

الگوریتمهای بیز ساده (Naive Bayes algorithms) گروهی از الگوریتمهای یادگیری ماشین پرطرفدار و کاربردی در زمینه طبقهبندی هستند. روشهای مختلفی برای پیادهسازی الگوریتم بیز ساده وجود دارد، مثل بیز ساده گوسی، بیز ساده چندجملهای و غیره.
بیز ساده مکمل (Complement Naive Bayes) نوعی سازگاری از الگوریتم بیز ساده چندجملهای استاندارد است. بیز ساده چندجملهای در مجموعههای داده نامتوازن عملکرد خوبی ندارد. مجموعههای داده نامتوازن آنهایی هستند که تعداد نمونههای یک کلاس بیشتر از دیگر کلاسها است. این بدین معنی است که توزیع نمونهها یکسان نیست. کار کردن با این نوع دادهها میتواند سخت باشد چرا که مدل ممکن است به راحتی به دادهها بیشبرازش کند، به خصوص به کلاسی که تعداد نمونههای بیشتری دارد.
الگوریتم مکمل بیز ساده (CNB) چیست؟
الگوریتم مکمل بیز ساده یا cnb چیست؟ الگوریتم مکمل بیز ساده (CNB) یکی از نسخههای بهبود یافته بیز ساده است که به طور خاص برای مقابله با چالشهای دادههای نامتوازن و بهبود عملکرد دسته بندی طراحی شده است. برخلاف بیز ساده که فرض میکند تمامی ویژگیها مانند کلمات موجود در متون به صورت مستقل از یکدیگر عمل میکنند، CNB از اطلاعات مکمل یعنی بررسی ویژگیهایی که در سایر کلاسها کمتر مشاهده میشوند، بهره میبرد. به عبارت دیگر، اگر از خود بپرسید cnb چیست؟، پاسخ این است که CNB با ترکیب اطلاعات مثبت و منفی موجود در دادهها، شانس بهتری برای تعیین کلاس صحیح در مواجهه با دادههای نامتوازن ارائه میدهد.
این الگوریتم به ویژه در تحلیل دادههای متنی و کاربردهایی مانند تشخیص اسپم، تحلیل احساسات و دسته بندی اخبار مورد توجه قرار گرفته است. روش CNB، با استفاده از آمار دقیق و به روز، توانسته است نسبت به بیز ساده عملکرد بهتری از خود نشان دهد.
تفاوتهای CNB با بیز ساده (Naive Bayes)
برای درک بهتر کارکرد CNB و دانستن اینکه تفاوت بیز ساده با cnb چیست، لازم است به مقایسه آن با بیز ساده بپردازیم. در جدول زیر، تفاوتهای اصلی این دو الگوریتم آورده شده است:
| ویژگی | Naïve Bayes (بیز ساده) | CNB (مکمل بیز ساده) |
| فرض استقلال ویژگیها | فرض میکند که تمامی ویژگیها بهصورت مستقل از یکدیگر عمل میکنند. | از اطلاعات مکمل کلاسها برای کاهش وابستگی بین ویژگیها استفاده میکند. |
| روش محاسبه احتمال | احتمال وقوع هر ویژگی در یک کلاس براساس فراوانی آن در همان کلاس محاسبه میشود. | احتمال وقوع هر ویژگی به همراه فراوانی آن در سایر کلاسها مد نظر قرار میگیرد. |
| عملکرد در دادههای نامتوازن | در مواجهه با دادههای نامتوازن ممکن است عملکرد دقیق نداشته باشد. | با بررسی دادههای مکمل، عملکرد بهتری در دادههای نامتوازن ارائه میدهد. |
| مقاومت در برابر نویز | حساسیت بیشتری نسبت به نویز در دادهها دارد. | نسبت به نویز و دادههای نامتوازن مقاومتر است. |
| کاربردهای اصلی | مناسب برای مسائل ساده دسته بندی متون. | کاربرد گستردهتر در حوزههایی مانند تحلیل احساسات، تشخیص اسپم و طبقهبندی اخبار. |
| پیاده سازی و سادگی | پیاده سازی ساده و سریع؛ مناسب برای مسائل ابتدایی دستهبندی متون. | مشابه بیز ساده از نظر پیادهسازی، اما با بهبود عملکرد در شرایط دشوار. |
با دانستن این موضوع که تفاوت بیز ساده با cnb چیست به این نکته پی میبریم که این تفاوتها نشان میدهد که CNB با بهبود روش محاسبه احتمال و استفاده از اطلاعات مکمل، راهکاری مناسب برای مشکلات موجود در بیز ساده محسوب میشود.
