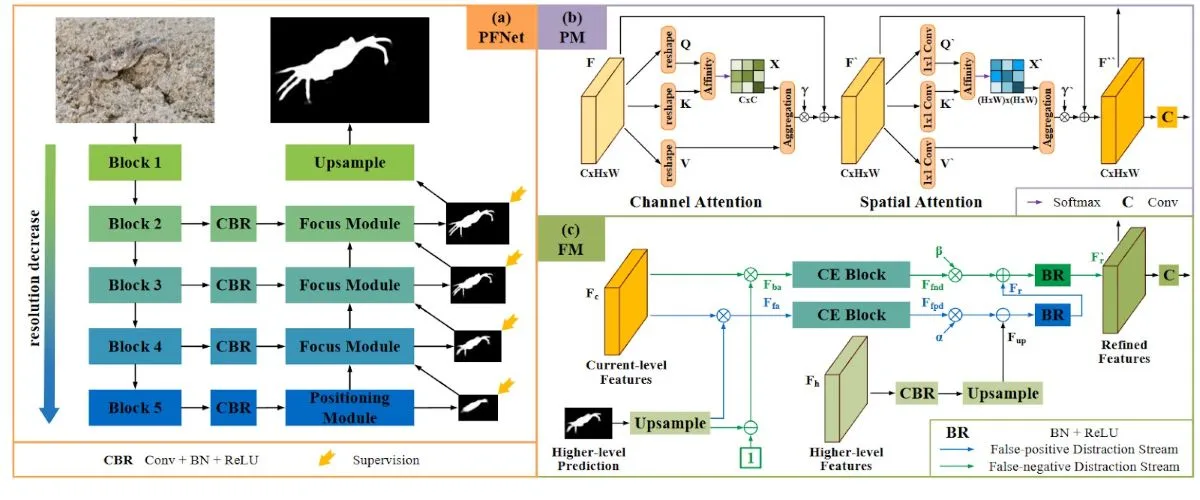
برای مثال، مدل PFNet یا شبکه موقعیتیابی و تمرکز (Positioning and Focus Network)، یک مدل مبتنی بر CNN است که برای حل مسئلهی دشوار بخش بندی اشیا استتارشده (camouflaged) طراحی شده است. این شبکه از دو ماژول کلیدی تشکیل شده است:
ماژول موقعیتیابی (PM): این ماژول برای تشخیص اشیاء طراحی شده و عملکرد آن از شکارچیانی تقلید میکند که ابتدا موقعیت کلی شکار را تخمین میزنند.
ماژول تمرکز (FM): این ماژول فرآیند شناسایی دقیقتر را با تمرکز بر روی نواحی مبهم انجام میدهد تا نتایج اولیهی بخش بندی را پالایش (refine) کند.
معماری مدل PFNet در تصویر زیر نشان داده شده است:
تشخیص اشیا (Object Detection)
تشخیص اشیا یا Object Detection، وظیفهی شناسایی اشیاء در یک تصویر است که اغلب در کاربردهایی مانند سیستمهای امنیتی و نظارت تصویری استفاده میشود.
الگوریتمهای زیادی برای تشخیص اشیاء وجود دارد، اما امروزه متداولترین رویکرد، استفاده از مدلهای یادگیری عمیق، به ویژه شبکههای عصبی پیچشی (CNNs) است.
CNNها نوعی شبکه عصبی مصنوعی (Artificial Neural Network) هستند که به طور خاص برای وظایف پردازش تصویر طراحی شدهاند. زیرا عملیات کانولوشن (convolution) در هستهی آنها به کامپیوتر کمک میکند تا به جای پردازش پیکسل به پیکسل، بخشهایی از تصویر را به صورت یکجا ببیند. CNNهایی که برای تشخیص اشیاء آموزش دیدهاند، یک (bounding box) را به عنوان خروجی تولید میکنند که موقعیت شیء شناساییشده در تصویر را به همراه برچسب کلاس آن نشان میدهد.
