

در درس سیزدهم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم با روش کدبندی وان هات (One Hot Encoding) در یادگیری ماشین آشنا شویم.
زمانی که با دادهها در پروژه های علم داده سروکار داریم، اغلب با مجموعههایی مواجه میشویم که نوع دادههای متفاوتی دارند. این مجموعهها هم دادههای غیرعددی دارند و هم عددی. اما بسیاری از مدلهای یادگیری ماشین نمیتوانند با دادههای غیرعددی کار کنند. پس برای استفاده از آنها در این مدلها، باید آنها را به شکل عددی تبدیل کرد.
برای مثال، فرض کنید یک مجموعه داده با ستون جنسیت داریم که شامل مقادیر «مرد» و «زن» است. چون این مقادیر غیرعددی هستند و ترتیب خاصی ندارند، مدلهای یادگیری ماشین ممکن است به اشتباه فکر کنند در این میان یک ترتیب یا ارتباط هست.
یک راه برای حل این مشکل استفاده از “رمزگذاری برچسب” است، که در آن به هر برچسب یک عدد نسبت داده میشود. مثلاً، «مرد» به 0 و «زن» به 1 نگاشت میشود.
اما این کار ممکن است به مدل ما سویه اضافه کند، چرا که مدل شروع به دادن اهمیت بیشتر به «زن» میکند، چون عدد 1 از 0 بزرگتر است، در حالی که هر دو برچسب واقعاً مهم هستند. برای حل این مشکل، از روش کدبندی وان هات (One Hot Encoding) استفاده میکنیم.
کدبندی وان هات (One Hot Encoding)
کدبندی وان هات روشی است که برای نمایش متغیرهای غیرعددی به صورت مقادیر عددی در مدل یادگیری ماشین استفاده میشود.
مزایای کدبندی وان هات (One Hot Encoding)
✔️ این روش به ما این امکان را میدهد که از دادههای دستهای در مدلهایی که داده عددی میخواهند، استفاده کنیم.
✔️ با ارائه اطلاعات دقیقتر به مدل، عملکرد آن را بهبود میبخشد.
✔️ مشکلات ناشی از ترتیب در متغیرهای غیرعددی، مثل تفاوت بین «کوچک»، «متوسط» و «بزرگ» را برطرف میکند.
معایب کدبندی وان هات (One Hot Encoding)
✔️ این روش میتواند باعث افزایش تعداد ویژگیها شود، زیرا هر دسته جدید یک ستون جدید ایجاد میکند. این موضوع میتواند مدل را پیچیدهتر کند و زمان آموزش آن را طولانیتر سازد.
✔️ بیشتر دادهها در ستونهای رمزگذاری شده 0 خواهند بود و این میتواند منجر به دادههای پراکنده شود.
✔️ در صورت داشتن تعداد زیادی دسته و دادههای محدود، ممکن است باعث بیشبرازش شود.
✔️ هرچند روش one hot encoding برای دادههای غیرعددی مفید است، اما میتواند باعث پیچیدگیهای ذکر شده شود. بنابراین، استفاده هوشمندانه از آن و در نظر گرفتن روشهای دیگر مانند رمزگذاری ترتیبی یا دودویی حائز اهمیت است.
مثالهایی از کدبندی وان هات (One Hot Encoding)
در کدبندی وان هات، برای هر برچسب مثل “مرد” یا “زن”، یک ستون مجزا در نظر گرفته میشود. پس اگر یک نمونه برچسب “مرد” داشته باشد، در ستون مربوط به “مرد” عدد 1 و در ستون “زن” عدد 0 قرار میگیرد، و بالعکس.
برای فهم بهتر، فرض کنید دادهای داریم که در آن اسامی میوهها، برچسبهای دستهبندیشان و قیمتها آمده است.
| قیمت | ارزش | میوه |
| 5 | 1 | سیب |
| 10 | 2 | انبه |
| 15 | 1 | سیب |
| 20 | 3 | پرتغال |
پس از اجرای روش کدبندی وان هات، خروجی به این شکل خواهد بود:
| قیمت | پرتغال | انبه | سیب |
| 5 | 0 | 0 | 1 |
| 10 | 0 | 1 | 0 |
| 15 | 0 | 0 | 1 |
| 20 | 1 | 0 | 0 |
چطور با استفاده از پایتون از one hot encoding استفاده کنیم؟
ساخت دیتافریم (Dataframe)
از یک فایل CSV دیتافریمی میسازیم تا روش کدبندی وان هات را روی آن پیادهسازی کنیم.
