

شبکههای عصبی آگاه از فیزیک یا Physics‑Informed Neural Networks (PINNs) در سالهای اخیر توجه زیادی را در حوزه یادگیری ماشین و مدلسازی سیستمهای فیزیکی جلب کردهاند. این روشها بهویژه در شرایطی که داده کمی در اختیار داریم بسیار ارزشمند هستند، زیرا علاوه بر دادهها، از دانش فیزیکی موجود در قالب معادلات دیفرانسیل نیز برای آموزش مدل استفاده میکنند.
در بسیاری از مسائل دنیای واقعی، جمعآوری داده میتواند پرهزینه یا حتی غیرممکن باشد. در چنین شرایطی اگر بتوانیم قوانین فیزیکی شناختهشده درباره یک پدیده را در فرآیند یادگیری شبکه عصبی وارد کنیم، مدل میتواند با داده کمتر نیز رفتار سیستم را بهخوبی یاد بگیرد.
در این مطلب از بخش آموزش هوش مصنوعی، تلاش میکنیم ابتدا مفهوم PINN را بهصورت شهودی توضیح دهیم و سپس یک پیادهسازی ساده با PyTorch ارائه کنیم. بسیاری از مثالهای موجود در اینترنت یا با TensorFlow نوشته شدهاند یا بیش از حد پیچیده هستند، بنابراین هدف این مقاله ارائه یک مثال ساده و قابل فهم است.
نویسنده در این مقاله فرض میکند که خواننده با شبکههای عصبی، نمادگذاری ریاضی و مفاهیم پایه حساب دیفرانسیل آشنایی دارد.
شبکههای عصبی آگاه از فیزیک (PINNs) چیست و چرا اهمیت دارند؟
شبکههای عصبی آگاه از فیزیک یا PINNs نوعی مدل یادگیری عمیق در هوش مصنوعی هستند که علاوه بر دادههای آموزشی، از قوانین فیزیکی مانند معادلات دیفرانسیل نیز برای آموزش استفاده میکنند. این رویکرد بهویژه زمانی مفید است که داده کم، پرهزینه یا نویزی باشد. مزیت اصلی PINN این است که مدل را وادار میکند علاوه بر برازش داده، با رفتار واقعی سیستم فیزیکی نیز سازگار بماند.
به زبان ساده، اگر بدانیم یک پدیده از چه قانون فیزیکی پیروی میکند، میتوانیم آن قانون را وارد تابع خطای شبکه کنیم تا مدل با داده کمتر، پیشبینی بهتری داشته باشد.
شبکههای عصبی راهحل جادویی برای همه مسائل نیستند
فکر نمیکنم لازم باشد توضیح بدهم که شبکههای عصبی تا چه اندازه برای دنیای امروز اهمیت دارند. برای مثال ChatGPT در واقع یک شبکه عصبی بسیار بزرگ با میلیاردها پارامتر است. چارچوب یادگیری عمیق در یادگیری وابستگیها میان دادهها بسیار قدرتمند است و به عنوان تقریبزننده عمومی توابع (Universal Function Approximator) انعطافپذیری بسیار بالایی دارد.
با این حال، بزرگترین نقطه قوت آنها در عین حال بزرگترین ضعفشان نیز هست. از آنجا که شبکههای عصبی در تقریب توابع بسیار خوب عمل میکنند، به همان اندازه نیز در بیشبرازش (Overfitting) روی دادههای آموزشی مهارت دارند. به همین دلیل، برای اینکه بتوانند بهخوبی تعمیمپذیری (Generalisation) داشته باشند و صرفاً دادههای آموزش را حفظ نکنند، به مقدار زیادی داده نیاز دارند و معمولاً از تکنیکهایی مانند Batching نیز استفاده میشود.
