

در درس هفدهم آموزش رایگان یادگیری ماشین با پایتون می خواهیم با انواع تکنیک های رگرسیون در یادگیری ماشین آشنا شویم و بصورت تک به تک آنها را مورد بررسی قرار دهیم.
مواقعی که متغیر خروجی یک مقدار پیوسته یا واقعی است، مثل “حقوق” یا “وزن”، با یک مسئله رگرسیون مواجه هستیم. انواع مختلفی از مدلها میتوانند برای این کار استفاده شوند، که سادهترین آنها، رگرسیون خطی است. این مدل سعی دارد تا دادهها را با بهترین ابرصفحه که از بین نقاط عبور میکند، تطابق دهد.
تحلیل رگرسیون چیست؟
تحلیل رگرسیون (Regression Analysis) یک روش آماری است که به منظور پیشبینی روابط بین متغیرهای وابسته و یک یا چند متغیر مستقل استفاده میشود.
این روش عمدتاً زمانی کاربرد دارد که با دادههایی رو به رو هستیم که متغیر هدف آنها به شکل پیوسته است. تحلیل رگرسیون، تغییرات در متغیرهای معیار را بر اساس تغییرات در متغیرهای پیش بینی کننده توضیح میدهد.
سه کاربرد اصلی تحلیل رگرسیون عبارتند از:
- تعیین قدرت متغیرهای پیش بین (پیش بینی کننده)
- پیشبینی یک تاثیر خاص
- و پیشبینی ترندها (روندها).
هدف از استفاده از تحلیل رگرسیون چیست؟
گاهی اوقات ما میخواهیم تاثیر ویژگیهای مستقل مختلف را بر روی هدف یا همان ویژگیهای وابسته، مورد تجزیه و تحلیل قرار دهیم. این کار به ما کمک میکند تا تصمیمهایی بگیریم که میتوانند متغیر هدف را به سمت مورد نظر هدایت کنند.
تحلیل رگرسیون به شدت بر اساس آمار استوار است و به همین دلیل نتایج قابل اعتمادی ارائه میدهد. به همین دلیل است که مدلهای رگرسیون برای یافتن رابطه خطی و همچنین غیرخطی بین متغیرهای مستقل و وابسته یا هدف استفاده میشوند.
انواع تکنیک های رگرسیون در یادگیری ماشین
با توسعه حوزه یادگیری ماشین، تکنیکهای تحلیل رگرسیون نه تنها محبوبیت یافتهاند بلکه فراتر از فرمول ساده y = mx + c توسعه یافتهاند. چندین نوع تکنیک رگرسیون وجود دارد که هرکدام برای نوع خاصی از دادهها و روابط متفاوت بین آنها مناسب است. اصلیترین روش های رگرسیون در ماشین لرنینگ عبارتند از:
- رگرسیون خطی (Linear Regression)
- رگرسیون چندجمله ای (Polynomial Regression)
- رگرسیون گام به گام (Stepwise Regression)
- رگرسیون درخت تصمیم (Decision Tree Regression)
- رگرسیون جنگل تصادفی (Random Forest Regression)
- رگرسیون بردار پشتیبان (Support Vector Regression)
- رگرسیون ریج (Ridge Regression)
- رگرسیون لاسو (Lasso Regression)
- رگرسیون الاستیکنت (ElasticNet Regression)
- رگرسیون خطی بیز (Bayesian Linear Regression)
1- رگرسیون خطی
رگرسیون خطی برای انجام تحلیلهای پیشبینی مورد استفاده قرار میگیرد. در این روش، یک مدل خطی میان پاسخ اسکالار یا معیار و چندین متغیر توضیحی (توصیفی) یا پیشبین، ایجاد میشود.
رگرسیون خطی بر بررسی توزیع احتمال شرطی پاسخ با توجه به مقادیر پیشبینها تمرکز دارد. یکی از مشکلاتی که در رگرسیون خطی ممکن است پیش بیاید، خطر بیشبرازش است. فرمول رگرسیون خطی به شکل زیر است:
نحوه نوشتار:
y = θx + b که در اینجا:
- θ – وزنها یا پارامترهای مدل است.
