درخت تصمیم یک ابزار تصمیمگیری است که از یک ساختار نموداری درخت مانند یا یک مدل از تصمیمها و تمام نتایج ممکن آنها، شامل نتایج، هزینههای ورودی و کارایی استفاده میکند.
الگوریتم درخت تصمیم وارد دستهبندی الگوریتمهای یادگیری نظارتی میشود. این الگوریتم برای متغیرهای خروجی هم به صورت پیوسته و هم به صورت گسسته کار میکند.
شاخهها/یالها (لبهها) نتیجه گره را نمایان میکنند و گرهها میتوانند شامل موارد زیر باشند:
- شرایط [گرههای تصمیم]
- نتیجه [گرههای پایانی]
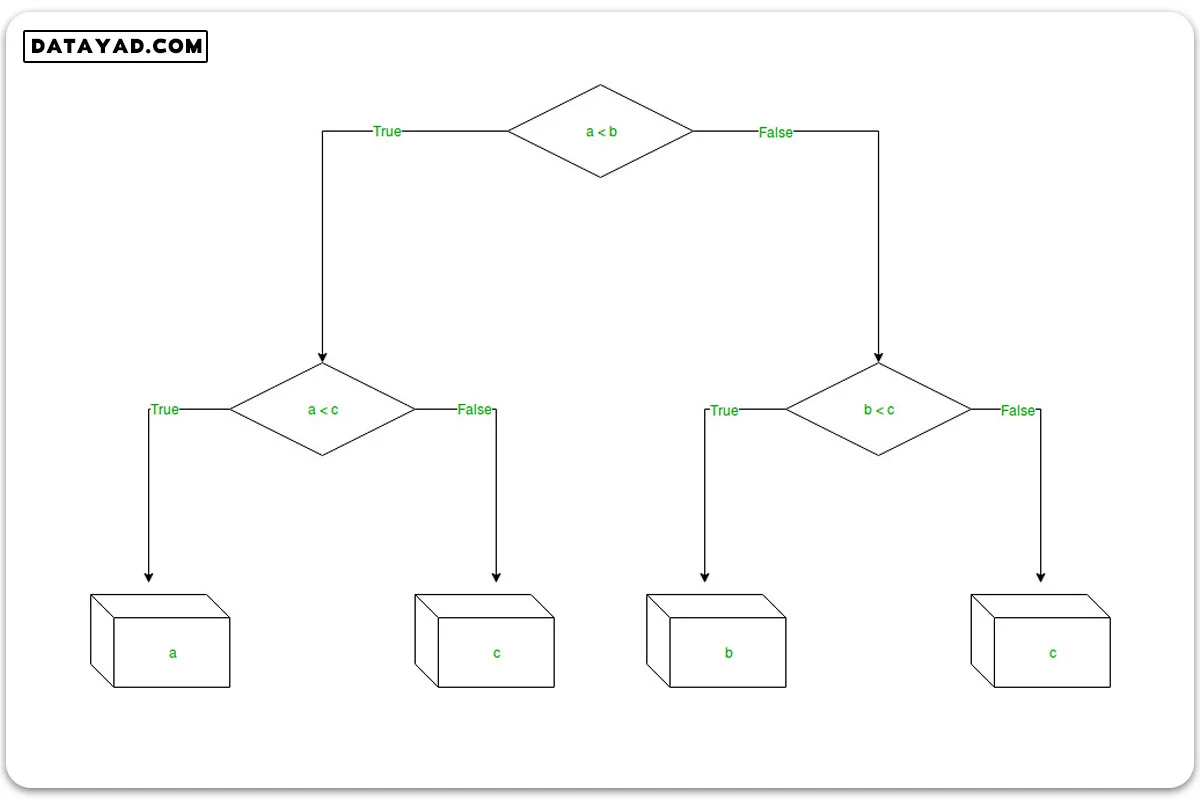
شاخهها یا لبهها درستی یا غلط بودن اظهاری را نمایان میکنند و بر اساس آن تصمیمی اتخاذ میکنند. به عبارت دیگر، درخت تصمیم در مثال زیر، که سه عدد، کوچکترین را ارزیابی میکند، از جمله شرایطی است که بر اساس درستی یا غلط بودن یک اظهار، تصمیم میگیرد.
رگرسیون درخت تصمیم
رگرسیون درخت تصمیم (Decision tree regression) ویژگیهای یک شی را مشاهده کرده و یک مدل را با ساختار درختی آموزش میدهد تا دادهها را در آینده پیشبینی کند و خروجی پیوسته و مفیدی تولید کند. خروجی پیوسته به این معنی است که نتیجه یا خروجی به صورت گسسته نیست، به عبارت دیگر تنها توسط یک مجموعه گسسته از اعداد یا مقادیر معلوم نمایان نمیشود.
مثال خروجی گسسته: یک مدل پیشبینی آب و هوا که پیشبینی میکند آیا در یک روز خاص باران میآید یا نه.