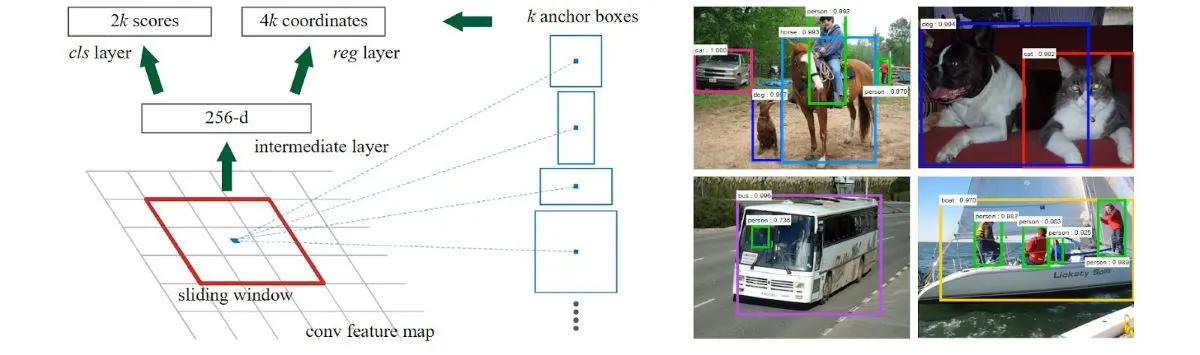
یک نمونه از چنین شبکههایی، مدل محبوب Faster R-CNN است که یک شبکه کاملا پیچشی (fully convolutional) و قابل آموزش به صورت سرتاسری (end-to-end) میباشد. مدل Faster R-CNN به طور متناوب بین دو وظیفه جابجا میشود: ابتدا تنظیم دقیق (fine-tuning) برای ماژول تولید پیشنهاد ناحیه (Region Proposal – پیشبینی نواحیای از تصویر که احتمالاً یک شیء در آن وجود دارد) و سپس تنظیم دقیق برای تشخیص خودِ شیء (اینکه چه شیئی در آن ناحیه وجود دارد)، در حالی که نواحی پیشنهادی ثابت نگه داشته میشوند.
معماری و نمونههایی از نواحی پیشنهادی (region proposals) در این مدل، در ادامه نمایش داده شده است.
فشردهسازی تصویر (Image Compression)
فشردهسازی تصویر، فرآیند کاهش حجم فایل (file size) یک تصویر است، در حالی که تلاش میشود کیفیت آن تا حد امکان حفظ شود. این کار با هدف صرفهجویی در فضای ذخیرهسازی (بهویژه برای اجرای الگوریتمهای پردازش تصویر روی دستگاههای موبایل انجام میشود.
رویکردهای سنتی از الگوریتمهای فشردهسازی با اتلاف (lossy compression) استفاده میکنند. این الگوریتمها با کاهش جزئی کیفیت تصویر، به حجم فایل کمتری دست پیدا میکنند. برای مثال، فرمت فایل JPEG از تبدیل کسینوسی گسسته (Discrete Cosine Transform) برای این منظور استفاده میکند.