در بسیاری از حوزهها جمعآوری داده کار بسیار دشواری است و این مسئله برای بسیاری از مهندسان یادگیری ماشین (از جمله نویسنده مقاله) دردسر بزرگی ایجاد میکند. زمانی که داده کافی وجود نداشته باشد، استفاده از مدلهای پیچیدهای مثل شبکههای عصبی میتواند خطرناک باشد، زیرا احتمال دارد مدل روی همان مقدار کم داده بیشبرازش پیدا کند و در نتیجه نتوان عملکرد آن را بهدرستی ارزیابی کرد.
یکی از روشهای رایج برای جلوگیری از بیشبرازش Regularization (منظمسازی) است. همانطور که در رگرسیون خطی از منظمسازی استفاده میشود، در شبکههای عصبی نیز میتوان همین کار را انجام داد.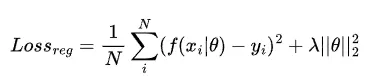
با کوچک نگه داشتن وزنها مطمئن میشویم که هیچ وزنی مقدار بسیار بزرگی نگیرد و در نتیجه تابع بهدستآمده شکل غیرعادی یا پیچیدهای نداشته باشد. این کار کمک میکند مدل بدون اینکه «ظاهر بدی» پیدا کند، دادهها را بهتر برازش دهد.
در مثال ارائهشده در مقاله، نویسنده دادههایی را با استفاده از یک معادله درجه دوم به همراه نویز تولید کرده است. سپس ویژگیهای چندجملهای ساخته و یک مدل رگرسیون خطی با و بدون Regularization روی دادهها آموزش داده است.
در نمودار مشاهده میشود که وقتی Regularization وجود ندارد، مدل رفتار بسیار عجیب و ناپایداری پیدا میکند. حتی در این مثال ساده نیز میبینیم که بیشبرازش باعث میشود مدل به محض خروج از محدوده دادههای آموزشی، پیشبینیهای غیرقابل اعتمادی ارائه دهد.
تئوری شبکههای عصبی آگاه از فیزیک (PINNs)
در چارچوب معرفیشده، پیشدانستههای مبتنی بر فیزیک (Physics‑informed priors) روشی برای منظمسازی (Regularization) شبکههای عصبی هستند، البته در سطحی پیشرفتهتر. ایده اصلی این است که به شبکه عصبی کمک کنیم تا شکل صحیح تابع را یاد بگیرد.
برای رسیدن به این هدف، اطلاعات فیزیکی را در قالب یک معادله دیفرانسیل درون شبکه قرار میدهیم. زمانی که دادههای کمی در اختیار داریم، توانایی اضافه کردن اطلاعاتی که از جنس «داده» نیستند اما از دانش فیزیکی بهدست آمدهاند، میتواند بسیار قدرتمند باشد.
اما چگونه این اطلاعات را وارد شبکه میکنیم؟
پاسخ این است که دقیقاً مشابه کاری که در Regularization انجام میدهیم: یعنی با اضافه کردن آن به تابع هزینه (Loss Function).
سادهترین روش این است که میانگین مربعات خطا (Mean Squared Error) را برای معادلهای که دادهها را توصیف میکند محاسبه کنیم.
فرض کنید یک معادله دیفرانسیل به شکل زیر داریم:
g(x, y) = 0
همچنین مجموعهای از دادهها داریم:
{x_j , y_j}
و یک شبکه عصبی داریم:
f(x | θ)
که مقدار y را تقریب میزند.