# Program for demonstration of one hot encoding
# import libraries
import numpy as np
import pandas as pd
# import the data required
data = pd.read_csv('employee_data.csv')
print(data.head())
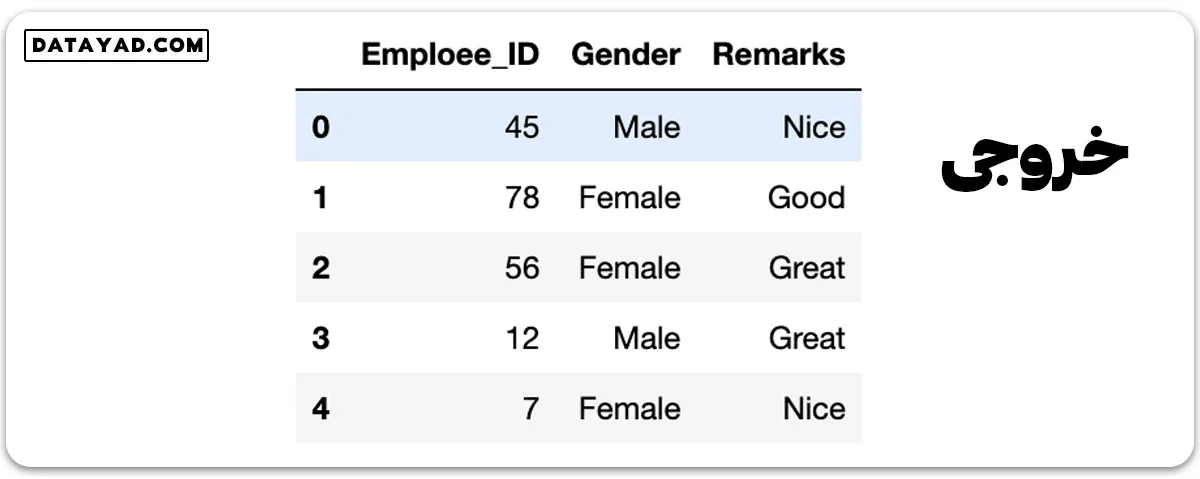
یافتن مقادیر منحصر به فرد در ستونهای غیرعددی
برای دسترسی به مقادیر منحصر به فرد یک ستون، از تابع ()unique در کتابخانه pandas استفاده میکنیم.
print(data['Gender'].unique()) print(data['Remarks'].unique())

شمارش تعداد المانها در یک ستون
برای محاسبه تعداد مقادیر مختلف در یک ستون، میتوانیم از تابع ()value_counts در pandas استفاده کنیم.
data['Gender'].value_counts() data['Remarks'].value_counts()

دو روش برای کدبندی وان هات ستونهای غیرعددی
1- با استفاده از کتابخانه pandas
میتوانیم از تابع ()pd.get_dummies برای انجام کدبندی وان هات ستون های غیرعددی استفاده کنیم.
one_hot_encoded_data = pd.get_dummies(data, columns = ['Remarks', 'Gender']) print(one_hot_encoded_data)
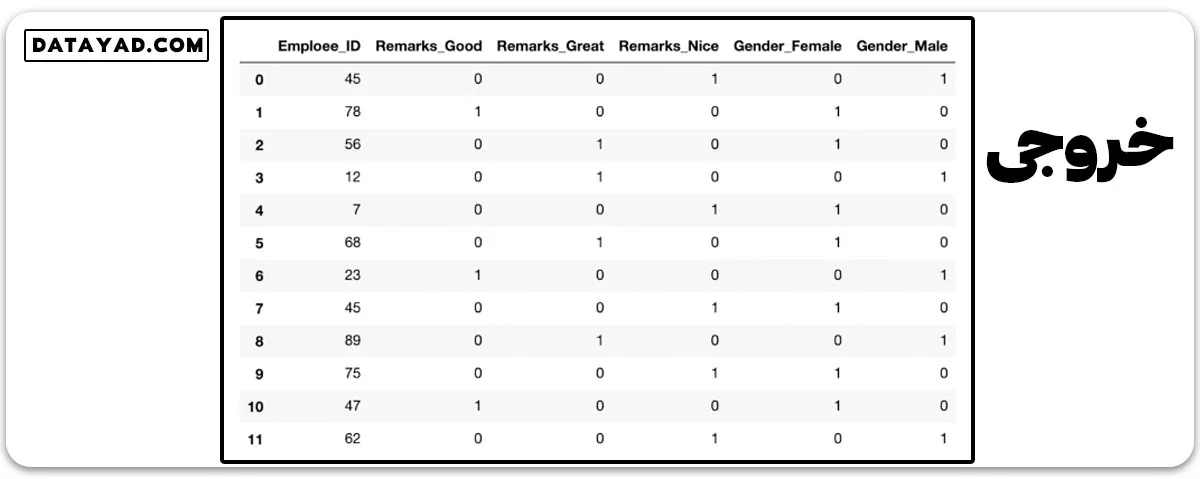
در دادهها، ما سه ستون ریمارک و دو ستون جنسیت داریم. اما اگر بخواهیم n برچسب مختلف را نمایش دهیم، فقط به n-1 ستون نیاز داریم. به عبارت دیگر، اگر فقط ستون جنسیت زن را نگه داریم و ستون جنسیت مرد را حذف کنیم، هنوز هم اطلاعات کافی داریم.
