

آمار، زیربنای علم داده است. آمار توصیفی ابزارهای سادهای هستند که به ما در درک و خلاصه کردن دادهها کمک میکنند. آنها ویژگیهای اساسی یک مجموعه داده، مانند میانگین، بالاترین و پایینترین مقادیر و میزان پراکندگی اعداد را نشان میدهند. این اولین قدم در درک و معنا بخشیدن به اطلاعات است. برای تسلط بر این مفاهیم پایهای و یادگیری نحوه پیادهسازی آنها در پروژههای واقعی، شرکت در یک آموزش یادگیری ماشین و علم داده جامع، نقطه شروعی عالی خواهد بود.
آمار توصیفی، کلید درک دادهها در علم داده و هوش مصنوعی
آمار توصیفی در علم داده مانند یک لنز عمل میکند که تودهای از اعداد خام و گیجکننده را به تصویری شفاف و قابل فهم تبدیل مینماید. با استفاده از این ابزارها، ما میتوانیم به جای بررسی تکتک دادهها، ویژگیهای کلی و الگوهای پنهان در آنها را به سادگی شناسایی کنیم.
در واقع، این مفاهیم به متخصص علم داده میگویند که دادههای ما حول چه مقداری میچرخند، چقدر از هم فاصله دارند و با چه شکلی در کنار هم چیده شدهاند. بدون آمار توصیفی، تحلیلهای پیشرفتهتر و مدلسازیهای هوش مصنوعی عملاً غیرممکن خواهد بود.
آمار، زیربنای علم داده است. آمار توصیفی ابزارهای سادهای هستند که به ما در درک و خلاصه کردن دادهها کمک میکنند. آنها ویژگیهای اساسی یک مجموعه داده، مانند میانگین، بالاترین و پایینترین مقادیر و میزان پراکندگی اعداد را نشان میدهند. این اولین قدم در درک و معنا بخشیدن به اطلاعات است. برای تسلط بر این مفاهیم پایهای و درک بهتر پیشنیازهای ورود به این حوزه، استفاده از آموزش ریاضی هوش مصنوعی میتواند نقطه شروع بسیار مناسبی باشد.
