

یکی از رویکردهای پایه در یادگیری ماشین (ML) که به طور متداول برای وظایف دستهبندی دودویی استفاده میشود، رگرسیون لجستیک (Logistic Regression) نام دارد. برخلاف نامش، این رویکرد از تابع سیگموئید (sigmoid function) برای تقلید احتمال وقوع یک نمونه در یک کلاس خاص استفاده میکند و مقادیری بین 0 و 1 تولید میکند.رگرسیون خطی چند متغیره نیز نوعی از این مدل است که در آن، برای پیشبینی خروجی، از چندین ویژگی (متغیر مستقل) به طور همزمان استفاده میشود.
رگرسیون لجستیک با تمرکز بر تفسیرپذیری، سادگی و محاسبات کارآمد، به طور گسترده در حوزههای مختلفی مانند بازاریابی، مالی و بهداشت مورد استفاده قرار میگیرد و پیشبینیهای معقول و اطلاعات مفیدی برای تصمیمگیری ارائه میدهد.
رگرسیون لجستیک چیست؟
رگرسیون لجستیک یک مدل آماری برای دستهبندی دودویی است که از تابع سیگموئید استفاده میکند تا احتمال تعلق یک نمونه به یک کلاس خاص را پیشبینی کند و نتایجی را بین 0 و 1 ارائه میکند. برای کاهش خطای لگاریتمی، این مدل یک ترکیب خطی از ویژگیهای ورودی محاسبه میکند، سپس آن را با استفاده از تابع سیگموئید تبدیل کرده و در نهایت ضرایب خود را با استفاده از روشهای بهینهسازی مانند گرادیان کاهشی بهینه میکند.
این ضرایب مرز تصمیمگیری را مشخص میکنند که کلاسها را از یکدیگر جدا میکند. به دلیل سادگی استفاده، قابلیت تفسیر و تطبیق پذیری در حوزههای مختلف، رگرسیون لجستیک در یادگیری ماشین برای مسائلی که نتایج دودویی دارند، به طور گسترده مورد استفاده قرار میگیرد. از طریق اعمال روشهای regularization نیز میتوان از بیشبرازش جلوگیری کرد.
الگوریتم رگرسیون لجستیک چطور کار می کند؟
رگرسیون لجستیک احتمال تعلق یک نمونه به یک کلاس خاص را مدل میکند. این الگوریتم از یک معادله خطی برای ترکیب اطلاعات ورودی و تابع سیگموئید برای محدود کردن پیشبینیها به مقادیر بین 0 و 1 استفاده میکند.
برای بهینهسازی ضرایب مدل و کاهش خطای لگاریتمی، از روشهایی مانند گرادیان کاهشی و تکنیکهای دیگر استفاده میشود. این ضرایب مرز تصمیمگیری نهایی را ایجاد میکنند که نمونهها را به دو کلاس مختلف تقسیم میکند.
در مسائل دستهبندی دودویی، رگرسیون لجستیک بهترین انتخاب است چرا که به راحتی قابل درک، ساده و در محیطهای متنوعی قابلاستفاده است. با استفاده از روشهای regularization، میتوان عملکرد عمومی مدل را بهبود بخشید.
مفاهیم کلیدی رگرسیون لجستیک
مفاهیم کلیدی مهم در رگرسیون لجستیک عبارتاند از:
1- تابع سیگموئید
این تابع اصلی است که با تبدیل ترکیب خطی اطلاعات ورودی به احتمالات بین 0 و 1، مطمئن میشود که خروجیها در این محدوده باشند. تابع سیگموئید با σ(z) نمایش داده میشود و به شکل زیر تعریف میشود:
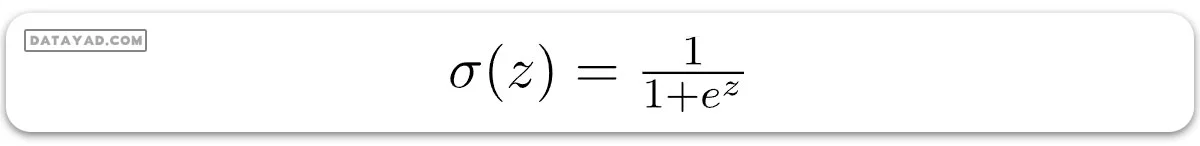
در اینجا z ترکیب خطی از دادههای ورودی و ضرایب است.
