

یکی از روش های یادگیری ماشین، یادگیری ماشین تحت نظارت یا نظارت شده (Supervised Learning) است که در درس پانزدهم آموزش رایگان یادگیری ماشین با پایتون می خواهیم به طور مفصل در مورد آن صحبت کنیم.
وقتی میگوییم یک ماشین در مورد مجموعهای از وظایف، از تجربیات گذشته (دادههایی که به آن داده شده) یاد میگیرد، منظور این است که عملکرد آن در یک وظیفه خاص با افزایش تجربه بهبود می یابد.
به عنوان مثال، فرض کنید یک ماشین میخواهد پیشبینی کند که آیا یک مشتری در این سال محصول خاصی مثل “آنتیویروس” را میخرد یا نه؟ ماشین با استفاده از دانش یا تجربیات قبلی این کار را انجام میدهد. یعنی، او نگاهی به دادههای محصولاتی میاندازد که مشتری در سالهای گذشته خریده است و اگر مشتری هر سال یک آنتیویروس را خریده باشد، آن وقت احتمال زیادی هست که او در این سال نیز آنتیویروس را بخرد. این بیان، نحوه عملکرد یادگیری ماشین در سطح ابتدایی و مفهومی است.
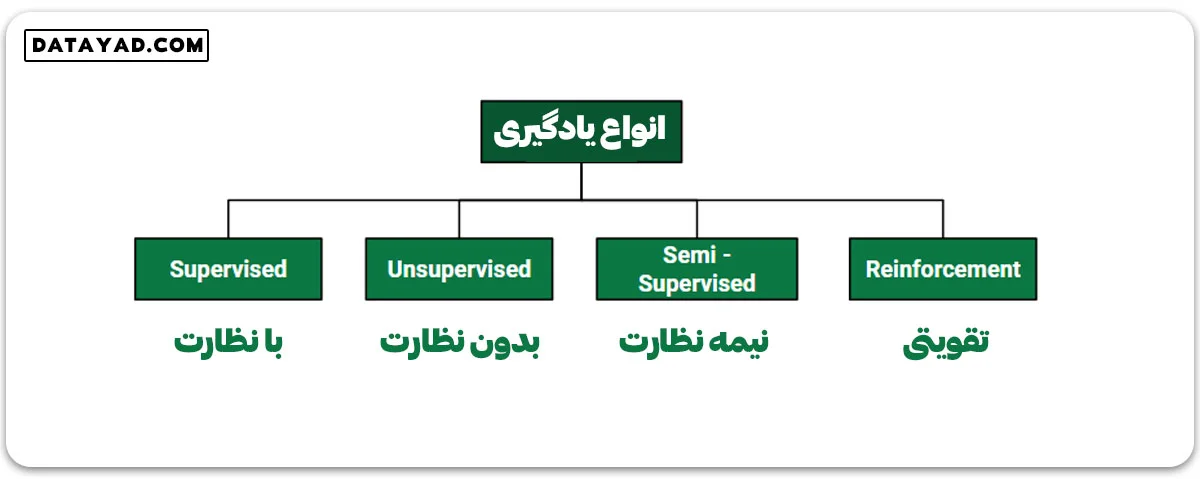
یادگیری ماشین تحت نظارت
یادگیری تحت نظارت یک روش یادگیری ماشین است که در زمینههای متنوعی مانند مالی، بهداشت، بازاریابی و غیره به طور گسترده استفاده میشود.
در این روش، الگوریتم با استفاده از دادههایی که قبلاً برچسبزده شدهاند، آموزش میبیند تا بتواند بر اساس ورودیهای جدید پیشبینی یا تصمیم بگیرد.
در یادگیری تحت نظارت، الگوریتم نسبت میان دادههای ورودی و خروجی را فهمیده و این نسبت را از یک مجموعه داده برچسبزده که شامل جفتهای ورودی و خروجی است، یاد میگیرد.
