

در درس شانزدهم آموزش رایگان یادگیری ماشین می خواهیم یاد بگیریم که طبقه بندی چیست و با انواع الگوریتم های آن در ماشین لرنینگ آشنا شویم.
طبقه بندی (Classification)، همانطور که از نامش مشخص است، یعنی «دستهبندی چیزها» به گروههای کوچکتر؛ ولی این بار توسط یک ماشین! اگر فکر میکنید خیلی جذاب نیست، فقط تصور کنید کامپیوتر میتواند تفاوت شما را با یک ناشناس تشخیص دهد یا تمایز یک سیبزمینی را از یک گوجهفرنگی بفهمد یا فرق بین نمرهی A و F را بشناسد. حالا جالب شد، نه؟
طبقهبندی جزو انواع یادگیری ماشین تحت نظارت است که در آن از دادههایی با برچسب برای آموزش استفاده میشود. در یادگیری ماشین و آمار، موضوع طبقهبندی این است که بر اساس دادههای آموزشی که قبلاً دستهبندی شدهاند، بفهمیم یک داده جدید به کدام دسته یا گروه از میان مجموعهها متعلق است.
طبقه بندی چیست؟
طبقهبندی، یک فرایند برای قرار دادن دادهها یا اشیاء در دستههای معینی است که بر اساس ویژگیهای آنها تعیین میشود. در یادگیری ماشین، طبقهبندی یک روش از یادگیری نظارت شده است، جایی که الگوریتم بر روی مجموعهای از دادههای دارای برچسب آموزش میبیند تا بتواند دسته دادههای جدید و ناشناخته را پیشبینی کند.
هدف از طبقهبندی این است که مدلی بسازیم که قادر باشد به مشاهدات جدید، بر اساس ویژگیهای آنها، برچسب مناسبی اختصاص دهد.
به عنوان مثال، فرض کنید مدلی را بر روی تصاویری که به عنوان سگ یا گربه برچسبگذاری شدهاند آموزش دادهایم؛ سپس از این مدل استفاده میشود تا تصاویر جدیدی که تا به حال ندیده است را بر اساس ویژگیهایی مثل رنگ، بافت و شکل طبقهبندی کند.
انواع طبقه بندی یا Classification
طبقهبندی به دو دسته تقسیم میشود:
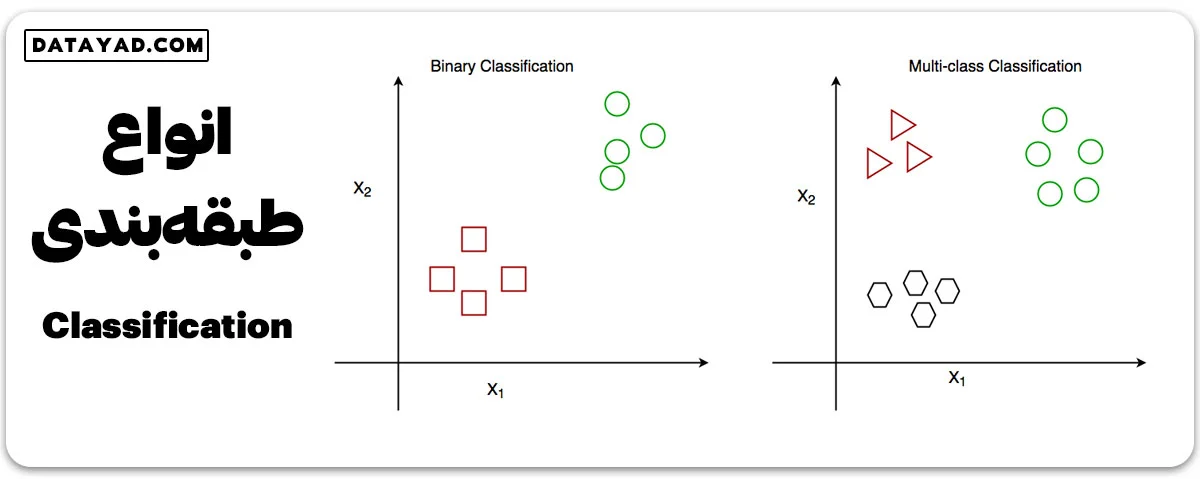
1- طبقهبندی دودویی (باینری – Binary)
در این نوع طبقهبندی هدف این است که ورودی را در یکی از دو دسته قرار دهیم. مثلاً، بر اساس وضعیت سلامت فرد، تصمیم میگیریم که آیا او به یک بیماری خاص مبتلا است یا نه.