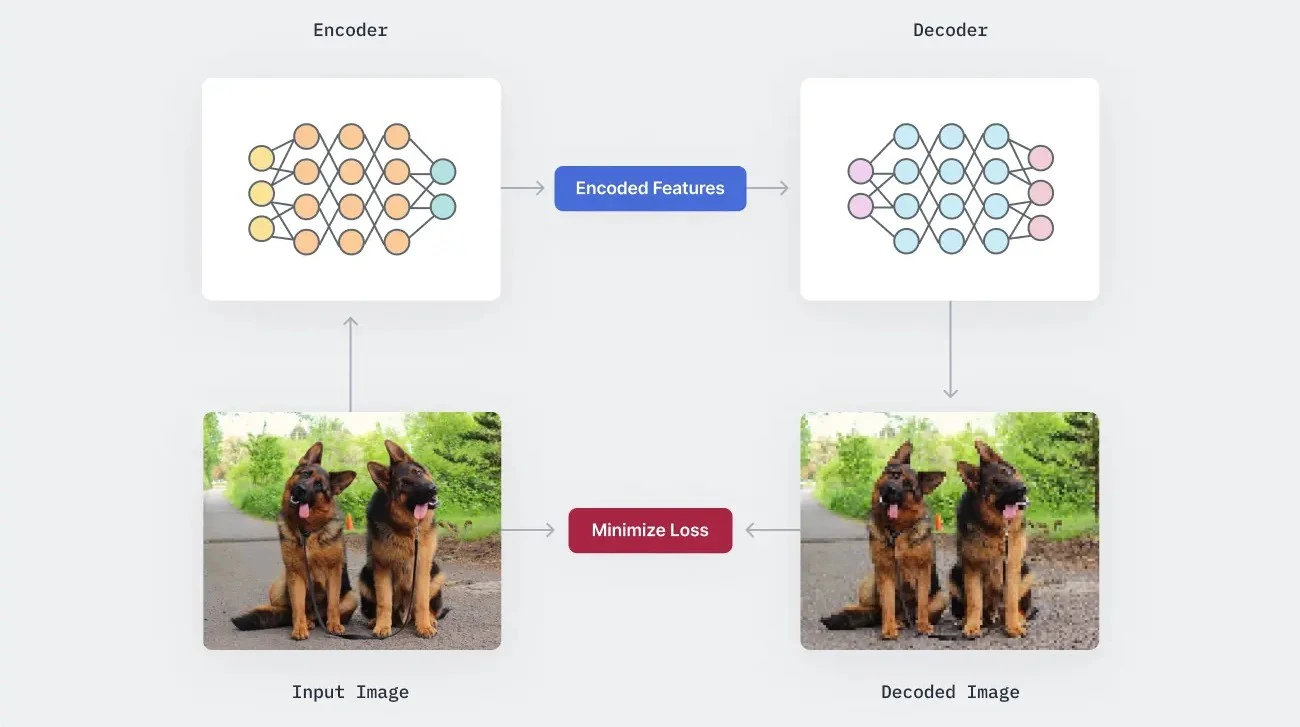
رویکردهای مدرن، از یادگیری عمیق برای رمزگذاری (encoding) تصاویر در یک فضای ویژگی با ابعاد کمتر و سپس بازیابی آن در سمت گیرنده با استفاده از یک شبکه رمزگشا (decoder) بهره میبرند. این مدلها خودرمزگذار (autoencoders) نامیده میشوند که از یک شاخه رمزگذار برای یادگیری یک طرح رمزگذاری بهینه، و یک شاخه رمزگشا تشکیل شدهاند که تلاش میکند تصویر را بدون اتلاف کیفیت از روی ویژگیهای رمزگذاریشده بازیابی کند.
