پیش از شروع پیادهسازی رگرسیون خطی با استفاده از تنسورفلو (TensorFlow) ابتدا یک خلاصه مختصری از آن ارائه میدهیم.
خلاصهای از رگرسیون خطی
رگرسیون خطی یک روش آماری بسیار رایج است که به ما امکان میدهد تابع یا رابطه ی موجود در مجموعهای از دادههای پیوسته را یاد بگیریم. به عنوان مثال، ما مجموعهای از نقاط داده x و مقادیر متناظر y را داریم و نیاز است تا رابطه بین آنها که به آن فرضیه (hypothesis) گفته میشود را یاد بگیریم.
در مورد رگرسیون خطی، این فرضیه یک خط مستقیم است، یعنی h(x) = wx + b که در آن w یک بردار به نام وزنها و b یک اسکالر به نام بایاس است. وزنها و بایاس به عنوان پارامترهای مدل شناخته میشوند.
تنها کاری که باید انجام دهیم، تخمین مقادیر w و b با توجه به مجموعه دادههای موجود است به گونهای که فرضیه حاصل، کمترین هزینه J را تولید کند. J تابع هزینه است که به صورت زیر تعریف میشود:
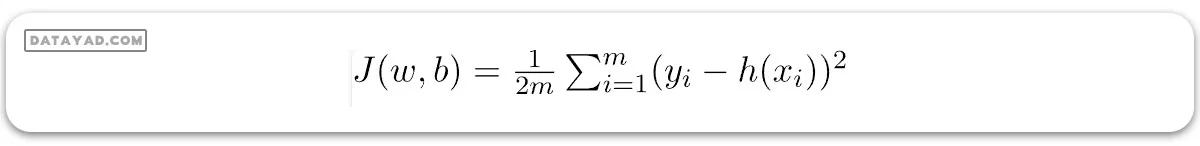
که در آن m تعداد نقاط داده در دیتاست مورد بررسی است. این تابع هزینه همچنین به عنوان خطای میانگین مربعات شناخته میشود.
برای پیدا کردن بهترین مقادیر پارامترها که در آن مقدار J کمترین باشد، از الگوریتم بهینهسازی (optimizer) شناخته شدهای به نام گرادیان کاهشی (Gradient Descent) استفاده میکنیم. که معادله آن به این صورت است:
{w = w – α * δJ/δw b = b – α * δJ/δb}
و این پروسه تا زمانی تکرار میشود که روند محاسبات همگرا (Convergence) شود و به نتیجه مطلوب برسیم. در این پروسه، α نرخ یادگیری نام دارد.
رگرسیون خطی یک روش آماری بسیار پرکاربرد برای مدل سازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل است. TensorFlow نیز یک کتابخانه نرمافزاری متنباز و محبوب در زمینه پردازش دادهها، یادگیری ماشین و کاربردهای یادگیری عمیق است. در اینجا برخی از مزایا و معایب استفاده از TensorFlow برای رگرسیون خطی آورده شده است:
مزایا
1. مقیاسپذیری: TensorFlow برای کار با دیتاست های حجیم طراحی شده و به راحتی میتواند برای کار با دادههای بیشتر و مدلهای پیچیدهتر تنظیم شود.
2. انعطافپذیری: TensorFlow یک API انعطافپذیر ارائه می کند که به کاربران امکان میدهد مدلهای خود را شخصیسازی کنند و الگوریتمهای خود را بهینه نمایند.
3. عملکرد بالا: TensorFlow قابلیت اجرا بر روی چندین پردازنده گرافیکی (GPU) و مرکزی (CPU) را دارد که این امر میتواند روند آموزش مدل را سرعت بخشیده و عملکرد را افزایش دهد.
4. قابلیت یکپارچهسازی: TensorFlow قابل یکپارچهسازی با دیگر کتابخانههای متنباز مانند Numpy، Pandas و Matplotlib را دارد و این امر روند پیشپردازش و تجسم دادهها را سادهتر میکند.
معایب
1. پیچیدگی: یادگیری کار با TensorFlow کمی دشوار است و نیازمند فهم خوبی از اصول یادگیری ماشین و یادگیری عمیق است
2. نیاز به منابع محاسباتی بالا: برای اجرای TensorFlow روی دادههای حجیم، منابع محاسباتی زیادی لازم است که ممکن است هزینهبر باشد.
3. چالشهای عیبیابی: پیدا کردن و رفع خطاها در TensorFlow، مخصوصاً هنگام کار با مدلهای پیچیده، میتواند چالشبرانگیز باشد.
4. استفاده زیاد از حد از منابع سیستمی: برای مدلهای رگرسیون خطی ساده، استفاده از TensorFlow ممکن است زیادی یا بیش ازحد باشد و برای مجموعه دادههای کوچکتر شاید ضرورتی نداشته باشد.
به طور کلی، استفاده از TensorFlow برای رگرسیون خطی مزایای زیادی دارد، اما همچنین دارای برخی معایب نیز هست. هنگام تصمیمگیری در مورد استفاده یا عدم استفاده از TensorFlow، لازم است که پیچیدگی مدل، اندازه دیتاست و منابع محاسباتی موجود را در نظر گرفت.
تنسورفلو (Tensorflow)
TensorFlow یک کتابخانه محاسباتی متنباز است که توسط گوگل ساخته شده و در ساخت برنامههایی با محاسبات عددی پیچیده و/یا برنامه هایی که نیاز به استفاده از واحدهای پردازش گرافیکی (GPU) دارند، بسیار محبوب است.
این ویژگیها TensorFlow را به انتخابی برجسته برای کاربردهای یادگیری ماشین، بهخصوص در زمینه یادگیری عمیق، تبدیل کردهاند. TensorFlow همچنین APIهایی مانند Estimator دارد که ساخت برنامههای یادگیری ماشین را با ارائه سطح بالایی از انتزاع آسانتر میکند.
در این مقاله، ما قصد نداریم از API های سطح بالا استفاده کنیم؛ بلکه قصد داریم مدل رگرسیون خطی را با استفاده از TensorFlow در حالت اجرای تنبل (Lazy Execution Mode) بسازیم. در این حالت، TensorFlow یک گراف جهتدار غیرمدور (DAG) میسازد که تمام محاسبات را ردیابی کرده و آنها را در یک Session TensorFlow اجرا میکند.
پیاده سازی
ابتدا با وارد کردن کتابخانههای لازم شروع میکنیم. برای انجام محاسبات، از Numpy به همراه TensorFlow استفاده خواهیم کرد و برای ترسیم نمودارها، از Matplotlib بهره خواهیم برد.
# Importing libraries import numpy as np # ignore the warning, because you are using version 1 for this program import tensorflow.compat.v1 as tf tf.disable_v2_behavior() import matplotlib.pyplot as plt
برای قابل پیشبینی کردن اعداد تصادفی، seed های ثابتی را هم برای Numpy و هم برای TensorFlow تعریف خواهیم کرد.
np.random.seed(101)
حال، بیایید تعدادی داده تصادفی را برای آموزش مدل رگرسیون خطی تولید کنیم.
# Generating random linear data # There will be 50 data points ranging from 0 to 50 x = np.linspace(0, 50, 50) y = np.linspace(0, 50, 50) # Adding noise to the random linear data x += np.random.uniform(-4, 4, 50) y += np.random.uniform(-4, 4, 50) n = len(x) # Number of data points
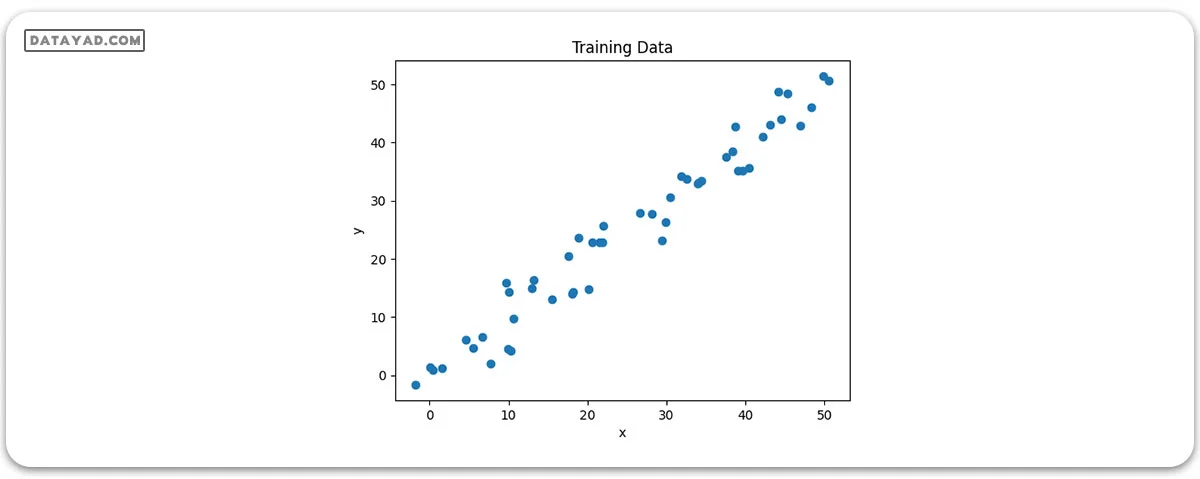
بیایید داده آموزشی را بصریسازی کنیم.
# Plot of Training Data
plt.scatter(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.title("Training Data")
plt.show()
اکنون با تعریف placeholder های X و Y شروع به ساخت مدل خود میکنیم، تا بتوانیم در طی فرآیند آموزش، مثالهای آموزشی X و Y را به بهینهساز تغذیه کنیم.
X = tf.placeholder("float")
Y = tf.placeholder("float")
حالا دو تانسور (Tensor) قابل آموزش در TensorFlow برای وزنها و بایاس تعریف میکنیم و آنها را با استفاده از دستور np.random.randn به صورت تصادفی مقداردهی اولیه میکنیم.
W = tf.Variable(np.random.randn(), name = "W") b = tf.Variable(np.random.randn(), name = "b")
اکنون هایپرپارامترهای (hyperparameters) مدل را تعریف میکنیم، که شامل نرخ یادگیری و تعداد دورههای آموزشی (Epochs) است.
learning_rate = 0.01 training_epochs = 1000
حالا به ایجاد فرضیه، تابع هزینه و بهینهساز می پردازیم. نیازی نیست که بهینهساز گرادیان کاهشی را خودمان بسازیم، چون این ابزار در TensorFlow از پیش تعبیه شده است. بعد از این مرحله، متغیرهای مدل را اولیهسازی خواهیم کرد.
# Hypothesis y_pred = tf.add(tf.multiply(X, W), b) # Mean Squared Error Cost Function cost = tf.reduce_sum(tf.pow(y_pred-Y, 2)) / (2 * n) # Gradient Descent Optimizer optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) # Global Variables Initializer init = tf.global_variables_initializer()
اکنون فرآیند آموزش را در داخل یک Session TensorFlow آغاز خواهیم کرد.
# Starting the Tensorflow Session
with tf.Session() as sess:
# Initializing the Variables
sess.run(init)
# Iterating through all the epochs
for epoch in range(training_epochs):
# Feeding each data point into the optimizer using Feed Dictionary
for (_x, _y) in zip(x, y):
sess.run(optimizer, feed_dict = {X : _x, Y : _y})
# Displaying the result after every 50 epochs
if (epoch + 1) % 50 == 0:
# Calculating the cost a every epoch
c = sess.run(cost, feed_dict = {X : x, Y : y})
print("Epoch", (epoch + 1), ": cost =", c, "W =", sess.run(W), "b =", sess.run(b))
# Storing necessary values to be used outside the Session
training_cost = sess.run(cost, feed_dict ={X: x, Y: y})
weight = sess.run(W)
bias = sess.run(b)
حال بیایید به نتایج نگاه کنیم.
# Calculating the predictions
predictions = weight * x + bias
print("Training cost =", training_cost, "Weight =", weight, "bias =", bias, '\n')
Training cost = 5.3110332 Weight = 1.0199214 bias = 0.02561658
توجه داشته باشید که در این مورد هم وزن و هم بایاس به صورت اسکالر هستند. این به دلیل آن است که ما فقط یک متغیر وابسته را در دادههای آموزشی خود در نظر گرفتهایم. اگر ما m متغیر وابسته در مجموعه دادههای آموزشی خود داشته باشیم، وزن به صورت یک بردار m-بعدی خواهد بود، در حالی که بایاس همچنان یک اسکالر خواهد بود.
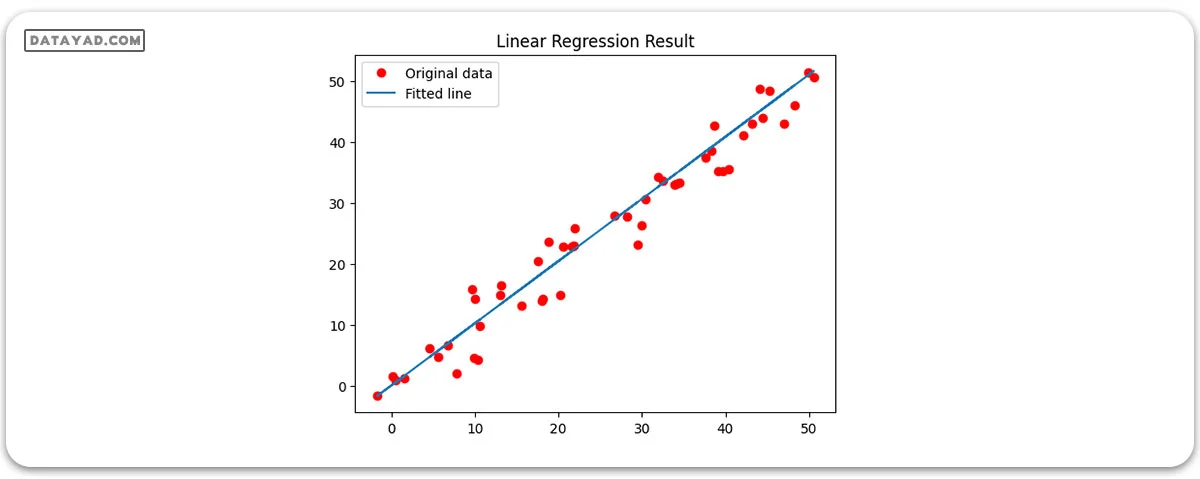
در نهایت، ما نتیجه را روی نمودار ترسیم خواهیم کرد.
# Plotting the Results
plt.plot(x, y, 'ro', label ='Original data')
plt.plot(x, predictions, label ='Fitted line')
plt.title('Linear Regression Result')
plt.legend()
plt.show()