

در درس بیست و هشتم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم به پیادهسازی رگرسیون چندجمله ای با پایتون از پایه بپردازیم. تا انتها با ما همراه باشید.
پیشنیازها
1- رگرسیون خطی (Linear Regression)
2- گرادیان کاهشی (Gradient Descent)
مقدمه
رگرسیون خطی، ارتباط بین متغیر وابسته (یا هدف) و متغیرهای مستقل (یا ویژگیها) را پیدا میکند. به زبان ساده، یک مدل خطی است که برای تطبیق دادهها به صورت خطی طراحی می شود. اما این مدل در درک و تطبیق دادههای غیرخطی ناتوان است.
اول از همه بیایید رگرسیون خطی را روی دادههای غیرخطی امتحان کنیم تا به اهمیت و نیاز به وجود رگرسیون چند جملهای (Polynomial Regression) پی ببریم. مدل رگرسیون خطی که در این مقاله استفاده میشود، از کتابخانه sklearn برداشته شده است. برای درک نحوه پیادهسازی این مدل رگرسیون خطی، میتوانید به مقاله جداگانهای مراجعه کنید.
# Importing libraries import numpy as np import pandas as pd from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # driver code def main() : # Create dataset X = np.array( [ [1], [2], [3], [4], [5], [6], [7] ] ) Y = np.array( [ 45000, 50000, 60000, 80000, 110000, 150000, 200000 ] ) # Model training model = LinearRegression() model.fit( X, Y ) # Prediction Y_pred = model.predict( X ) # Visualization plt.scatter( X, Y, color = 'blue' ) plt.plot( X, Y_pred, color = 'orange' ) plt.title( 'X vs Y' ) plt.xlabel( 'X' ) plt.ylabel( 'Y' ) plt.show() if __name__ == "__main__" : main()
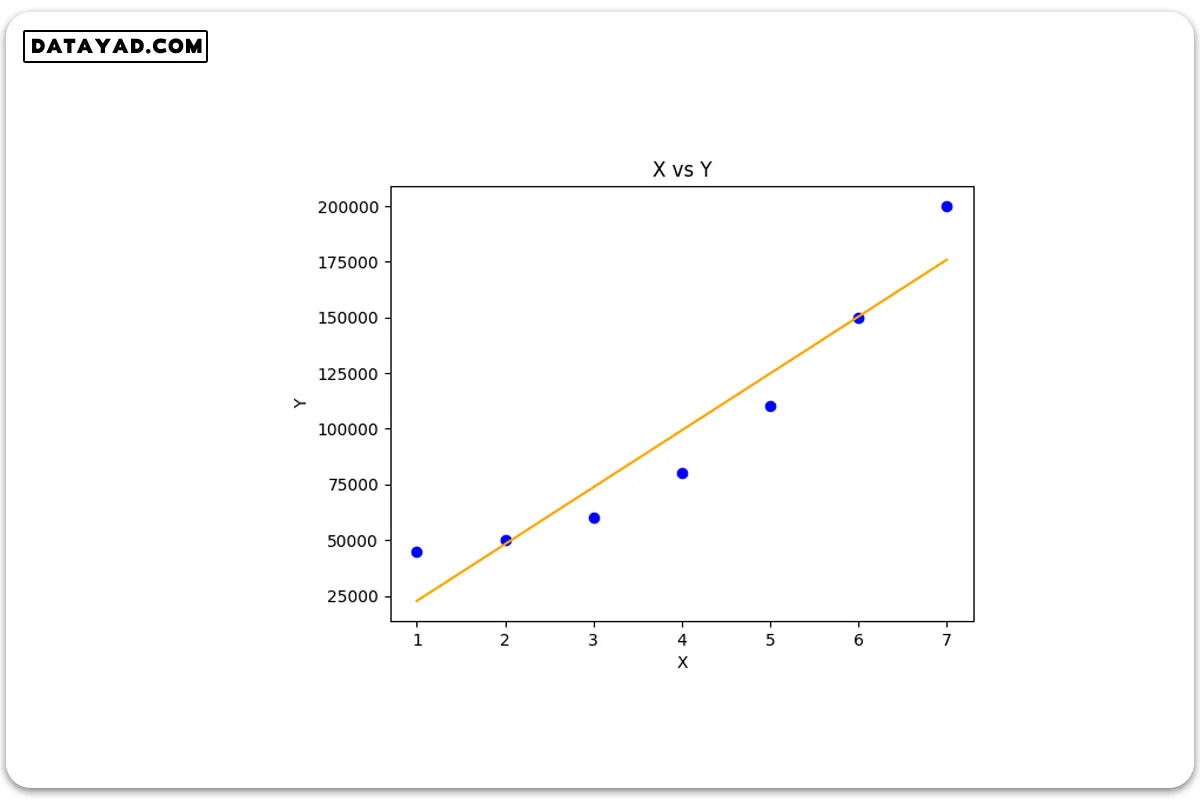
همانطور که در خروجی کد مشاهده میشود، رگرسیون خطی حتی در تطبیق دادن دادههای آموزشی به طور صحیح، ناموفق بود (در درک الگوی رفتاری متغیر Y نسبت به X ناتوان بود). دلیل این امر این است که تابع فرضی آن از ماهیتی خطی برخوردار است، در حالی که Y یک تابع غیرخطی از X میباشد.
