

در درس هشتم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم به درک پردازش داده (Data Processing) و مراحل اصلی آن بپردازیم.
پردازش داده وظیفه تبدیل دادهها از یک فرم اولیه به یک فرم قابل استفاده و مطلوبتر دیگر است؛ به عبارت دیگر، پردازش داده همان ایجاد معنا و اطلاعات بیشتری از دادهها میباشد. با استفاده از الگوریتمهای یادگیری ماشین، مدلسازی ریاضی و دانش آماری، میتوان تمام این فرآیند را به صورت اتوماتیک انجام داد.
خروجی نهایی این فرآیند میتواند به هر شکل دلخواهی باشد؛ از جمله:
✔️ نمودارها،
✔️ ویدیوها،
✔️ گراف ها،
✔️ جداول،
✔️ تصاویر
و موارد دیگر؛ که وابسته به وظیفهای که در حال انجام دادن و نیازهای دستگاه است، تعیین میشود. این امر ممکن است به نظر ساده بیاید، اما در شرکت های بزرگ مانند توییتر، فیسبوک، نهادهای اداری مانند مجلس، یونسکو و سازمانهای حوزه بهداشت، این فرآیند باید با دقت و به شکل منظمی انجام شود. بنابراین، مراحل انجام این کار را در ادامه بررسی می کنیم.
پردازش داده یک مرحله حیاتی در یادگیری ماشین (ML) میباشد، زیرا دادهها را برای استفاده در ساخت و آموزش مدلهای یادگیری ماشین آماده میکند. برای درک پردازش داده بهتر است هدف از آن را بدانیم:
هدف از پردازش داده، تمیز کردن، تغییر شکل دادهها و آماده کردن آنها با یک فرمت مناسب برای مدلسازی است.
مراحل اصلی در پردازش داده
1- جمعآوری داده
این فرآیند به معنای گردآوری داده از منابع مختلف مثل حسگرها، پایگاههای داده یا سیستمهای دیگر است. دادهها ممکن است ساختاردار یا بدون ساختار باشند و ممکن است به اشکال مختلفی نظیر متن، تصاویر یا صدا تولید شوند.
2- پیشپردازش داده
در این مرحله، دادهها تمیز میشوند، فیلتر میشوند و به گونهای تغییر شکل مییابند که برای تحلیل بعدی مناسب باشند. این مرحله شامل حذف مقادیر گمشده، مقیاسدهی یا نرمالسازی دادهها یا تبدیل آن به فرمت دیگری میشود.
3- تجزیه و تحلیل داده
در این مرحله، دادهها با استفاده از تکنیکهای مختلفی نظیر تحلیل آماری، الگوریتمهای یادگیری ماشین یا تجسم دادهها تحلیل میشوند. هدف این مرحله استخراج اطلاعات یا دانش از داده است.
4- تفسیر داده
این مرحله شامل تفسیر نتایج تحلیل داده و استنتاجهایی بر اساس دانش به دست آمده است. این مرحله ممکن است شامل ارائه نتایج به شیوهای واضح و مختصر مثل گزارشها، داشبوردها یا تجسمهای دیگر باشد.
5- ذخیره و مدیریت داده
پس از پردازش و تجزیه و تحلیل داده، دادهها باید به گونهای ذخیره و مدیریت شوند که امن و به راحتی قابل دسترسی باشند. این امر ممکن است شامل ذخیره داده در پایگاهداده، ذخیره در فضای ابری یا سیستمهای دیگر باشد. همچنین این مرحله میتواند شامل استفاده از راهکارهای پشتیبانگیری و بازیابی برای محافظت در برابر از دست رفتن دادهها باشد.
6- تجسم و گزارشدهی داده
در نهایت، نتایج تحلیل داده به صورتی ارائه میشوند که به راحتی قابل فهم و اجرایی باشند و این مرحله ممکن است شامل ایجاد تجسمها، گزارشها یا داشبوردهایی باشد که نتایج کلیدی و روندهای داده را نشان میدهند.
برای پردازش داده در یادگیری ماشین، ابزارها و کتابخانههای متعددی نظیر Pandas برای زبان برنامهنویسی پایتون و ابزار تبدیل و تمیزکاری داده در RapidMiner وجود دارد. انتخاب ابزارها بستگی به نیازهای خاص پروژه دارد، که شامل اندازه و پیچیدگی داده و نتیجه مورد نظر است.