2- طبقهبندی چنددستهای (چندگانه – Multiclass)
در اینجا هدف این است که ورودی را در یکی از چند دسته مختلف قرار دهیم. به عنوان مثال، با داشتن اطلاعات مختلف درباره گونههای گلها، میخواهیم بفهمیم مشاهده ما به کدام گونه متعلق است.الگوریتمهایی مانند Naive Bayes و الگوریتم مکمل بیز ساده (CNB) برای این نوع مسائل کاربرد فراوانی دارند.
انواع الگوریتمهای طبقه بندی
ما با طبقه بندیکننده های مختلفی روبرو هستیم:
✔️ طبقهبندیکنندههای خطی
این طبقهبندیکنندهها یک مرز تصمیم ساده و خطی بین دستهها ترسیم میکنند. به خاطر سادگی خود، از نظر محاسباتی بسیار سریع عمل میکنند. مثالهایی از این نوع:
- رگرسیون لجستیک
- ماشینهای بردار پشتیبان با کرنل خطی
- پرسپترون تکلایه
- طبقهبندیکننده گرادیان تصادفی (SGD)
✔️ طبقه بندیکننده های غیر خطی
این طبقهبندیکنندهها قادرند به روابط پیچیدهتر بین ویژگیها و هدف پاسخ دهند و مرز تصمیم غیرخطی میان دستهها ایجاد میکنند. مثالهایی از آنها:
- K-نزدیکترین همسایه
- Kernel SVM
- بیز ساده
- درخت تصمیم
- طبقهبندیکنندههای ترکیبی:
- جنگلهای تصادفی
- AdaBoost
- طبقهبندیکننده Bagging
- طبقهبندیکننده Voting
- طبقهبندیکننده ExtraTrees
- شبکههای عصبی مصنوعی چندلایه
انواع یادگیرندگان در الگوریتمهای طبقهبندی
در یادگیری ماشین، یادگیرندگان طبقهبندی نیز میتوانند به دو دسته “تنبل” یا “فوری” طبقهبندی شوند.
✔️ یادگیرندگان تنبل
این یادگیرندگان، که به نام یادگیرندگان مبتنی بر نمونه نیز شناخته میشوند، در مرحله آموزش، یادگیری ندارند. به جای آن، تنها دادههای آموزشی را ذخیره میکنند و از آن برای طبقهبندی نمونههای جدید در زمان پیشبینی استفاده میکنند. چون در زمان پیشبینی به محاسبات نیاز ندارد، سرعت بالایی دارد. اما در فضاهای با ابعاد بالا یا زمانی که تعداد نمونههای آموزشی زیاد است، کمتر موثر است. مثالهایی از یادگیرندگان تنبل شامل k-نزدیکترین همسایه و case-based reasoning است.
✔️ یادگیرندگان فوری
این یادگیرندگان، که به نام یادگیرندگان مبتنی بر مدل نیز شناخته میشوند، در مرحله آموزش، از دادههای آموزشی، یادگیری مدل دارند و از این مدل برای طبقهبندی نمونههای جدید در زمان پیشبینی استفاده میکنند. این نوع یادگیرنده در فضاهای با ابعاد بالا که دارای دادههای آموزشی زیادی هستند، موثرتر است. مثالهایی از یادگیرندگان فوری شامل درختان تصمیم، جنگلهای تصادفی و ماشینهای بردار پشتیبان هستند.
ارزیابی مدل طبقهبندی
ارزیابی مدل طبقهبندی گام مهمی در یادگیری ماشین است چرا که کمک میکند تا کارایی و توانایی تعمیم مدل روی دادههای جدید و ندیدهشده را سنجید. چندین معیار و روش برای ارزیابی یک مدل طبقهبندی وجود دارد که بسته به مسئله و نیازهای خاص مورد استفاده قرار میگیرند. معیارهای متداول ارزیابی به شرح زیر هستند:
✔️ دقت طبقهبندی (accuracy)
نسبت تعداد نمونههایی که به درستی طبقهبندی شدهاند به تعداد کل نمونهها در مجموعه آزمون. این معیار ساده و قابل درک است اما در مجموعه دادههای نامتوازن، که کلاس اکثریت بر دقت حاکم است، ممکن است گمراه کننده باشد.