2- تابع فرضی
از تابع سیگموئید و وزنها (ضرایب) برای ترکیب ویژگیهای ورودی به منظور تخمین احتمال تعلق به یک کلاس خاص استفاده میشود. در رگرسیون لجستیک، تابع فرضی به صورت زیر تعریف میشود:
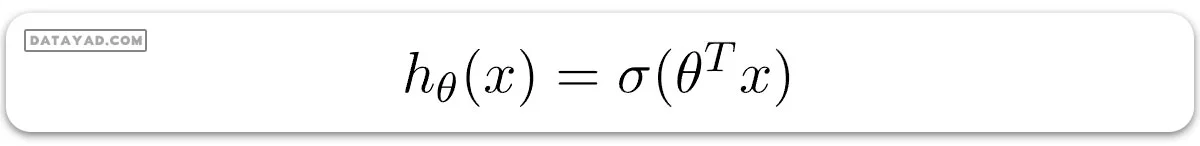
- در اینجا hθ(x) احتمال پیشبینی شده است که (y = 1) باشد
- و θ بردار ضرایب است
- و x بردار ویژگیهای ورودی است.
3- تابع هزینه لگاریتمی
این تابع به عنوان اندازهگیری اختلاف بین برچسبهای کلاس و احتمالات پیشبینی شده تعریف میشود. تعریف تابع هزینه لگاریتمی برای یک نمونه به شکل زیر است:
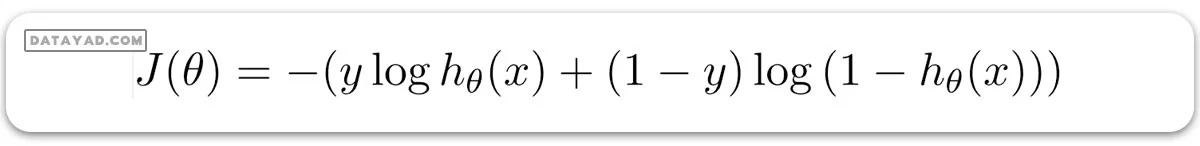
4- مرز تصمیمگیری
سطح یا خطی که برای تقسیم نمونهها به چند کلاس براساس احتمال تعیین شده استفاده میشود.
5- آستانه احتمال
یک عدد (معمولاً 0.5) که برای محاسبه اختصاص کلاس با استفاده از احتمالات پیشبینی شده استفاده میشود.
6- نسبت احتمال
احتمال وقوع یک رویداد نسبت به واقع نشدن آن رویداد است که سبب میشود ارتباط میان ویژگیها و متغیر هدف بهتر درک شود.
پیادهسازی رگرسیون لجستیک با استفاده از پایتون
وارد کردن کتابخانهها
# Import necessary libraries import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_curve, auc
خواندن و بررسی دادهها
# Load the diabetes dataset diabetes = load_diabetes() X, y = diabetes.data, diabetes.target # Convert the target variable to binary (1 for diabetes, 0 for no diabetes) y_binary = (y > np.median(y)).astype(int)
در این بخش از کد، مجموعه داده دیابت با استفاده از تابع load_diabetes از کتابخانه scikit-learn خوانده میشود. ورودیهای ویژگی با نام X و مقادیر هدف با نام y بارگذاری میشوند. سپس، متغیر هدف پیوسته به شکل دودویی تبدیل میشود. به این ترتیب، اگر اندازه دیابت بیمار بیشتر از مقدار میانگین باشد، به عنوان 1 (نشانگر وجود دیابت) دستهبندی میشود و اگر کمتر باشد، به عنوان 0 (نشانگر عدم وجود دیابت) دستهبندی میشود.
