

در درس دوم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم به طور مفصل تر در مورد یادگیری ماشین و نحوه عملکرد الگوریتم های آن، و آموزش ساخت مدل یادگیری ماشین صحبت کنیم.

یادگیری ماشین چیست؟
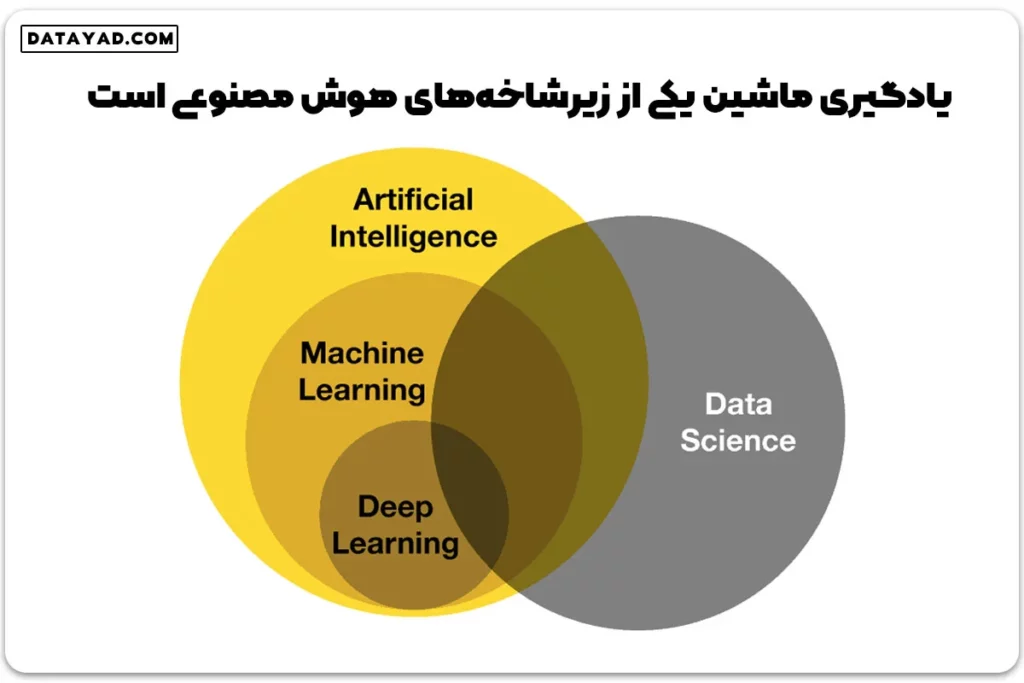
یادگیری ماشین یکی از زیرشاخههای اصلی هوش مصنوعی و علم داده است که با توسعه الگوریتمها، امکان استخراج الگوهای پنهان از مجموعهدادهها را فراهم میکند. این رویکرد به سیستمها اجازه میدهد بدون نیاز به برنامهنویسی صریح برای هر وظیفه، از دادههای گذشته بیاموزند و نتایج دادههای جدید با ساختار مشابه را پیشبینی کنند. با توجه به نقش کلیدی یادگیری ماشین در تحول فناوریهای نوین، آشنایی با مسیر جامع آموزش هوش مصنوعی برای افرادی که قصد ورود حرفهای به این حوزه را دارند، اهمیت ویژهای دارد.
یادگیری ماشین سنتی، دادهها را با ابزارهای آماری ترکیب میکند تا خروجیای را پیشبینی کند که بتوان از آن به منظور استخراج دانشهای قابل عمل استفاده کرد.
یادگیری ماشین (ML) در انواع مختلفی از کاربردها مورد استفاده قرار میگیرد، از بینایی کامپیوتر و گفتار تا پردازش زبان طبیعی، سیستمهای توصیه گر، تشخیص تقلب، بهینهسازی پرتفو، وظایف خودکار و بسیاری دیگر.
همچنین مدلهای یادگیری ماشین در وسایل نقلیه خودران و پهپادها مورد استفاده قرار میگیرند و رباتها را هوشمندتر می کنند و همچنین رباتها را قادر می کنند تا با محیط های متغیر خود را تطبیق دهند.