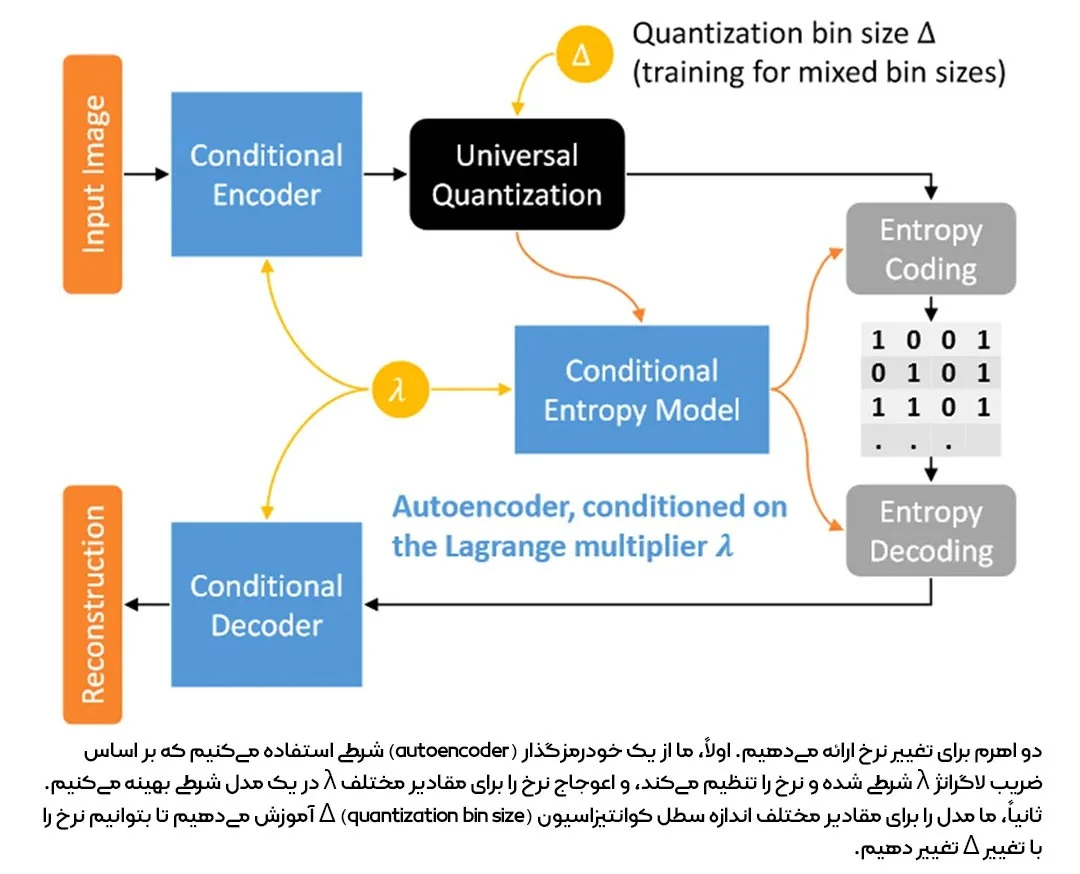
برای مثال، یک مقاله، چارچوبی برای فشردهسازی تصویر با نرخ متغیر با استفاده از یک خودرمزگذار شرطی (conditional autoencoder) ارائه کرده است.
این خودرمزگذار، بر اساس ضریب لاگرانژ (Lagrange multiplier) شرطیسازی میشود؛ یعنی شبکه، ضریب لاگرانژ را به عنوان ورودی دریافت کرده و یک بازنمایی نهان (latent representation) تولید میکند که نرخ فشردهسازی آن به مقدار ورودی بستگی دارد. نویسندگان همچنین شبکه را با اندازههای مختلف بازه کوانتیزاسیون (quantization bin sizes) آموزش میدهد تا نرخ فشردهسازی را به صورت دقیقتری تنظیم کنند.
