

در جلسه هجدهم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم به تفاوت طبقه بندی و رگرسیون و الگوریتم های آنها بپردازیم.
طبقهبندی (Classification) و رگرسیون (Regression) دو مسئله اصلی پیشبینی هستند که معمولاً در استخراج دادهها و یادگیری ماشین مورد بررسی قرار میگیرند.
الگوریتم های طبقه بندی
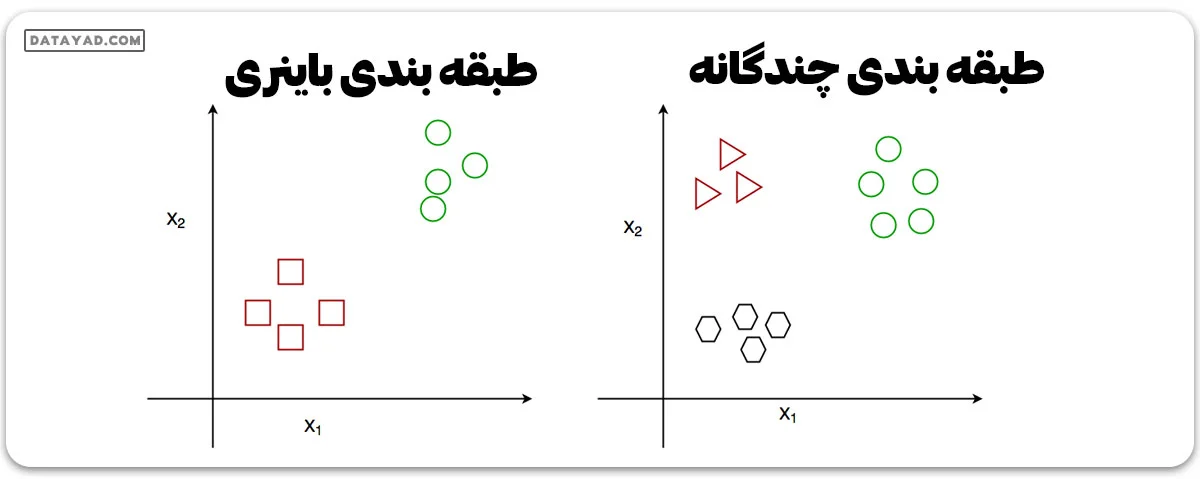
طبقه بندی چیست؟ طبقه بندی فرایندی است که در آن مدل یا تابعی یافت یا کشف میشود که به جدا کردن دادهها به چندین کلاس دستهبندی، یعنی مقادیر گسسته، کمک میکند.
در طبقهبندی، دادهها بر اساس برخی پارامترهای دادهشده در ورودی تحت برچسبهای مختلف دستهبندی میشوند و سپس برچسبها برای دادهها پیشبینی میشوند.
- در طبقهبندی، ما باید متغیرهای هدف گسسته (برچسبهای کلاس) را با استفاده از ویژگیهای مستقل پیشبینی کنیم.
- در طبقهبندی، ما باید یک مرز تصمیم پیدا کنیم که بتواند کلاسهای مختلف در متغیر هدف را از یکدیگر جدا کند.
تابع نگاشت به دست آمده میتواند به صورت قوانین «IF-THEN» نمایش داده شود. فرآیند طبقهبندی با مسائلی مواجه میشود که در آن دادهها میتوانند به برچسبهای گسسته دوتایی یا چندتایی تقسیم شوند.
به عنوان مثال، فرض کنید میخواهیم احتمال برنده شدن یک مسابقه توسط تیم A را بر اساس برخی پارامترهایی که قبلاً ثبت شدهاند، پیشبینی کنیم. در این صورت دو برچسب «بله» و «خیر» وجود خواهد داشت.
انواع الگوریتم های طبقه بندی
تعدادی از بهترین الگوریتم های طبقه بندی با استفاده از تکنیکهایی مانند جمعآوری (bagging) و بوستینگ (boosting) برای ارائه بهترین نتایج در وظایف طبقهبندی طراحی شدهاند.