مثال خروجی پیوسته: یک مدل پیشبینی سود که میزان سود قابل انتظار از فروش یک محصول را اعلام میکند.
در اینجا، مقادیر پیوسته با کمک یک مدل رگرسیون درخت تصمیم پیشبینی میشوند.
بیایید به صورت مرحله به مرحله پیادهسازی را بررسی کنیم:
مرحله 1: وارد کردن کتابخانههای مورد نیاز
# import numpy package for arrays and stuff import numpy as np # import matplotlib.pyplot for plotting our result import matplotlib.pyplot as plt # import pandas for importing csv files import pandas as pd
مرحله 2: مقداردهی اولیه و چاپ مجموعه داده
# import dataset
# dataset = pd.read_csv('Data.csv')
# alternatively open up .csv file to read data
dataset = np.array(
[['Asset Flip', 100, 1000],
['Text Based', 500, 3000],
['Visual Novel', 1500, 5000],
['2D Pixel Art', 3500, 8000],
['2D Vector Art', 5000, 6500],
['Strategy', 6000, 7000],
['First Person Shooter', 8000, 15000],
['Simulator', 9500, 20000],
['Racing', 12000, 21000],
['RPG', 14000, 25000],
['Sandbox', 15500, 27000],
['Open-World', 16500, 30000],
['MMOFPS', 25000, 52000],
['MMORPG', 30000, 80000]
])
# print the dataset
print(dataset)
خروجی:
[['Asset Flip' '100' '1000'] ['Text Based' '500' '3000'] ['Visual Novel' '1500' '5000'] ['2D Pixel Art' '3500' '8000'] ['2D Vector Art' '5000' '6500'] ['Strategy' '6000' '7000'] ['First Person Shooter' '8000' '15000'] ['Simulator' '9500' '20000'] ['Racing' '12000' '21000'] ['RPG' '14000' '25000'] ['Sandbox' '15500' '27000'] ['Open-World' '16500' '30000'] ['MMOFPS' '25000' '52000'] ['MMORPG' '30000' '80000']]
مرحله 3: انتخاب همه سطرها و ستون ۱ از مجموعه داده به عنوان “X“
# select all rows by : and column 1 # by 1:2 representing features X = dataset[:, 1:2].astype(int) # print X print(X)
خروجی:
[[ 100] [ 500] [ 1500] [ 3500] [ 5000] [ 6000] [ 8000] [ 9500] [12000] [14000] [15500] [16500] [25000] [30000]]
مرحله 4: انتخاب تمام سطرها و ستون ۲ از مجموعه داده به عنوان “y“
# select all rows by : and column 2 # by 2 to Y representing labels y = dataset[:, 2].astype(int) # print y print(y)
خروجی:
[ 1000 3000 5000 8000 6500 7000 15000 20000 21000 25000 27000 30000 52000 80000]
مرحله 5: تنظیم رگرسور درخت تصمیم بر روی مجموعه داده
# import the regressor from sklearn.tree import DecisionTreeRegressor # create a regressor object regressor = DecisionTreeRegressor(random_state = 0) # fit the regressor with X and Y data regressor.fit(X, y)
خروجی:
DecisionTreeRegressor(ccp_alpha=0.0, criterion='mse', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=0, splitter='best')
مرحله 6: پیشبینی یک مقدار جدید
# predicting a new value
# test the output by changing values, like 3750
y_pred = regressor.predict([[3750]])
# print the predicted price
print("Predicted price: % d\n"% y_pred)
خروجی:
Predicted price: 8000
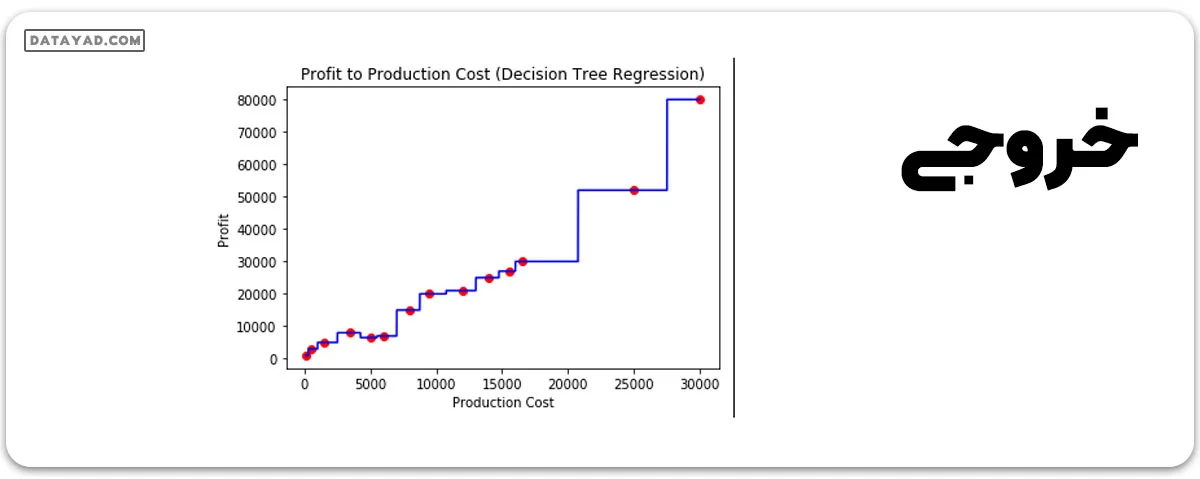
مرحله 7: تصویرسازی نتیجه
# arange for creating a range of values
# from min value of X to max value of X
# with a difference of 0.01 between two
# consecutive values
X_grid = np.arange(min(X), max(X), 0.01)
# reshape for reshaping the data into
# a len(X_grid)*1 array, i.e. to make
# a column out of the X_grid values
X_grid = X_grid.reshape((len(X_grid), 1))
# scatter plot for original data
plt.scatter(X, y, color = 'red')
# plot predicted data
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
# specify title
plt.title('Profit to Production Cost (Decision Tree Regression)')
# specify X axis label
plt.xlabel('Production Cost')
# specify Y axis label
plt.ylabel('Profit')
# show the plot
plt.show()
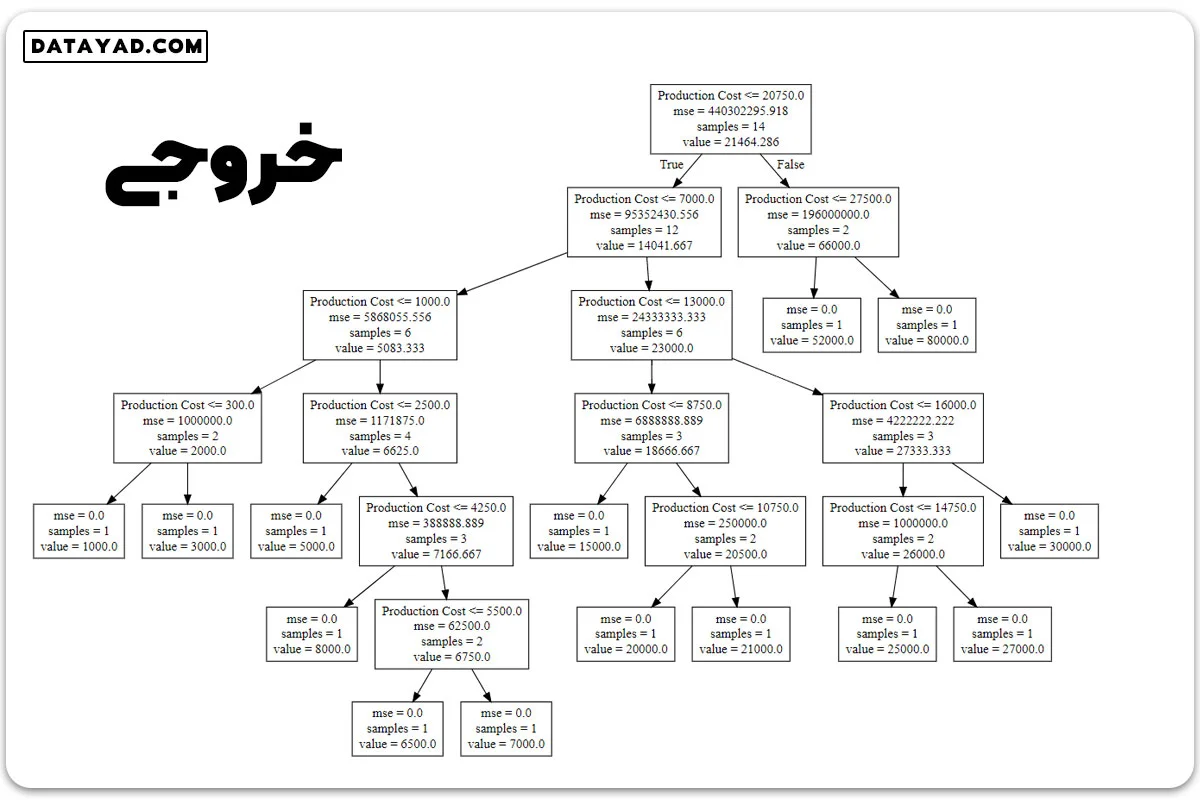
مرحله 8: درخت در نهایت استخراج و در ساختار درختی زیر نمایش داده شده است، که با استفاده از http://www.webgraphviz.com/ و کپی اطلاعات از فایل ‘tree.dot‘ بصریسازی شده است
# import export_graphviz from sklearn.tree import export_graphviz # export the decision tree to a tree.dot file # for visualizing the plot easily anywhere export_graphviz(regressor, out_file ='tree.dot', feature_names =['Production Cost'])