برای رگرسیون خطی تک متغیره:
h(x) = w * x
در اینجا، x بردار ویژگی است.
و w بردار وزن است.
این مشکل همچنین به عنوان “کمبرازش” (underfitting) شناخته میشود. برای غلبه بر مشکل کمبرازش، ما با افزودن توان به بردار ویژگی اصلی، بردار ویژگی جدیدی را معرفی میکنیم.
پس برای رگرسیون چندجملهای تک متغیره به این شکل تغییر می کند:
h(x) = w1x + w2x² + … + wnxⁿ
در اینجا، w بردار وزن است.
که در آن x² ویژگی بهدستآمده از x است.
پس از تبدیل X اصلی به ترمهای درجه بالاتر، این کار باعث میشود که تابع فرضی ما قادر به تطبیق دادههای غیرخطی باشد. در اینجا مدل رگرسیون چندجمله ای با پایتون از ابتدا پیاده سازی شده و اعتبارسنجی مدل روی یک مجموعه داده نمونه ارائه شده است.
ما همچنین X را پیش از ورود به مدل نرمالیزه میکنیم تا از مشکلات ناپدید شدن (Vanishing) و انفجار گرادیان (Exploding) جلوگیری کنیم.
# Importing libraries import numpy as np import math import matplotlib.pyplot as plt # Univariate Polynomial Regression class PolynomailRegression() : def __init__( self, degree, learning_rate, iterations ) : self.degree = degree self.learning_rate = learning_rate self.iterations = iterations # function to transform X def transform( self, X ) : # initialize X_transform X_transform = np.ones( ( self.m, 1 ) ) j = 0 for j in range( self.degree + 1 ) : if j != 0 : x_pow = np.power( X, j ) # append x_pow to X_transform X_transform = np.append( X_transform, x_pow.reshape( -1, 1 ), axis = 1 ) return X_transform # function to normalize X_transform def normalize( self, X ) : X[:, 1:] = ( X[:, 1:] - np.mean( X[:, 1:], axis = 0 ) ) / np.std( X[:, 1:], axis = 0 ) return X # model training def fit( self, X, Y ) : self.X = X self.Y = Y self.m, self.n = self.X.shape # weight initialization self.W = np.zeros( self.degree + 1 ) # transform X for polynomial h( x ) = w0 * x^0 + w1 * x^1 + w2 * x^2 + ........+ wn * x^n X_transform = self.transform( self.X ) # normalize X_transform X_normalize = self.normalize( X_transform ) # gradient descent learning for i in range( self.iterations ) : h = self.predict( self.X ) error = h - self.Y # update weights self.W = self.W - self.learning_rate * ( 1 / self.m ) * np.dot( X_normalize.T, error ) return self # predict def predict( self, X ) : # transform X for polynomial h( x ) = w0 * x^0 + w1 * x^1 + w2 * x^2 + ........+ wn * x^n X_transform = self.transform( X ) X_normalize = self.normalize( X_transform ) return np.dot( X_transform, self.W ) # Driver code def main() : # Create dataset X = np.array( [ [1], [2], [3], [4], [5], [6], [7] ] ) Y = np.array( [ 45000, 50000, 60000, 80000, 110000, 150000, 200000 ] ) # model training model = PolynomailRegression( degree = 2, learning_rate = 0.01, iterations = 500 ) model.fit( X, Y ) # Prediction on training set Y_pred = model.predict( X ) # Visualization plt.scatter( X, Y, color = 'blue' ) plt.plot( X, Y_pred, color = 'orange' ) plt.title( 'X vs Y' ) plt.xlabel( 'X' ) plt.ylabel( 'Y' ) plt.show() if __name__ == "__main__" : main()
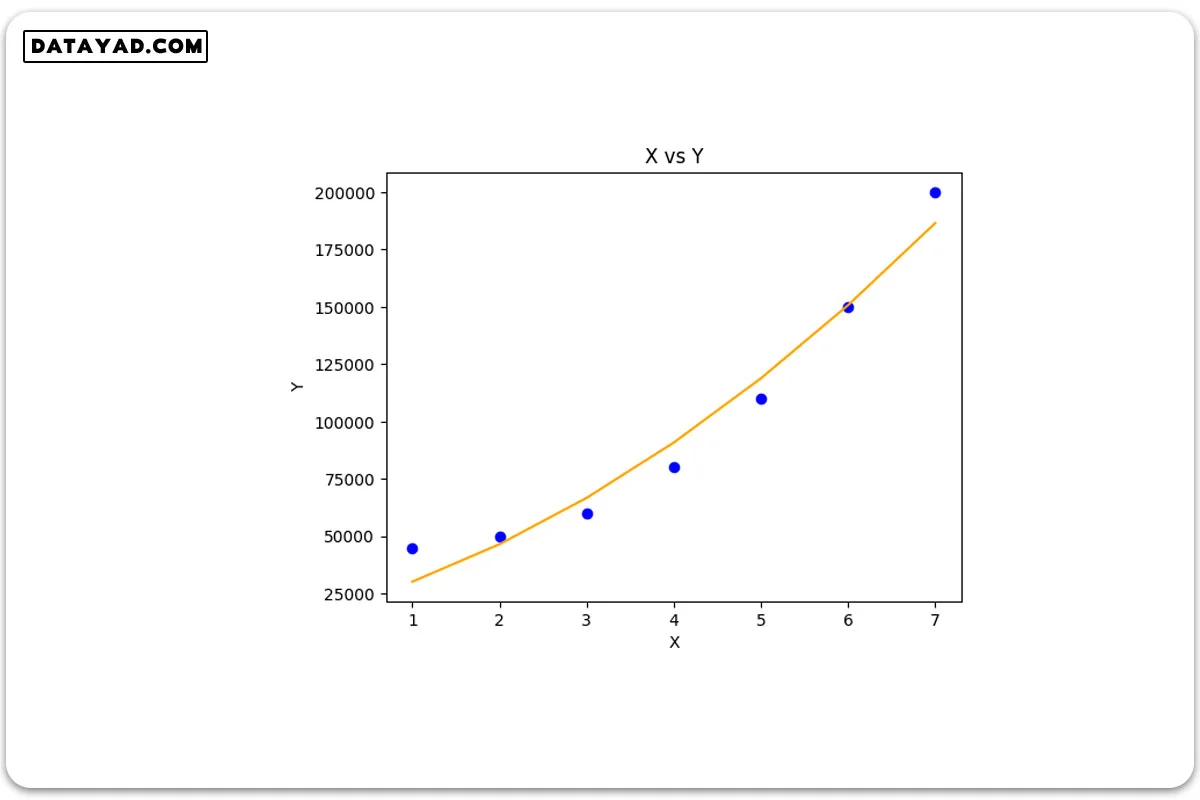
خروجی نشان می دهد که رگرسیون چندجملهای با ایجاد یک منحنی، با الگوی تغییرات غیرخطی داده ها منطبق شد.