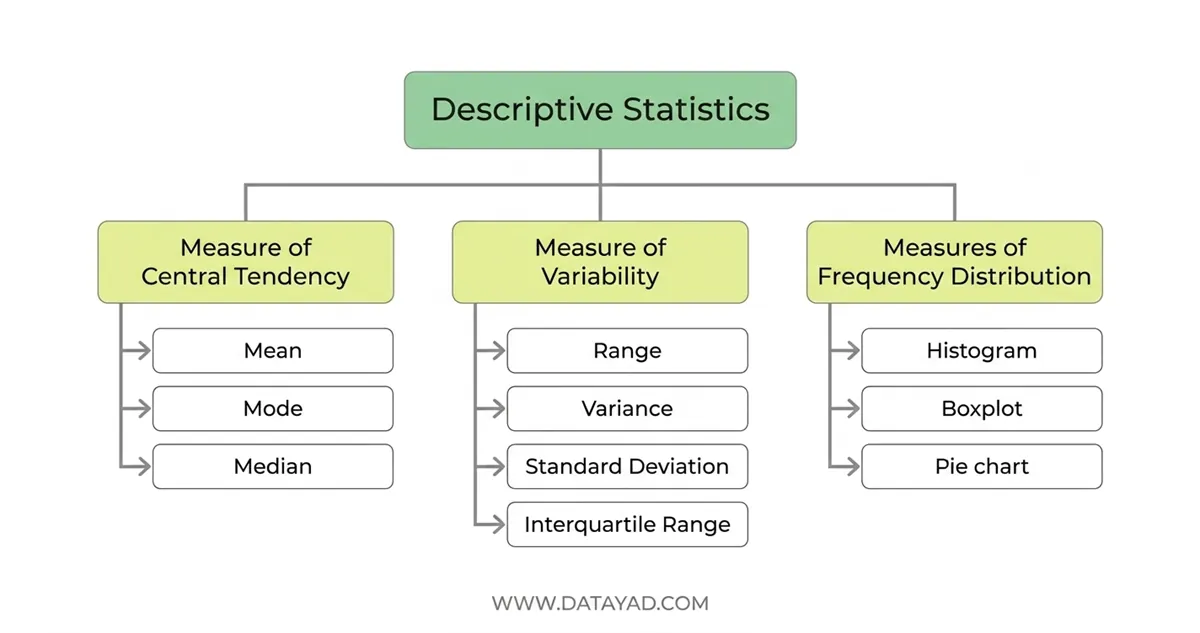
انواع آمار توصیفی
سه دستهبندی برای طبقهبندی استاندارد روشهای آمار توصیفی وجود دارد که هر کدام اهداف متفاوتی در خلاصهسازی و توصیف دادهها دنبال میکنند. آنها به ما کمک میکنند بفهمیم:
- دادهها کجا متمرکز شدهاند (شاخصهای گرایش به مرکز)
- دادهها چقدر پراکنده هستند (شاخصهای پراکندگی)
- دادهها چگونه توزیع شدهاند (شاخصهای توزیع فراوانی)
۱. شاخصهای گرایش به مرکز در آمار توصیفی
مقادیر آماری که موقعیت مرکزی را در یک مجموعه داده توصیف میکنند. سه شاخص اصلی برای گرایش به مرکز وجود دارد:
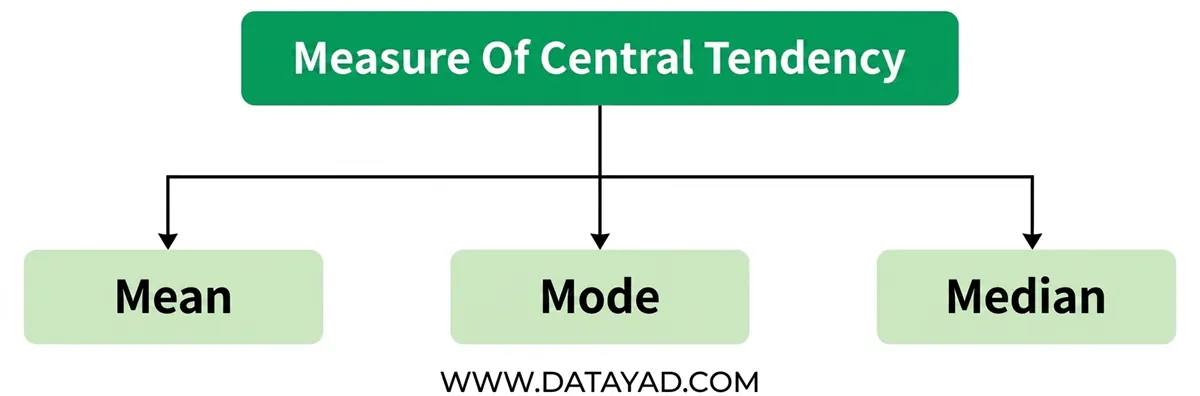
میانگین: مجموع مشاهدات تقسیم بر تعداد کل مشاهدات است. همچنین به عنوان متوسط تعریف میشود که همان تقسیم مجموع بر تعداد است.
![]()
که در آن،
- x = مشاهدات
- n = تعداد جملات
بیایید به مثالی از نحوه پیدا کردن میانگین یک مجموعه داده با استفاده از پیادهسازی کد پایتون نگاه کنیم. قبل از پیادهسازی، باید دانش پایهای در مورد numpy و scipy داشته باشیم.
import numpy as np
# Sample Data
arr = [5, 6, 11]
# Mean
mean = np.mean(arr)
print("Mean = ", mean)
Mode: مقداری که بیشترین تکرار را در مجموعه داده دارد. این شاخص برای دادههای کیفی و در مواردی که دانستن رایجترین انتخاب حیاتی است، مفید است.
import scipy.stats as stats
# sample Data
arr = [1, 2, 2, 3]
# Mode
mode = stats.mode(arr)
print("Mode = ", mode)
خروجی:
Mode = ModeResult(mode=array([2]), count=array([2]))
میانه: میانه مقدار میانی در یک مجموعه داده مرتب شده است. اگر تعداد مقادیر فرد باشد، مقدار مرکزی است و اگر زوج باشد، میانگین دو مقدار میانی است. میانه اغلب برای دادههای چولهدار بهتر از میانگین است.
import numpy as np
# sample Data
arr = [1, 2, 3, 4]
# Median
median = np.median(arr)
print("Median = ", median)
خروجی:
Median = 2.5
نکته: تمام پیادهسازیها با استفاده از کتابخانه numpy در پایتون انجام شده است. اگر میخواهید در این مورد بیشتر یاد بگیرید و بدانید، به لینک مراجعه کنید.
شاخصهای گرایش به مرکز، پایه و اساس درک توزیع دادهها و شناسایی ناهنجاریها هستند. به عنوان مثال، میانگین میتواند روندها را آشکار کند، در حالی که میانه توزیعهای چوله را برجسته میکند.
۲. شاخصهای پراکندگی در آمار توصیفی
دانستن اینکه دادهها نه تنها در کجا متمرکز شدهاند، بلکه چگونه پراکنده شدهاند نیز مهم است. شاخصهای پراکندگی، که شاخصهای انتشار نیز نامیده میشوند، به ما در شناسایی میزان گستردگی یا توزیع مشاهدات در یک مجموعه داده کمک میکنند. آنها در شناسایی دادههای پرت، ارزیابی مفروضات مدل و درک تغییرپذیری دادهها نسبت به میانگین مفید هستند. شاخصهای کلیدی پراکندگی عبارتند از:
۱. دامنه: تفاوت بین بزرگترین و کوچکترین نقطه داده را در مجموعه داده توصیف میکند. هرچه دامنه بزرگتر باشد، پراکندگی دادهها بیشتر است و برعکس. در حالی که محاسبه دامنه آسان است، نسبت به دادههای پرت حساس است. این شاخص میتواند حس سریعی از پراکندگی دادهها ارائه دهد اما باید با سایر آمارهها تکمیل شود.
Range = Largest data value - smallest data value
import numpy as np
# Sample Data
arr = [1, 2, 3, 4, 5]
# Finding Max
Maximum = max(arr)
# Finding Min
Minimum = min(arr)
# Difference Of Max and Min
Range = Maximum-Minimum
print("Maximum = {}, Minimum = {} and Range = {}".format(
Maximum, Minimum, Range))
خروجی:
Maximum = 5, Minimum = 1 and Range = 4
۲. واریانس: به عنوان میانگین مجذور انحراف از میانگین تعریف میشود. واریانس با پیدا کردن تفاوت بین هر نقطه داده و میانگین (که به عنوان متوسط نیز شناخته میشود)، به توان دو رساندن آنها، جمع کردن همه آنها و سپس تقسیم بر تعداد نقاط داده موجود در مجموعه داده محاسبه میشود.
![]()
که در آن،
- x -> مشاهده مورد نظر
- N -> تعداد جملات
- μ -> میانگین
import statistics
# sample data
arr = [1, 2, 3, 4, 5]
# variance
print("Var = ", (statistics.variance(arr)))
خروجی:
Var = 2.5
۳. انحراف معیار: انحراف معیار اندازهگیری میکند که مقادیر داده چقدر از میانگین تفاوت دارند. این شاخص بهطور گسترده در آمار و یادگیری ماشین برای درک پراکندگی دادهها و عملکرد مدل استفاده میشود.
- به عنوان جذر واریانس تعریف میشود.
- انحراف معیار پایین به معنای نزدیک بودن مقادیر به میانگین است.
- انحراف معیار بالا نشاندهنده تغییرات بیشتر در مجموعه داده است.