✔️ ماتریس درهمریختگی
جدولی که تعداد مثبتهای صحیح، منفیهای صحیح، مثبتهای غلط و منفیهای غلط را برای هر کلاس نشان میدهد و میتوان با استفاده از آن، معیارهای ارزیابی مختلفی را محاسبه کرد.
✔️ دقت (تشابه) و بازخوانی (Precision and Recall)
دقت نسبت تعداد مثبتهای صحیح به تعداد کل مثبتهای پیشبینی شده را اندازهگیری میکند، در حالی که بازخوانی، نسبت مثبتهای صحیح به تعداد کل مثبتهای واقعی را اندازهگیری میکند. این معیارها در مواردی که یک کلاس از دیگری مهمتر است یا زمانی که میان مثبتهای غلط و منفیهای غلط تعادلی وجود دارد، مفید هستند.
✔️ امتیاز F1
میانگین هارمونیکی از دقت و بازخوانی، که به صورت محاسبه میشود. این معیار برای مجموعههای داده نامتوازن که هر دوی دقت و بازخوانی مهم هستند، مفید است.
✔️ منحنی ROC و AUC
منحنی مشخصه عملکرد (ROC) نموداری از نرخ مثبتهای صحیح (بازخوانی) در مقابل نرخ مثبتهای غلط (1-خصوصیت) برای مقادیر آستانه مختلف تابع تصمیم طبقهبندی است. مساحت زیر منحنی (AUC) کارایی کلی طبقهبندی را اندازهگیری میکند، با مقادیری که از 0.5 (حدس تصادفی) تا 1 (طبقهبندی کامل) متغیر میشوند.
✔️ اعتبارسنجی متقابل (Cross-Validation)
روشی که دادهها را به چندین قسمت تقسیم میکند و مدل را برای هر قسمت آموزش میدهد، در حالی که روی بقیه آنها آزمون انجام میشود، تا بتوان به تخمین موثقتری از کارایی مدل دست یافت.
انتخاب معیار(های) مناسب ارزیابی بر اساس مسئله و نیازهای خاص بسیار مهم است. همچنین باید از بیشبرازش جلوگیری کرد و مدل را با استفاده از دادههای آزمون مستقل ارزیابی نمود.
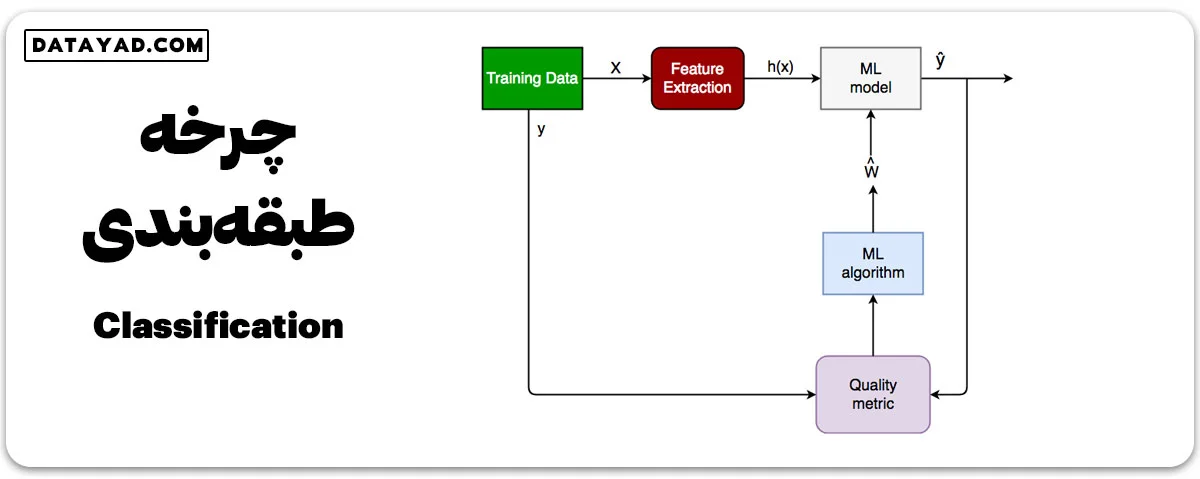
طبقهبندی چگونه کار میکند؟
در طبقهبندی، هدف اصلی این است که یک مدل روی دادههایی با برچسب آموزش داده شود تا الگوها و ارتباطات بین ورودیها و برچسبهای آنها را فهمیده و بیاموزد. وقتی مدل آموزش داده شود، میتوانیم از آن برای پیشبینی برچسبها برای دادههای جدید و ندیده استفاده کنیم.