تقسیم مجموعه داده: مجموعه داده های آموزش و آزمون
در این مرحله، مجموعه داده به دو بخش تقسیم میشود؛ 80 درصد از داده برای آموزش مدل استفاده میشود و 20 درصد از آن برای ارزیابی عملکرد مدل مورد استفاده قرار میگیرد.
# Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split( X, y_binary, test_size=0.2, random_state=42)
در این کد، مجموعه داده دیابت با استفاده از تابع train_test_split از کتابخانه scikit-learn به دو بخش تقسیم میشود. متغیر هدف دودویی به نام y_binary نامیده میشود و ویژگیها در متغیر X ذخیره شدهاند.
داده به دو بخش آزمون (X_test، y_test) و آموزش (X_train، y_train) تقسیم میشود. بر اساس تنظیم test_size=0.2، بیست درصد از داده برای آزمون استفاده میشود. با استفاده از یک seed ثابت برای تصادفیسازی در طول تقسیم، تنظیم random_state=42 سبب میشود که نتایج قابل بازتولید باشند.
مقیاسبندی ویژگیها
# Standardize features scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test)
در این بخش از کد، از StandardScaler از کتابخانه scikit-learn برای انجام مقیاسبندی ویژگیها استفاده میشود:
یک نمونه از StandardScaler ایجاد میشود؛ این نمونه برای مقیاسبندی ویژگیها استفاده میشود. از روش fit_transform برای نرمالسازی دادههای آموزش (X_train) استفاده میشود تا میانگین و انحراف معیار آنها مشخص شود. سپس، دادههای آزمون (X_test) با استفاده از میانگین و انحراف معیار محاسبه شده از مجموعه آموزش مقیاسبندی میشوند. مقیاسبندی به آموزش و ارزیابی مدل کمک میکند و تضمین میکند که ویژگیها میانگین 0 و انحراف معیار 1 داشته باشند.
آموزش مدل
# Train the Logistic Regression model model = LogisticRegression() model.fit(X_train, y_train)
در این بخش از کد، با استفاده از LogisticRegression از کتابخانه scikit-learn، یک مدل رگرسیون لجستیک آموزش داده میشود.
یک نمونه از مدل رگرسیون لجستیک ایجاد میشود. سپس، با استفاده از روش fit، مدل با استفاده از مقادیر هدف دودویی (y_train) و دادههای آموزش مقیاسبندی شده (X_train) آموزش داده میشود. پس از اجرا، اکنون میتوان از شیء مدل برای پیشبینی دادههای جدید با استفاده از الگوهایی که از مجموعه آموزش آموخته است، استفاده کرد.
معیارهای ارزیابی
معیارها برای بررسی عملکرد مدل بر مقادیر پیشبینی شده و مقادیر واقعی استفاده میشوند.
# Evaluate the model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {:.2f}%".format(accuracy * 100))
خروجی:
Accuracy: 73.03%
در این کد، متغیر هدف پیشبینی میشود و سپس دقت آن محاسبه میشود تا مدل رگرسیون لجستیک را بر روی مجموعه آزمون ارزیابی کند. تابع accuracy_score برای مقایسه مقادیر پیشبینی شده در آرایه y_pred با مقادیر واقعی هدف (y_test) استفاده میشود.