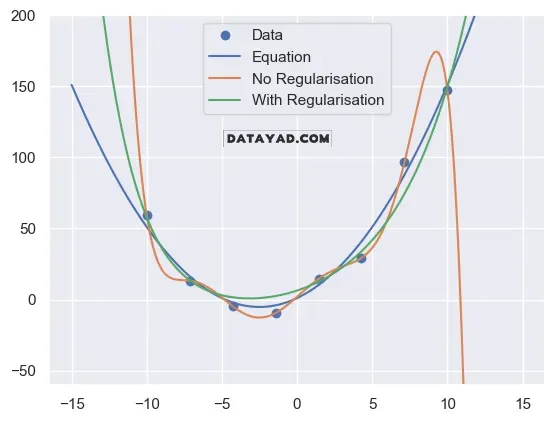
در چارچوب Physics‑Informed Neural Networks، تابع هزینه به شکل زیر تعریف میشود:
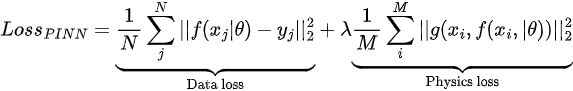
این تابع هزینه معمولاً از دو بخش تشکیل میشود:
- خطای دادهها (Data Loss)
- خطای معادله فیزیکی (Physics Loss)
در این فرمول:
مقادیر x_i به عنوان نقاط هممکانی (Collocation Points) شناخته میشوند.
این نقاط میتوانند هر مقداری داشته باشند، اما معمولاً در بازهای انتخاب میشوند که به آن علاقه داریم.
مقادیر x_j و y_j همان دادههای واقعی مشاهدهشده هستند.
همچنین میتوان یک پارامتر برای کنترل نسبت اهمیت این دو بخش از تابع هزینه تعریف کرد. در مقاله این پارامتر با نماد λ (lambda) نشان داده شده است.
این پارامتر مشخص میکند:
چه مقدار از آموزش شبکه باید به برازش دادهها توجه کند
و چه مقدار باید قوانین فیزیکی را رعایت کند
پس از تعریف این تابع هزینه، میتوان شبکه را دقیقاً مانند هر شبکه عصبی معمولی آموزش داد.
چند نکته مهم (Some caveats)
چارچوب PINN نیازمند وجود یک معادله یا رابطه فیزیکی مرتبط با دادهها است. در بسیاری از مجموعهدادهها چنین دانشی وجود ندارد. برای مثال در مسائل رایجی مانند برچسبگذاری تصاویر (Image Labelling) معمولاً رابطه دقیقی میان ورودی و خروجی که بتوان آن را با یک معادله فیزیکی بیان کرد وجود ندارد.
به همین دلیل این روش عمدتاً برای دادههایی استفاده میشود که پدیدههای فیزیکی واقعی را اندازهگیری میکنند.
چنین دادههایی معمولاً دو ویژگی دارند:
- اغلب دارای نویز هستند
- جمعآوری آنها دشوار و پرهزینه است
جالب اینجاست که هر دو مشکل تا حدی با استفاده از PINNها قابل مدیریت هستند.
نکته مهم دیگر این است که نشان داده شده اگر معادلات دیفرانسیل بسیار پیچیده در این چارچوب استفاده شوند، ممکن است فرایند بهینهسازی پارامترهای شبکه عصبی سختتر شود. دلیل آن این است که منظر تابع هزینه (Loss Landscape) بسیار ناهموار یا اصطلاحاً «پر از برآمدگی» میشود و در نتیجه روشهای بهینهسازی مبتنی بر گرادیان نزولی (Gradient Descent) ممکن است در نقاط نامناسب گیر کنند.
مثال: سرد شدن یک فنجان قهوه (Example: a cooling coffee cup)
فرض کنید من دادههایی از یک فرآیند فیزیکی در اختیار دارم. برای سادگی، مثال را با یک فنجان قهوه که در حال سرد شدن است در نظر میگیریم. این پدیده از یک قانون ساده فیزیکی پیروی میکند. این قانون همان قانون سرد شدن نیوتن (Newton’s Law of Cooling) است که تغییرات دما در طول زمان را توصیف میکند.