چارچوب این مدل در تصویر زیر نمایش داده شده است:
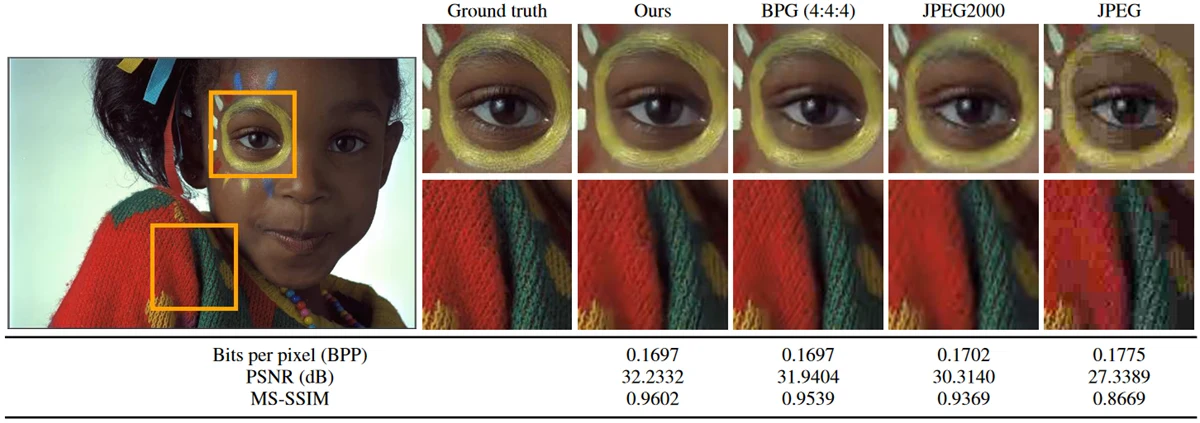
نویسندگان این مقاله در مقایسه با روشهای رایجی مانند JPEG، نتایج برتری به دست آوردند؛ هم از نظر کاهش بیت بر پیکسل (bits per pixel) و هم از نظر کیفیت بازسازی (reconstruction quality).
نمونهای از این برتری در تصویر زیر قابل مشاهده است:
دستکاری تصویر (Image Manipulation)
دستکاری تصویر، فرآیند تغییر دادن یک تصویر برای عوض کردن ظاهر آن است. این کار میتواند به دلایل مختلفی انجام شود، مانند حذف یک شیء ناخواسته از تصویر یا افزودن شیئی که در تصویر اصلی وجود ندارد. طراحان گرافیک اغلب از این تکنیک برای ساخت پوستر، فیلم و موارد دیگر استفاده میکنند.
یک نمونه از دستکاری تصویر، انتقال استایل عصبی (Neural Style Transfer) است؛ تکنیکی که با استفاده از مدلهای یادگیری عمیق، یک تصویر را با سبک (style) یک تصویر دیگر تطبیق میدهد. برای مثال، میتوان یک تصویر معمولی را به سبک نقاشی «شب پرستاره» (The Starry Night) اثر ونگوگ تبدیل کرد.. انتقال استایل همچنین به هوش مصنوعی امکان تولید آثار هنری را میدهد.

به عنوان نمونه، در یک مقاله مدلی ارائه شده است که با استفاده از یک چارچوب مبتنی بر (autoencoder)، قادر است سبکهای دلخواه و جدید را به صورت بلادرنگ (real-time) منتقل کند (درحالیکه زمان استنتاج در سایر رویکردها اغلب بسیار طولانیتر است).
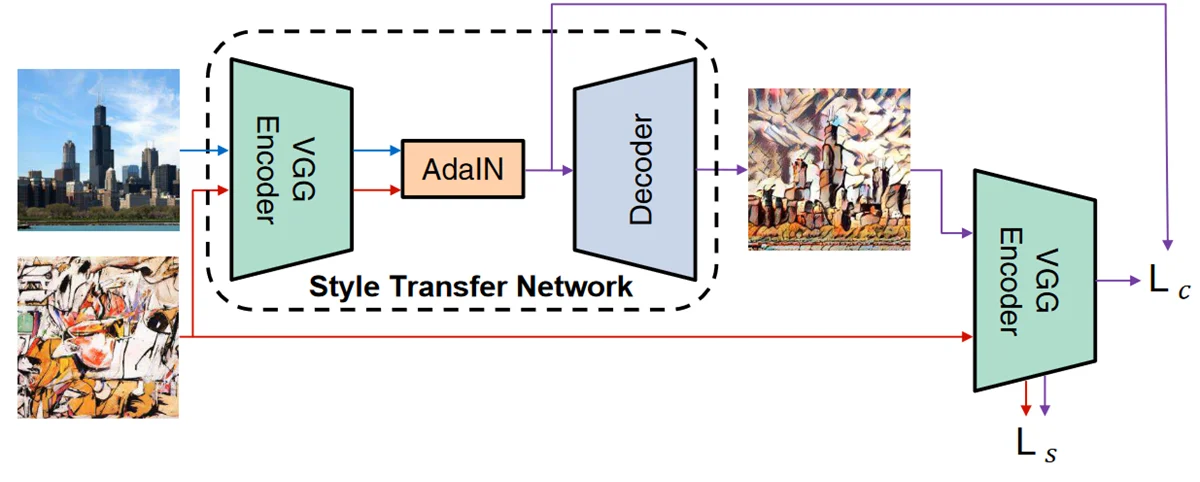
نویسندگان این مقاله، یک لایه نرمالسازی نمونه تطبیقی (Adaptive Instance Normalization) را پیشنهاد کردند. این لایه، میانگین (mean) و واریانس (variance) ورودی محتوا (تصویری که میخواهیم تغییر دهیم) را طوری تنظیم میکند که با میانگین و واریانس ورودی استایل (تصویری که میخواهیم سبک آن را تقلید کنیم) مطابقت داشته باشد.