هدف اصلی این الگوریتم فهمیدن رابطه میان دادههای ورودی و خروجی است تا بتواند در مواجهه با دادههای جدید و بدون برچسب، پیشبینیهای دقیقی انجام دهد.
یادگیری تحت نظارت وقتی انجام میشود که مدل بر روی یک مجموعه داده با برچسب آموزش ببیند. یک مجموعه داده با برچسب، مجموعهای است که هم پارامترهای ورودی و هم پارامترهای خروجی را دارد. در این نوع یادگیری، هر دو مجموعه داده آموزشی و اعتبارسنجی با برچسب هستند، همانطور که در شکلهای زیر نشان داده شده است.
مجموعه دادههای با برچسب مورد استفاده در یادگیری تحت نظارت، از ویژگیهای ورودی و برچسبهای خروجی متناظر تشکیل شده است. ویژگیهای ورودی، صفات یا خصوصیات داده هستند که برای انجام پیشبینیها استفاده میشوند، در حالی که برچسبهای خروجی، نتایج مورد نظر یا هدفهایی هستند که الگوریتم سعی دارد آنها را پیشبینی کند.
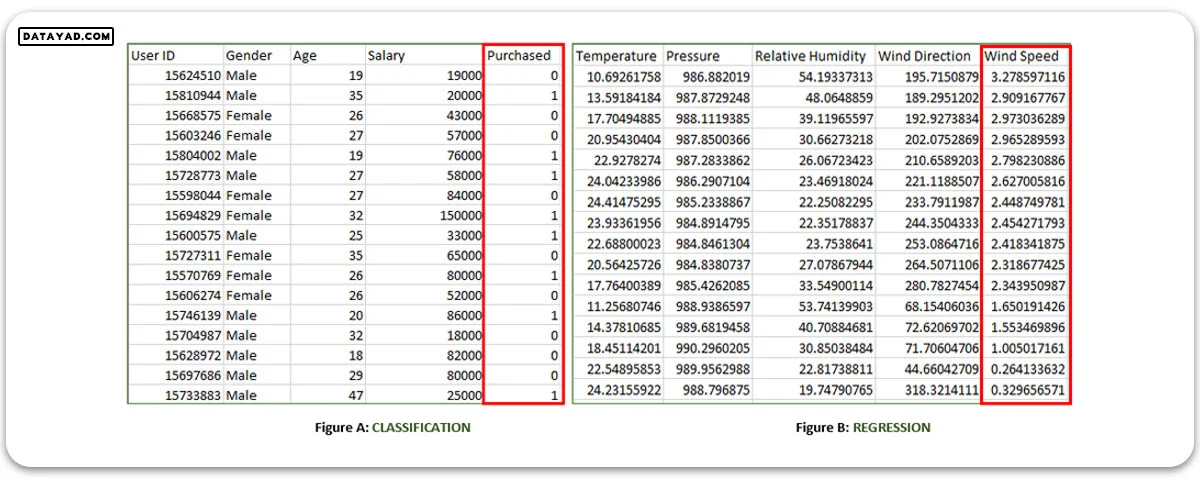
هر دو شکل بالا دارای مجموعه دادههای با برچسب به شرح زیر است:
- شکل A: شکل سمت چپ یک مجموعه داده از یک فروشگاه است که برای پیشبینی اینکه آیا یک مشتری محصول مورد نظر را خریداری میکند یا نه، بر اساس جنسیت، سن و حقوق وی مورد استفاده قرار میگیرد.
ورودی: جنسیت، سن، حقوق
خروجی: خریداری شده یعنی 0 یا 1؛ 1 به این معناست که مشتری محصول را خریداری میکند و 0 به این معناست که مشتری آن را خریداری نمیکند.
- شکل B: این شکل یک مجموعه داده متورولوژیکی است که برای پیشبینی سرعت باد بر اساس پارامترهای مختلف استفاده میشود.