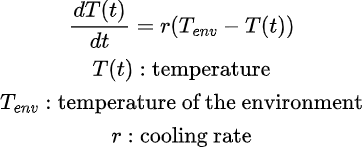
در این مثال فرض میکنیم قهوهای که ابتدا بسیار داغ بوده است، طی حدود ۱۵ دقیقه در حال سرد شدن است و دمای محیط خانه ۲۵ درجه سانتیگراد است. همچنین برای نرخ سرد شدن (cooling rate) مقدار 0.005 در نظر گرفته میشود. ما نمیدانیم قهوه دقیقاً چه زمانی به دمای محیط میرسد، اما نمیخواهیم منتظر بمانیم تا این اتفاق بیفتد.
بنابراین ابتدا بررسی میکنیم که این فرآیند چه شکلی دارد. برای این کار، این معادله را رسم میکنیم و از آن دادههای آموزشی میسازیم. در این مثال، ۱۰ نقطه داده در ۵ دقیقه اول تولید میکنیم تا به عنوان دادههای آموزش استفاده شوند.
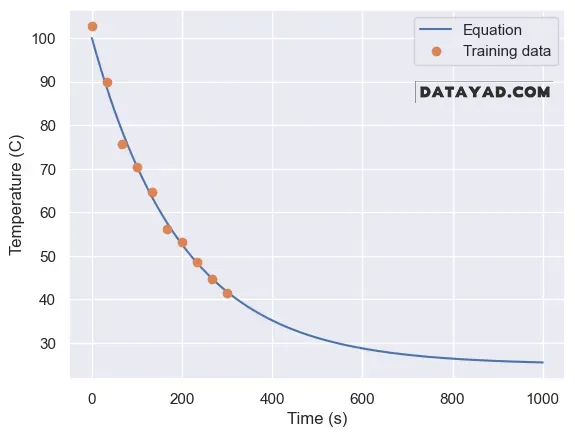
در نمودار مربوطه:
- محور افقی زمان است
- محور عمودی دمای قهوه است
- نقاط داده در واقع اندازهگیریهای نویزی دما هستند
آموزش یک شبکه عصبی معمولی
حالا یک شبکه خطی ساده با تابع فعالسازی ReLU را روی این دادهها آموزش میدهیم. سپس همین کار را با یک شبکه دارای Regularization از نوع L2 انجام میدهیم. نتیجه جالب است.
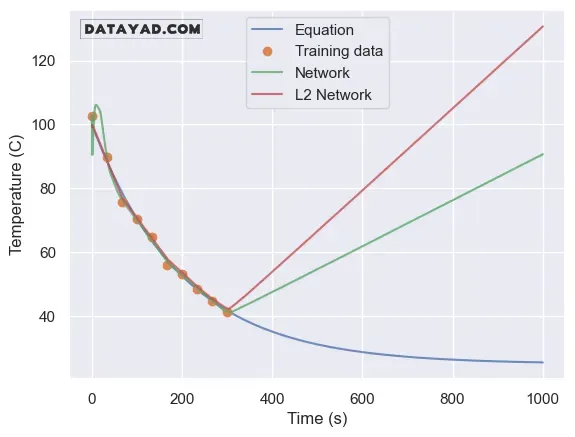
هر دو شبکه وقتی از محدوده دادههای آموزشی خارج میشویم، کاملاً نادرست عمل میکنند. این موضوع کاملاً قابل انتظار است، زیرا شبکهها هیچ اطلاعاتی خارج از دادههای آموزشی ندارند.
همچنین در شبکه بدون Regularization رفتارهای عجیبتری دیده میشود، بهخصوص در فاصله بین اولین و دومین نقطه داده.
بیایید به جای آن یک شبکههای عصبی آگاه از فیزیک بسازیم
فرض کنید یک شبکه عصبی داریم:
f(t | θ)
که دمای فنجان قهوه T را بر اساس زمان t پیشبینی میکند.
در این صورت میتوانیم یک physics loss برای دادهها تعریف کنیم که از معادله فیزیکی سیستم به دست میآید.
ممکن است برای برخی این سؤال پیش بیاید که در عمل چگونه مشتق شبکه عصبی را محاسبه میکنیم.