یکی از وظایف رایج یادگیری ماشین، ارائه پیشنهادات به کاربران است. سیستمهای توصیهگر، یکی از کاربردهای شایع یادگیری ماشین هستند و از دادههای تاریخی برای ارائه پیشنهادهای شخصیسازی شده به کاربران استفاده میکنند.
به عنوان مثال، در مورد Netflix، این سیستم از ترکیب فیلترینگ همکاری و فیلترینگ مبتنی بر محتوا برای پیشنهاد فیلمها و برنامههای تلویزیونی به کاربران بر اساس تاریخچه تماشا، امتیازات و عوامل دیگر مانند ترجیحات ژانری استفاده میکند.
یادگیری تقویتی نوع دیگری از یادگیری ماشین است که میتواند برای بهبود سیستمهای مبتنی بر توصیه استفاده شود. در یادگیری تقویتی، یک عامل بر اساس بازخوردی که از محیط خود دریافت میکند، تصمیمگیری را یاد میگیرد و این بازخورد میتواند برای بهبود پیشنهادهای ارائه شده به کاربران مورد استفاده قرار گیرد.
به عنوان مثال، سیستم میتواند ردیابی کند که چقدر کاربر یک فیلم پیشنهادی را تماشا میکند و از این بازخورد برای تنظیم پیشنهادهای آینده استفاده کند.
پیشنهادات شخصیسازی بر اساس یادگیری ماشین، در بسیاری از صنایع از جمله تجارت الکترونیک، رسانههای اجتماعی و تبلیغات آنلاین به شدت مورد توجه قرار گرفتهاند که به علت توانایی آنها در ارائه تجربه کاربری بهتر و افزایش ارتباط کاربران با پلتفرم یا خدمات میباشد.
انقلاب در اینجا با این ایده آغاز میشود که یک ماشین میتواند از داده (به عبارت دیگر، یک نمونه) به تنهایی بیاموزد و نتایج دقیقی تولید کند. یادگیری ماشین به طور نزدیکی با داده کاوی و علم داده مرتبط است. ماشین ورودیهای داده را دریافت کرده و از الگوریتمها برای ارائه پاسخهای مطلوب استفاده میکند.
“به نقل از ibm.com: ماشین لرنینگ یک شاخه پرکاربرد از هوش مصنوعی میباشد و بیشتر روی توانمندسازی کامپیوترها و ماشینها برای تقلید از روشهای یادگیری انسانها متمرکز است. هدف از ایجاد این فناوری، انجام وظایف مختلف بهصورت خودکار و بهبود عملکرد و دقت آنها از طریق تجربه و دسترسی به دادههای بیشتر میباشد. الگوریتمهای یادگیری ماشین برای پیشبینی یا طبقهبندی کاربرد دارند و بر اساس دادههای ورودی که میتواند برچسبگذاری شده یا بدون برچسب باشد، تخمینی از الگوهای موجود در دادهها ارائه میدهند.
سیستم یادگیری ماشین به سه بخش اصلی تقسیم میشود. بخش اول فرآیند تصمیمگیری است که پیشبینی یا طبقهبندی را انجام میدهد. بخ شدوم تابع خطا میباشد که پیشبینی مدل را مورد ارزیابی قرار میدهد. بخش سوم فرآیند بهینهسازی مدل است که در آن وزنها برای کاهش اختلاف بین مثالهای شناختهشده و تخمین مدل تنظیم میشوند. این الگوریتم به صورت پیوسته این فرآیند “ارزیابی و بهینهسازی” را تکرار میکند تا زمانی که به یک آستانه دقت مشخص برسد.”
<
یادگیری ماشین به زبان ساده
یادگیری ماشین زیرشاخهای از هوش مصنوعی است که بهطور کلی به عنوان توانایی ماشین برای تقلید از رفتار هوشمند انسان تعریف میشود.