نحوه عملکرد CNB
بیز ساده مکمل به خصوص برای کار با مجموعههای داده نامتوازن مناسب است. در بیز ساده مکمل، به جای محاسبه احتمال تعلق یک آیتم به یک کلاس خاص، احتمال تعلق آیتم به تمام کلاسها محاسبه میشود. این مفهوم کلمه «مکمل» است و به همین دلیل به آن بیز ساده مکمل گفته میشود.
توضیح ساده و گام به گام الگوریتم (بدون استفاده از محاسبات پیچیده)
– برای هر کلاس، احتمال اینکه نمونه داده شده به آن تعلق نداشته باشد را حساب کنید.
– پس از انجام محاسبه برای همه کلاسها، همه مقادیر حساب شده را بررسی کرده و کوچکترین مقدار را انتخاب کنید.
– کوچکترین مقدار (پایینترین احتمال) انتخاب میشود چون این پایینترین احتمال است که آن نمونه متعلق به آن کلاس خاص نیست. این به معنای داشتن بیشترین احتمال برای واقعاً تعلق داشتن به آن کلاس است. پس این کلاس انتخاب میشود.
توجه: ما کلاس با بالاترین مقدار را انتخاب نمیکنیم چون ما در حال محاسبه مکمل احتمال هستیم. کلاسی که بالاترین مقدار را دارد، کمترین احتمال را دارد که نمونه متعلق به آن باشد.
حالا یک مثال را در نظر بگیریم:
فرض کنید ما دو کلاس داریم: سیبها و موزها و باید تشخیص دهیم که آیا یک جمله داده شده مربوط به سیبها یا موزها است، بر اساس فراوانی تعداد مشخصی از کلمات. در اینجا یک نمایش جدولی از مجموعه داده ساده وجود دارد.
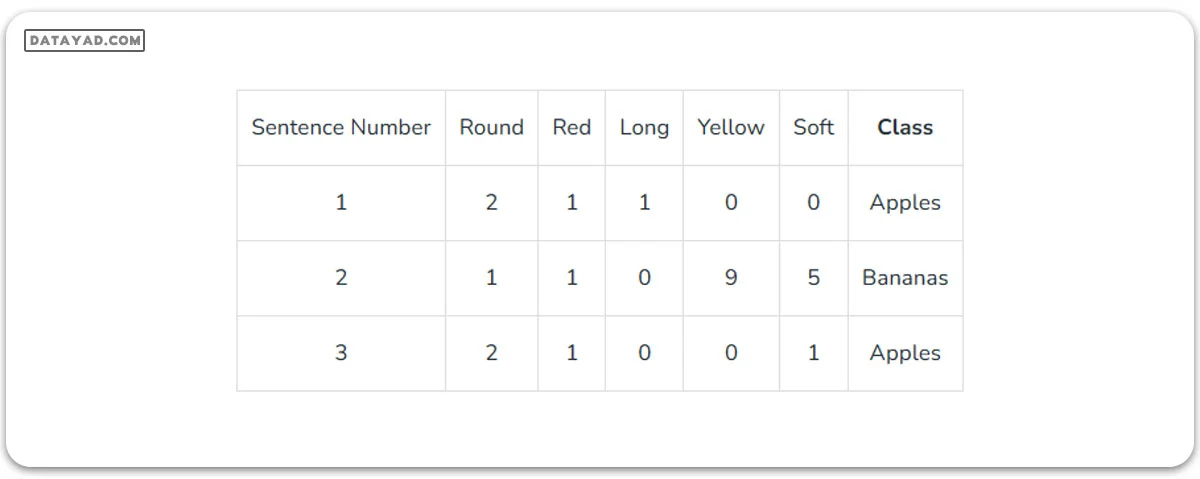
تعداد کل کلمات در کلاس «سیبها»:
(2+1+1) + (2+1+1) = 8
تعداد کل کلمات در کلاس «موزها»:
(1 + 1 + 9 + 5) = 16