در PyTorch این کار بسیار ساده است، زیرا ماژول torch.autograd تابعی به نام grad() دارد که دقیقاً همین کار را انجام میدهد. حتی میتوان با آن مشتقهای مرتبه بالاتر نیز محاسبه کرد.
فقط باید مطمئن شویم که گزینه create_graph=True فعال باشد تا یک گراف محاسباتی جدید ساخته شود.
کد زیر نحوه پیادهسازی این موضوع را نشان میدهد:
def grad(outputs, inputs):
"""Computes the partial derivative of
an output with respect to an input."""
return torch.autograd.grad(
outputs,
inputs,
grad_outputs=torch.ones_like(outputs),
create_graph=True
)
def physics_loss(model: torch.nn.Module):
"""The physics loss of the model"""
# make collocation points
ts = torch.linspace(0, 1000, steps=1000,).view(-1,1).requires_grad_(True)
# run the collocation points through the network
temps = model(ts)
# get the gradient
dT = grad(temps, ts)[0]
# compute the ODE
ode = dT - R*(Tenv - temps)
# MSE of ODE
return torch.mean(ode**2)
در اینجا:
- ابتدا collocation points ساخته میشوند
- این نقاط به شبکه داده میشوند
- مشتق دما نسبت به زمان محاسبه میشود
- سپس معادله دیفرانسیل بررسی میشود
- و در نهایت MSE معادله به عنوان physics loss محاسبه میشود
- در مقاله، شبکه با ۱۰۰۰ collocation point آموزش داده شده است.
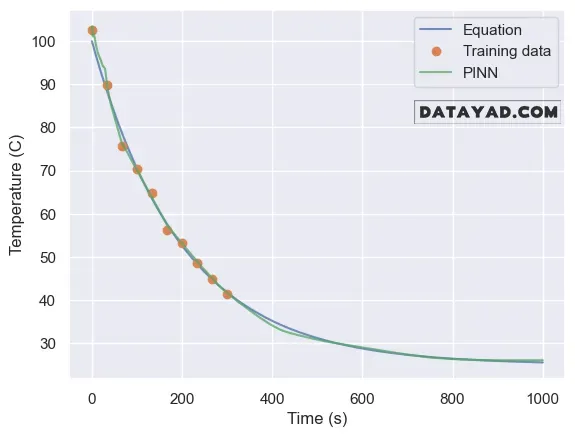
نتیجه بسیار جالب است. مدل توانسته دمای قهوه را حتی خارج از محدوده دادههای آموزشی نیز بهدرستی پیشبینی کند.
آیا واقعاً اینقدر شگفتانگیز است؟
ممکن است برخی متوجه شده باشند که در این مثال کمی «تقلب» وجود دارد. در واقع ما فرم دقیق معادله فیزیکی را به شبکه دادهایم. بنابراین خودمان هم میتوانستیم این معادله را مستقیماً حل کنیم.
معادلهای که در این مثال استفاده شده یک معادله دیفرانسیل بسیار ساده است. با استفاده از جداسازی متغیرها (Separation of Variables) و اعمال شرایط مرزی میتوان آن را حل کرد.
![]()
در نتیجه به تابعی میرسیم که دمای قهوه را بر حسب زمان توصیف میکند.
پس سؤال پیش میآید: اگر میتوانیم معادله را مستقیم حل کنیم، چرا اصلاً از شبکه عصبی استفاده کنیم؟
پاسخ این است که این مثال صرفاً یک مثال آموزشی ساده (toy example) است. در اینجا معادله دیفرانسیل تمام ورودیها و خروجیهایی را که به آنها علاقه داریم، کاملاً توصیف میکند.
اما در بسیاری از مسائل واقعی:
شبکه ممکن است به شکل
y = f(t, x | θ)
و معادله فیزیکی به شکل
g(t, y) = 0
باشد.
در این حالت، معادله دیفرانسیل تمام دادهها را توضیح نمیدهد و شبکه عصبی برای یادگیری روابط پیچیدهتر مورد نیاز است.
این مثال فقط برای سادگی و درک مفهوم PINN انتخاب شده است، نه به دلیل کاربرد عملی مستقیم آن.
افزودن انعطافپذیری: استفاده از شبکههای عصبی آگاه از فیزیک برای کشف معادله
واقعیت این است که جهان بیرون بهندرت دقیقاً مطابق فیزیک ایدهآل رفتار میکند. معادلهای که در این مثال استفاده شده، بسیار سادهسازیشده است، چون بسیاری از اثرات دیگر را در نظر نمیگیرد. برای مثال، نرخ سرد شدن قهوه تحت تأثیر ضخامت و جنس لیوان نیز قرار میگیرد.
حالا فرض کنید یکی از پارامترهای معادله دیفرانسیل ما ناشناخته باشد. در این مثال، نویسنده نرخ سرد شدن را انتخاب میکند؛ همان پارامتری که اندازهگیری آن سختتر است.
در این حالت، معادله دیفرانسیل ما به این صورت در نظر گرفته میشود:
g(t, T | r) = 0
که در آن r ناشناخته است.
نویسنده توضیح میدهد که به لطف PyTorch فقط یک تغییر کوچک لازم است:
باید r را بهعنوان یک پارامتر قابل مشتقگیری (differentiable parameter) به مدل اضافه کنیم.
این کار بسیار ساده است. کافی است این متغیر را در بخش مقداردهی اولیه شبکه تعریف کنیم تا PyTorch بقیه کارها را انجام دهد. همچنین باید physics loss را هم متناسب با این تغییر اصلاح کنیم.
کد مقاله دقیقاً به این صورت است:
class Net(nn.Module):
def __init__(self, *args):
...
# make r a differentiable parameter included in self.parameters()
self.r = nn.Parameter(data=torch.tensor([0.]))
...
def physics_loss_discovery(model: torch.nn.Module):
ts = torch.linspace(0, 1000, steps=1000,).view(-1,1).requires_grad_(True).to(DEVICE)
temps = model(ts)
dT = grad(temps, ts)[0]
# use the differentiable parameter instead
pde = model.r * (Tenv - temps) - dT
return torch.mean(pde**2)
در این پیادهسازی:
- پارامتر r مستقیماً داخل مدل تعریف شده است
- این پارامتر بهصورت خودکار در self.parameters() قرار میگیرد
- بنابراین در فرایند آموزش، همراه با وزنها و بایاسهای شبکه، بهینهسازی میشود
- در تابع physics_loss_discovery نیز بهجای مقدار ثابت نرخ سرد شدن، از model.r استفاده میشود
نتیجه جالب است:
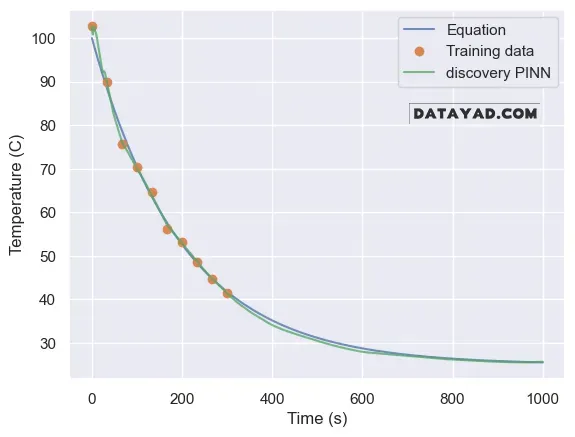
شبکه با شروع از مقدار 0.0 برای پارامتر r، در نهایت مقدار 0.0051 را برای نرخ سرد شدن پیدا میکند.
این در حالی است که مقدار واقعی برابر با 0.0050 بوده است.