ورودی: نقطه شبنم، دما، فشار، رطوبت نسبی، جهت باد
خروجی: سرعت باد
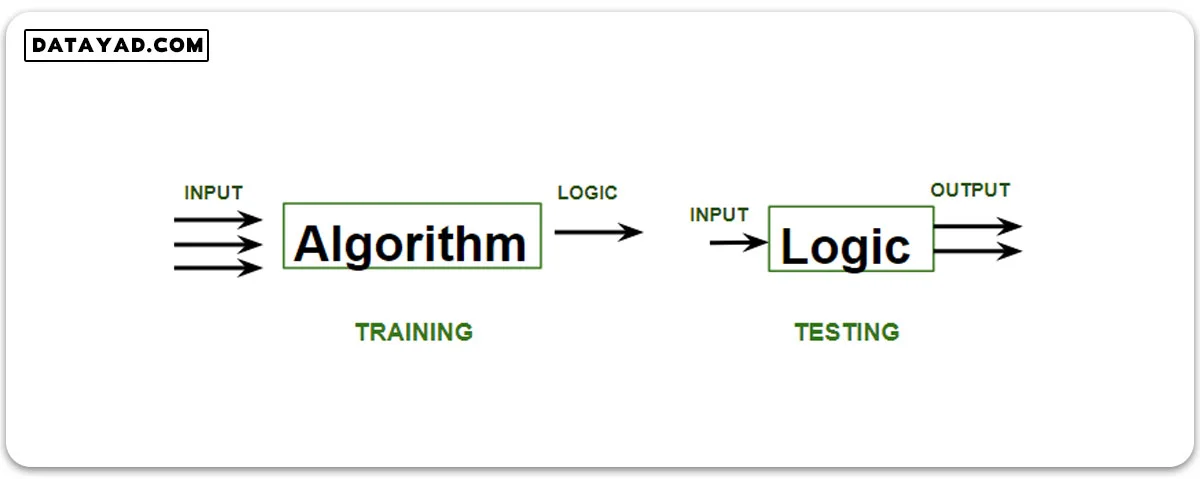
آموزش سیستم
در هنگام آموزش مدل، دادهها معمولاً با نسبت 80 به 20 تقسیم میشوند، یعنی 80 درصد به عنوان دادههای آموزشی و باقیمانده به عنوان دادههای آزمون. در دادههای آموزشی، هم ورودی و هم خروجی برای 80 درصد از دادهها آموزش داده میشود.
مدل فقط از دادههای آموزشی یاد میگیرد. ما از الگوریتم های یادگیری ماشین برای ساخت مدل خود استفاده میکنیم. یادگیری به این معناست که مدل منطق خودش را بسازد.
پس از آماده شدن مدل، زمان آزمون آن فرا رسیده است. در هنگام آزمون، ورودی از 20 درصد باقیمانده از دادهها که مدل قبلاً ندیده است، وارد میشود، مدل مقداری را پیشبینی میکند و ما آن را با خروجی واقعی مقایسه کرده و دقت را محاسبه میکنیم.
انواع الگوریتمهای یادگیری تحت نظارت
یادگیری تحت نظارت معمولاً به دو دسته اصلی تقسیم میشود:
1- رگرسیون (regression)
2- طبقهبندی (classification)
در رگرسیون، الگوریتم یاد میگیرد یک مقدار خروجی پیوسته را پیشبینی کند، مانند قیمت یک خانه یا دمای یک شهر.
در طبقهبندی، الگوریتم یاد میگیرد یک متغیر خروجی دستهای یا برچسب کلاس را پیشبینی کند، مانند اینکه آیا یک مشتری احتمالاً یک محصول را خریداری میکند یا نه.
یکی از مزایای اصلی یادگیری تحت نظارت این است که:
اجازه میدهد مدلهای پیچیدهای ایجاد شود که میتواند بر دادههای جدید پیشبینیهای دقیقی انجام دهد.
