

در درس نهم آموزش رایگان یادگیری ماشین با پایتون می خواهیم در مورد تولید داده های تست برای یادگیری ماشین صحبت کنیم.
هرگاه به یادگیری ماشین فکر میکنیم، اولین چیزی که به ذهنمان میآید، مجموعهای از دادههاست. هر چند میتوان دادههای زیادی را در سایتهایی مانند کگل (kaggle) پیدا کرد، گاهی نیاز داریم خودمان داده جمعآوری کنیم و یک مجموعه داده ایجاد نماییم.
وقتی خودمان داده تولید میکنیم، بیشتر میتوانیم بر آن سلطه داشته باشیم و مدل یادگیری ماشین خود را آموزش دهیم. در این درس، قصد داریم با استفاده از کتابخانهی sklearn.datasets در پایتون، مجموعههای داده تصادفی بسازیم.
تولید داده های تست برای دسته بندی
برای دستهبندی، دادههای تست را میتوانیم اینگونه تولید کنیم:
✓ در دستهبندی دودویی
مثال 1: دادههای دو بعدی که با تابع ()make_circles ساخته میشوند، دارای مرز تصمیم گویواره هستند.
# Import necessary libraries from sklearn.datasets import make_circles import matplotlib.pyplot as plt # Generate 2d classification dataset X, y = make_circles(n_samples=200, shuffle=True, noise=0.1, random_state=42) # Plot the generated datasets plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
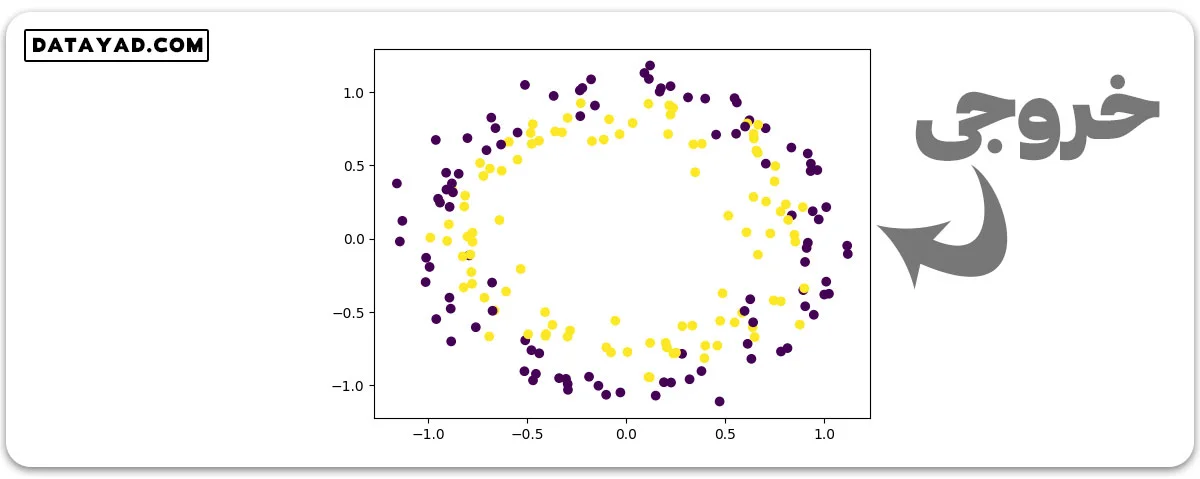
مثال 2: دو نیم دایرهی پیوسته که توسط تابع ()make_moons ساخته شدهاند، نمونههایی از دادههای دستهبندی دودویی دو بعدی هستند.