حالا پس از اینکه فهمیدیم یادگیری ماشین چیست می خواهیم ببینیم تفاوت آن با برنامه نویسی سنتی و همچنین با هوش مصنوعی چیست؟
تفاوت میان یادگیری ماشین و برنامه نویسی سنتی و هوش مصنوعی
ما قبلا در مقاله تفاوت هوش مصنوعی و یادگیری ماشین، به صورت کامل تفاوت های آنها را با هم بررسی کردیم. در اینجا هم می خواهیم علاوه بر اشاره به تفاوت های ماشین لرنینگ با هوش مصنوعی، آن را با برنامه نویسی سنتی نیز مقایسه کنیم.
| هوش مصنوعی | برنامه نویسی سنتی | یادگیری ماشین |
| هوش مصنوعی شامل تواناسازی ماشین تا حدی است که بتواند وظایفی را انجام دهد که معمولاً نیاز به هوش انسانی دارند. | در برنامهنویسی سنتی، کد مبتنی بر قوانین توسط توسعهدهندگان بر اساس بیانیههای مسئله نوشته میشود. | یادگیری ماشین زیرمجموعهای از هوش مصنوعی است که بر روی یادگیری از دادهها تمرکز دارد تا الگوریتمی توسعه دهد که برای پیشبینی استفاده شود. |
| هوش مصنوعی میتواند شامل روشهای مختلفی باشد، از جمله یادگیری ماشین و یادگیری عمیق، و همچنین برنامهنویسی سنتی مبتنی بر قوانین. | برنامهنویسی سنتی به طور معمول مبتنی بر قوانین و قاعدهمند است. ویژگیهای خودآموزی مانند یادگیری ماشین و هوش مصنوعی ندارد. | یادگیری ماشین از رویکرد مبتنی بر داده استفاده میکند، معمولا بر اساس دادههای تاریخی آموزش دیده شده و سپس برای پیشبینی در دادههای جدید استفاده میشود. |
| گاهی اوقات هوش مصنوعی از ترکیب داده و قوانین از پیشتعریف شده استفاده میکند که به او امکان حل وظایف پیچیده با دقت خوبی که به نظر ممکن نمیآید را میدهد. | برنامهنویسی سنتی به طور کامل به هوش توسعهدهندگان وابسته است، بنابراین دارای قابلیت محدودی است. | یادگیری ماشین میتواند الگوها و تفسیرهایی را در مجموعهدادههای بزرگ را پیدا کند که یافتن آنها برای انسانها ممکن است سخت باشد. |
| هوش مصنوعی یک زمینه گسترده است که شامل بسیاری از کاربردهای مختلف مانند پردازش زبان طبیعی، بینایی ماشین و رباتیک میشود. | برنامهنویسی سنتی به طور معمول برای ساخت برنامهها و سیستمهای نرمافزاری با قابلیتهای خاص استفاده میشود. | یادگیری ماشین زیرمجموعهای از هوش مصنوعی است و در حال حاضر در وظایف مبتنی بر هوش مصنوعی مانند پاسخگویی به سوالات چتبات، خودروهای خودران و غیره استفاده میشود. |
کاربردهای یادگیری ماشین
همان طور که گفتیم یادگیری ماشین (Machine Learning) یکی از شاخههای اصلی هوش مصنوعی است و کاربردهای بسیار زیادی در زمینههای مختلف مثل تحلیل دادههای پزشکی دارد. در صنعت یادگیری ماشین در مواردی مثل پیشبینی رفتار مشتری، بهینهسازی فرآیندهای تولید، تشخیص تقلب در تراکنشهای مالی و مدیریت زنجیره تأمین به کار میرود. در حوزه سلامت این فناوری در تشخیص بیماریها به وسیله تحلیل تصاویر پزشکی، پیشبینی نتایج درمانی و تولید داروهای جدید نقش بسیار مهمی دارد. همچنین در مواردی مثل بازاریابی دیجیتال، سیستمهای توصیهگر (Recommendation Systems) با تحلیل رفتار کاربران، محصولات یا خدمات مرتبط را به آنها پیشنهاد میدهند. این دانش نوین در زمینه خودروهای خودران نیز کاربردهای بسیار زیادی دارد.
یادگیری ماشین در حوزههای اجتماعی و محیطی نیز تا حد زیادی مورد استفاده قرار میگیرد. به عنوان مثال در مدیریت ترافیک شهری، الگوریتمهای یادگیری ماشین به بهبود جریان ترافیک کمک زیادی میکنند. در حوزه محیط زیست نیز این فناوری برای پیشبینی تغییرات آبوهوایی، نظارت بر اکوسیستمها و مدیریت منابع طبیعی کاربرد دارد. علاوه بر همه این موارد در حوزه زمینه امنیت سایبری، یادگیری ماشین با شناسایی الگوهای حمله و تشخیص ناهنجاریها، به افزایش امنیت سیستمهای اطلاعاتی کمک شایانی میکند. با توجه به همه این موارد ذکر شده یادگیری ماشین با توانایی تحلیل حجم وسیعی از دادهها و ک الگوهای پیچیده، تحولات چشمگیری در بسیاری از صنایع و حوزههای علمی به وجود آورده است. برای درک بهتر میتوانید تفاوت یادگیری ماشین و یادگیری عمیق را مطالعه کنید.