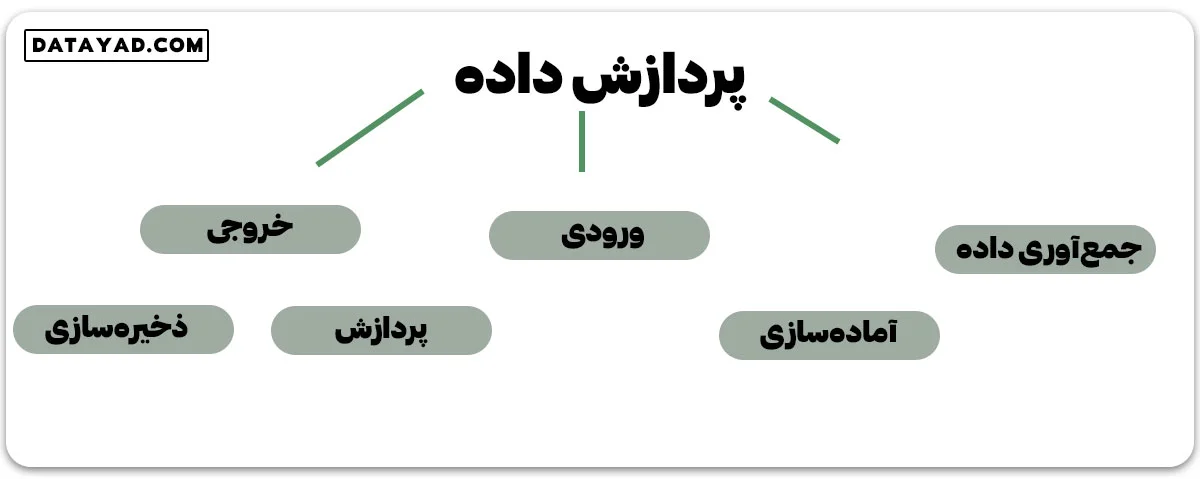
جمعآوری داده
مرحلهی بسیار حیاتی در شروع کار با یادگیری ماشین، داشتن دادههای با کیفیت و دقیق است. دادهها میتوانند از منابع معتبری مانند سایت data.gov.in، Kaggle یا مخزن مجموعه داده UCI جمعآوری شوند.
به عنوان مثال، هنگام آمادهشدن برای یک آزمون رقابتی، دانشآموزان از بهترین منابع آموزشی استفاده میکنند تا بهترین مطالب را یاد بگیرند و نتایج بهتری بدست آورند. به همین ترتیب، دادههای با کیفیت و دقیق، فرآیند یادگیری مدل را آسانتر و بهتر میکنند و در زمان تست، مدل نتایجی با کیفیت بالاتر تولید میکند.
برای جمعآوری داده، مقدار زیادی سرمایه، زمان و منابع صرف میشود. سازمانها یا پژوهشگران باید تصمیم بگیرند که نوع دادهای که برای انجام وظایف یا تحقیقات خود نیاز دارند، چیست.
مثال: در کار روی تشخیص حالات صورت، به تعداد زیادی تصویر با انواع مختلف حالات چهره انسانی نیاز است. داده با کیفیت، اطمینان می دهد که نتایج مدل، معتبر و قابل اعتماد هستند.
آمادهسازی
دادهها گاهی در قالب خاماند و نمیتوان آنها را مستقیم به ماشین داد. در این مرحله، دادهها از منابع مختلف جمعآوری شده و مورد بررسی قرار میشوند، و بر اساس آنها یک مجموعه داده جدید برای پردازشهای بعدی تهیه میشود. این کار میتواند به صورت دستی یا خودکار انجام شود.
همچنین، دادهها میتوانند به قالب عددی هم آماده شوند تا فرآیند یادگیری سریعتر پیش برود. مثلاً، یک تصویر میتواند به یک ماتریس با ابعاد N*N تغییر کند که هر خانهی آن، یک پیکسل از تصویر است.
ورودی
بعضی اوقات دادههای آمادهشده، در قالبی است که ماشین نمیتواند آن را بخواند. در این موارد، نیاز به الگوریتمهایی داریم تا دادهها را برای ماشین قابل فهم کنیم. انجام این کار نیازمند محاسبات قوی و دقیق است. به عنوان مثال، دادهها از منابعی همچون تصاویر ارقام MNIST، نظرات توییتر یا ویدئوها جمعآوری میشوند.
پردازش
در این مرحله، با استفاده از الگوریتمها و تکنیکهای یادگیری ماشین، دستورات بر روی دادهها اجرا میشوند.
خروجی
ماشین نتایج را به شکل قابل فهم برای کاربر ارائه میدهد. این نتایج ممکن است به شکل گزارش، نمودار یا ویدئو باشد.
ذخیرهسازی
در این مرحله نهایی، همه نتایج و مدلهای دادهای که به دست آمده است، برای استفادههای بعدی ذخیره میشوند.
مزایای پردازش داده در یادگیری ماشین
✔️ افزایش کارایی مدل: با تمیز کردن و تبدیل دادهها، مدل یادگیری ماشین بهتر عمل میکند.
✔️ نمایش مناسبتر داده: با پردازش، دادهها به شکلی تبدیل میشوند که روابط و الگوهای موجود در آنها بهتر به نمایش درآیند، و این باعث میشود ماشین بهتر و آسانتر یاد بگیرد.
✔️ افزایش دقت: با اطمینان از صحت و یکپارچگی دادهها، دقت مدل یادگیری بهبود مییابد.
معایب پردازش داده در یادگیری ماشین
✔️ زمانبر: بخصوص در مجموعههای داده بزرگ، پردازش میتواند طول بکشد.
✔️ خطر خطا: در فرآیند پردازش، ممکن است اطلاعاتی از بین بروند یا خطاهای جدیدی ایجاد شود.
✔️ درک ناقص از داده: گاهی دادههای تبدیل شده، تمام جنبهها و روابط موجود در داده اصلی را نمایان نمیکنند.
کتابهای پیشنهادی
برای درک پردازش داده، 3 مورد پایین کتاب های خوبی برای مطالعه هستند:
✔️ «علم داده از صفر: با پایتون» نوشته جول گروس.
✔️ «آمادهسازی داده برای استخراج داده» تألیف دوریان پایل.
✔️ «دستکاری داده با پایتون» نوشته جاکلین کازیل و کاترین جارمول.