#import the necessary libraries from sklearn.datasets import make_moons import matplotlib.pyplot as plt # generate 2d classification dataset X, y = make_moons(n_samples=500, shuffle=True, noise=0.15, random_state=42) # Plot the generated datasets plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()

✓ در دستهبندی چندگانه
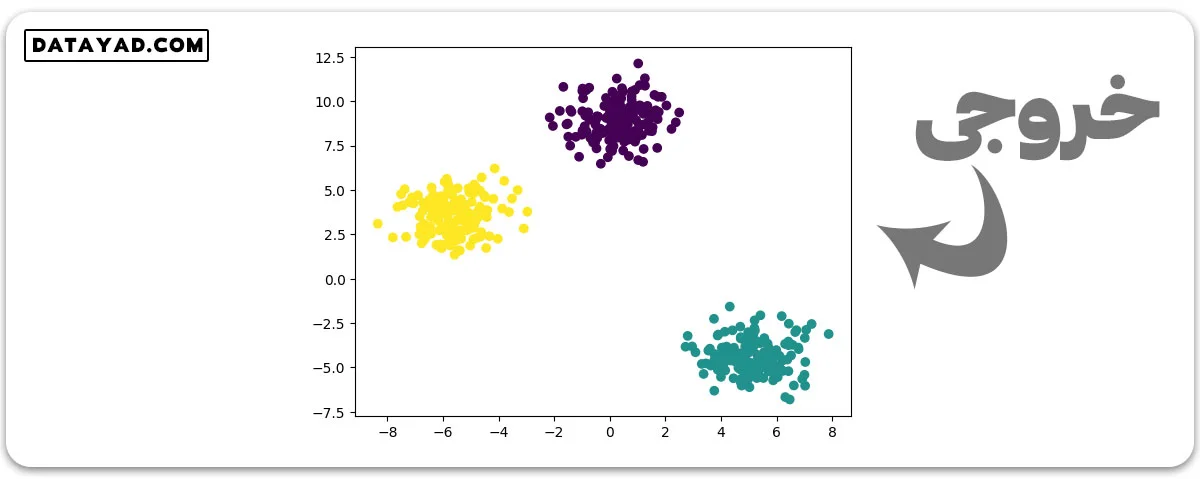
مثال 1: به عنوان مثال، دادههایی که توسط تابع ()make_blobs ساخته میشوند، به شکل گلولههایی هستند که میتوان آنها را برای خوشهبندی استفاده کرد.
#import the necessary libraries from sklearn.datasets import make_blobs import matplotlib.pyplot as plt # Generate 2d classification dataset X, y = make_blobs(n_samples=500, centers=3, n_features=2, random_state=23) # Plot the generated datasets plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
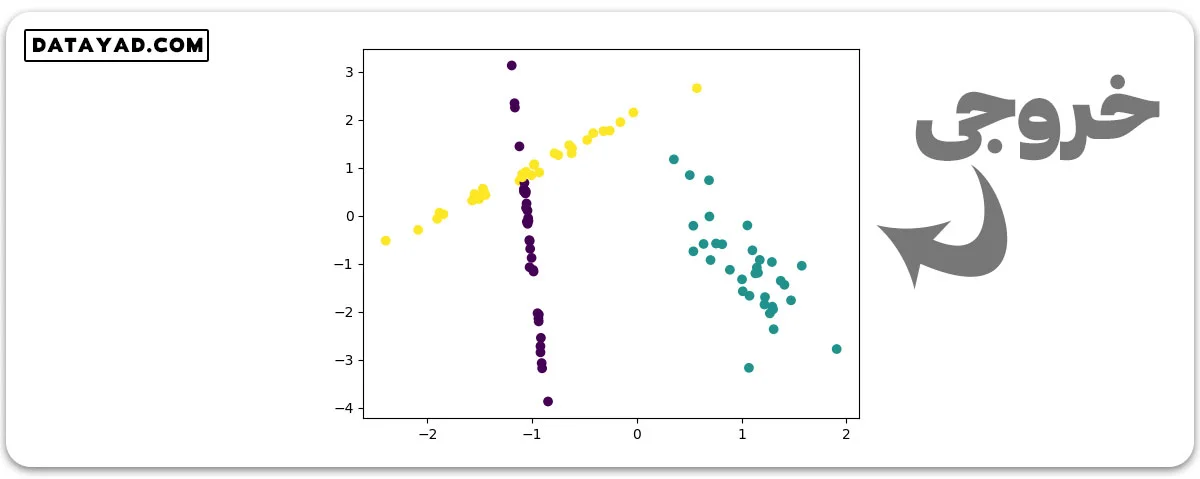
مثال 2: برای استفاده از تابع ()make_classification، باید بین ویژگیهای n_informative، n_redundant و n_classes تعادل برقرار کنیم.