- b – که به آن بایاس (سوگیری) میگویند.
این فرم ابتدایی تحلیل رگرسیون است و برای مدلسازی یک رابطه خطی بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود.
در اینجا، یک مدل رگرسیون خطی ایجاد شده تا یک رابطه خطی بین ویژگیهای ورودی (X) و مقادیر هدف (y) برازش کند. این کد به منظور نمایش سادهتر این رویکرد استفاده میشود.
from sklearn.linear_model import LinearRegression # Create a linear regression model model = LinearRegression() # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد نحوهی کارکرد ابتدایی ایجاد، آموزش، و استفاده از یک مدل رگرسیون خطی را با هدف مدلسازی پیشبینیکننده نشان میدهد.
2- رگرسیون چندجملهای
یکی دیگر از روش های رگرسیون در یادگیری ماشین، چندجمله ای است. این روش یک مشتق از رگرسیون خطی است و برای مدلسازی یک رابطه غیرخطی بین متغیر وابسته و متغیرهای مستقل استفاده میشود.
در اینجا نیز نحوه نوشتار همانند قبل است، بجز آنکه در متغیرهای ورودی، علاوه بر ویژگیهای موجود، عبارات چندجملهای یا مرتبههای بالاتر نیز افزوده میشوند.
رگرسیون خطی تنها قادر به برازش یک مدل خطی به دادهها بود، اما با استفاده از ویژگیهای چندجملهای، میتوانیم به راحتی یک رابطه غیرخطی بین هدف و ویژگیهای ورودی را برازش کنیم. در اینجا کدی برای نمایش ساده رویکرد رگرسیون چندجملهای آورده شده است.
from sklearn.linear_model import PolynomialRegression # Create a polynomial regression model model = PolynomialRegression(degree=2) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون چندجملهای را با هدف مدلسازی پیشبینیکننده نشان میدهد.
3- رگرسیون گام به گام
رگرسیون گام به گام برای مدلسازی رگرسیون با استفاده از مدلهای پیشبینی کاربرد دارد و به صورت خودکار اجرا میشود. در این روش، در هر مرحله، یک متغیر به مجموعه متغیرهای توصیفی اضافه یا از آن حذف میشود.
روشهایی که در رگرسیون گام به گام استفاده میشوند، عبارتاند از:
- انتخاب روبهجلو (forward selection)،
- حذف عقبگرد (backward elimination)
- حذف دوطرفه (bidirectional elimination).
فرمول رگرسیون گام به گام به این صورت است:
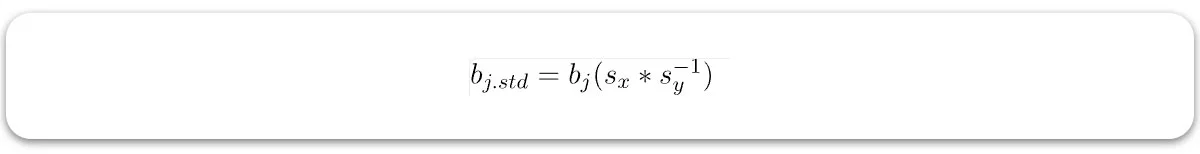
در اینجا کدی برای نشان دادن رویکرد رگرسیون گام به گام آورده شده است.
from sklearn.linear_model import StepwiseLinearRegression # Create a stepwise regression model model = StepwiseLinearRegression(forward=True, backward=True, verbose=1) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون گام به گام را با هدف مدلسازی پیشبینی نشان میدهد.
4- رگرسیون درخت تصمیم
درخت تصمیم یکی از ابزارهای قدرتمند و پرطرفدار برای دستهبندی و پیشبینی است. درخت تصمیم شبیه به یک فلوچارت است که در آن، هر گره داخلی به بررسی یک ویژگی اختصاص دارد، هر شاخه نتیجهی آزمون را نشان میدهد و هر گره برگ (یا نهایی)، یک برچسب کلاس را نگهداری میکند. روشی غیرپارامتریک برای مدلسازی درخت تصمیم به منظور پیشبینی یک پاسخ پیوسته نیز وجود دارد.