اما، یادگیری تحت نظارت نیاز به مقادیر زیادی از دادههای آموزشی با برچسب دارد تا موثر باشد. علاوه بر این، کیفیت و نمایانگر بودن دادههای آموزشی میتواند تأثیر قابل توجهی بر دقت مدل داشته باشد.
خب گفتیم که یادگیری تحت نظارت میتواند به دو دسته تقسیم گردد:
رگرسیون
رگرسیون یک تکنیک یادگیری تحت نظارت است که برای پیشبینی مقادیر عددی پیوسته بر اساس ویژگیهای ورودی استفاده میشود. هدف از آن برقراری یک رابطه عملکردی بین متغیرهای مستقل و یک متغیر وابسته است، مانند پیشبینی قیمت خانه بر اساس ویژگیهایی مانند اندازه، تعداد اتاقها، و مکان.
هدف این است که تفاوت بین مقادیر پیشبینی شده و واقعی را به حداقل برسانیم با استفاده از الگوریتمهایی مانند رگرسیون خطی، درخت تصمیم، یا شبکه های عصبی، تا مطمئن شویم که مدل الگوهای باطنی موجود در داده را به خوبی درک کرده است.
طبقهبندی
طبقهبندی یک نوع از یادگیری تحت نظارت است که دادههای ورودی را با برچسبهای از پیش تعریف شده دستهبندی میکند. این امر شامل آموزش یک مدل بر روی نمونههای برچسبدار است تا الگوهای میان ویژگیهای ورودی و کلاسهای خروجی را یاد بگیرد.
در طبقهبندی، متغیر هدف یک مقدار غیرعددی است. به عنوان مثال، طبقهبندی ایمیلها به عنوان هرزنامه یا غیر از آن. هدف مدل این است که این یادگیری را عمومیسازی کرده و بر دادههای جدید و نادیده پیشبینیهای دقیقی انجام دهد. الگوریتمهایی مانند درخت تصمیم، ماشین بردار پشتیبان، و شبکههای عصبی به طور معمول برای وظایف طبقهبندی استفاده میشوند.
توجه: الگوریتمهای معمول یادگیری ماشین تحت نظارتی نیز وجود دارد که میتوانند برای هر دو وظیفه رگرسیون و طبقهبندی استفاده شوند.
الگوریتمهای یادگیری ماشین تحت نظارت
یادگیری تحت نظارت میتواند به چندین نوع مختلف تقسیم شود، هر کدام با ویژگیها و کاربردهای منحصر به فرد خود. در زیر برخی از متداولترین انواع الگوریتمهای یادگیری با نظارت آورده شدهاند:
✅ رگرسیون خطی
رگرسیون خطی نوعی از الگوریتم است که برای پیشبینی یک مقدار خروجی پیوسته استفاده میشود. این الگوریتم یکی از سادهترین و پرکاربردترین الگوریتمها در یادگیری تحت نظارت است. در رگرسیون خطی، الگوریتم سعی میکند تا یک رابطه خطی بین ویژگیهای ورودی و مقدار خروجی را پیدا کند. مقدار خروجی بر اساس جمع وزندار ویژگیهای ورودی پیشبینی میشود.
✅ رگرسیون لجستیک
رگرسیون لجستیک نوعی از الگوریتم طبقهبندی است که برای پیشبینی یک متغیر خروجی دودویی استفاده میشود. این الگوریتم به طور رایج در برنامههای یادگیری ماشین استفاده میشود جایی که متغیر خروجی یا صحیح است یا غلط، مانند تشخیص تقلب یا فیلتر کردن هرزنامه. در رگرسیون لجستیک، الگوریتم سعی میکند تا یک رابطه خطی بین ویژگیهای ورودی و متغیر خروجی را پیدا کند. متغیر خروجی سپس با استفاده از یک تابع لجستیک تغییر مییابد تا یک مقدار احتمال بین 0 و 1 تولید کند.