from sklearn.datasets import make_classification import matplotlib.pyplot as plt # generate 2d classification dataset X, y = make_classification(n_samples = 100, n_features=2, n_redundant=0, n_informative=2, n_repeated=0, n_classes =3, n_clusters_per_class=1) # Plot the generated datasets plt.scatter(X[:, 0], X[:, 1], c=y) plt.show()
مثال 3: با استفاده از تابع ()make_multilabel_classification، دادههای دستهبندی چند برچسب تصادفی ساخته میشوند.
# Import necessary libraries from sklearn.datasets import make_multilabel_classification import pandas as pd import matplotlib.pyplot as plt # Generate 2d classification dataset X, y = make_multilabel_classification(n_samples=500, n_features=2, n_classes=2, n_labels=2, allow_unlabeled=True, random_state=23) # create pandas dataframe from generated dataset df = pd.concat([pd.DataFrame(X, columns=['X1', 'X2']), pd.DataFrame(y, columns=['Label1', 'Label2'])], axis=1) display(df.head()) # Plot the generated datasets plt.scatter(df['X1'], df['X2'], c=df['Label1']) plt.show()

تولید داده های تست برای رگرسیون
برای رگرسیون، دادههای تست را میتوانیم اینگونه بسازیم:
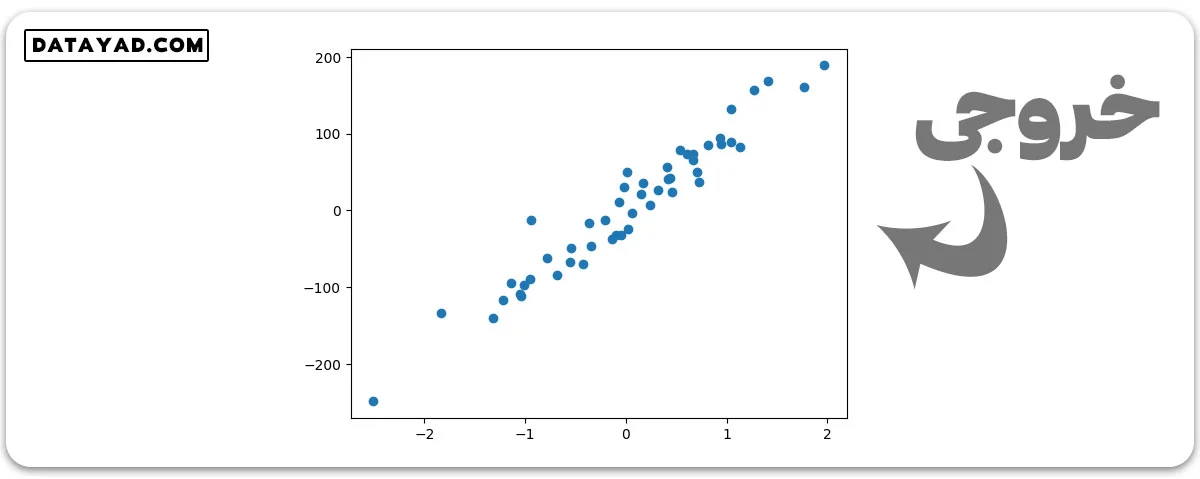
مثال 1: با استفاده از تابع make_regression، یک ویژگی و هدف یک بعدی برای رگرسیون خطی تولید میکنیم.
# Import necessary libraries from sklearn.datasets import make_regression import matplotlib.pyplot as plt # Generate 1d Regression dataset X, y = make_regression(n_samples = 50, n_features=1,noise=20, random_state=23) # Plot the generated datasets plt.scatter(X, y) plt.show()
مثال 2: با استفاده از تابع ()make_sparse_uncorrelated، ویژگیهای چند برچسبی تولید میشوند.