در اینجا کدی برای نشان دادن روش رگرسیون درخت تصمیم آورده شده است.
from sklearn.tree import DecisionTreeRegressor # Create a decision tree regression model model = DecisionTreeRegressor() # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون درخت تصمیم را با هدف مدلسازی پیشبینی نشان میدهد.
5- رگرسیون جنگل تصادفی
جنگل تصادفی یک تکنیک ترکیبی است که میتواند هم وظایف رگرسیون و هم دستهبندی را با استفاده از چند درخت تصمیم و یک روش به نام بوتاسترپ و تجمیع، که معمولاً به آن بگینگ (bagging) میگویند، انجام دهد. اصل این روش این است که به جای تکیه بر یک درخت تصمیم مستقل، از ترکیب چندین درخت تصمیم برای مشخص کردن خروجی نهایی استفاده میشود.
در جنگل تصادفی، چندین درخت تصمیم به عنوان مدلهای اصلی یادگیری عمل میکنند. ما به صورت تصادفی از سطرها و ویژگیهای دیتاست نمونهبرداری میکنیم تا مجموعه دادههای نمونه برای هر مدل ایجاد کنیم. این بخش بوتاسترپ (Bootstrap) نام دارد.
کدی برای نمایش سادهای از رویکرد رگرسیون جنگل تصادفی در اینجا آورده شده است.
from sklearn.ensemble import RandomForestRegressor # Create a random forest regression model model = RandomForestRegressor(n_estimators=100) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون جنگل تصادفی را با هدف مدلسازی پیشبینی نشان میدهد.
6- رگرسیون بردار پشتیبان (SVR)
رگرسیون بردار پشتیبان، یک شاخه از ماشینهای بردار پشتیبان (SVM) است که برای کارهای رگرسیون به کار میرود. این روش تلاش میکند تا تابعی را پیدا کند که به بهترین شکل، مقدار خروجی پیوسته را برای یک مقدار ورودی مشخص پیشبینی کند.
SVR هم از کرنلهای خطی و هم غیرخطی استفاده میکند. یک کرنل خطی فقط محصول نقطهای دو بردار ورودی است، اما یک کرنل غیرخطی تابعی پیچیدهتر است که توانایی شناسایی الگوهای بیشتری در دادهها را دارد. انتخاب نوع کرنل به ویژگیهای دادهها و پیچیدگی کار وابسته است.
در اینجا کدی برای نمایش سادهای از روش رگرسیون بردار پشتیبان آورده شده است.
from sklearn.svm import SVR # Create a support vector regression model model = SVR(kernel='linear') # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل SVR را با هدف مدلسازی پیشبینی نشان میدهد.
7- رگرسیون ریج (Ridge)
رگرسیون ریج یک روش رگرسیون در یادگیری ماشین برای بررسی دادههای رگرسیون چند متغیره است. در زمانی که پدیدهی همخطی (multicollinearity) رخ میدهد، تخمینهای حاصل از روش حداقل مربعات دارای سوگیری یا بایاس کمتری هستند.
رگرسیون ریج، که یک مدل رگرسیون خطی با ریگولارشده است، با اضافه کردن یک جملهی جریمه به تابع هزینه، سعی در کاهش پیچیدگی مدل دارد. در این روش، مقداری بایاس به تخمینهای رگرسیون اضافه میشود و در نتیجه، خطاهای استاندارد کاهش مییابند.
کدی در اینجا برای نشان دادن نحوهی کار رگرسیون ریج قرار داده شده است.
from sklearn.linear_model import Ridge # Create a ridge regression model model = Ridge(alpha=0.1) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون ریج را با هدف مدلسازی پیشبینی نشان میدهد.
8- رگرسیون لاسو
رگرسیون لاسو یک شیوه تحلیل رگرسیون است که همزمان متغیرها را انتخاب کرده و مدل را تنظیم میکند. در این روش از آستانهگذاری نرم (soft thresholding) استفاده میشود. لاسو تنها بخشی از متغیرهای توصیفی داده شده را برای مدل نهایی انتخاب میکند.
لاسو یک مدل رگرسیون خطی ریگولارشده دیگر است که با افزودن یک جمله جریمه به تابع هزینه عمل میکند. این روش تمایل دارد که ضرایب برخی از ویژگیها را به صفر برساند، که این خاصیت آن را برای انتخاب ویژگیها مفید میکند.
کدی در اینجا برای نمایش ساده روش رگرسیون لاسو آورده شده است.
from sklearn.linear_model import Lasso # Create a lasso regression model model = Lasso(alpha=0.1) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون لاسو را با هدف مدلسازی پیشبینی نشان میدهد.
9- رگرسیون الاستیکنت
رگرسیون خطی مشکل بیشبرازش دارد و با دادههای همخط کنار نمیآید. زمانی که مجموعه داده شامل تعداد زیادی ویژگی است و حتی برخی از این ویژگیها اصلاً با مدل پیشبینی ما ارتباط ندارند، مدل به شکلی پیچیدهتر میشود و پیشبینیهای کمدقتی روی مجموعه آزمون ارائه میدهد (یعنی به بیشبرازش میافتد).
یک مدل با واریانس بالا نمیتواند به خوبی روی دادههای جدید پیاده شود. پس، برای رفع این مشکلات، هر دو نوع ریگولارسازهای L-2 و L-1 را به کار میبریم تا همزمان از مزایای رگرسیون Ridge و Lasso بهرهمند شویم.
مدل نتیجهگیری شده توانایی پیشبینی بهتری نسبت به Lasso دارد، ویژگیها را انتخاب میکند و همچنین فرضیات را سادهتر میسازد. تابع هزینه اصلاحشده برای رگرسیون الاستیکنت به شرح زیر است:
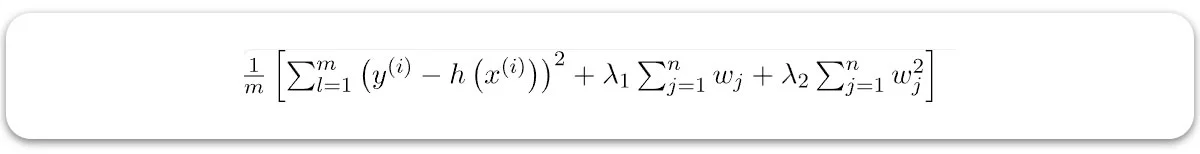
در اینجا:
- w(j) وزن برای ویژگی jم است.
- n تعداد کل ویژگیها در مجموعه داده است.
- lambda1 قدرت معمولیسازی برای نُرم L1 است.
- lambda2 قدرت معمولیسازی برای نُرم L2 است.
کدی در اینجا برای نمایش ساده روش رگرسیون الاستیکنت آورده شده است.
from sklearn.linear_model import ElasticNet # Create an elastic net regression model model = ElasticNet(alpha=0.1, l1_ratio=0.5) # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون الاستیکنت را با هدف مدلسازی پیشبینی نشان میدهد.
10- رگرسیون خطی بیز
همانطور که از نامش معلوم است، این الگوریتم کاملاً بر اساس قضیه بیز توسعه یافته است. دلیل استفاده نکردن از روش حداقل مربعات برای یافتن ضرایب مدل رگرسیون، همین موضوع است. در این روش، یافتن وزنها و پارامترهای مدل بر اساس توزیع پسین ویژگیها انجام میشود، که این مسأله عاملی افزاینده بر پایداری مدل رگرسیون مبتنی بر این تکنیک است.
کدی در اینجا برای نمایش ساده روش رگرسیون خطیبیزین آورده شده است.
from sklearn.linear_model import BayesianLinearRegression # Create a Bayesian linear regression model model = BayesianLinearRegression() # Fit the model to the data model.fit(X, y) # Predict the response for a new data point y_pred = model.predict(X_new)
توجه: این کد، گردش کار ابتدایی ایجاد، آموزش و استفاده از یک مدل رگرسیون خطیبیزین را با هدف مدلسازی پیشبینی نشان میدهد.











