

در درس چهاردهم از نیچ کورس آموزش رایگان یادگیری ماشین با پایتون می خواهیم در مورد مقابله با داده های نامتوازن صحبت کنیم و با دو الگوریتم اصلی برای رفع مشکل داده های نامتوازن آشنا شویم.
در دنیای یادگیری ماشین و علم داده، گاهی با مشکل توزیع نامتوازن دادهها روبهرو میشویم. این موضوع زمانی پیش میآید که تعداد نمونههای یک کلاس خیلی بیشتر یا کمتر از دیگری است. الگوریتم های یادگیری ماشین برای افزایش دقت خود، معمولاً به توزیع کلاسها توجهی ندارند. این چالش در مواردی مثل تشخیص تقلب یا شناسایی چهره، معمول است.
روشهای معمول یادگیری ماشین مثل درخت تصمیم یا رگرسیون لجستیک، میل بیشتری به پیشبینی کلاسهای با تعداد نمونه بیشتر دارند و ممکن است کلاسهای با تعداد نمونه کمتر را نادیده بگیرند. به عبارت سادهتر، اگر دادههایمان نامتوازن باشد، مدل ما ممکن است در تشخیص کلاسهای با نمونه کم عملکرد خوبی نداشته باشد.
روشهای مدیریت دادههای نامتوازن
دو الگوریتم اصلی وجود دارد که به وفور برای رفع مشکل نامتوازن بودن دادهها استفاده میشوند.
1- SMOTE
2- Near Miss
تکنیک SMOTE (Synthetic Minority Oversampling Technique) – نمونهگیری Oversampling
تکنیک SMOTE یکی از روشهای محبوب نمونهگیری Oversampling (افزایشی) است که برای مقابله با مشکل دادههای نامتوازن استفاده میشود. این روش با تولید نمونههای تصادفی از کلاس کمترین نمونه، به هدف تعادل بین کلاسها میپردازد.
SMOTE نمونههای جدید را میان نمونههای کلاس اقلیت موجود میسازد. با استفاده از یک رویکرد خطی، نمونههای مصنوعی جدید از کلاس اقلیت ایجاد میکند، و این امر با انتخاب تصادفی همسایههای نزدیک به هر نمونه انجام میپذیرد. پس از این فرآیند، دادهها دوباره سازی میشوند و سپس میتوان از مدلهای طبقهبندی مختلف بر روی آنها استفاده کرد.
فهم عمیقتر از چگونگی کارکرد الگوریتم SMOTE
گام 1: تعیین مجموعه کلاس اقلیت به نام A، برای هر نمونه x:
x ɛ A
همسایههای نزدیک k به x با محاسبه فاصله اقلیدسی بین x و سایر نمونههای موجود در مجموعه A به دست میآید.
گام 2: نرخ نمونهبرداری N بر اساس نسبت عدم توازن تنظیم میشود. برای هر نمونه:
x ɛ A
N نمونه (یعنی x1، x2، … xn) به طور تصادفی از همسایههای نزدیک k انتخاب شده و مجموعهای را تشکیل میدهند.
A1
گام 3: برای هر نمونه:
xk ɛ A1
– (برای k=1، 2، 3 … N)، فرمول زیر برای تولید یک نمونه جدید استفاده میشود:
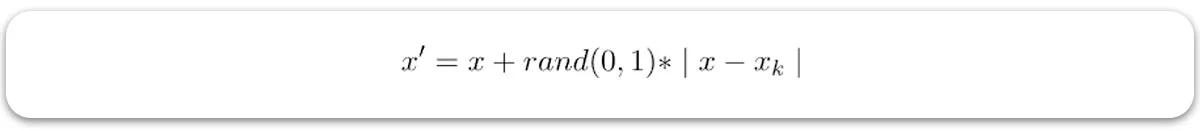
- که در آن rand(0، 1) نمایانگر یک عدد تصادفی بین 0 و 1 است.
الگوریتم NearMiss – نمونهگیری Undersampling
NearMiss یک تکنیک نمونهبرداری Undersampling (کاهشی) است. هدف آن تعادل بین توزیع کلاسها با حذف تصادفی نمونههای کلاس اکثریت است. وقتی نمونههای دو کلاس مختلف به یکدیگر بسیار نزدیک هستند، ما نمونههای کلاس اکثریت را حذف میکنیم تا فاصله بین دو کلاس افزایش یابد. این امر کمک میکند تا فرآیند طبقهبندی بهبود یابد.
برای جلوگیری از مشکل از دست رفتن اطلاعات در بسیاری از تکنیکهای نمونهبرداری کاهشی، روشهای همسایگی نزدیک به طور گستردهای استفاده میشوند.
شهود اساسی در مورد چگونگی عملکرد روشهای همسایهی نزدیک به شرح زیر است:
- گام 1: ابتدا، این روش فواصل بین تمام نمونههای کلاس اکثریت و نمونههای کلاس اقلیت را پیدا میکند. در اینجا، نمونههای کلاس اکثریت باید کاهش یابند.