# Import necessary libraries
from sklearn.datasets import make_sparse_uncorrelated
import matplotlib.pyplot as plt
# Generate 1d Regression dataset
X, y = make_sparse_uncorrelated(n_samples = 100, n_features=4, random_state=23)
# Plot the generated datasets
plt.figure(figsize=(12,10))
for i in range(4):
plt.subplot(2,2, i+1)
plt.scatter(X[:,i], y)
plt.xlabel('X'+str(i+1))
plt.ylabel('Y')
plt.show()

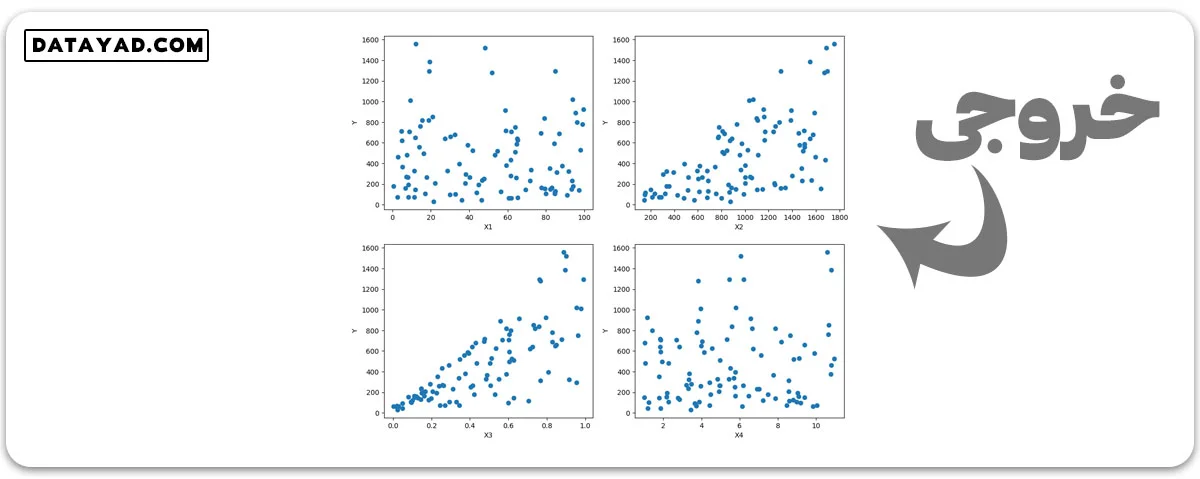
مثال 3: با استفاده از تابع ()make_friedman2، ویژگیهای چند برچسبی دیگر تولید میکنیم.
# Import necessary libraries
from sklearn.datasets import make_friedman2
import matplotlib.pyplot as plt
# Generate 1d Regression dataset
X, y = make_friedman2(n_samples = 100, random_state=23)
# Plot the generated datasets
plt.figure(figsize=(12,10))
for i in range(4):
plt.subplot(2,2, i+1)
plt.scatter(X[:,i], y)
plt.xlabel('X'+str(i+1))
plt.ylabel('Y')
plt.show()
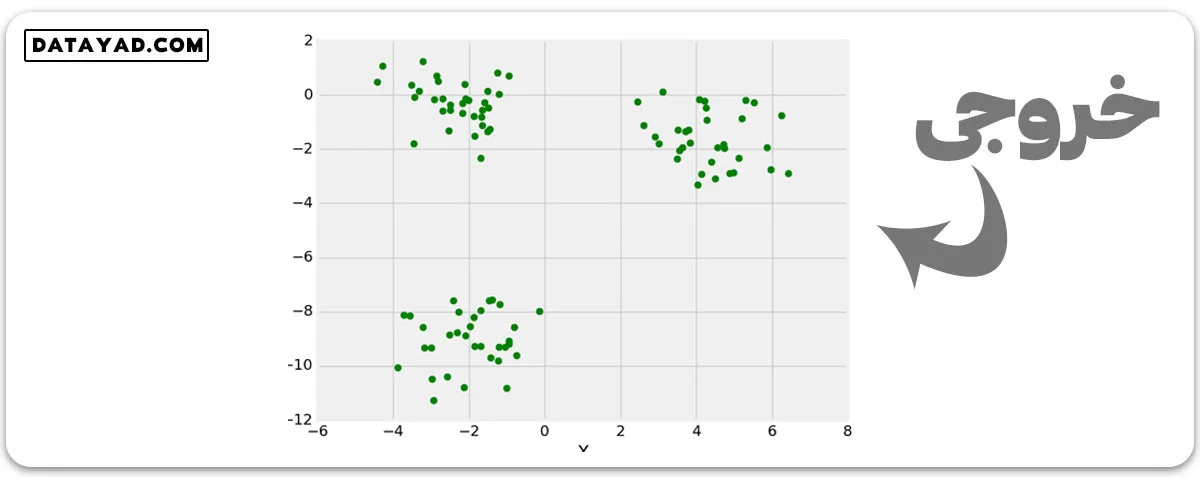
ایجاد دادههای تست (آزمایشی) با استفاده از Sklearn
کتابخانهی Sklearn در پایتون امکان ساخت دادههای آزمایشی را برایمان فراهم میکند. با استفاده از این کتابخانه میتوانیم به راحتی و با سرعت کار تولید مجموعه داده های تست برای یادگیری ماشین را برای پروژه های خود شروع کنیم.