✅ درخت تصمیم
درخت تصمیم یک ساختار شبه درختی است که برای مدلسازی تصمیمات و عواقب احتمالی آنها استفاده میشود.
هر گره داخلی در درخت نمایانگر یک تصمیم است، در حالی که هر گره برگ نمایانگر یک نتیجه احتمالی است. درختهای تصمیم میتوانند برای مدلسازی روابط پیچیده بین ویژگیهای ورودی و متغیرهای خروجی استفاده شوند.
درخت تصمیم نوعی الگوریتم است که برای هر دو وظیفه طبقهبندی و رگرسیون استفاده میشود.
- رگرسیون با درخت تصمیم: با استفاده از درختهای تصمیم، میتوان مقدار مرتبط با گره برگ را پیشبینی کرد.
- طبقهبندی درخت تصمیم: الگوریتم جنگل تصادفی از چندین درخت تصمیم بهره میبرد تا طبقهبندی را بهبود ببخشد و از بیشبرازش جلوگیری کند.
✅ جنگلهای تصادفی
جنگلهای تصادفی از چندین درخت تصمیم تشکیل شدهاند که با هم همکاری میکنند تا پیشبینیها را انجام دهند. هر درخت در جنگل بر روی یک زیرمجموعه متفاوت از ویژگیها و دادههای ورودی آموزش داده شده است. پیشبینی نهایی با جمعبندی پیشبینیهای تمام درختها در جنگل انجام میشود.
جنگلهای تصادفی یک تکنیک یادگیری مجموعهای هستند که برای هر دو وظیفه طبقهبندی و رگرسیون استفاده میشوند.
- رگرسیون با جنگل تصادفی: این روش چندین درخت تصمیم را ترکیب میکند تا از بیشبرازش جلوگیری کرده و دقت پیشبینی را افزایش دهد.
- جنگل تصادفی طبقهبندی کننده: چندین درخت تصمیم را ترکیب میکند تا دقت طبقهبندی را افزایش داده و همزمان از بیشبرازش جلوگیری کند.
✅ ماشین بردار پشتیبان (SVM)
این الگوریتم یک ابرصفحه (هایپرپلین) را برای تقسیم فضای n-بعدی به کلاسهای مختلف ایجاد میکند و دسته مناسب نقاط دادهای جدید را مشخص میکند. نقاط برجستهای که در ایجاد این سطح کمک میکنند، به نام بردارهای پشتیبان شناخته میشوند. به همین دلیل از نام “ماشین بردار پشتیبان” استفاده میشود.
SVM یک الگوریتم است که برای طبقهبندی و همچنین وظایف رگرسیون مورد استفاده قرار میگیرد.
- رگرسیون بردار پشتیبان: این الگوریتم نمونهای از ماشینهای بردار پشتیبان است و برای پیشبینی مقادیر مداوم به کار میرود.
- بردار پشتیبان طبقهبندی کننده: هدف آن یافتن بهترین ابرصفحهای است که فاصله بیشتری میان نقاط مختلف کلاسها ایجاد کند.
✅ K نزدیکترین همسایه (KNN)
این الگوریتم با تعیین k نقطه نزدیک به داده ورودی کار میکند و بر اساس کلاس یا مقدار میانگین همسایهها، پیشبینی میکند. انتخاب k و معیار فاصله، عملکرد KNN را میتواند تغییر دهد. اگرچه قابل فهم است، اما ممکن است به نویز در دادهها حساس باشد و برای نتایج بهتر، انتخاب مناسب k ضروری است.
الگوریتم K-نزدیکترین همسایه (KNN) برای وظایف طبقهبندی و رگرسیون استفاده میشود:
- در رگرسیون K-نزدیکترین همسایه: مقادیر پیوسته با استفاده از میانگین خروجیهای K نزدیکترین همسایه پیشبینی میشود.