- گام 2: سپس، n نمونه از کلاس اکثریت که کمترین فاصله را به نمونههای کلاس اقلیت دارند انتخاب میشوند.
- گام 3: اگر k نمونه در کلاس اقلیت وجود داشته باشد، روش نزدیکترین همسایه منجر به وجود k*n نمونه از کلاس اکثریت خواهد شد.
با استفاده از الگوریتم NearMiss برای پیدا کردن n نمونه نزدیک در کلاس با بیشترین نمونهها، چندین روش وجود دارد:
نسخه 1: در این روش، نمونههایی از کلاس با بیشترین تعداد انتخاب میشوند که فاصلهی میانگین آنها تا k نمونه نزدیک کلاس با کمترین تعداد، کمتر است.
نسخه 2: در اینجا، نمونههایی از کلاس با بیشترین تعداد انتخاب میشوند که فاصلهی میانگین آنها تا k نمونه دور از کلاس با کمترین تعداد، کمتر است.
نسخه 3: این روش در دو مرحله اجرا میشود. در مرحله اول، برای هر نمونه در کلاس با کمترین تعداد، M نزدیکترین همسایهها ذخیره میشوند. در مرحله دوم، نمونههای کلاس با بیشترین تعداد انتخاب میشوند که فاصلهی میانگین آنها تا N نزدیکترین همسایه بیشترین است.
این مقاله به درک بهتر و تمرین عملی در مورد چگونگی انتخاب بهترین روش برای مواجهه با دادههای نامتعادل کمک میکند.
بارگذاری کتابخانهها و فایل دادهها
مجموعه داده ها شامل معاملات انجام شده با کارتهای اعتباری است. در این بین، 492 معامله کلاهبردارانه وجود دارد که از مجموع 284,807 معامله، تنها 0.172% را شامل میشود، که نشاندهنده نامتعادل بودن آن است.
برای دسترسی به مجموعه داده، از این لینک استفاده کنید.
# import necessary modules
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix, classification_report
# load the data set
data = pd.read_csv('creditcard.csv')
# print info about columns in the dataframe
print(data.info())
خروجی:
RangeIndex: 284807 entries, 0 to 284806 Data columns (total 31 columns): Time 284807 non-null float64 V1 284807 non-null float64 V2 284807 non-null float64 V3 284807 non-null float64 V4 284807 non-null float64 V5 284807 non-null float64 V6 284807 non-null float64 V7 284807 non-null float64 V8 284807 non-null float64 V9 284807 non-null float64 V10 284807 non-null float64 V11 284807 non-null float64 V12 284807 non-null float64 V13 284807 non-null float64 V14 284807 non-null float64 V15 284807 non-null float64 V16 284807 non-null float64 V17 284807 non-null float64 V18 284807 non-null float64 V19 284807 non-null float64 V20 284807 non-null float64 V21 284807 non-null float64 V22 284807 non-null float64 V23 284807 non-null float64 V24 284807 non-null float64 V25 284807 non-null float64 V26 284807 non-null float64 V27 284807 non-null float64 V28 284807 non-null float64 Amount 284807 non-null float64 Class 284807 non-null int64
# normalise the amount column data['normAmount'] = StandardScaler().fit_transform(np.array(data['Amount']).reshape(-1, 1)) # drop Time and Amount columns as they are not relevant for prediction purpose data = data.drop(['Time', 'Amount'], axis = 1) # as you can see there are 492 fraud transactions. data['Class'].value_counts()
خروجی:
0 284315
1 492
حالا دادهها را برای آموزش و آزمون تقسیم کنیم.
from sklearn.model_selection import train_test_split
# split into 70:30 ration
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# describes info about train and test set
print("Number transactions X_train dataset: ", X_train.shape)
print("Number transactions y_train dataset: ", y_train.shape)
print("Number transactions X_test dataset: ", X_test.shape)
print("Number transactions y_test dataset: ", y_test.shape)
خروجی:
Number transactions X_train dataset: (199364, 29)
Number transactions y_train dataset: (199364, 1)
Number transactions X_test dataset: (85443, 29)
Number transactions y_test dataset: (85443, 1)
سپس مدل را بدون توجه به نامتعادل بودن کلاسها آموزش می دهیم.
# logistic regression object lr = LogisticRegression() # train the model on train set lr.fit(X_train, y_train.ravel()) predictions = lr.predict(X_test) # print classification report print(classification_report(y_test, predictions))
خروجی:
precision recall f1-score support
0 1.00 1.00 1.00 85296
1 0.88 0.62 0.73 147
accuracy 1.00 85443
macro avg 0.94 0.81 0.86 85443
weighted avg 1.00 1.00 1.00 85443
دقت مدل به 100% رسیده، اما آیا متوجه تفاوتی شدهاید؟
بازیابی کلاس کمتعداد خیلی کم است. این نشاندهنده این است که مدل بیشتر به سمت کلاس با تعداد زیاد گرایش دارد. پس، این مدل لزوماً بهترین گزینه نیست.