بنابراین، احتمال اینکه یک جمله به کلاس «سیبها» تعلق داشته باشد:

به همین ترتیب، احتمال اینکه یک جمله به کلاس «موزها» تعلق داشته باشد:

در جدول بالا، دادهها به گونهای نمایش داده شدهاند که ستونها فراوانی کلمات در یک جمله مشخص را نشان میدهند و سپس نشان میدهند که جمله به کدام کلاس تعلق دارد. قبل از شروع، ابتدا باید با قضیه بیز آشنا شوید. قضیه بیز برای یافتن احتمال وقوع یک رویداد، با توجه به اینکه رویداد دیگری رخ داده است، استفاده میشود. فرمول آن به صورت زیر است:
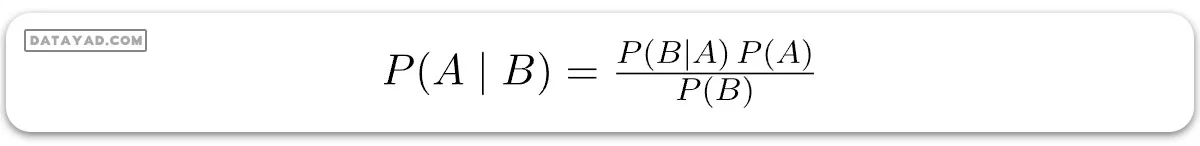
که در آن A و B رویدادها هستند، P(A) احتمال وقوع A است، و P(A|B) احتمال وقوع A با فرض اینکه رویداد B قبلاً رخ داده است. P(B)، احتمال وقوع رویداد B نمیتواند 0 باشد چون قبلاً رخ داده است.
حال بیایید ببینیم که بیز ساده و بیز ساده مکمل چگونه کار میکنند. فرمول الگوریتم بیز ساده معمولی به صورت زیر است:
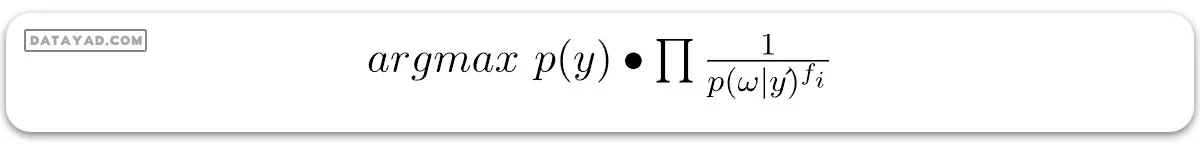
که در آن fi فراوانی برخی ویژگیها است. به عنوان مثال، تعداد دفعاتی که کلمات خاصی در یک جمله رخ میدهند.
اما در بیز ساده مکمل، فرمول به این شکل است:
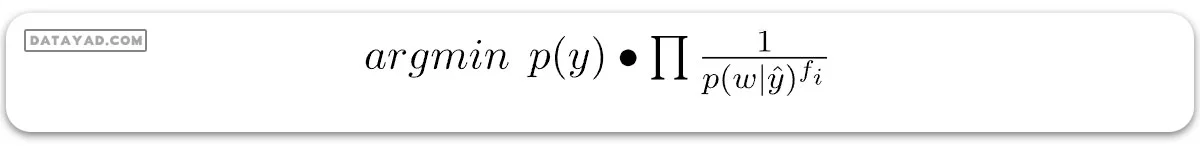
اگر دقیقتر به فرمولها نگاه کنید، میبینید که بیز ساده مکمل فقط معکوس بیز ساده معمولی است. در بیز ساده، کلاسی که بیشترین مقدار را از فرمول به دست میآورد، کلاس پیشبینی شده است. بنابراین، چون بیز ساده مکمل فقط معکوس است، کلاسی که کمترین مقدار را از فرمول CNB به دست میآورد، کلاس پیشبینی شده است.