بنابراین، حتی با فقط ۱۰ نقطه داده، مدل توانسته به مقدار واقعی بسیار نزدیک شود.
نویسنده تأکید میکند که این ویژگی میتواند در برخورد با سیستمهای فیزیکی واقعی بسیار مفید باشد؛ مخصوصاً زمانی که:
- روابط کلی بین متغیرها را میدانیم
- اما مقدار دقیق بعضی از پارامترها را نمیدانیم
سوالات متداول در مورد شبکههای عصبی آگاه از فیزیک
شبکههای عصبی آگاه از فیزیک (PINNs) چیست؟
PINNها نوعی شبکه عصبی هستند که علاوه بر دادههای آموزشی، از قوانین فیزیکی مانند معادلات دیفرانسیل نیز در فرایند آموزش استفاده میکنند. این کار باعث میشود مدل با داده کمتر هم بتواند رفتار سیستم را بهتر یاد بگیرد.
PINNها در چه مسائلی کاربرد دارند؟
PINNها بیشتر در مسائلی کاربرد دارند که با سیستمهای فیزیکی واقعی سروکار داریم؛ مانند انتقال حرارت، دینامیک سیالات، مکانیک، مدلسازی فرآیندهای مهندسی و مسائل مبتنی بر معادلات دیفرانسیل.
مزیت PINN نسبت به شبکه عصبی معمولی چیست؟
مهمترین مزیت PINN این است که مدل را فقط به داده محدود نمیکند، بلکه دانش فیزیکی را هم وارد آموزش میکند. به همین دلیل در شرایط کمبود داده یا وجود نویز، معمولاً عملکرد بهتری نسبت به مدلهای معمولی دارد.
آیا برای استفاده از PINN باید معادله فیزیکی دقیق سیستم را بدانیم؟
در بسیاری از کاربردها بله، اما همیشه لازم نیست همه پارامترها دقیقاً مشخص باشند. یکی از قابلیتهای مهم PINN این است که میتواند بعضی پارامترهای ناشناخته معادله را نیز از روی دادهها تخمین بزند.
آیا PINNها همیشه بهترین انتخاب هستند؟
خیر. اگر داده بسیار زیاد و باکیفیت در دسترس باشد، ممکن است مدلهای معمولی هم عملکرد خوبی داشته باشند. PINNها بیشتر زمانی ارزشمند هستند که داده کم باشد اما دانش فیزیکی خوبی از مسئله داشته باشیم.
چگونه PINN را در PyTorch پیادهسازی کنیم؟
در PyTorch معمولاً با تعریف یک شبکه عصبی، محاسبه مشتق خروجی نسبت به ورودی با torch.autograd و اضافه کردن physics loss به data loss میتوان یک PINN ساده پیادهسازی کرد.
Physics Loss در PINN چیست؟
Physics Loss بخشی از تابع خطاست که میزان پایبندی خروجی شبکه به معادله فیزیکی مسئله را اندازهگیرد. این بخش در کنار خطای دادهها، شبکه را به یادگیری پاسخهای سازگار با فیزیک هدایت میکند.
جمعبندی
PINNها روشی برای منظمسازی شبکه عصبی هستند، البته به شرطی که درباره نحوه تعامل برخی از ورودیها و خروجیها دانشی داشته باشیم.
در سناریوهایی که داده کمی در دسترس است، اما در عوض دانش پیشینی درباره دادهها وجود دارد، این روش میتواند برای یادگیری سایر وابستگیهای موجود در داده بسیار مفید باشد.
نویسنده در پایان تأکید میکند که اگر حجم بسیار زیادی از داده در اختیار داشته باشیم، دیگر این موضوع چندان تعیینکننده نیست، چون در آن حالت وابستگیها در خود دادهها نهفته هستند و شبکه عصبی در نهایت آنها را یاد خواهد گرفت.




