وقتی مقدار 1 باشد، به این معنی است که زن است و وقتی مقدار 0 باشد، مرد است. با این روش، میتوانیم دادههای غیرعددی را کدگذاری کرده و در عین حال، تعداد ستونها را کاهش دهیم.
2- با استفاده از کتابخانه Sci-kit Learn
Scikit-learn (یا به اختصار sklearn) یکی از کتابخانههای یادگیری ماشین در پایتون است که ابزارهای زیادی برای پیش پردازش داده ها ارائه میدهد.
این کتابخانه تابع OneHotEncoder را فراهم میکند که برای رمزگذاری متغیرهای غیرعددی و عددی به بردارهای دودویی استفاده میشود.
قبل از پیادهسازی این الگوریتم، مطمئن شوید که مقادیر غیرعددی به درستی برچسبگذاری شدهاند.
# importing libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
# Retrieving data
data = pd.read_csv('Employee_data.csv')
# Converting type of columns to category
data['Gender'] = data['Gender'].astype('category')
data['Remarks'] = data['Remarks'].astype('category')
# Assigning numerical values and storing it in another columns
data['Gen_new'] = data['Gender'].cat.codes
data['Rem_new'] = data['Remarks'].cat.codes
# Create an instance of One-hot-encoder
enc = OneHotEncoder()
# Passing encoded columns
enc_data = pd.DataFrame(enc.fit_transform(
data[['Gen_new', 'Rem_new']]).toarray())
# Merge with main
New_df = data.join(enc_data)
print(New_df)
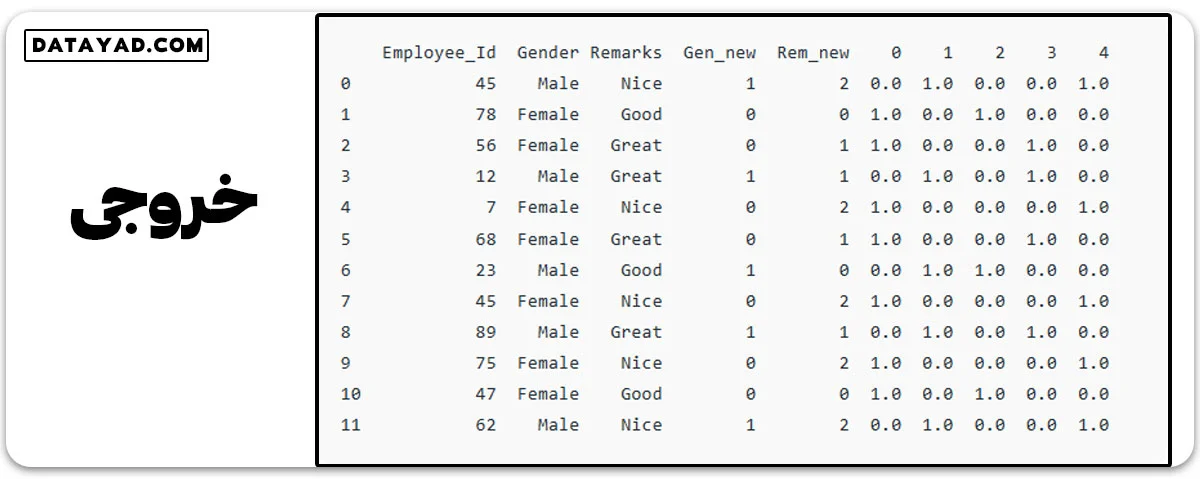
توجه: در اینجا متد ()enc.fit_transform را به یک آرایه تبدیل کردهایم، زیرا متد fit_transform از OneHotEncoder یک ماتریس پراکنده از نوع SciPy را برمیگرداند. لذا تبدیل به آرایه به ما این امکان را میدهد که در مواردی که تعداد زیادی متغیر غیرعددی داریم، در فضای مورد استفاده صرفهجویی کنیم.