“به نقل از ibm.com: در ادامه چند نمونه از کاربردهای یادگیری ماشین که ممکن است روزانه با آنها مواجه شوید را معرفی میکنیم:
- تشخیص گفتار: این فناوری که به عنوان تشخیص گفتار خودکار (ASR) نیز شناخته میشود، از پردازش زبان طبیعی (NLP) برای تبدیل گفتار انسان به متن بهره میبرد. بسیاری از گوشیهای تلفن همراه از این فناوری برای جستجوی صوتی مانند Siri یا بهبود دسترسی برای ارسال پیام استفاده میکنند.
- خدمات مشتری: رباتهای چت آنلاین در حال جایگزینی نمایندگان انسانی هستند و نحوه تعامل ما با مشتریان را در وبسایتها و پلتفرمهای اجتماعی تغییر میدهند. این رباتها به سؤالات متداول درباره موضوعاتی مثل حمل و نقل پاسخ داده و یا مشاوره شخصی ارائه میدهند.
- بینایی کامپیوتری: این فناوری به کامپیوترها امکان میدهد تا اطلاعات معنیدار را از تصاویر دیجیتال، ویدئوها و ورودیهای بصری دیگر استخراج کنند و سپس اقدام مناسب را انجام دهند. بینایی کامپیوتری در برچسبگذاری عکسها در شبکههای اجتماعی، تصویربرداری رادیولوژی در حوزه بهداشت و خودروهای خودران کاربرد دارد.
- موتورهای توصیه: الگوریتمهای هوش مصنوعی با استفاده از دادههای رفتار مصرف گذشته میتوانند روندهای دادهای را بیابند که برای توسعه استراتژیهای فروش متقابل مؤثرتر باشند. این موتورهای توصیه توسط خردهفروشان آنلاین برای ارائه پیشنهادات محصول مرتبط به مشتریان در زمان پرداخت مورد استفاده قرار میگیرند.
- اتوماسیون فرآیندهای رباتیک (RPA): این حوزه که به عنوان رباتیک نرمافزاری نیز شناخته میشود از فناوریهای اتوماسیون هوشمند برای انجام وظایف تکراری دستی بهره میبرد.
- معاملات خودکار سهام: پلتفرمهای معاملاتی با فرکانس بالا که توسط هوش مصنوعی هدایت میشوند، هزاران یا حتی میلیونها معامله را در طول روز و بدون دخالت انسان انجام میدهند.
- تشخیص تقلب: بانکها و مؤسسات مالی میتوانند از یادگیری ماشین برای شناسایی معاملات مشکوک استفاده کنند. همچنین یادگیری نظارتشده میتواند مدلی را با استفاده از اطلاعات مربوط به معاملات تقلبی شناختهشده آموزش دهد. تشخیص ناهنجاری نیز میتواند معاملاتی را شناسایی کند که غیرمعمول به نظر میرسند و نیاز به بررسی بیشتر دارند.”
مسیرشغلی یادگیری ماشین
مسیر شغلی در زمینه ماشین لرنینگ به دلیل گستردگی و تنوع کاربردهای آن، بسیار متنوع و داینامیک است. معمولاً برای شروع این مسیر و یافتن شغل در این حوزه باید دانش پایهای در ریاضیات، آمار و برنامهنویسی (مانند پایتون یا R) داشته باشید. بسیاری از متخصصان این حوزه با تحصیل در رشتههایی مانند علوم کامپیوتر، مهندسی برق، ریاضیات یا فیزیک وارد این بازار کار در این حوزه میشوند. پس از یادگیری دانش پایه و کسب مهارتهای لازم، باید مفاهیم پیشرفتهتر مانند الگوریتمهای یادگیری ماشین، شبکههای عصبی، پردازش زبان طبیعی و بینایی ماشین را نیز یاد بگیرید. توجه داشته باشید که دورههای آنلاین، کتابها و پروژههای عملی میتوانند به شما در تسلط بر این مفاهیم کمک زیادی کنند.