- درخت تصمیم (Decision Tree)
- طبقهبندی جنگل تصادفی (Random Forest Classifier)
- K – همسایههای نزدیک (K – Nearest Neighbors)
- ماشین بردار پشتیبان (Support Vector Machine)
الگوریتم های رگرسیون
رگرسیون به دنبال یافتن یک مدل یا تابع است که دادهها را به مقادیر پیوسته واقعی تقسیم کند، به جای اینکه از کلاسها یا مقادیر گسسته استفاده کند. این فرآیند همچنین میتواند تغییرات توزیع را بر اساس دادههای گذشته شناسایی کند. چون مدل پیشبینی رگرسیون یک مقدار را پیشبینی میکند، مهارت مدل باید به صورت خطا در این پیشبینیها اعلام شود.
- در وظیفه رگرسیون، ما قرار است یک متغیر هدف پیوسته را با استفاده از ویژگیهای مستقل پیشبینی کنیم.
- در کارهای رگرسیون، معمولاً با دو نوع مشکل، یعنی رگرسیون خطی و غیرخطی، مواجه هستیم.
بیایید یک مثال مشابه در رگرسیون نیز بزنیم، جایی که ما میخواهیم احتمال بارش باران در مناطق خاصی را با توجه به برخی پارامترهایی که قبلاً ثبت شدهاند، پیدا کنیم. در اینجا یک احتمال مرتبط با باران وجود دارد.
انواع الگوریتم های رگرسیون
تعدادی الگوریتم رگرسیون پیشرفته و متنوع وجود دارد که با گذر زمان توسعه یافتهاند تا با استفاده از تکنیکهایی مانند جمعآوری (bagging) و بوستینگ (boosting) بهترین نتایج را برای وظایف رگرسیون ارائه دهند. این الگوریتمها عبارتند از:
- رگرسیون لاسو (Lasso Regression)
- رگرسیون ریج (Ridge Regression)
- رگرسور XGBoost
- رگرسور LGBM
تفاوت طبقه بندی و رگرسیون
| طبقه بندی | رگرسیون |
| در این مسئله، متغیرهای هدف گسسته هستند. | در این مسئله، متغیرهای هدف پیوسته هستند. |
| مسائلی مانند تشخیص ایمیلهای هرز و پیشبینی بیماری با استفاده از الگوریتمهای دستهبندی حل میشوند. | مسائلی مانند پیشبینی قیمت خانه و پیشبینی بارندگی با استفاده از الگوریتمهای رگرسیون حل میشوند. |
| در این الگوریتم، ما سعی داریم بهترین مرز تصمیم را پیدا کنیم که بتواند دو کلاس را با بیشترین فاصله ممکن از هم جدا کند. | در این الگوریتم، ما سعی داریم بهترین خط مناسب را پیدا کنیم که بتواند کلیت روند دادهها را نمایش دهد. |
| معیارهای ارزیابی مانند دقت (Precision)، بازخوانی (Recall)، و نمره F1 در اینجا برای ارزیابی عملکرد الگوریتمهای دستهبندی استفاده میشوند. | معیارهای ارزیابی مانند خطای میانگین مربع (Mean Squared Error)، امتیاز R2، و MAPE در اینجا برای ارزیابی عملکرد الگوریتمهای رگرسیون استفاده میشوند. |
| در اینجا ما با مسائلی مانند دستهبندی دودویی یا چند کلاسی روبرو هستیم. | در اینجا ما با مسائلی مانند مدلهای رگرسیون خطی و همچنین مدلهای غیرخطی روبرو هستیم. |
| دادههای ورودی شامل متغیرهای مستقل و متغیر وابسته گسسته هستند. | دادههای ورودی شامل متغیرهای مستقل و متغیر وابسته پیوسته هستند. |
| خروجی برچسبهای گسسته است. | خروجی مقادیر عددی پیوسته است. |
| هدف پیشبینی برچسبهای گسسته/کلاسی است. | هدف پیشبینی مقادیر عددی پیوسته است. |
| موارد کاربردی شامل تشخیص هرزنامه، شناسایی تصویر، و تحلیل احساسات هستند. | موارد کاربردی شامل پیشبینی قیمت سهام، پیشبینی قیمت خانه، پیشبینی درخواست |