حال بیایید یک مثال را با استفاده از مجموعه دادههایمان و الگوریتم CNB تحلیل کنیم.

ما باید مقادیر زیر را محاسبه کنیم:

و

ما باید هر دو مقدار را مقایسه کنیم و کلاس با کمترین مقدار را به عنوان کلاس پیشبینی شده انتخاب کنیم. اگر مقدار برای (y = سیبها) کمتر باشد، کلاس پیشبینی شده سیبها خواهد بود، و اگر مقدار برای (y = موزها) کمتر باشد، کلاس پیشبینی شده موزها خواهد بود.
با استفاده از فرمول CNB برای هر دو کلاس، داریم:
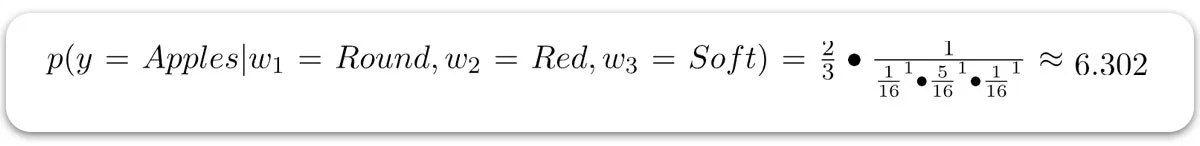
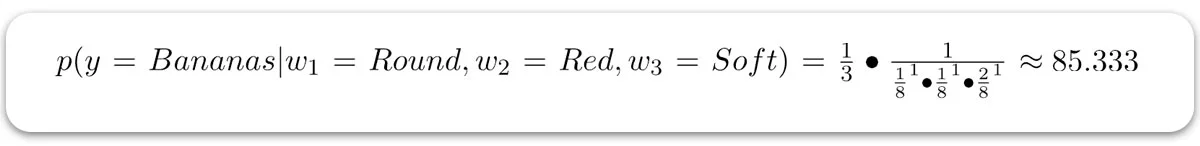
چون 6.302 < 85.333 است، پس کلاس پیشبینی شده سیبها خواهد بود.
ما کلاس با مقدار بالاتر را انتخاب نمیکنیم چون مقدار بالاتر نشان میدهد که احتمال کمتری وجود دارد که یک جمله با آن کلمات متعلق به آن کلاس باشد. همین دلیل است که این الگوریتم بیز ساده مکمل نامیده میشود.
چه زمانی از CNB استفاده کنیم؟
– وقتی دادهها نامتوازن هستند: اگر مجموعه دادهای که قرار است روی آن طبقهبندی انجام شود نامتوازن باشد، بیز ساده چندجملهای و بیز ساده گوسی ممکن است دقت پایینی داشته باشند. اما بیز ساده مکمل عملکرد خوبی خواهد داشت و دقت نسبتاً بالاتری را ارائه میدهد.
– برای وظایف طبقهبندی متن: بیز ساده مکمل در وظایف طبقهبندی متن، هم از بیز ساده گوسی و هم از بیز ساده چندجملهای بهتر عمل میکند.
مزایا استفاده از CNB
مزایای cnbچیست؟ الگوریتم مکمل بیز ساده دارای مزایای فراوانی است که آن را به گزینهای جذاب برای دسته بندی دادهها تبدیل میکند. یکی از این مزایا دقت بالای آن در دادههای نامتوازن است؛ زیرا با بهرهگیری از اطلاعات مکمل، CNB قادر است عملکردی دقیقتر نسبت به بیز ساده ارائه دهد. علاوه بر این، سرعت بالای این الگوریتم به دلیل سبک بودن محاسبات، امکان پیاده سازی و اجرای سریع را فراهم میکند. همچنین، استفاده از دادههای مکمل باعث میشود که الگوریتم نسبت به نویز و اطلاعات نادرست مقاومتر عمل کند. از طرفی، سادگی پیاده سازی CNB در زبانهای برنامه نویسی مختلف مانند پایتون، آن را به ابزاری کارآمد و محبوب در میان توسعهدهندگان و متخصصان علم داده تبدیل کرده است.