پس از کسب مهارتهای فنی، میتوانید از فرصتهای شغلی متنوع این حوزه استفاده کنید. برای مثال شما میتوانید به عنوان دانشمند داده (Data Scientist)، مهندس یادگیری ماشین (Machine Learning Engineer) و یا محقق هوش مصنوعی (AI Researcher) فعالیت کنید. شرکتهای فناوری، مؤسسات مالی، سازمانهای بهداشتی و حتی استارتآپها به دنبال جذب متخصصان یادگیری ماشین هستند. علاوه بر این، با افزایش تجربه و تخصص، امکان پیشرفت به سمت نقشهای مدیریتی مانند مدیر فنی (CTO) یا راهاندازی کسبوکارهای مرتبط با هوش مصنوعی نیز وجود دارد. این مسیر شغلی به دلیل سرعت پیشرفت فناوری و نیاز روزافزون به تحلیل دادهها، آیندهای روشن و پرتقاضا دارد.
الگوریتم های یادگیری ماشین چطور کار می کنند؟
یادگیری ماشین به صورت زیر عمل میکند:
✅ مسیر رو به جلو (Forward Pass)
در این گام، الگوریتم یادگیری ماشین دادههای ورودی را دریافت کرده و سعی می کند با کشف ارتباط میان آنها خروجی مطلوب، که مبتنی بر درک این ارتباط هست، را تولید کند. این گام بسته به نوع الگوریتم مدل، پیشبینیها را محاسبه میکند.
✅ تابع خطا (Loss Function)
تابع خطا، که همچنین به عنوان تابع هزینه شناخته میشود، برای ارزیابی دقت پیشبینیهای انجام شده توسط مدل استفاده میشود. این تابع میزان تفاوت بین خروجی پیشبینی شده توسط مدل و خروجی واقعی را محاسبه کرده و این تفاوت به عنوان خطا یا اشتباه شناخته میشود. هدف مدل این است که با تنظیم پارامترهای داخلی خود، خطا یا تابع خطا را به حداقل برساند.
✅ فرآیند بهینهسازی مدل
فرآیند بهینهسازی مدل، فرآیند تکراری تنظیم پارامترهای داخلی مدل به منظور کاهش خطا یا تابع خطا است. این کار با استفاده از یک الگوریتم بهینهسازی مانند کاهش گرادیان انجام میشود. الگوریتم بهینهسازی گرادیان تابع خطا را نسبت به پارامترهای مدل محاسبه کرده و از این اطلاعات برای تنظیم پارامترها به منظور کاهش خطا استفاده میکند. الگوریتم، این فرآیند را تا زمانی که خطا به سطحی قابل قبول کاهش یابد، تکرار میکند.
پس از آموزش و بهینهسازی مدل بر روی دادههای آموزش، میتوان از مدل برای پیشبینی بر روی دادههای جدید استفاده کرد. دقت پیشبینیهای مدل با استفاده از معیارهای مختلف مانند دقت، دقت دستهبندی، بازخوانی و F1 Score (یک معیار مناسب برای ارزیابی دقت یک آزمایش) ارزیابی میشود.
“به نقل از ibm.com: رایجترین الگوریتمهای یادگیری ماشین عبارتند از:
- شبکههای عصبی: این شبکهها عملکرد مغز انسان را با تعداد زیادی از گرههای پردازشی مرتبط، شبیهسازی میکنند. همچنین این الگوریتمها در تشخیص الگوها بسیار خوب عمل کرده و نقش مهمی در ترجمه زبانهای طبیعی، تشخیص تصویر، تشخیص گفتار و ایجاد تصویر دارند.
- رگرسیون خطی: این الگوریتم برای پیشبینی مقادیر عددی بر اساس یک رابطه خطی بین مقادیر مختلف کاربرد دارد. برای مثال میتوان از آن برای پیشبینی قیمت مسکن بر اساس دادههای تاریخی منطقه استفاده کرد.
- رگرسیون لجستیک: این الگوریتم یادگیری نظارتشده، پیشبینیهایی را برای متغیرهای پاسخ دستهبندیشده مانند پاسخهای “بله/خیر” به سؤالات ارائه میدهد. در نتیجه میتوان از آن برای برنامههایی مانند طبقهبندی هرزنامه و کنترل کیفیت در خط تولید استفاده کرد.