حالا قصد داریم روشهای مختلف برخورد با دادههای نامتعادل یا نامتوازن را بررسی کنیم و نتایج آنها را مقایسه کنیم.
با استفاده از الگوریتم SMOTE
شما میتوانید جزئیات پارامترها را از لینک مربوطه مشاهده کنید.
print("Before OverSampling, counts of label '1': {}".format(sum(y_train == 1)))
print("Before OverSampling, counts of label '0': {} \n".format(sum(y_train == 0)))
# import SMOTE module from imblearn library
# pip install imblearn (if you don't have imblearn in your system)
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state = 2)
X_train_res, y_train_res = sm.fit_sample(X_train, y_train.ravel())
print('After OverSampling, the shape of train_X: {}'.format(X_train_res.shape))
print('After OverSampling, the shape of train_y: {} \n'.format(y_train_res.shape))
print("After OverSampling, counts of label '1': {}".format(sum(y_train_res == 1)))
print("After OverSampling, counts of label '0': {}".format(sum(y_train_res == 0)))
خروجی:
Before OverSampling, counts of label '1': [345] Before OverSampling, counts of label '0': [199019] After OverSampling, the shape of train_X: (398038, 29) After OverSampling, the shape of train_y: (398038, ) After OverSampling, counts of label '1': 199019 After OverSampling, counts of label '0': 199019
مشاهده میکنید که الگوریتم SMOTE نمونههای کمتعداد را افزایش داده و آنها را با کلاس با تعداد زیاد تراز کرده است. حالا، با اعمال این الگوریتم، نتایج دقت و بازیابی را بررسی کنیم.
پیشبینی و بازیابی
lr1 = LogisticRegression() lr1.fit(X_train_res, y_train_res.ravel()) predictions = lr1.predict(X_test) # print classification report print(classification_report(y_test, predictions))
خروجی:
precision recall f1-score support
0 1.00 0.98 0.99 85296
1 0.06 0.92 0.11 147
accuracy 0.98 85443
macro avg 0.53 0.95 0.55 85443
weighted avg 1.00 0.98 0.99 85443
دقت مدل به 98% کاهش یافته است. اما نسبت به مدل اولیه، بازیابی کلاس کمتعداد به 92% افزایش یافته است. این مدل در مقایسه با مدل قبلی بهتر است.
در مرحله بعد، قصد داریم با استفاده از تکنیک NearMiss، کلاس با تعداد زیاد را کم کنیم و نتایج را مورد ارزیابی قرار دهیم.
با استفاده از الگوریتم NearMiss
برای مشاهده تمام پارامترها، میتوانید به لینک مرجع مراجعه کنید.
print("Before Undersampling, counts of label '1': {}".format(sum(y_train == 1)))
print("Before Undersampling, counts of label '0': {} \n".format(sum(y_train == 0)))
# apply near miss
from imblearn.under_sampling import NearMiss
nr = NearMiss()
X_train_miss, y_train_miss = nr.fit_sample(X_train, y_train.ravel())
print('After Undersampling, the shape of train_X: {}'.format(X_train_miss.shape))
print('After Undersampling, the shape of train_y: {} \n'.format(y_train_miss.shape))
print("After Undersampling, counts of label '1': {}".format(sum(y_train_miss == 1)))
print("After Undersampling, counts of label '0': {}".format(sum(y_train_miss == 0)))
خروجی:
Before Undersampling, counts of label '1': [345] Before Undersampling, counts of label '0': [199019] After Undersampling, the shape of train_X: (690, 29) After Undersampling, the shape of train_y: (690, ) After Undersampling, counts of label '1': 345 After Undersampling, counts of label '0': 345
با استفاده از الگوریتم NearMiss، تعداد نمونههای کلاس با تعداد بیشتر کاهش یافته و با کلاس با تعداد کمتر برابر شده است. یعنی کلاس با تعداد بیشتر به تعداد کلاس با تعداد کمتر رسیده است تا هر دو یک تعداد نمونه داشته باشند.
پیشبینی و بازیابی
# train the model on train set lr2 = LogisticRegression() lr2.fit(X_train_miss, y_train_miss.ravel()) predictions = lr2.predict(X_test) # print classification report print(classification_report(y_test, predictions))
خروجی:
precision recall f1-score support
0 1.00 0.56 0.72 85296
1 0.00 0.95 0.01 147
accuracy 0.56 85443
macro avg 0.50 0.75 0.36 85443
weighted avg 1.00 0.56 0.72 85443
ظاهراً این مدل نسبت به مدل اول بهتر عمل میکند و بازیابی کلاس با تعداد کمتر به 95% افزایش یافته است. اما، بازیابی کلاس با تعداد بیشتر به 56% کاهش پیدا کرده است. در این وضعیت، چون SMOTE نتایج بهتری دارد، تصمیم میگیرم از آن استفاده کنم!





