

امروزه، در دنیایی که حجم دادهها بهصورت تصاعدی در حال رشد است، سازمانها برای تصمیم گیریهای استراتژیک و کسب مزیت رقابتی، بیش از هر زمان دیگری به ابزاری برای استخراج دانش و ارزش از این اقیانوس اطلاعات نیاز دارند. علم داده (Data Science) پاسخی جامع به این نیاز حیاتی است.
این حوزه هیجانانگیز، که در هسته خود ترکیبی از آمار، برنامهنویسی، و دانش کسبوکار است، با استفاده از تکنیکهای پیشرفته داده کاوی (Data Mining)، دادههای خام را به اطلاعات معنادار تبدیل میکند. در واقع، علم داده پلی است میان دادههای خام و خروجیهای معنادار، که بخش عظیمی از موفقیت آن مدیون پیادهسازی الگوریتمهای یادگیری ماشین (Machine Learning)، از جمله تکنیکهای پیشرفته یادگیری عمیق (Deep Learning)، در بستر هوش مصنوعی (Artificial Intelligence) است.
حوزه دیتا ساینس نه تنها به شرکتها کمک میکند تا عملکرد فعلی خود را تحلیل کنند، بلکه توانایی مدلسازی پیش بینانه، کشف الگوهای پنهان و بهینه سازی فرایندها را نیز فراهم میآورد. به همین دلیل، موقعیت شغلی یک متخصص علم داده توسط مؤسسه معتبر هاروارد بیزینس ریویو به عنوان «جذابترین شغل قرن بیست و یک» شناخته شده است.
در این مقاله جامع از دیتایاد، ما به صورت گام به گام بررسی میکنیم که علم داده چیست، چه کاربردها، ابزارها و فرآیندهایی (مانند گردآوری، پاکسازی و تحلیل داده) دارد و مسیر شغلی موفق در این حوزه رو به رشد چگونه ترسیم میشود.
اگر به دنبال یادگیری عملی این حوزه هستید، پیشنهاد میکنیم دوره آموزش علم داده را ببینید.

علم داده (Data Science) چیست؟
برای درک عمیقتر این حوزه، باید بدانیم که دیتا ساینس یک قلمرو چند رشتهای است.
علم داده (Data Science) یک رشته نوظهور و مجموعهای از اصول، فرآیندها و روشهای علمی است که با ترکیب دانش آمار و احتمال، برنامه نویسی و علوم کامپیوتر و تخصص حوزه کسب و کار (Domain Knowledge)، از مجموعه داده های حجیم (شامل دادههای ساختاریافته و بدون ساختار) برای استخراج دانش، کشف الگوهای پنهان و ساخت مدلهای پیشبینانه و تجویزی استفاده میکند.
هدف نهایی دانشمند داده، تبدیل دادههای خام به بینشهای عملی (Actionable Insights) است تا سازمانها بتوانند تصمیمات داده محور بگیرند، فرایندها را بهینه سازی کنند و در نهایت، ارزش تجاری خلق نمایند.
چرا علم داده مهم است؟
اهمیت علم داده تنها در تحلیل دادهها خلاصه نمیشود، بلکه در توانایی آن برای تبدیل دادههای خام به ارزشهای ملموس تجاری و بینشهای عملیاتی نهفته است. در عصر رقابتی امروز، شرکتی موفق است که بتواند سریعتر و دقیقتر از رقبای خود، تصمیمات هوشمندانه بگیرد.
اهمیت علم داده در چهار محور اصلی زیر خلاصه میشود:
۱. پیشبینی و آینده نگری (Predictive Power)
علم داده به سازمانها این امکان را میدهد که از تحلیلهای توصیفی (Descriptive) (بررسی گذشته) عبور کرده و وارد تحلیلهای پیش گویانه (Predictive) و تجویزی (Prescriptive) شوند.
- پیشبینی فروش: تخمین میزان تقاضای مشتریان در فصول یا دورههای آینده.
- تشخیص تقلب: شناسایی الگوهای غیرعادی در تراکنشهای مالی قبل از وقوع خسارت.
- نگهداری پیشگیرانه: پیشبینی زمان احتمالی خرابی تجهیزات صنعتی و انجام تعمیرات پیش از توقف تولید.
۲. بهینهسازی فرایندها و افزایش کارایی
دانشمند داده میتواند با مدلسازی، نقاط ضعف و گلوگاههای عملیاتی را کشف کرده و فرایندها را خودکار و بهینه سازد.
- مدیریت زنجیره تأمین: بهینهسازی موجودی انبارها و زمانبندی ارسال کالاها برای کاهش هزینههای لجستیکی.
- بهبود تجربه مشتری (CX): استفاده از یادگیری ماشین برای خودکارسازی بخشهای پشتیبانی مشتری (مانند چتباتها) و افزایش سرعت پاسخگویی.
۳. شخصیسازی و بازاریابی هدفمند (Personalization)
بزرگترین ارزش علم داده درک عمیق رفتار تکتک مشتریان است.
- سیستمهای توصیهگر: ارائه پیشنهادهای محصول (مانند آمازون و نتفلیکس) که مستقیماً منجر به افزایش فروش میشود.
- ارتباطات شخصی: ارسال پیامها و تبلیغات متناسب با نیاز، سابقه خرید و ترجیحات هر کاربر.
۴. نوآوری و خلق محصول جدید
علم داده بستر خلق محصولات کاملاً جدید مبتنی بر داده را فراهم میکند که در گذشته غیرممکن بودند. از هوش مصنوعی در خودروهای خودران و تشخیصهای پزشکی پیشرفته گرفته تا موتورهای جستجوی هوشمند، همگی محصول کاربرد علم داده و هوش مصنوعی در حجم عظیم دادهها هستند.