خروجی لایه AdaIN سپس به فضای تصویر رمزگشایی (decode) وارد میشود تا تصویر نهایی با استایل منتقلشده به دست آید. نمای کلی این چارچوب در تصویر زیر نشان داده شده است.:
در ادامه، نمونههایی از تصاویری که به سبکهای هنری مختلف تبدیل شدهاند، نمایش داده شده و با بهترین و جدیدترین روشهای موجود (state-of-the-art) مقایسه شدهاند:

تولید تصویر (Image Generation)
تولید تصاویر جدید، یکی دیگر از وظایف مهم در پردازش تصویر است؛ به خصوص برای الگوریتمهای یادگیری عمیق که برای آموزش به مقادیر زیادی دادهی برچسبدار (labeled data) نیاز دارند.
روشهای تولید تصویر معمولاً از شبکههای مولد تخاصمی (Generative Adversarial Networks) استفاده میکنند که یک معماری منحصربهفرد در شبکههای عصبی محسوب میشود.
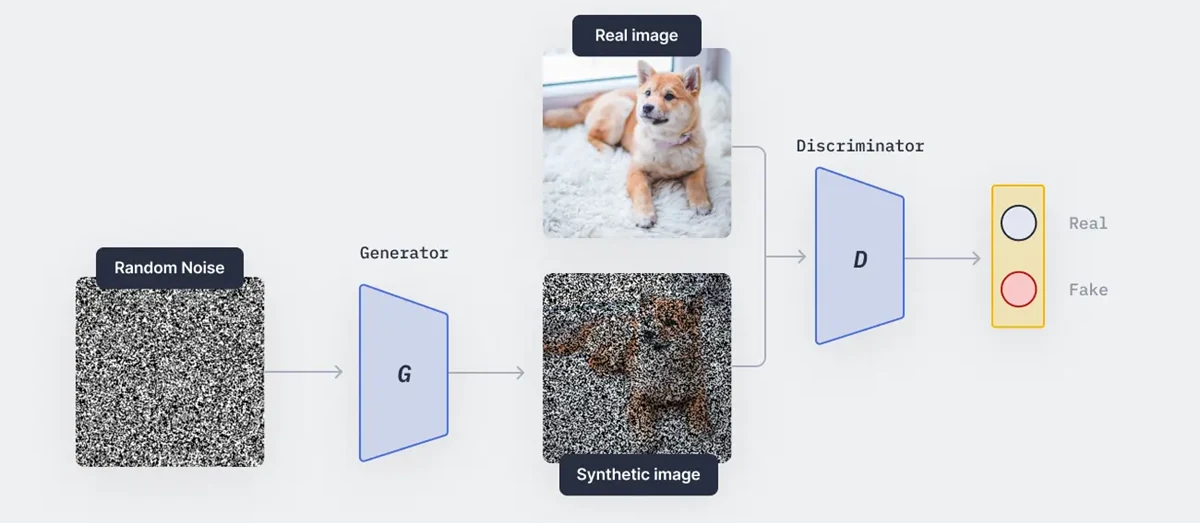
GAN ها از دو مدل مجزا تشکیل شدهاند:
مولد (Generator): وظیفهی آن تولید تصاویر مصنوعی (synthetic) است.