ماتریس درهمریختگی و گزارش دستهبندی
# evaluate the model
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
خروجی:
Confusion Matrix:
[[36 13]
[11 29]]
Classification Report:
precision recall f1-score support
0 0.77 0.73 0.75 49
1 0.69 0.72 0.71 40
accuracy 0.73 89
macro avg 0.73 0.73 0.73 89
weighted avg 0.73 0.73 0.73 89
نمایش عملکرد مدل ما
# Visualize the decision boundary with accuracy information
plt.figure(figsize=(8, 6))
sns.scatterplot(x=X_test[:, 2], y=X_test[:, 8], hue=y_test, palette={
0: 'blue', 1: 'red'}, marker='o')
plt.xlabel("BMI")
plt.ylabel("Age")
plt.title("Logistic Regression Decision Boundary\nAccuracy: {:.2f}%".format(
accuracy * 100))
plt.legend(title="Diabetes", loc="upper right")
plt.show()
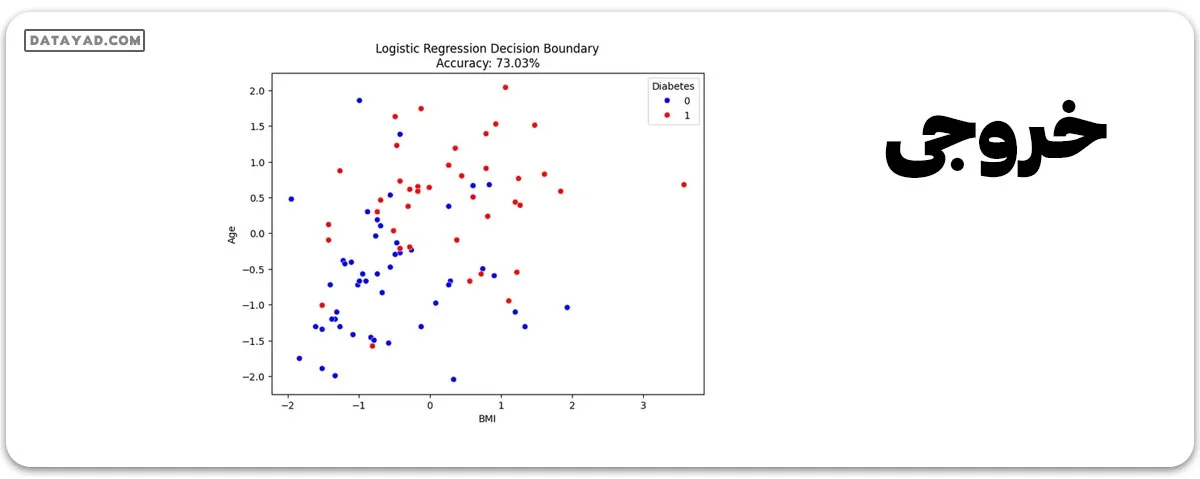
برای مشاهده مرز تصمیم مدل رگرسیون لجستیک، این کد یک نمودار پراکندگی ایجاد میکند. هر نقطه در نمودار نمایانگر یک فرد از مجموعه آزمون است که در محور Y سن و در محور X، BMI قرار دارد. نقاط بر اساس وضعیت واقعی دیابت رنگآمیزی میشوند، که ارزیابی کردن نحوه تمییز دادن مدل بین افراد دارای دیابت و بدون دیابت را آسانتر میکند.
عنوان نمودار که شامل اطلاعات دقت مدل است، یک سیاق بصری برای عملکرد مدل روی دادههای آزمون فراهم میکند. نشانی قرار گرفته در گوشه بالا و سمت راست نمایانگر رنگهای نمایانگر دیابت (1) و عدم دیابت (0) است.