تاریخچه علم داده (Data Science)
اصطلاح “علم داده” نسبتاً جدید است، اما مفاهیم بنیادین آن ریشههای عمیقی در قرن بیستم، بهویژه در علم آمار و علوم کامپیوتر دارد. تکامل علم داده را میتوان در سه دوره اصلی بررسی کرد:
۱. ریشههای آماری (دهه ۱۹۶۰ تا ۱۹۷۰)
- تولد اصطلاح: اصطلاح «علم داده» برای اولین بار در دهه ۱۹۶۰ توسط پیتر نور (Peter Naur)، بهعنوان نام جایگزینی برای علم آمار مطرح شد.
- تمرکز: در آن زمان، تمرکز عمدتاً بر تحلیل دادههای آماری، جمع آوری ساختاریافته دادهها و طبقه بندی بود. علم داده در این دوره، بهعنوان یک زیرمجموعه از آمار با تمرکز بر دادههای حجیمتر شناخته میشد.
۲. ظهور فناوری و تمایز (دهه ۱۹۹۰ تا ۲۰۰۰)
- انفجار دادهها: با ظهور اینترنت و افزایش تواناییهای ذخیرهسازی، دادههای دیجیتال بهصورت تصاعدی رشد کردند. این امر، نیاز به ابزارهایی فراتر از آمار سنتی را ایجاد کرد.
- تعریف رسمی: در اواخر دهه ۱۹۹۰، متخصصان علوم کامپیوتر علم داده را به طور رسمی بهعنوان یک رشته مستقل تعریف کردند. آنها این حوزه را با چهار جنبه اصلی از آمار مجزا دانستند: طراحی، جمعآوری، ذخیرهسازی و تحلیل دادهها.
۳. عصر دادههای بزرگ و یادگیری ماشین (Big Data ) (قرن ۲۱ تا امروز)
- میانرشتگی کامل: با ظهور کلان داده ها (Big Data) و پیشرفتهای چشمگیر در حوزه یادگیری ماشین (Machine Learning) و هوش مصنوعی، علم داده به نقطه اوج خود رسید.
- استفاده در صنعت: این حوزه از فضاهای آکادمیک خارج شده و تبدیل به یک ابزار استراتژیک در تمام صنایع (از تجارت الکترونیک گرفته تا پزشکی) شد و برای پیشبینی دقیق و تصمیم گیریهای مبتنی بر شواهد به کار گرفته شد.
- تخصصهای جدید: ظهور تخصصهایی مانند مهندسی داده (Data Engineering) و تحلیلگری داده (Data Analytics)، مرزهای علم داده را به مرزهای امروزی آن گسترش داد.

آینده علم داده (Data Science)
علم داده به دلیل همگرایی با پیشرفتهای حوزه هوش مصنوعی (AI) و نیاز فزاینده کسب و کارها به تصمیم گیری های آنی، یکی از سریعترین حوزههای در حال رشد باقی خواهد ماند. آینده علم داده نه تنها گستردهتر، بلکه تخصصیتر و اخلاقیتر خواهد شد:
۱. هوش مصنوعی توضیفپذیر (Explainable AI – XAI)
همچنان که الگوریتم های یادگیری ماشین پیچیدهتر میشوند، نیاز به درک و اعتماد به نتایج آنها نیز افزایش مییابد. آینده علم داده با تمرکز بر XAI تعریف خواهد شد؛ یعنی توسعه ابزارها و تکنیکهایی که به دانشمندان داده کمک میکنند تا نحوه عملکرد، منطق و دلایل پیشبینیهای مدلها را برای کاربران غیرمتخصص توضیح دهند. این موضوع برای صنایع حساس مانند مالی و پزشکی بسیار حیاتی است.
۲. یادگیری ماشین خودکار (AutoML)
ابزارهای AutoML به دانشمندان داده این امکان را میدهند که بخشهای تکراری فرآیند علم داده (مانند مهندسی ویژگی یا انتخاب مدل) را به طور خودکار انجام دهند. این امر کارایی را بهشدت بالا برده و به متخصصان داده اجازه میدهد تا زمان بیشتری را صرف تعریف مسئله کسب و کار و ارتباط نتایج کنند.
۳. حکمرانی داده و اخلاق در داده (Data Ethics & Governance)
با افزایش نگرانیها در مورد حریم خصوصی، تعصبات الگوریتمی و مقرراتی مانند GDPR، نقش دانشمند داده با تمرکز بیشتری بر مسائل اخلاقی و انطباق قانونی همراه خواهد شد. آینده علم داده، متخصصانی را میطلبد که نه تنها مدل بسازند، بلکه از استفاده منصفانه و بدون تبعیض از دادهها اطمینان حاصل کنند.
۴. فراتر از دادههای بزرگ: دادههای آنی و لبه (Real-time and Edge Computing)
تقاضا برای تحلیل دادههای آنی (Real-time) (مانند دادههای حسگرها یا ترافیک وب) افزایش خواهد یافت. همچنین، ظهور محاسبات لبه (Edge Computing) به این معنی است که مدلهای یادگیری ماشین به جای سرورهای مرکزی، مستقیماً بر روی دستگاهها (مانند خودروهای خودران یا ابزارهای IOT) اجرا خواهند شد.