تمایزدهنده (Discriminator): تلاش میکند تصاویر مصنوعی را از تصاویر واقعی تشخیص دهد.
در طول فرآیند آموزش، مولد سعی میکند با ساختن تصاویر واقعگرایانهتر، تمایزدهنده را فریب دهد و در مقابل، تمایزدهنده نیز آموزش میبیند تا در تشخیص واقعی یا مصنوعی بودن یک تصویر بهتر عمل کند.
این بازی تخاصمی (adversarial game) باعث میشود که مولد پس از تکرارهای فراوان، قادر به تولید تصاویر بسیار واقعگرایانه (photo-realistic) شود که میتوان از آنها برای آموزش سایر مدلهای یادگیری عمیق استفاده کرد.
تبدیل تصویر به تصویر (Image-to-Image Translation)
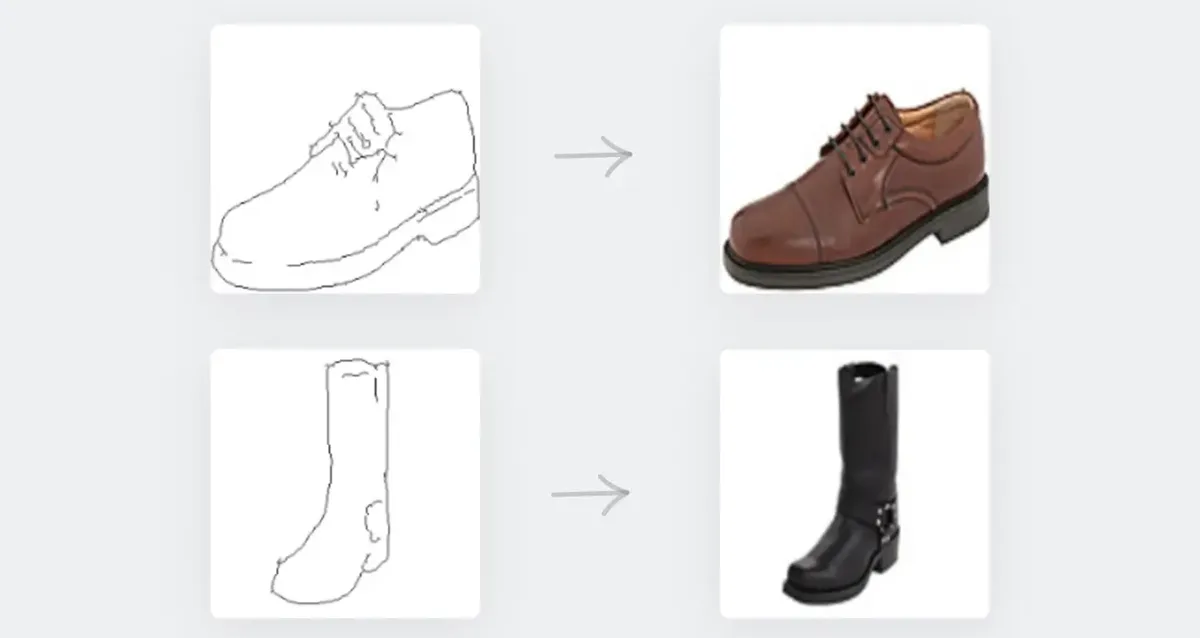
تبدیل تصویر به تصویر (Image-to-Image Translation)، دستهای از مسائل در حوزهی بینایی و گرافیک کامپیوت است که هدف آن، یادگیری نگاشت (mapping) بین یک تصویر ورودی و یک تصویر خروجی، با استفاده از یک مجموعه دادهی آموزشی از جفت تصاویر همتراز شده (aligned image pairs) است.