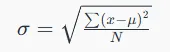
که در آن،
- x = مشاهده مورد نظر
- N = تعداد جملات
- μ = میانگین
import statistics
arr = [1, 2, 3, 4, 5]
print("Std = ", (statistics.stdev(arr)))
خروجی:
Std = 1.5811388300841898
شاخصهای پراکندگی در تحلیل باقیماندهها برای بررسی میزان برازش یک مدل با دادهها مهم هستند.
۳. شاخصهای توزیع فراوانی در آمار توصیفی
جدول توزیع فراوانی روشی خلاصهشده برای نشان دادن نحوه توزیع نقاط داده در دستهها یا فواصل مختلف است. این کار به شناسایی الگوها، دادههای پرت و ساختار کلی مجموعه داده کمک میکند. معمولاً اولین قدم در درک مجموعه داده قبل از اعمال روشهای تحلیلی پیشرفتهتر یا ایجاد بصریسازیهایی مانند هیستوگرام یا نمودارهای دایرهای است.
جدول توزیع فراوانی شامل مواردی مانند زیر است:
- فواصل یا دستههای داده
- شمارش فراوانی
- فراوانیهای نسبی (درصدها)
- فراوانیهای تجمعی در صورت نیاز
سوالات متداول در مورد آمار توصیفی
تفاوت اصلی میانگین و میانه چیست؟
میانگین مجموع مقادیر تقسیم بر تعداد آنهاست و به دادههای پرت بسیار حساس است؛ اما میانه مقدار میانی در یک لیست مرتبشده است و برای توزیعهای نامتقارن تصویر دقیقتری ارائه میدهد.
چرا انحراف معیار از واریانس محبوبتر است؟
زیرا واحد انحراف معیار با واحد دادههای اصلی یکسان است (به دلیل جذر گرفتن)، که درک و تفسیر آن را برای تحلیلگران بسیار سادهتر از واریانس (که واحد مجذور دارد) میکند.
چه زمانی از Mode استفاده میکنیم؟
Mode بیشتر برای دادههای کیفی (مانند رنگ یا نام شهرها) و شناسایی رایجترین الگو در یک مجموعه داده استفاده میشود، جایی که میانگین و میانه کارایی ندارند.
آیا آمار توصیفی برای پیشبینی آینده کافی است؟
خیر، آمار توصیفی فقط وضعیت موجود دادهها را خلاصه و توصیف میکند. برای پیشبینی و نتیجهگیریهای آماری، باید از آمار استنباطی (Inferential Statistics) استفاده کرد.
مسیر تخصص در علم داده
تسلط بر آمار توصیفی و کار با کتابخانههای پایتون، اولین گام حیاتی برای ورود به دنیای شگفتانگیز دادههاست؛ اما برای تبدیل شدن به یک متخصص که میتواند از دل اعداد، استراتژیهای پولساز و مدلهای هوشمند استخراج کند، باید دیدگاهی جامعتر پیدا کنید. مسیر پیش روی شما از تحلیلهای پایه آغاز شده و به مدلسازیهای پیچیده یادگیری ماشین و هوش مصنوعی ختم میشود که نیازمند یک نقشه راه اصولی و پروژهمحور است.
برای اینکه این مفاهیم تئوریک را به مهارتهای عملیاتی و پولساز تبدیل کنید، ما آموزش یادگیری ماشین و علم داده را فراهم کردهایم که شما را از سطح صفر به یک تحلیلگر و مدلساز ارشد تبدیل میکند. در این راه، نه تنها بر آمار و ریاضیات، بلکه بر تمامی ابزارهای مدرن صنعت علم داده مسلط خواهید شد.
- آموزش صفر تا صد پایتون، آمار کاربردی و یادگیری ماشین برای حل مسائل واقعی
- اجرای پروژههای عملی جهت آمادگی کامل برای ورود به بازار کار داخلی و بینالمللی




