- خوشهبندی: الگوریتمهای خوشهبندی با استفاده از یادگیری بدون نظارت، میتوانند الگوهایی را در دادهها تشخیص دهند تا بتوان آنها را گروهبندی کرد. کامپیوترها میتوانند با شناسایی تفاوتهای بین موارد دادهای که انسانها نادیده گرفتهاند، به کمک دانشمندان داده بیایند.
- درختهای تصمیم: از درختهای تصمیم میتوان هم برای پیشبینی مقادیر عددی (رگرسیون) و هم برای طبقهبندی دادهها به دستهها استفاده کرد. درختهای تصمیم از یک توالی شاخهای از تصمیمات مرتبط استفاده بهره میبرند که میتوان آنها را با یک نمودار درختی نشان داد. یکی از مزایای درختهای تصمیم این است که برخلاف جعبه سیاه شبکه عصبی، به راحتی میتوان آنها را اعتبارسنجی و ممیزی کرد.
جنگلهای تصادفی: در یک جنگل تصادفی، الگوریتم یادگیری ماشین با ترکیب نتایج حاصل از تعدادی درخت تصمیم، یک مقدار یا دسته را پیشبینی میکند
چرخه حیات یادگیری ماشین
خب تا اینجا گفتیم که یادگیری ماشین چیست و الگوریتم های آن چطور کار می کنند، حال می خواهیم چرخه حیات یک پروژه یادگیری ماشین را بررسی کنیم و ببینیم که شامل چه مراحلی است؟ به 9 مرحله زیر دقت کنید:
1- بررسی مسئله
مرحله اول، مطالعه مسئله است. در این مرحله، ما باید مسئله تجاری را درک کرده و اهداف مدل را تعریف کنیم.
2- جمعآوری داده
وقتی مسئله به خوبی تعریف شده است، میتوانیم دادههای مرتبط مورد نیاز برای مدل را جمعآوری کنیم. دادهها ممکن است از منابع مختلفی مانند پایگاههای داده، رابطهای برنامهنویسی (API) یا استخراج از وب (web scraping) به دست آید.
3- آمادهسازی داده
وقتی دادههای مرتبط با مسئله جمعآوری شدهاند، منطقی است که دادهها را به درستی بررسی کرده و به فرمت مورد نیاز تبدیل کنیم تا مدل بتواند الگوهای پنهان را پیدا کند. این کار ممکن است شامل مراحل زیر باشد:
- پاکسازی داده
- تبدیل داده
- تحلیل داده توضیحی و مهندسی ویژگی
- تقسیم مجموعه داده برای آموزش و آزمون.
4- انتخاب مدل
مرحله بعد انتخاب الگوریتم یادگیری ماشین مناسب برای مسئله ماست. این مرحله نیازمند دانش در مورد نقاط قوت و ضعف الگوریتمهای مختلف است. گاهی اوقات از چند مدل استفاده میشود و نتایج آنها مقایسه شده و بهترین مدل بر اساس نیازهای ما انتخاب میشود.
5- ساخت و آموزش مدل
پس از انتخاب الگوریتم، باید مدل را بسازیم.
- در مورد یادگیری ماشینی سنتی، ساخت مدل به راحتی انجام میشود و تنها چند مورد از تنظیم پارامترها مورد نیاز است.
- در مورد یادگیری عمیق، باید معماری لایهای مدل را به همراه اندازه ورودی و خروجی، تعداد نودها در هر لایه، تابع هزینه، بهینهساز کاهش گرادیان و غیره را تعریف کنیم.
- سپس مدل با استفاده از مجموعه داده پیشپردازش شده آموزش میبیند.
6- ارزیابی مدل
پس از آموزش مدل، میتوان آن را بر روی مجموعه داده آزمون ارزیابی کرد تا دقت و عملکرد آن با استفاده از تکنیکهای مختلفی مانند گزارش دستهبندی، F1 score، دقت، بازخوانی، منحنی ROC، خطای میانگین مربعات و خطای مطلق و غیره تعیین شود.