برای مثال، همانطور که در نمونهی زیر مشاهده میکنید، میتوان یک طرح دستی (sketch) را به عنوان ورودی به مدل داد و یک تصویر واقعگرایانه از شیء ترسیمشده را به عنوان خروجی دریافت کرد.
{تصویر}
Pix2pix یک مدل بسیار محبوب در حوزه تبدیل تصویر به تصویر (Image-to-Image Translation) است. این مدل با تکیه بر ساختار شبکه مولد تخاصمی شرطی (Conditional GAN)، برای وظایف عمومی ساخته شده است. این شبکه، مسائل مختلف پردازش تصویر را (مانند قطعه بندی معنایی (Semantic Segmentation) و تبدیل طرح به عکس) توسط یک ساختار واحد حل میکند. این رویکرد در شبکههای تخاصمی شرطی (cGANs) برای ترجمه تصویر به تصویر، بهعنوان یک مقاله پیشگام معرفی شد و مبنای تحول بزرگی در این حوزه گردید.
شبکه مولد تخاصمی شرطی (cGAN) شامل تولید شرطی (conditional generation) تصاویر توسط یک مدل مولد هستند. برای مثال، میتوان تولید تصویر را به یک برچسب کلاس (class label) خاص مشروط کرد تا تصاویری مختص همان کلاس تولید شوند.
مدل Pix2pix از یک مولد U-Net و یک تمایزدهنده PatchGAN تشکیل شده است. این تمایزدهنده برخلاف مدلهای GAN سنتی، تکههای N×N از تصویر را دریافت میکند تا پیشبینی کند که آن بخش واقعی است یا مصنوعی.
نویسندگان مقاله معتقدند که چنین تمایزدهندهای، قید و بندهای بیشتری را اعمال میکند که به تولید جزئیات واضح با فرکانس بالا (sharp high-frequency detail) کمک میکند.
در ادامه، نمونههایی از نتایج بهدستآمده توسط مدل pix2pix در وظایف و نقشه به تصویر نمایش داده شده است.

جمع بندی نهایی
در عصر انفجار دادههای بصری، دیگر روشهای کلاسیک پردازش تصویر توانایی تحلیل و مدیریت این حجم عظیم از اطلاعات را نداشتند. انقلاب Deep Learning در این حوزه، به واسطه دو معماری کلیدی رقم خورد:
شبکههای عصبی کانولوشن (CNN) با توانایی یادگیری خودکار ویژگیها، وظایف حیاتی مانند طبقهبندی، تشخیص شیء و بخشبندی را از سطح دستی و شکننده به سطح هوشمند و قابل اعتماد رساندند. در مقابل، شبکههای مولد متخاصم (GAN)، مرزهای خلاقیت ماشینی را جابجا کرده و تولید، ترمیم و تبدیل تصاویر کاملاً واقعگرایانه را امکانپذیر ساختند.
این مقاله، گذار از روشهای کلاسیک پردازش تصویر به دوران هوش مصنوعی مولد و تحلیلی را نشان داد. از معماری پیچیده لایههای کانولوشن در CNNها تا بازی دو نفره مولد و تمیزدهنده در GANها، این مدلهای پیشرفته اکنون زیربنای اصلی هرگونه پروژه جدی در بینایی کامپیوتر هستند.
برای درک عمیقتر مفاهیم پایه، مانند پیکسل، رزولوشن و مراحل سنتی، میتوانید مقاله پردازش تصویر چیست را مطالعه کنید. اگر به دنبال تسلط کامل بر این مباحث و پیادهسازی پروژههای واقعی با CNN و GAN هستید، دوره پردازش تصویر با پایتون مسیر جامع برای کسب تخصص در این حوزه است.




