معایب استفاده از CNB
با وجود مزایای فراوان، الگوریتم CNB نیز دارای محدودیتها و معایبی است که باید مد نظر قرار گیرند. اما معایب cnb چیست؟ یکی از مهمترین معایب این الگوریتم نیاز به پیش پردازش دقیق دادهها است؛ برای دستیابی به عملکرد مطلوب، دادههای ورودی باید به دقت پاکسازی و پردازش شوند. علاوه بر این، CNB عمدتا در تحلیل دادههای متنی کاربرد دارد و ممکن است در مسائل عددی یا جدولی عملکرد کمتری داشته باشد. همچنین، این الگوریتم به شدت به توزیع دادهها وابسته است؛ در صورتی که دادهها به طور قابل توجهی از توزیع معمول فاصله داشته باشند، نتایج حاصل ممکن است بهینه نباشد.
پیادهسازی CNB در پایتون
برای این مثال، از مجموعه داده شراب استفاده میکنیم که کمی نامتوازن است. این مجموعه داده مبدأ شراب را از روی پارامترهای شیمیایی مختلف تعیین میکند.
برای ارزیابی مدل، دقت مجموعه داده آزمایشی و گزارش طبقهبندی کلاسیفایر (طبقهبندی کننده یا دستهبند) را بررسی خواهیم کرد. ما از کتابخانه scikit-learn برای پیادهسازی الگوریتم بیز ساده مکمل استفاده خواهیم برد.
# Import required modules
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.naive_bayes import ComplementNB
# Loading the dataset
dataset = load_wine()
X = dataset.data
y = dataset.target
# Splitting the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.15, random_state = 42)
# Creating and training the Complement Naive Bayes Classifier
classifier = ComplementNB()
classifier.fit(X_train, y_train)
# Evaluating the classifier
prediction = classifier.predict(X_test)
prediction_train = classifier.predict(X_train)
print(f"Training Set Accuracy : {accuracy_score(y_train, prediction_train) * 100} %\n")
print(f"Test Set Accuracy : {accuracy_score(y_test, prediction) * 100} % \n\n")
print(f"Classifier Report : \n\n {classification_report(y_test, prediction)}")
خروجی:
Training Set Accuracy : 65.56291390728477 %
Test Set Accuracy : 66.66666666666666 %
Classifier Report :
precision recall f1-score support
0 0.64 1.00 0.78 9
1 0.67 0.73 0.70 11
2 1.00 0.14 0.25 7
accuracy 0.67 27
macro avg 0.77 0.62 0.58 27
weighted avg 0.75 0.67 0.61 27
ما روی مجموعه دادههای آموزشی دقت 65.56٪ و روی مجموعه دادههای آزمایشی دقت 66.66٪ به دست آوردیم. این دقتها تقریباً مشابه هستند و با توجه به کیفیت مجموعه دادهها، واقعاً خوب محسوب میشوند. این مجموعه دادهها به خاطر سختی در طبقهبندی با دستهبندهای ساده مانند آنچه که ما استفاده کردیم، شناخته شدهاند. پس این دقتها قابل قبول هستند.

کاربردهای عملی CNB در دادههای نامتوازن
در بسیاری از پروژههای حوزه هوش مصنوعی و علم داده، دادههای ورودی به دلیل توزیع نامتوازن، چالشهای جدی در طبقهبندی دادههای نامتوازن ایجاد میکنند. الگوریتم CNB به دلیل ویژگیهای منحصر به فردش، در چنین شرایطی میتواند عملکرد بسیار مناسبی ارائه دهد. از کاربردهای عملی CNB میتوان به موارد زیر اشاره کرد:
- تحلیل احساسات
در دنیای دیجیتال که نظرات کاربران نقش مهمی در تصمیمگیریها دارند، تحلیل احساسات یکی از کاربردهای کلیدی الگوریتمهای یادگیری ماشین محسوب میشود. الگوریتم مکمل بیز ساده (CNB) با دقت بالا میتواند احساسات مثبت، منفی و حتی خنثی را در متنهای کاربران تشخیص دهد. این ویژگی باعث شده است که CNB در پلتفرمهایی مانند رسانههای اجتماعی، بخش نظرات فروشگاههای آنلاین و سیستمهای بازخورد مشتری مورد استفاده قرار گیرد.