7- تنظیم مدل
بر اساس نتایج ارزیابی، ممکن است نیاز باشد مدل را تنظیم یا بهینهسازی کرد تا عملکرد آن بهبود یابد. این کار شامل تنظیم پارامترهای مدل میشود.
8- پیادهسازی
پس از آموزش و تنظیم مدل، میتوان آن را در محیط تولیدی پیادهسازی کرد تا بتواند دادههای جدید را پیشبینی کند. این مرحله نیازمند ادغام مدل در یک سیستم نرمافزاری موجود یا ایجاد یک سیستم جدید برای مدل است.
9- نظارت و نگهداری
در نهایت، نظارت بر عملکرد مدل در محیط تولیدی و انجام وظایف نگهداری ضروری است که شامل نظارت برای تغییرات داده، دوبارهآموزی مدل تا حد نیاز و بهروزرسانی مدل با توجه به دادههای جدید میشود.

جبر خطی در یادگیری ماشین
جبر خطی در یادگیری ماشین یکی از مفاهیم اساسی در یادگیری ماشین است که برای درک بهتر بسیاری از الگوریتمهای یادگیری ماشین ضروری است. بسیاری از روشهای یادگیری ماشین مانند رگرسیون خطی، تجزیه مقادیر منفرد (SVD) و تحلیل مؤلفههای اصلی (PCA) به شدت به جبر خطی متکی هستند. بردارها، ماتریسها و عملیات روی آنها مانند ضرب ماتریسی، وارونپذیری و مقدارهای ویژه نقش کلیدی در مدلسازی دادهها و کاهش ابعاد دارند. در یادگیری عمیق نیز، شبکههای عصبی مصنوعی با استفاده از ضرب ماتریسی و اعمال توابع غیرخطی روی لایههای مخفی، دادهها را پردازش و تحلیل میکنند.

سوالات متداول
یادگیری ماشین (Machine Learning) چیست و چگونه ماشینها را قادر میسازد که بدون برنامهنویسی مستقیم از دادهها یاد بگیرند؟
یادگیری ماشین (Machine Learning) شاخهای از هوش مصنوعی است که به سیستمها، توانایی یادگیری از دادهها و بهبود عملکرد بدون برنامهنویسی را میدهد. همچنین با استفاده از الگوریتمهای مختلف، ماشینها الگوها و رابطهها را در دادهها شناسایی کرده و بر اساس آنها پیشبینی یا تصمیمگیری میکنند.
چه تفاوتی میان یادگیری تحت نظارت (Supervised Learning)، یادگیری بدون نظارت (Unsupervised Learning)، و یادگیری تقویتی (Reinforcement Learning) وجود دارد؟
در یادگیری تحت نظارت (Supervised Learning) مدل با استفاده از دادههای برچسبدار آموزش میبیند تا رابطه بین ورودی و خروجی را بیاموزد. در یادگیری بدون نظارت (Unsupervised Learning)، مدل الگوها یا ساختارهای پنهان در دادههای بدون برچسب را پیدا میکند و در یادگیری تقویتی (Reinforcement Learning)، مدل از طریق تعامل با محیط و دریافت بازخورد (پاداش یا جریمه) یاد میگیرد که چگونه بهترین اقدامات را انجام دهد.
مدلهای یادگیری ماشین چگونه ساخته و آموزش داده میشوند و چه مراحلی را شامل میشوند؟
مدلهای یادگیری ماشین با انتخاب الگوریتم مناسب و تنظیم پارامترها ساخته میشوند، سپس با استفاده از دادههای آموزشی، مدل آموزش داده میشود تا الگوها را یاد بگیرد. مراحل اصلی این کار شامل جمعآوری داده، پیشپردازش، آموزش، ارزیابی و بهینهسازی مدل است.
کاربردهای اصلی یادگیری ماشین در حوزههایی مانند سلامت، تجارت و تکنولوژی چیست؟
در حوزه سلامت، یادگیری ماشین برای تشخیص بیماریها، پیشبینی نتایج درمان و تولید داروهای جدید به کار میرود. در تجارت، برای پیشبینی تقاضا، بهینهسازی قیمتگذاری و تحلیل رفتار مشتری کاربرد دارد و در تکنولوژی، برای بهبود سیستمهای توصیهگر، پردازش زبان طبیعی و توسعه خودروهای خودران مورد استفاده قرار میگیرد.