برای استفاده از این امکانات باید از ماژول sklearn.datasets.samples_generator استفاده کنید.
# importing libraries from sklearn.datasets import make_blobs # matplotlib for plotting from matplotlib import pyplot as plt from matplotlib import style
sklearn.datasets.make_blobs
# Creating Test DataSets using sklearn.datasets.make_blobs
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_blobs(n_samples = 100, centers = 3,
cluster_std = 1, n_features = 2)
plt.scatter(X[:, 0], X[:, 1], s = 40, color = 'g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
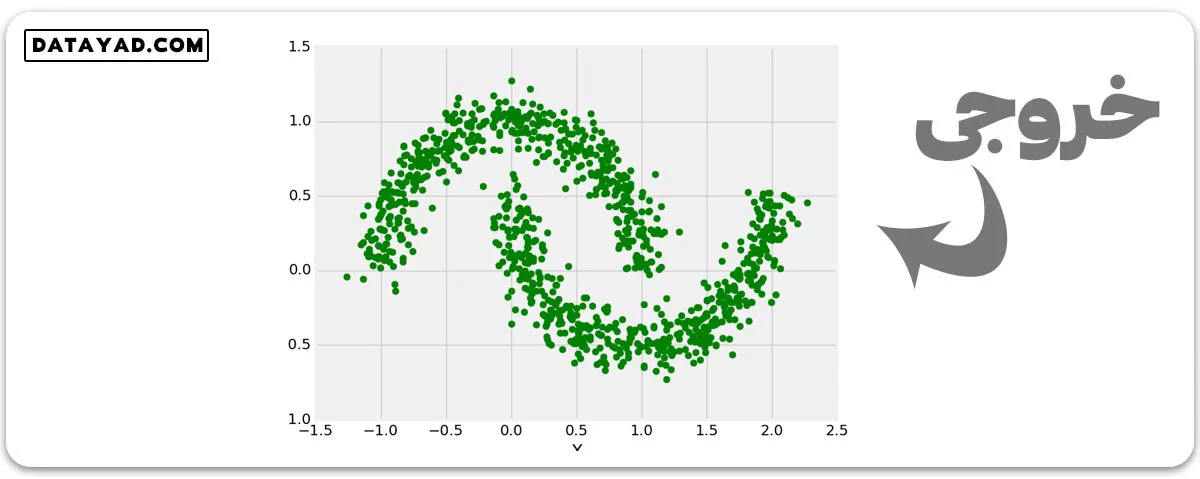
sklearn.datasets.make_moon
# Creating Test DataSets using sklearn.datasets.make_moon
from sklearn.datasets import make_moons
from matplotlib import pyplot as plt
from matplotlib import style
X, y = make_moons(n_samples = 1000, noise = 0.1)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
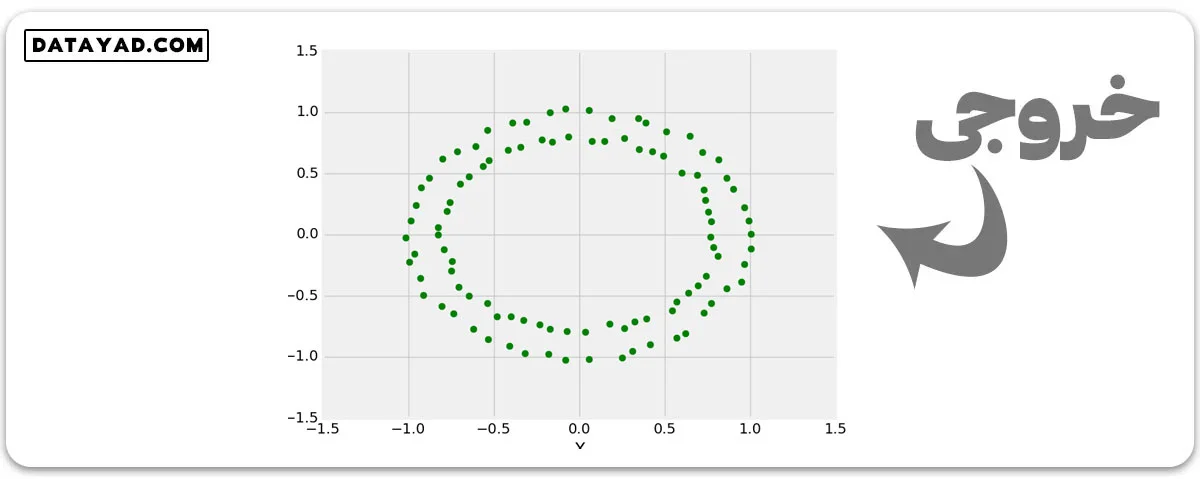
sklearn.datasets.make_circle
# Creating Test DataSets using sklearn.datasets.make_circles
from sklearn.datasets import make_circles
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
X, y = make_circles(n_samples = 100, noise = 0.02)
plt.scatter(X[:, 0], X[:, 1], s = 40, color ='g')
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
plt.clf()
Sklearn یکی از محبوبترین کتابخانههای یادگیری ماشین در پایتون است. با استفاده از آن میتوانیم به سرعت دادههای آزمایشی ایجاد کنیم.
مزایای استفاده از Sklearn برای ساخت دادههای آزمایشی
✅ صرفهجویی در زمان: با Sklearn به راحتی میتوان دادهها را تولید کرد.
✅ دادههای قابل پیشبینی: دادههای تولیدی با Sklearn قابل تکرار و پیشبینی هستند.
✅ انعطافپذیری: از دستهبندی گرفته تا رگرسیون، Sklearn توابع متنوعی دارد.
✅ کنترل: شما میتوانید ویژگیهای مختلف داده را تنظیم کنید.
معایب استفاده از Sklearn برای ساخت دادههای آزمایشی
✅ سادگی بیش از حد: دادههای Sklearn گاهی خیلی ساده هستند و ممکن است همیشه نیازهای واقعی را برآورده نکنند.
✅ کمبود تنوع: دادههای تولیدی ممکن است تنوع دادههای واقعی را نداشته باشند.
✅ خطر برازش زیاد: اگر دادههای آزمایشی خیلی به دادههای آموزش شبیه باشند، ممکن است مدل برازش زیادی داشته باشد.
در نهایت، با وجود اینکه Sklearn ابزاری مفید است، همیشه بهتر است در کنار آن از دادههای واقعی نیز استفاده کنیم تا دقت بیشتری در پروژههای خود داشته باشیم.