- در طبقهبندی K-نزدیکترین همسایه: نقاط داده براساس کلاس غالب K نزدیکترین همسایه طبقهبندی میشوند.
✅ تقویت گرادیان
تقویت گرادیان، آموزندههای ضعیف مانند درختهای تصمیم را ترکیب میکند تا یک مدل قوی ایجاد کند. این الگوریتم به صورت تکراری مدلهای جدیدی را میسازد که اشتباهات سابق را اصلاح میکند. هر مدل جدید برای کاهش خطاهای باقیمانده آموزش داده میشود، که در نتیجه به یک پیشبینی کننده قدرتمند منجر میشود که قادر است با روابط پیچیدهای در دادهها مواجه شود.
تقویت گرادیان نوعی الگوریتم است که برای هر دو وظیفه طبقهبندی و رگرسیون استفاده میشود.
- رگرسیون تقویت گرادیان: با ساختن یک مجموعه از آموزندههای ضعیف، دقت پیشبینی را از طریق آموزش تکراری بهبود میبخشد.
- طبقهبندی تقویت گرادیان: یک گروه از طبقهبندی کنندهها را ایجاد میکند تا دقت پیشبینیها را از طریق تکرارها به طور مداوم افزایش دهد.
مزایای یادگیری نظارت شده
قدرت یادگیری نظارتشده، در توانایی دقیق آن برای پیشبینی الگوها و اتخاذ تصمیمهای مبتنی بر داده در انواع برنامهها قرار دارد. در زیر برخی از مزایای آن آورده شدهاند:
- دادههای آموزشی با برچسب به یادگیری تحت نظارت (Supervised Learning) کمک میکند تا مدلها به طور دقیق الگوها و روابط میان ورودیها و خروجیها را یاد بگیرند.
- مدلهای یادگیری نظارتشده میتوانند دادههای جدید را به طور دقیق پیشبینی و طبقهبندی کنند.
- یادگیری نظارتشده کاربردهای گستردهای دارد، شامل طبقهبندی، رگرسیون و حتی مسائل پیچیدهتر مانند تشخیص تصویر و پردازش زبان طبیعی.
- معیارهای ارزیابی معتبر و موجود، از جمله دقت، تشابه (در اینجا به دلیل آنکه در فارسی هردو کلمه accuracy و precision معنای دقت را میدهند، کلمه precision به تشابه برگردانده شدهاست چرا که این کلمه به معنای تشابه اندازهگیری ها به یکدیگر است درحالی که accuracy به معنای نزدیکی اندازهگیری ها به مقدار واقعی میباشد)، بازخوانی (Recall) و امتیاز F1، امکان ارزیابی عملکرد مدل یادگیری نظارتشده را فراهم میکنند.
معایب یادگیری نظارت شده
هرچند یادگیری نظارتشده مزایای زیادی دارد، اما محدودیتهایی نیز وجود دارد که باید به آنها توجه کرد. این معایب عبارتند از:
- بیشبرازش: مدلها گاهی اوقات به شدت به دادههای آموزشی وابسته میشوند (بیش برازش) و بر روی دادههای جدید کمکی نمیکنند، چرا که حتی نویزهای اضافی را نیز یاد میگیرند.
- طراحی ویژگیها: استخراج ویژگی از دادهی خام امری ضروری است اما گاهی اوقات باید زمان زیادی صرف کنیم تا ویژگیهای مناسب از دادهها استخراج کنیم و این ممکن است نیاز به دانش تخصصی داشته باشد.
- سوگیری در مدلها: اگر دادههای آموزشی ما سوگیری داشته باشد، پیشبینیهای مدل نیز ممکن است غلط باشد.
- جمعآوری دادههای برچسبدار در یادگیری نظارتی میتواند زمانبر و گران باشد و ممکن است نیاز به دانش تخصصی داشته باشد.