فرآیند طبقهبندی شامل گام های زیر است:
1- فهم مسئله
قبل از شروع طبقهبندی، باید به درستی مسئلهای که میخواهید حل کنید را متوجه شوید. کدام برچسبها را میخواهید پیشبینی کنید؟ چطور دادههای ورودی با این برچسبها ارتباط دارند؟
- به عنوان مثال، فرض کنید میخواهیم بر اساس 7 ویژگی مستقل پیشبینی کنیم که آیا یک بیمار، بیماری خاصی دارد یا نه. این به این معناست که دو نتیجه ممکن داریم:
- بیمار مبتلا به بیماری است، یعنی “صحیح – True”.
- بیمار مبتلا نیست، یعنی “غلط – False”.
- این یک مسئله طبقهبندی دودویی است.
2- آماده سازی داده
وقتی با مسئله آشنا شدید، مرحله بعد آمادهکردن دادههاست. این مرحله شامل جمعآوری، پیش پردازش داده ها و تقسیم داده ها به دستههای آموزش، اعتبارسنجی و تست میشود. اینجا، دادهها تمیز و به شکل مناسب برای الگوریتم طبقهبندی تبدیل میشوند.
- X: ویژگی مستقلی است که به صورت ماتریسی با ابعاد N*M میباشد که N تعداد مشاهدات و M تعداد ویژگیها را نمایان میکند.
- y: برداری با طول N است که برای هر مشاهده، کلاس پیشبینی شده را نشان میدهد.
۳- استخراج ویژگیها
ویژگیهای مؤثر و مرتبط از دادهها استخراج میشوند تا بین کلاسها تمایز بیافرینیم.
- به عنوان مثال، فرض کنید دادههای ورودی X، شامل 7 ویژگی مستقل است، اما فقط 5 ویژگی از آنها بر روی نتیجه تاثیرگذارند و 2 ویژگی باقیمانده همبستگی کم یا بیمعنی دارند. در این حالت، ما فقط از این 5 ویژگی برای آموزش مدل استفاده میکنیم.
۴- انتخاب مدل
برای طبقهبندی، انواع مختلفی از مدلها مانند رگرسیون لجستیک، درخت تصمیم، ماشینهای بردار پشتیبان و شبکههای عصبی در دسترس هستند. انتخاب مدل مناسب برای مسئله شما، با توجه به حجم و پیچیدگی دادهها و منابع محاسباتی که دارید، اهمیت دارد.
۵- آموزش مدل
پس از انتخاب یک مدل، مرحله بعدی آموزش آن با دادههای آموزشی است. در این فرآیند، پارامترهای مدل به نحوی تغییر مییابند تا اختلاف بین برچسبهای پیشبینی شده و برچسبهای واقعی کلاس در دادههای آموزشی کاهش یابد.
۶- ارزیابی مدل
پس از آموزش مدل، لازم است که عملکرد آن روی یک مجموعه اعتبارسنجی بررسی شود. این ارزیابی به شما دید خوبی از عملکرد مدل بر روی دادههای جدید و ناشناخته میدهد.
- لگاریتم خطا یا خطای انتروپی متقابل، ماتریس درهمریختگی، دقت، بازخوانی و منحنی AUC-ROC از معیارهای کیفیتی هستند که برای اندازهگیری عملکرد مدل استفاده میشوند.
۷- تیونینگ مناسب مدل
اگر عملکرد مدل مطلوب نبود، میتوانید با تنظیم پارامترها یا امتحان یک مدل متفاوت، آن را بهینهسازی کنید.
۸- استقرار مدل
در نهایت، هنگامی که از عملکرد مدل راضی شدیم، میتوانیم آن را استقرار دهیم تا پیشبینیهایی روی دادههای جدید انجام دهد. این مدل میتواند برای حل مشکلات واقعی استفاده شود.
کاربردهای الگوریتم های طبقهبندی
الگوریتمهای طبقهبندی در موارد زیادی در زندگی روزمره به کار میروند. در زیر به برخی از این کاربردها اشاره شده است:
- جداسازی ایمیلهای اسپم
- ارزیابی ریسک اعتبار
- تشخیصهای طبی
- طبقهبندی تصاویر
- تحلیل و بررسی احساسات
- کشف کلاهبرداری
- نظارت و بهبود کیفیت
- سیستمهای پیشنهادی
پیادهسازی
تا اینجا گفتیم که طبقه بندی چیست و با انواع الگوریتم های آن آشنا شدیم. حالا بیایید بصورت عملی با طبقهبندی آشنا شویم. قصد داریم چندین طبقهبندی کننده را مورد بررسی قرار دهیم و عملکرد آنها را بر روی یک مجموعه دادهی شناخته شده، یعنی مجموعه دادهی ایریس، مقایسه کنیم.
برای اجرای این کد به موارد زیر نیاز دارید:
- پایتون
- Scipy و Numpy
- Pandas
- Scikit-learn
# Importing the required libraries
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn import datasets
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
# import the iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# splitting X and y into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1)
# GAUSSIAN NAIVE BAYES
gnb = GaussianNB()
# train the model
gnb.fit(X_train, y_train)
# make predictions
gnb_pred = gnb.predict(X_test)
# print the accuracy
print("Accuracy of Gaussian Naive Bayes: ",
accuracy_score(y_test, gnb_pred))
# print other performance metrics
print("Precision of Gaussian Naive Bayes: ",
precision_score(y_test, gnb_pred, average='weighted'))
print("Recall of Gaussian Naive Bayes: ",
recall_score(y_test, gnb_pred, average='weighted'))
print("F1-Score of Gaussian Naive Bayes: ",
f1_score(y_test, gnb_pred, average='weighted'))
# DECISION TREE CLASSIFIER
dt = DecisionTreeClassifier(random_state=0)
# train the model
dt.fit(X_train, y_train)
# make predictions
dt_pred = dt.predict(X_test)
# print the accuracy
print("Accuracy of Decision Tree Classifier: ",
accuracy_score(y_test, dt_pred))
# print other performance metrics
print("Precision of Decision Tree Classifier: ",
precision_score(y_test, dt_pred, average='weighted'))
print("Recall of Decision Tree Classifier: ",
recall_score(y_test, dt_pred, average='weighted'))
print("F1-Score of Decision Tree Classifier: ",
f1_score(y_test, dt_pred, average='weighted'))
# SUPPORT VECTOR MACHINE
svm_clf = svm.SVC(kernel='linear') # Linear Kernel
# train the model
svm_clf.fit(X_train, y_train)
# make predictions
svm_clf_pred = svm_clf.predict(X_test)
# print the accuracy
print("Accuracy of Support Vector Machine: ",
accuracy_score(y_test, svm_clf_pred))
# print other performance metrics
print("Precision of Support Vector Machine: ",
precision_score(y_test, svm_clf_pred, average='weighted'))
print("Recall of Support Vector Machine: ",
recall_score(y_test, svm_clf_pred, average='weighted'))
print("F1-Score of Support Vector Machine: ",
f1_score(y_test, svm_clf_pred, average='weighted'))
خروجی:
Accuracy of Gaussian Naive Bayes: 0.9333333333333333 Precision of Gaussian Naive Bayes: 0.9352007469654529 Recall of Gaussian Naive Bayes: 0.9333333333333333 F1-Score of Gaussian Naive Bayes: 0.933615520282187 Accuracy of Decision Tree Classifier: 0.9555555555555556 Precision of Decision Tree Classifier: 0.9555555555555556 Recall of Decision Tree Classifier: 0.9555555555555556 F1-Score of Decision Tree Classifier: 0.9555555555555556 Accuracy of Support Vector Machine: 1.0 Precision of Support Vector Machine: 1.0 Recall of Support Vector Machine: 1.0 F1-Score of Support Vector Machine: 1.0
نتیجهگیری درس طبقه بندی (Classification)
طبقهبندی یک زمینه گسترده و عمیق در مطالعات است و اگرچه فقط یک بخش کوچک از یادگیری ماشین را شامل میشود، ولی از جمله بخشهای مهم آن است.