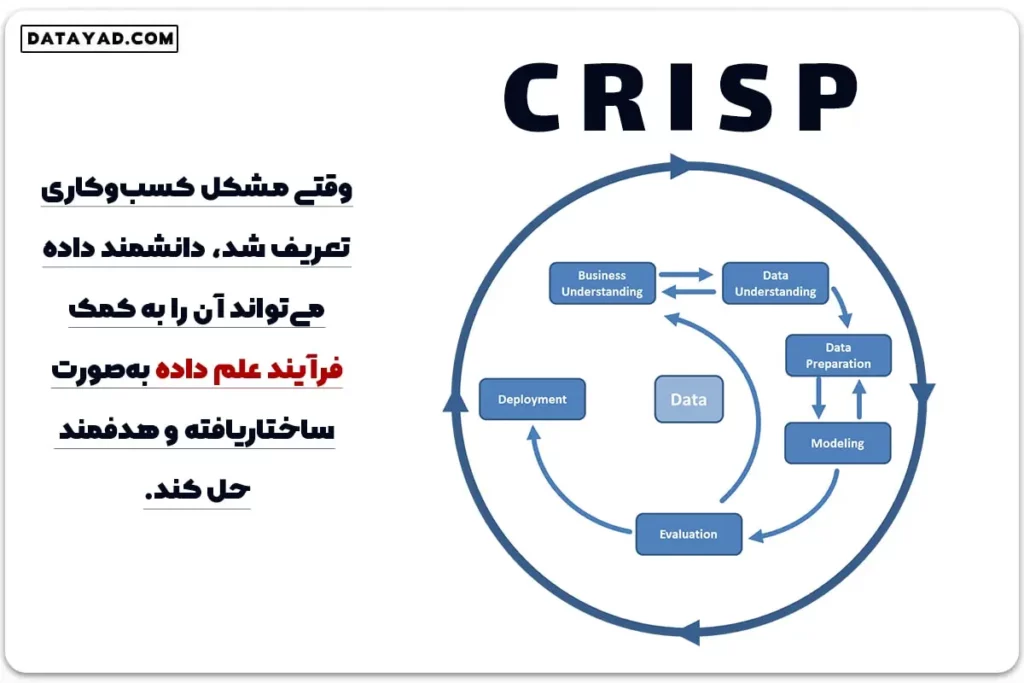
چرخه حیات علم داده: فرآیند گام به گام (CRISP-DM)
علم داده یک فرآیند تکرار شونده و ساختاریافته است که دانشمندان داده برای حل مسائل کسب و کار و استخراج دانش از دادهها از آن پیروی میکنند. متداولترین فریمورک مورد استفاده در صنعت، مدل فرآیند کاوی متقابل برای دادهکاوی (CRISP-DM) است که شامل شش مرحله اصلی زیر است:
۱. درک کسب و کار (Business Understanding)
این مرحله با همکاری نزدیک با مدیران کسب و کار آغاز میشود. هدف اصلی، درک دقیق مسئله، تعیین اهداف پروژه از منظر تجاری و تعریف معیارهای موفقیت است. در اینجا، سؤالات کلیدی (مثلاً: «آیا میتوانیم ریزش مشتری را پیشبینی کنیم؟») به اهداف قابل اندازهگیری دادهمحور تبدیل میشوند.
۲. درک دادهها (Data Understanding)
در این مرحله، منابع داده شناسایی، جمعآوری و بررسی میشوند. دانشمند داده به ارزیابی کیفیت دادهها، شناسایی مشکلات احتمالی (مانند مقادیر گمشده یا دادههای پرت)، و انجام تحلیلهای توصیفی (Descriptive Analytics) اولیه برای درک ساختار و ماهیت مجموعه داده میپردازد.
۳. آمادهسازی دادهها (Data Preparation)
این مرحله وقتگیرترین بخش فرآیند علم داده است که اغلب ۸۰٪ زمان پروژه را به خود اختصاص میدهد. وظایف اصلی شامل:
- پاکسازی (Cleaning): رفع ناسازگاریها، مدیریت مقادیر گمشده و اصلاح خطاهای داده.
- ترکیب (Integration): ادغام دادهها از منابع مختلف در یک مجموعه واحد.
- مهندسی ویژگی (Feature Engineering): تبدیل دادههای خام به متغیرهایی (Features) که برای مدلسازی مناسب و مفید هستند (مثلاً ساخت یک ستون جدید از نسبت دو ستون قدیمی).
۴. مدلسازی (Modeling)
در این مرحله، الگوریتمهای یادگیری ماشین یا روشهای آماری مناسب برای حل مسئله کسب و کار انتخاب میشوند. با توجه به ماهیت دادهها و هدف (پیشبینی یا دسته بندی)، مدلهای مختلفی (مانند رگرسیون، شبکههای عصبی یا خوشه بندی) توسعه داده شده و پارامترهای آنها تنظیم میشوند تا بهترین عملکرد ممکن به دست آید.
۵. ارزیابی (Evaluation)
پس از ساخت مدل، عملکرد آن با استفاده از معیارهای مشخص ارزیابی میشود. دانشمند داده نه تنها دقت فنی مدل (مثلاً امتیاز F1 یا RMSE) را بررسی میکند، بلکه تأثیر و پاسخگویی مدل به اهداف اولیه کسب و کار (مرحله اول) را نیز میسنجد. آیا مدل به اندازه کافی قابل اعتماد است که وارد محیط واقعی شود؟
۶. استقرار و نظارت مستمر (Deployment & Continuous Monitoring)
این مرحله نهایی برای ایجاد ارزش واقعی در کسب و کار است. مدل ساخته شده و تأیید شده، وارد محیط عملیاتی کسب و کار میشود (مثلاً، یک مدل پیش بینی در سیستمهای اصلی شرکت فعال میشود). اما کار به اینجا ختم نمیشود؛ نظارت و بهبود مداوم پس از استقرار، حیاتی است.
توضیح نظارت: مدلها ممکن است با تغییر رفتار مشتریان یا شرایط بازار، با گذشت زمان دچار افت عملکرد (Model Drift) شوند. بنابراین، دانشمند داده باید به طور مستمر بر عملکرد مدل در محیط واقعی نظارت داشته باشد و در صورت لزوم، آن را بازآموزی (Retraining) یا با دادههای جدید بهروزرسانی کند تا دقت آن حفظ شود.
اهمیت MLOps در استقرار: در پروژههای مقیاس بزرگ، فرآیند استقرار و نظارت توسط مفاهیم MLOps (عملیات یادگیری ماشین) مدیریت میشود. MLOps به دنبال ایجاد یک رویکرد اتوماتیک و استاندارد برای مدیریت چرخه حیات مدلها است؛ شامل تست خودکار، استقرار خودکار و پایش عملکرد در لحظه (Real-time Monitoring). این رویکرد به تیمها اجازه میدهد تا مدلها را سریعتر و با پایداری بیشتری به روزرسانی کنند، که یک ضرورت برای حفظ دقت در محیطهای دائماً در حال تغییر است.
ابزارها و فناوریهای کلیدی در دیتا ساینس
موفقیت در علم داده مستلزم تسلط بر ابزارهای قدرتمندی است که فرآیند تبدیل داده به بینش را تسهیل میکنند. این ابزارها از زبانهای برنامهنویسی اولیه تا فریمورکهای تخصصی یادگیری عمیق را در بر میگیرند و انتخاب درست آنها میتواند مرز بین یک پروژه موفق و یک شکست محاسباتی باشد.
زبانهای برنامهنویسی: پایتون در مقابل R
میدان نبرد اصلی در ابزارهای علم داده، بین دو زبان برنامهنویسی قدرتمند تقسیم شده است:
- پایتون (Python): به دلیل سادگی، خوانایی و اکوسیستم فوق العاده غنی کتابخانههایش، امروزه استاندارد صنعت در نظر گرفته میشود. پایتون به واسطه ابزارهایی مانند Pandas (برای دستکاری داده)، NumPy (برای محاسبات عددی) و Scikit-learn (برای یادگیری ماشین کلاسیک)، تقریباً در تمام مراحل پروژه (از پاکسازی داده تا استقرار مدل) استفاده میشود.
- R: این زبان بیشتر در محیطهای آکادمیک و تحلیلهای آماری پیشرفته محبوبیت دارد. R با بستههایی مانند ggplot2 برای تجسم دادهها، قابلیتهای آماری عمیقتری ارائه میدهد، اما در زمینه مهندسی نرمافزار و ادغام با سیستمهای تولیدی بزرگ، معمولاً ضعیفتر از پایتون عمل میکند.
فریمورکهای یادگیری ماشین و یادگیری عمیق
برای اجرای مدلسازیهای پیچیده، به خصوص در حوزههای هوش مصنوعی و کار با دادههای غیرساختاریافته (مانند تصویر و متن)، فریمورکهای زیر نقش حیاتی دارند:
- Scikit-learn: کتابخانه مرجع برای پیادهسازی سریع الگوریتمهای یادگیری ماشین کلاسیک (مانند رگرسیون، خوشهبندی و طبقهبندی) در پایتون است.
- TensorFlow و PyTorch: این دو فریمورک قدرتمند، ستون فقرات یادگیری عمیق (Deep Learning) هستند. آنها امکان ساخت شبکههای عصبی پیچیده و مقیاسپذیر را فراهم میکنند و در حال حاضر نیروی محرکه اصلی در حوزههایی مانند بینایی کامپیوتر و پردازش زبان طبیعی هستند.
ابزارهای مدیریت و پردازش Big Data
زمانی که حجم دادهها از ظرفیت یک کامپیوتر فراتر میرود، به ابزارهای پردازش توزیعشده نیاز است:
- Apache Spark: یک موتور تحلیلی سریع و چندمنظوره برای پردازش دادههای توزیعشده است که میتواند حجم عظیمی از دادهها را با سرعت بالا و به صورت موازی پردازش کند و به عنوان جانشین مدرن Hadoop شناخته میشود.
- ابزارهای ابری (Cloud Services): پلتفرمهایی مانند AWS SageMaker، Google Cloud AI Platform و Azure Machine Learning ابزارهای مدیریت داده، مدلسازی و استقرار در مقیاس ابری را فراهم میکنند و روند کار با بیگ دیتا را به شکل چشمگیری آسان کردهاند.
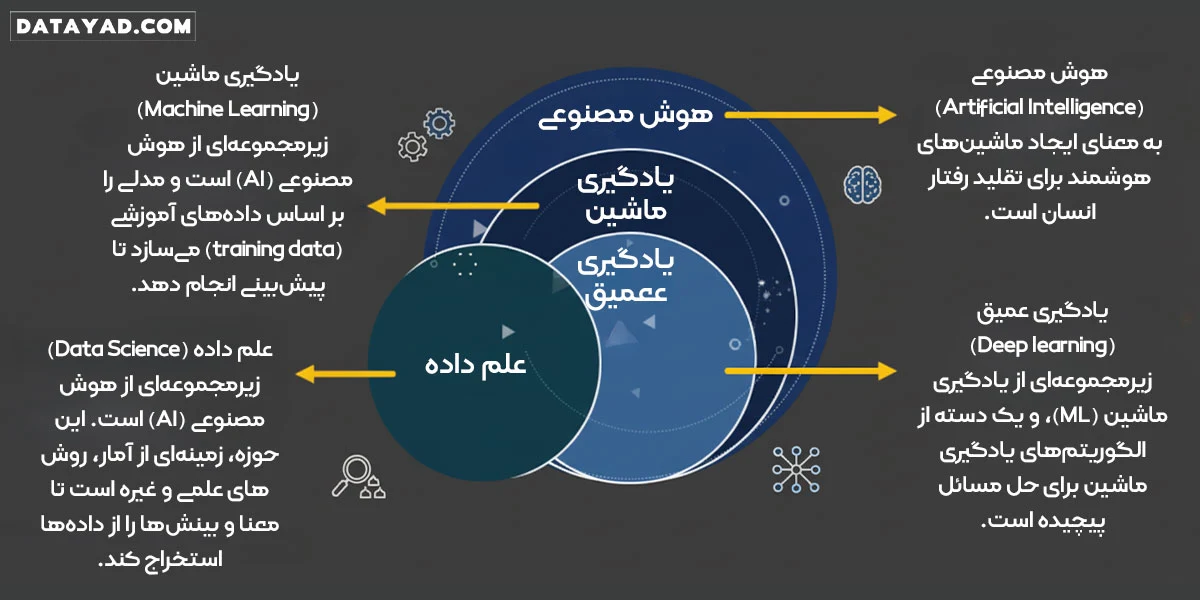
ارتباط و تفاوت علم داده با هوش مصنوعی و یادگیری عمیق
گرچه مفاهیم علم داده (Data Science)، هوش مصنوعی (AI) و یادگیری ماشین (ML) اغلب به جای یکدیگر استفاده میشوند، اما در واقعیت، دارای تفاوتهای واضح و روابط ساختاری مشخصی هستند. درک این سلسله مراتب برای هر متخصص یا علاقهمند به این حوزه ضروری است:
هوش مصنوعی (AI): چتر اصلی
هوش مصنوعی یک مفهوم بزرگ و جامع است که هدف آن ایجاد سیستمهایی با توانایی شبیهسازی هوش انسانی (مانند توانایی استدلال، یادگیری یا حل مسئله) است. علم داده و یادگیری ماشین، زیرمجموعههای فنی هستند که به AI اجازه میدهند تا هدف خود را محقق کند. در واقع، AI مانند یک آرزوست که توسط ML و DS به واقعیت میپیوندد.
یادگیری ماشین (ML): قلب تحلیل داده
یادگیری ماشین زیرمجموعهای از AI است که الگوریتمهایی برای یادگیری الگوها از دادهها و انجام پیشبینیها بدون برنامهنویسی صریح استفاده میکند. یادگیری ماشین در واقع ابزار اصلی علم داده برای استخراج دانش و ساخت مدلهای پیشبینی کننده است. این همان موتور تحلیل است که در چرخه حیات علم داده (فاز مدلسازی) استفاده میشود.
دیتا ساینس: فرآیند کاربردی
علم داده یک رشته میانرشتهای و کاربردی است که از ابزارها و تکنیکهای ML، آمار، برنامهنویسی و دانش تجاری برای حل مسائل پیچیده استفاده میکند. تمرکز آن بر کل فرآیند (از تعریف مسئله تجاری تا استقرار مدل) است، نه صرفاً ساخت الگوریتم.
یادگیری عمیق (Deep Learning): قدرت بالا در زیر مجموعه ML
دیپ لرنینگ زیرمجموعهای تخصصیتر از ماشین لرنینگ است که از شبکههای عصبی عمیق برای تحلیل استفاده میکند. این حوزه برای حل مسائل بسیار پیچیده مانند تشخیص تصویر، پردازش زبان های طبیعی (NLP) و ساخت مدلهای مولد (Generative)، که به مقادیر عظیم داده و قدرت محاسباتی بالا نیاز دارند، استفاده میشود و یکی از پیشرفتهترین ابزارهای موجود در جعبه ابزار متخصص علم داده (Data Scientist) است.
در نهایت، تفاوت اصلی در دامنه و هدف هر رشته نهفته است:
- هدف علم داده: یافتن پاسخ از دادهها و حل مسئله کسبوکار (با هر ابزاری، حتی آمار سنتی).
- هدف یادگیری ماشین: ساخت مدلهایی که از دادهها یاد میگیرند و پیشبینی میکنند.
- هدف هوش مصنوعی: ساخت ماشینهایی که هوشمندانه رفتار میکنند.

روشهای علم داده در مطالعه دادهها: از توصیف تا تجویز
دانشمندان داده برای استخراج بینشهای معنادار، از یک طیف وسیع از روشها و رویکردهای آماری و محاسباتی استفاده میکنند. این روشها را میتوان در دو سطح اصلی دسته بندی کرد: سطح تحلیل (برای پاسخگویی به پرسشهای کسب و کار) و سطح یادگیری (برای ساخت مدلهای پیشبینانه).
۱. دسته بندی بر اساس نوع تحلیل (Analytics Taxonomy)
روشهای علم داده معمولاً برای پاسخ به چهار نوع اصلی از سؤالات کسب و کار به کار میروند:
| نوع تحلیل | هدف اصلی | پاسخ به سؤال: |
| توصیفی (Descriptive) | توصیف وضعیت گذشته و حال |
چه اتفاقی افتاده است؟ (مثلاً: میانگین فروش ماه گذشته چقدر بود؟)
|
| تشخیصی (Diagnostic) | درک علت یک اتفاق |
چرا این اتفاق افتاد؟ (مثلاً: چرا فروش نسبت به ماه قبل کاهش یافته است؟)
|
| پیشگویانه (Predictive) | پیشبینی رویدادهای آینده |
چه اتفاقی خواهد افتاد؟ (مثلاً: آیا این مشتری در سال آینده ریزش خواهد کرد؟)
|
| تجویزی (Prescriptive) | توصیه بهترین اقدام |
برای بهینهسازی نتیجه، چه کاری باید انجام دهیم؟ (مثلاً: بهترین قیمت یا دوز دارو برای این بیمار چیست؟)
|
۲. دسته بندی بر اساس نوع یادگیری (Machine Learning Methods)
هستهی اصلی روشهای علم داده، الگوریتمهای یادگیری ماشین (Machine Learning) هستند که بر اساس نحوه آموزش مدلها، به سه دسته اصلی تقسیم میشوند:
الف) یادگیری نظارت شده (Supervised Learning)
مدل با استفاده از دادههای برچسبدار (Labeled Data) آموزش میبیند؛ یعنی دادههایی که خروجی صحیح آنها از پیش مشخص شده است.
- تکنیکهای کلیدی: رگرسیون (Regression) (برای پیشبینی مقادیر پیوسته مانند دما یا قیمت) و دسته بندی (Classification) (برای پیشبینی یک برچسب گسسته مانند “بیمار” یا “سالم”). در این حوزه، الگوریتمهایی مانند رگرسیون لجستیک (Logistic Regression)، درخت تصمیم (Decision Trees) و ماشین بردار پشتیبان (SVM) کاربرد فراوان دارند.
ب) یادگیری بدون نظارت (Unsupervised Learning)
مدل با استفاده از دادههای بدون برچسب آموزش میبیند و هدف آن کشف ساختارها و الگوهای پنهان در دادهها بدون داشتن خروجی مشخص است.
- تکنیکهای کلیدی: خوشه بندی (Clustering) (برای تقسیم مشتریان به گروههای مشابه) و کاهش ابعاد (Dimensionality Reduction).
ج) یادگیری تقویتی (Reinforcement Learning)
مدل از طریق تعامل با محیط آموزش میبیند. سیستم (Agent) با انجام عمل و دریافت پاداش یا جریمه، یاد میگیرد که بهترین تصمیم را در شرایط مختلف بگیرد.
- کاربرد اصلی: رباتیک، بازیهای پیچیده و سیستمهای کنترل خودکار.
تحلیلهای علت و معلول پیشبینیکننده (Causal Prediction)
مدلهای پیشبینیکننده معمولاً به سؤال “چه اتفاقی خواهد افتاد؟” پاسخ میدهند، اما تحلیلهای علت و معلول، یک گام فراتر میروند و به سؤال “اگر ما X را انجام دهیم، چه اتفاقی خواهد افتاد؟” پاسخ میدهند. این تحلیلها به سازمانها اجازه میدهند تا تأثیر تغییرات را قبل از اجرا، شبیهسازی کنند.
۱. مدلسازی علت و معلول (Causal Modeling)
در این رویکرد، دانشمند داده تلاش میکند تا رابطه علی (Causal) را بین متغیرها (به جای همبستگی صرف) پیدا کند. این مدلها به سازمانها کمک میکنند بفهمند کدام اقدام به کدام نتیجه مطلوب یا نامطلوب منجر خواهد شد.
- مثال: اگر مقدار سرمایهگذاری در کمپین بازاریابی را ۵۰٪ افزایش دهیم، سود ما چقدر افزایش پیدا میکند؟
۲. آزمون A/B و روشهای تجویزی (A/B Testing & Prescriptive)
معتبرترین راه برای اثبات یک رابطه علت و معلولی، استفاده از روشهای تجویزی است.
- آزمون A/B: این تکنیک به شرکتها امکان میدهد که نسخههای مختلفی از یک متغیر (مانند دکمه خرید در وبسایت) را به طور همزمان برای دو گروه از کاربران آزمایش کنند تا تأثیر مستقیم تغییرات را بر رفتار کاربر (مانند نرخ کلیک یا خرید) مشاهده کنند.
- تصمیم گیری بهینه: بر اساس یافتههای علت و معلولی، مدلهای تجویزی میتوانند بهترین اقدام (مانند بهترین قیمت یا بهترین زمان تماس با مشتری) را به صورت خودکار پیشنهاد دهند.

کاربردهای علم داده (Data Science)
نفوذ علم داده در تمام جنبههای کسب و کار و زندگی روزمره، آن را به یک ابزار استراتژیک تبدیل کرده است. در اینجا، برخی از مهمترین کاربردهای علم داده در صنایع مختلف را مرور میکنیم:
۱. صنعت مالی و بانکداری (Financial Services)
- تشخیص تقلب (Fraud Detection): بانکها با استفاده از الگوریتمهای دسته بندی (Classification) و یادگیری بدون نظارت، میتوانند تراکنشهای غیرعادی و مشکوک را در لحظه تشخیص داده و از خسارتهای مالی جلوگیری کنند.
- ارزیابی ریسک اعتباری: مدلهای پیشبینی، احتمال نکول (بازپرداخت نکردن وام) یک مشتری را بر اساس دهها متغیر تعیین میکنند و به بانکها اجازه میدهند تصمیمات سریعتر و امنتری بگیرند.
- تحلیل بازارهای مالی و سرمایهگذاری: در کنار استفادههای سنتی مانند ارزیابی ریسک اعتباری و تشخیص تقلب، علم داده نقشی حیاتی در پیشبینی حرکت قیمت سهام و سایر داراییها ایفا میکند. با استفاده از سریهای زمانی (Time Series) و مدلهای پیچیده یادگیری ماشین، متخصصان میتوانند استراتژیهای معاملاتی الگوریتمی (Algo-Trading) را توسعه دهند که در کسری از ثانیه تصمیمگیری میکنند. برای جزئیات بیشتر درباره چگونگی بهکارگیری این علم در دنیای بازهای مالی و تریدینگ، به مقاله علم داده در بازارهای مالی مراجعه کنید.
۲. تجارت الکترونیک و بازاریابی (E-Commerce & Marketing)
- سیستم های توصیهگر (Recommendation Systems): این سیستمها با استفاده از فیلترینگ مشارکتی یا روشهای مبتنی بر محتوا، محصولاتی را به مشتریان پیشنهاد میدهند که احتمال خرید بالاتری دارند (مانند آمازون یا دیجیکالا). این امر مستقیماً نرخ تبدیل و فروش را افزایش میدهد.
- بخش بندی مشتریان (Customer Segmentation): استفاده از تکنیک خوشه بندی (Clustering) برای گروه بندی مشتریان بر اساس رفتار خرید، امکان طراحی کمپینهای بازاریابی بسیار هدفمند را فراهم میآورد.
۳. پزشکی و سلامت (Healthcare)
- تشخیص بیماری: مدلهای یادگیری عمیق (Deep Learning) قادرند تصاویر پزشکی (مانند اشعه ایکس و MRI) را با دقتی گاهی بالاتر از پزشکان تحلیل کرده و به تشخیص زودهنگام بیماریهایی مانند سرطان کمک کنند.
- کشف دارو: علم داده با تحلیل مجموعه دادههای ژنومی و شیمیایی، سرعت و کارایی فرآیند کشف و توسعه داروهای جدید را بهشدت افزایش میدهد.
۴. حمل و نقل و لجستیک (Logistics & Transportation)
- بهینه سازی مسیر: الگوریتمها برای یافتن سریعترین و بهینهترین مسیرهای تحویل، مصرف سوخت و زمان رسیدن به مقصد را کاهش میدهند.
- خودروهای خودران: هسته اصلی این فناوریها، مدلهای بینایی کامپیوتر (Computer Vision) و یادگیری تقویتی (Reinforcement Learning) است که به وسایل نقلیه امکان درک محیط اطراف، تشخیص اشیا و تصمیم گیری های لحظهای را میدهد.

نقش و وظایف یک دانشمند داده (Data Scientist)
دانشمند داده یک نقش محوری و چندوجهی است که نه تنها نیازمند مهارتهای فنی و کدنویسی است، بلکه قدرت تحلیل آماری و درک عمیق از اهداف کسب و کار را نیز میطلبد. دانشمند داده در واقع پل ارتباطی میان دنیای دادههای خام و تصمیمات استراتژیک سازمان است.
توزیع زمان وظایف روزانه
بر خلاف تصور رایج که دانشمند داده صرفاً درگیر مدلسازی است، بخش زیادی از زمان صرف مراحل آمادهسازی و ارتباطات میشود:
وظایف محوری یک دانشمند داده
- تعریف مسئله (Problem Framing): همکاری با تیمهای کسب و کار برای تبدیل یک چالش مبهم به یک سؤال داده محور و قابل حل (مثلاً: تبدیل «فروش کم شده» به «ریزش مشتری چقدر قابل پیشبینی است؟»).
- جمعآوری و مدیریت داده: شناسایی منابع داده داخلی و خارجی و استفاده از ابزارهایی مانند SQL یا NoSQL برای استخراج دادهها.
- توسعه مدلهای پیشبینی: ساخت و آموزش مدلهای یادگیری ماشین که میتوانند روندهای آینده را پیشبینی یا دادهها را دسته بندی کنند.
- استقرار و نگهداری (Deployment & Maintenance): قرار دادن مدلهای تأیید شده در محیطهای عملیاتی و نظارت بر عملکرد آنها در طول زمان (Model Monitoring).
تفاوت هوش تجاری (BI) با علم داده (Data Science)
در حالی که هوش تجاری (Business Intelligence) و علم داده هر دو با دادهها سروکار دارند و به بهبود تصمیم گیری کمک میکنند، اهداف، ابزارها و خروجیهای آنها کاملاً متفاوت است. تمایز کلیدی این است که هوش تجاری به گذشته نگاه میکند تا بفهمد چه اتفاقی افتاده، اما علم داده به آینده نگاه میکند تا پیشبینی کند چه اتفاقی خواهد افتاد.
این تمایز کلیدی در جدول زیر خلاصه شده است تا درک موضوع آسانتر شود:
| ویژگی | هوش تجاری (BI) |
علم داده (Data Science)
|
| تمرکز اصلی (جهتگیری) | تحلیل دادههای گذشته |
پیشبینی، کشف الگو و تجویز آینده
|
| نوع تحلیل | توصیفی (Descriptive) و تشخیصی (Diagnostic) |
پیشگویانه (Predictive) و تجویزی (Prescriptive)
|
| انواع داده | عمدتاً دادههای ساختاریافته (مثل پایگاه دادههای سازمانی) |
دادههای ساختاریافته و بدون ساختار (متن، تصویر، صوت، حسگرها)
|
| ابزارهای اصلی | ابزارهای مصورسازی و داشبوردسازی (مانند Power BI, Tableau) |
زبانهای برنامه نویسی (Python, R) و ابزارهای یادگیری ماشین
|
| خروجی نهایی | گزارشها، داشبوردها و شاخصهای کلیدی عملکرد (KPIها) |
مدلهای آماری، الگوریتمهای هوش مصنوعی و بینشهای جدید
|
شرح تفاوت: از گزارش تا نوآوری
- نقش BI: هوش تجاری برای پایش عملکرد روزانه و پاسخ به سؤالاتی مانند «در ماه گذشته چه تعداد از محصولات ما فروخته شد؟» ضروری است. خروجی آن به تیمهای مدیریتی کمک میکند تا وضعیت فعلی را درک کنند.
- نقش Data Science: علم داده از همین دادههای BI استفاده میکند اما با تکنیکهای پیچیدهتر، فراتر میرود و به سؤالاتی مانند «اگر قیمت را ۵ درصد کاهش دهیم، فروش چقدر در فصل آینده افزایش مییابد؟» پاسخ میدهد و راهکاری را تجویز میکند.
مسیر شغلی دانشمند داده: مهارتها، تخصصها و پیشنیازهای علم داده
مسیر شغلی در علم داده، یک سفر جذاب و چندوجهی است که نیازمند ترکیب مهارتهای فنی، آماری و تجاری است. تبدیل شدن به یک دانشمند داده (Data Scientist) موفق نیازمند تسلط بر چندین ستون دانشی است:
۱. پیشنیازهای فنی و ابزارهای ضروری در دیتا ساینس
یک دانشمند داده باید یک جعبه ابزار (Toolbox) قوی برای مدیریت دادهها و ساخت مدلها داشته باشد:
- برنامهنویسی: تسلط کامل بر زبان پایتون (Python) و اکوسیستم کتابخانههای آن (مانند Pandas، NumPy، Scikit-learn) ضروری است. زبان R نیز در زمینههای تحلیل آماری اهمیت خود را حفظ کرده است.
- پایگاه داده: دانش قوی در SQL برای استخراج، فیلتر و مدیریت دادهها از پایگاههای داده حیاتی است. آشنایی با سیستمهای NoSQL نیز یک مزیت محسوب میشود.
- مبانی ریاضی: درک مفاهیم آمار و احتمال برای آزمون فرضیهها، جبر خطی برای کار با دادههای چندبعدی و حسابان برای بهینهسازی مدلها الزامی است.
۲. تخصصهای مورد نیاز (The Skill Set) در دیتا ساینس
دانشمند داده اغلب به عنوان یک متخصص چندوجهی عمل میکند که مهارتهای زیر را بهکار میگیرد:
- یادگیری ماشین (Machine Learning): توانایی ساخت، آموزش و ارزیابی مدلهای پیشبینی، از رگرسیون ساده تا شبکههای عصبی (Deep Learning).
- مصورسازی داده (Data Visualization): مهارت در تبدیل دادههای پیچیده به نمودارها و داشبوردهای واضح (با استفاده از ابزارهایی مانند Tableau یا Matplotlib) برای انتقال نتایج به ذینفعان غیرفنی.
- دانش حوزه (Domain Knowledge): درک عمیق از صنعتی که در آن کار میکنید (مانند مالی، سلامت، یا بازاریابی) برای تعریف دقیق مسئله و ارزیابی تأثیر مدل بر کسب و کار.
۳. سطوح شغلی و چشمانداز درآمدی در علم داده
درآمد یک متخصص داده به عوامل متعددی مانند سابقه کار، میزان تخصص (بهویژه در یادگیری عمیق) و شهر محل کار بستگی دارد.
- سطوح شغلی: این مسیر اغلب از تحلیلگر داده (Data Analyst) آغاز شده، به دانشمند داده جونیور (Junior Data Scientist) میرسد و با کسب تجربه به دانشمند داده ارشد (Senior Data Scientist) یا معمار داده (Data Architect) ارتقاء مییابد.
- بازار کار و درآمد: با توجه به اهمیت داده در تصمیم گیریهای اقتصادی، بازار کار برای متخصصان داده در حال گسترش است.
مسیر شغلی دانشمند داده، نیازمند یادگیری مداوم و عملی است. اگر به دنبال یک ساختار منظم و گام به گام هستید، ابتدا نقشه راه دیتا ساینس را مطالعه کنید تا مسیر خود را بهصورت دقیق ترسیم نمایید. سپس، برای کسب مهارتهای فنی مورد نیاز و ورود سریع و عملی به بازار کار، دوره علم داده دیتایاد بهترین گزینه است.
نتیجهگیری: علم داده، قطب نمای کسب و کارهای آینده
علم داده دیگر یک موضوع فرعی یا یک واژه مد روز نیست؛ بلکه زیربنای اصلی تحول دیجیتال و مزیت رقابتی در تمام صنایع محسوب میشود. دانشمند داده با تلفیق دانش آمار، برنامه نویسی و درک کسب و کار، نهتنها چرایی رخدادهای گذشته را توضیح میدهد، بلکه با استفاده از مدلهای پیشبینانه، آینده را شکل میدهد.
همانطور که در این مقاله مشاهده کردیم، فرآیند علم داده یک چرخه تکرار شونده است که از درک دقیق مسئله کسب و کار آغاز شده و با استقرار و نظارت مداوم بر مدلها به اوج خود میرسد تا همواره ارزشآفرینی کند.
در نهایت، موفقیت در این حوزه نیازمند دو چیز است: دانش عمیق و عملگرایی.
اگر آمادهاید که از نقش مصرفکننده داده خارج شده و به خالق بینشهای ارزشمند تبدیل شوید:
اول: مسیر یادگیری خود را با مطالعه نقشه راه جامع علم داده مشخص کنید.
دوم: مهارتهای لازم برای ورود به این حوزه پرتقاضا را با شرکت در دوره آموزش دیتا ساینس دیتایاد به صورت عملی کسب نمایید.


















عالی و مفید بود
متشکرم، خوشحالم که برات مفید بود
دم شما گرم، پر قدرت ادامه بدین
مرسی از انرژی خوبت
من می خوام وارد این مسیر یادگیری علم داده بشم
به زودی گام به گام بهتون میگیم چیکار کنین که بدون سردرگمی خیلی راحت بتونین وارد این مسیر بشین و ادامه اش بدین
ممنونم از اینکه انقدر جامع در مورد علم داده گفتید، کاش در مورد دانشمند داده بیشتر توضیح می دادین.
لطف داری، برای این مورد که گفتی می تونی این اموزش زیر رو ببینی، روی لینک زیر کلیک کن:
آموزش متخصص علم داده
عالی بود، 5 دقیقه زمان برد خوندنش اما کلی اطلاعات جدید یاد گرفتم. مرسی از سایت خوب تون
ممنونم احسان عزیز، خوشحالم که برات مفید و کاربردی بود