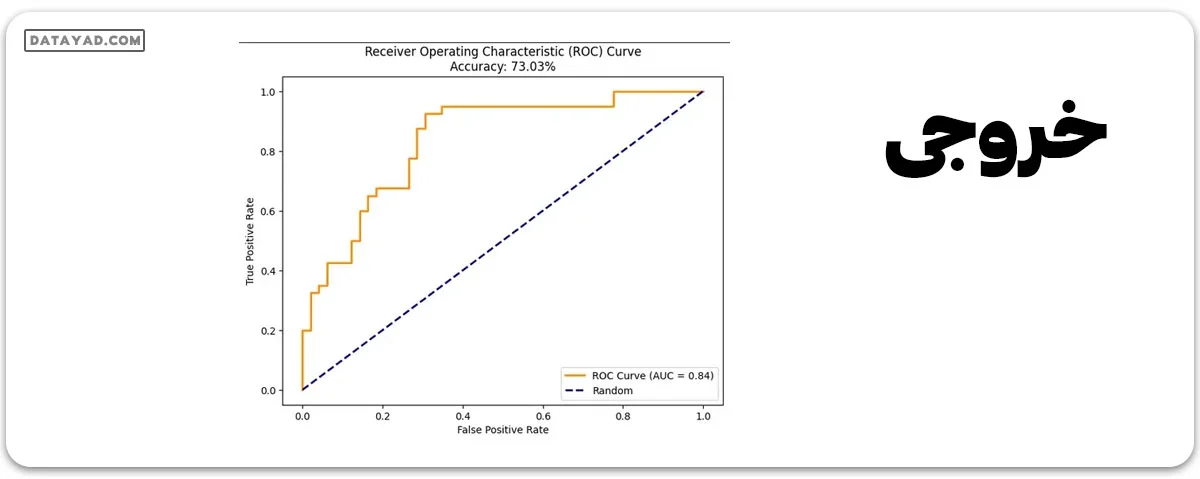
رسم منحنی ROC
# Plot ROC Curve
y_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2,
label=f'ROC Curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='Random')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve\nAccuracy: {:.2f}%'.format(
accuracy * 100))
plt.legend(loc="lower right")
plt.show()
در مورد مدل رگرسیون لجستیک، این کد یک منحنی مشخصه عملکرد گیرنده (ROC) ایجاد کرده و نمایش میدهد. نرخ واقعی مثبت (حساسیت) و نرخ مثبت نادرست در مقادیر آستانه مختلف با استفاده از تخمینهای احتمالی برای نتایج مثبت (y_prob) تعیین میشود که با استفاده از روش predict_proba به دست میآید.
استفاده از roc_auc_score مساحت زیر منحنی ROC (AUC) را محاسبه میکند. یک نمودار از منحنی حاصل نمایش داده میشود و در توضیحات نمایانگر مقدار AUC قرار دارد. در نمودار، خطچین برای نمایش منحنی ROC برای یک دستهبندی کننده تصادفی میباشد.
پرسشهای متداول
1. رگرسیون لجستیک چیست ؟
رگرسیون لجستیک یک تکنیک آماری برای مسائل دستهبندی دودویی است که از یک تابع لجستیک برای مدلسازی احتمال وقوع یک نتیجه دودویی استفاده میکند.
2. تفاوت رگرسیون لجستیک با رگرسیون خطی چیست؟
در رگرسیون لجستیک، احتمال وقوع یک حادثه دودویی پیشبینی میشود، در حالی که رگرسیون خطی یک نتیجه پیوسته را پیشبینی میکند. برای محدود کردن خروجی بین 0 و 1، رگرسیون لجستیک از تابع لجستیک (سیگموئید) استفاده میکند.
3. چگونه متغیرهای دستهای را در رگرسیون لجستیک مدیریت کنیم؟
برای تبدیل اطلاعات دستهای به نمایش عددی، میتوانید از one-hot encoding بهره ببرید. مطمئن شوید که دادهها به درستی پیشپردازش شده باشند تا برای استفاده در رگرسیون لجستیک آماده شوند.
4. آیا رگرسیون لجستیک میتواند با دستهبندی چندکلاسه کار کند؟
بله، میتوان از روشهایی مانند (One-vs-Rest) یا رگرسیون Softmax برای توسعه رگرسیون لجستیک برای دستهبندی چندکلاسه استفاده کرد.
5. نقش تابع سیگموئید در رگرسیون لجستیک چیست؟
تابع سیگموئید امکان تصویر نمودن هر عدد حقیقی به بازه [0، 1] را فراهم میکند. خروجی معادله خطی را به احتمالات تبدیل میکند.