- تشخیص اسپم
با افزایش حجم ایمیلها و پیامکهای تبلیغاتی یا مخرب، فیلتر کردن پیامهای ناخواسته به یکی از چالشهای مهم تبدیل شده است. الگوریتم CNB در سیستمهای تشخیص اسپم عملکرد قابل قبولی داشته و میتواند پیامهای ناخواسته و تبلیغاتی را با دقت بالاتری از پیامهای معتبر و مهم تفکیک کند. این ویژگی در بهبود امنیت کاربران و جلوگیری از اتلاف وقت در پردازش پیامهای غیرضروری نقش مؤثری دارد.
- دستهبندی اخبار و مقالات
این الگوریتم با تحلیل دادههای متنی، به طبقه بندی صحیح اخبار و مقالات بر اساس موضوعات آنها کمک میکند.
- کاربردهای دیگری مانند توصیهگرها
در سیستمهای توصیهگر، تحلیل دادههای نامتوازن با استفاده از CNB میتواند نتایج بهتری ارائه دهد.
علاوه بر درک مفهوم cnb چیست، برای کسب اطلاعات بیشتر در مورد نحوه استفاده از آمار در تحلیل دادهها، به کاربرد آمار مراجعه کنید.

نتیجه گیری
الگوریتم مکمل بیز ساده (CNB) یکی از روشهای مؤثر در حوزه طبقهبندی دادههای نامتوازن و پردازش متون است. اگر برای شما این سؤال مطرح شده که cnb چیست؟، باید بدانید که این مدل نسخهای بهبودیافته از بیز ساده (Naïve Bayes) است که با استفاده از اطلاعات مکمل کلاسها، عملکرد بهتری در مجموعه دادههایی با توزیع نامتقارن دارد. برخلاف بیز ساده که فرض استقلال ویژگیها را در نظر میگیرد، CNB با رویکرد متفاوتی احتمال دسته بندی دادهها را محاسبه کرده و حساسیت کمتری نسبت به نویز و دادههای نادرست دارد. این ویژگی باعث میشود CNB در کاربردهای عملی مانند تحلیل احساسات، تشخیص اسپم و دسته بندی متون به عنوان یک راهکار قابل اعتماد مورد استفاده قرار گیرد. در مجموع، این الگوریتم به دلیل دقت بالا، پایداری بیشتر و توانایی پردازش دادههای نامتوازن، گزینهای ارزشمند برای متخصصان علم داده محسوب میشود.
برای اطلاعات بیشتر درباره مباحث مرتبط با علم داده، میتوانید به دیتا ساینس چیست مراجعه کنید. همچنین، اگر به دنبال بهبود فرآیندهای یادگیری ماشین در پروژههای خود هستید، همین حالا در دورههای تخصصی DataYad شرکت کنید و از مشاوره رایگان بهرهمند شوید.
سوالات متداول
1-چه محدودیتهایی در استفاده از CNB وجود دارد؟
الگوریتم CNB با وجود عملکرد بهبود یافته در دادههای نامتوازن، نیازمند پیشپردازش دقیق دادهها و انتخاب صحیح ویژگیها است. همچنین، کاربرد آن بیشتر در مسائل متنی مشهود است و در دادههای عددی ممکن است محدودیتهایی وجود داشته باشد.
2-چگونه CNB با دادههای نامتوازن کار میکند؟
CNB با محاسبه احتمال وقوع ویژگیها در کلاسهای مکمل (یعنی سایر کلاسها) تلاش میکند تا عدم تعادل دادهها را کاهش دهد. این رویکرد به بهبود دقت پیشبینی در دادههای نامتوازن کمک میکند.
3-چه معیارهایی برای ارزیابی عملکرد CNB وجود دارد؟
معیارهایی مانند دقت (Accuracy)، ماتریس اشتباهات (Confusion Matrix)، F1-Score و معیارهای مرتبط دیگر از جمله مواردی هستند که برای ارزیابی عملکرد CNB مورد استفاده قرار میگیرند.
منابع:











