

داده های دیتاست مسکن بوستون
این دیتاست (مجموعه داده) از کتابخانه StatLib برداشته شده و تحت نگهداری دانشگاه کارنگی ملون است. این داده ها به قیمتهای مسکن در شهر بوستون اشاره دارند. دیتاست ارائه شده شامل ۵۰۶ نمونه است، که ۱۳ ویژگی دارند.
توضیحات مربوط به این دیتاست در جدول زیر آمده است:

بیایید مدل رگرسیون خطی (Linear Regression) را بسازیم و قیمت مسکن را با وارد کردن کتابخانهها و دیتاست پیشبینی کنیم.
# Importing Libraries import numpy as np import pandas as pd import matplotlib.pyplot as plt # Importing Data from sklearn.datasets import load_boston boston = load_boston()
حالا دو ویژگی shape (شکل داده ها) و feature names (نام ویژگی های دیتاست) را با هم می بینیم.
boston.data.shape

boston.feature_names

در این مرحله داده ها را از آرایه ای چند بعدی به دیتافریم تبدیل می کنیم و نام ویژگی ها را به داده ها اضافه می کنیم.
data = pd.DataFrame(boston.data) data.columns = boston.feature_names data.head(10)
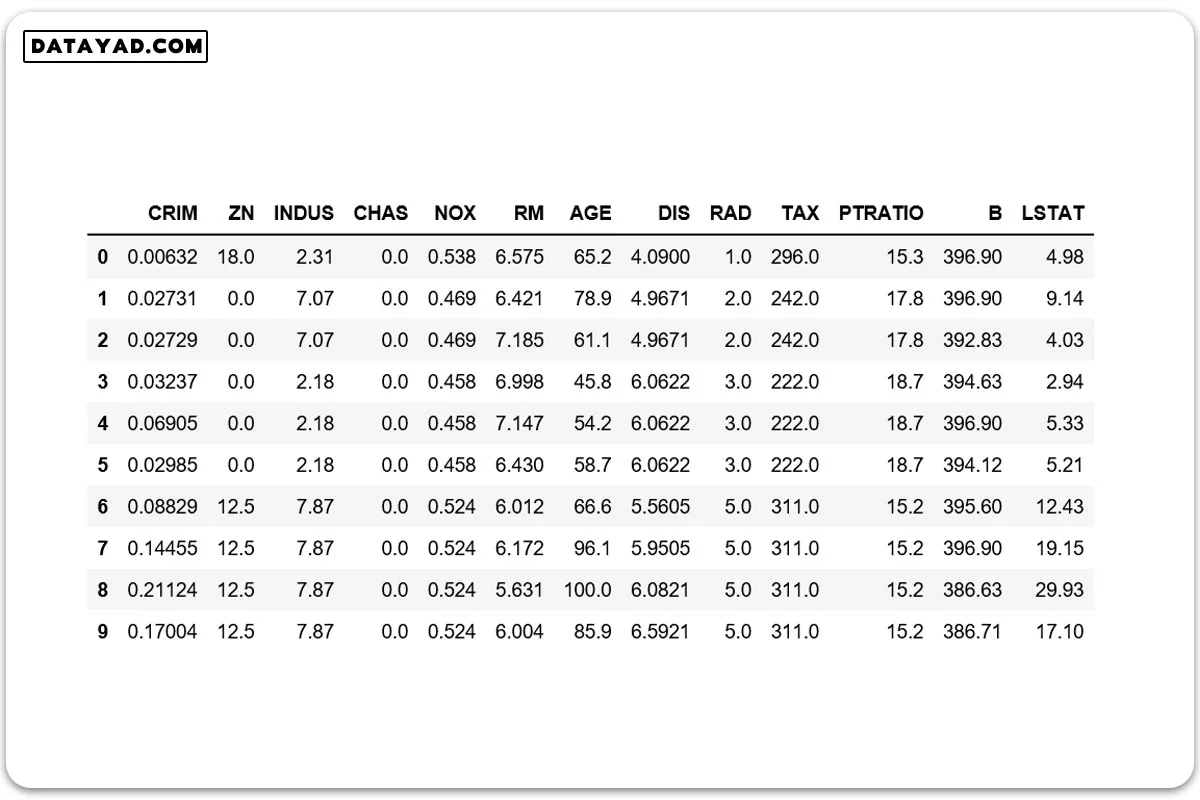
افزودن ستون ‘قیمت’ به دیتاست.
# Adding 'Price' (target) column to the data boston.target.shape

نمایش چند ردیف از داده های دیتاست به همراه قیمت:
data['Price'] = boston.target data.head()
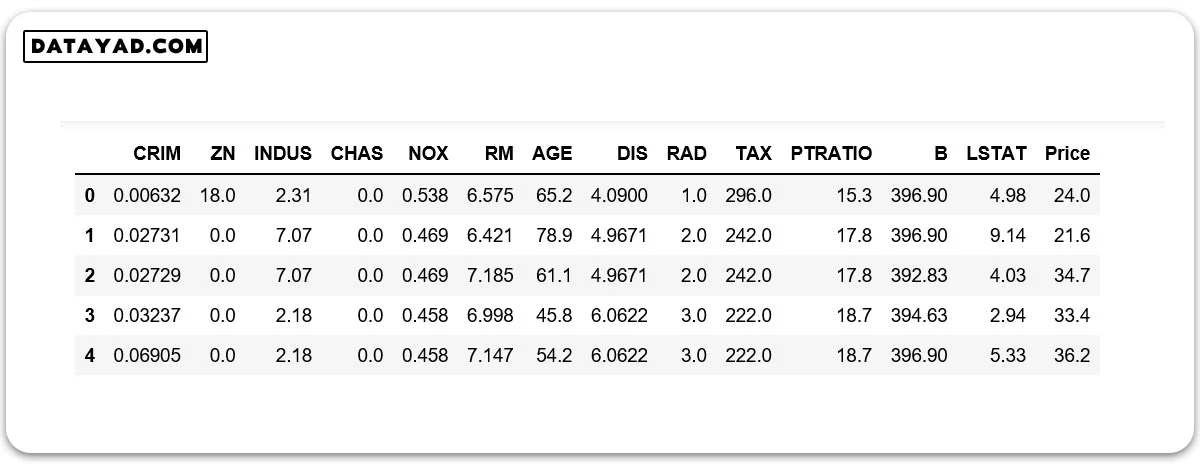
نمایش توصیف (Description) دیتاست بوستون.
data.describe()
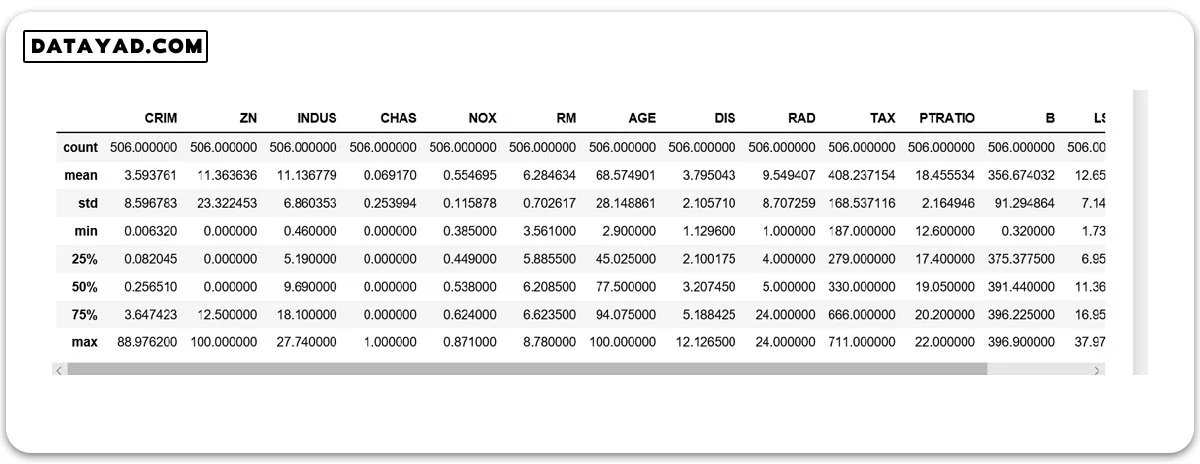
نمایش اطلاعات (info) دیتاست بوستون.
data.info()
دریافت داده های ورودی و خروجی و سپس تقسیم داده ها به مجموعه های آموزشی (train) و آزمایشی (test).
# Input Data
x = boston.data
# Output Data
y = boston.target
# splitting data to training and testing dataset.
#from sklearn.cross_validation import train_test_split
#the submodule cross_validation is renamed and deprecated to model_selection
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size =0.2,
random_state = 0)
print("xtrain shape : ", xtrain.shape)
print("xtest shape : ", xtest.shape)
print("ytrain shape : ", ytrain.shape)
print("ytest shape : ", ytest.shape)

اعمال مدل رگرسیون خطی بر روی دیتاست و پیشبینی قیمت ها.
# Fitting Multi Linear regression model to training model from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(xtrain, ytrain) # predicting the test set results y_pred = regressor.predict(xtest)
رسم نمودار پراکندگی (Scatter Plot) برای نمایش نتایج پیشبینی:
مقایسه مقادیر ‘ y_true ‘ (مقادیر حقیقی) با ‘ y_pred’ (مقادیر پیشبینی شده).
# Plotting Scatter graph to show the prediction
# results - 'ytrue' value vs 'y_pred' value
plt.scatter(ytest, y_pred, c = 'green')
plt.xlabel("Price: in $1000's")
plt.ylabel("Predicted value")
plt.title("True value vs predicted value : Linear Regression")
plt.show()
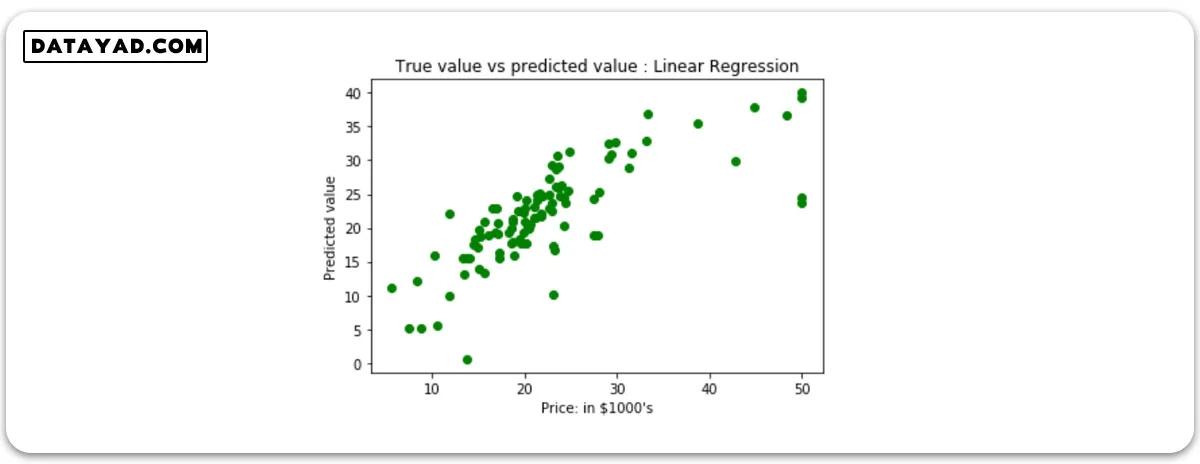
نتایج رگرسیون خطی
نمایش مقادیر خطای مربع میانگین و خطای مطلق میانگین.
from sklearn.metrics import mean_squared_error, mean_absolute_error
mse = mean_squared_error(ytest, y_pred)
mae = mean_absolute_error(ytest,y_pred)
print("Mean Square Error : ", mse)
print("Mean Absolute Error : ", mae)
Mean Square Error : 33.448979997676496 Mean Absolute Error : 3.8429092204444966
براساس نتایج، دقت مدل ما تنها ۶۶.۵۵ درصد است. بنابراین، مدل تهیه شده برای پیشبینی قیمت های مسکن چندان مناسب نیست. اما با به کارگیری دیگر الگوریتم ها و روشهای مختلف یادگیری ماشین می توان نتایج پیشبینی را بهبود داد.
در اینجا چند روش برای بهبود مدل پیشنهاد می شود:
۱ . انتخاب ویژگی (Feature Selection)
۲ . اعتبارسنجی متقابل (Cross Validation)
۳ . تنظیم هایپرپارامترها (Hyperparameter tuning)
جهت مشاهده کد بروزرسانی شده و سازگار با ورژن های جدید کتابخانه ها در Colab روی لینک زیر کلیک کنید:











