

در جلسه هفتم از آموزش رایگان شبکه عصبی می خواهیم به مفهوم epoch و batch در شبکه عصبی بپردازیم. با ما همراه باشید.
مفهوم epoch
در مسائل یادگیری ماشین (یادگیری عمیق)، مجموعه ای از داده ها را داریم که تعدادی نمونه در خود دارند. همان طور که قبلا دیدیم، این داده ها به عنوان ورودی به شبکه عصبی ما وارد می شوند و پس از تولید خروجی، میزان خطا محاسبه شده و سپس شبکه طی فرایند پس انتشار (back propagation)، وزن ها و بایاس ها را برای دور بعدی محاسبات آپدیت می کند.

هر یک دوری که چرخه فوق به طور کامل طی می شود، یک دوره یا epoch (ایپاک) نام دارد. در هر epoch، شبکه عصبی کل داده ها را می بیند، خطا محاسبه می شود و با پس انتشار (back propagation)، وزن ها و بایاس برای بهبود میزان خطا آپدیت می شوند. ایپاک بعدی نیز دقیقا مشابه ایپاک اول، اما این بار با وزن ها و بایاس های جدید روی کل داده ها طی می شود.
در الگوریتم گرادیان کاهشی (gradient descent) طی هر ایپاک میانگین گرادیان خطا روی کل داده ها محاسبه شده و بر اساس آن وزن ها آپدیت می شوند.
مفهوم batch و mini-batch
اگر با حجم زیادی از داده سر و کار داشته باشیم، به دلیل محدودیت مموری نمی توانیم کل داده را یک جا وارد شبکه کنیم. گذشته از این، حتی اگر مموری هم برای وارد کردن کل دیتا کافی باشد، در صورت وارد کردن کل دیتا به صورت همزمان، سرعت آموزش شبکه بسیار پایین می آید. به همین دلیل ایده دسته های کوچک تر (mini-batch) به میان آمد.
بدین ترتیب دیتاست را به دسته های کوچک تر (mini-batch) تقسیم بندی می کنیم که هر دسته می تواند شامل تعدادی داده باشد.
در شکل زیر طرحواره ای از این ایده نشان داده شده است. همان طور که در شکل می بینیم، اگر کل دیتاست را یک دسته (batch) در نظر بگیریم، هر epoch تنها طی یک چرخه کل داده ها را می بیند. اما با تقسیم داده ها به دسته های کوچک تر (mini-batch)، در هر ایپاک به تعداد این دسته ها باید چرخه آموزش شبکه عصبی طی شود.
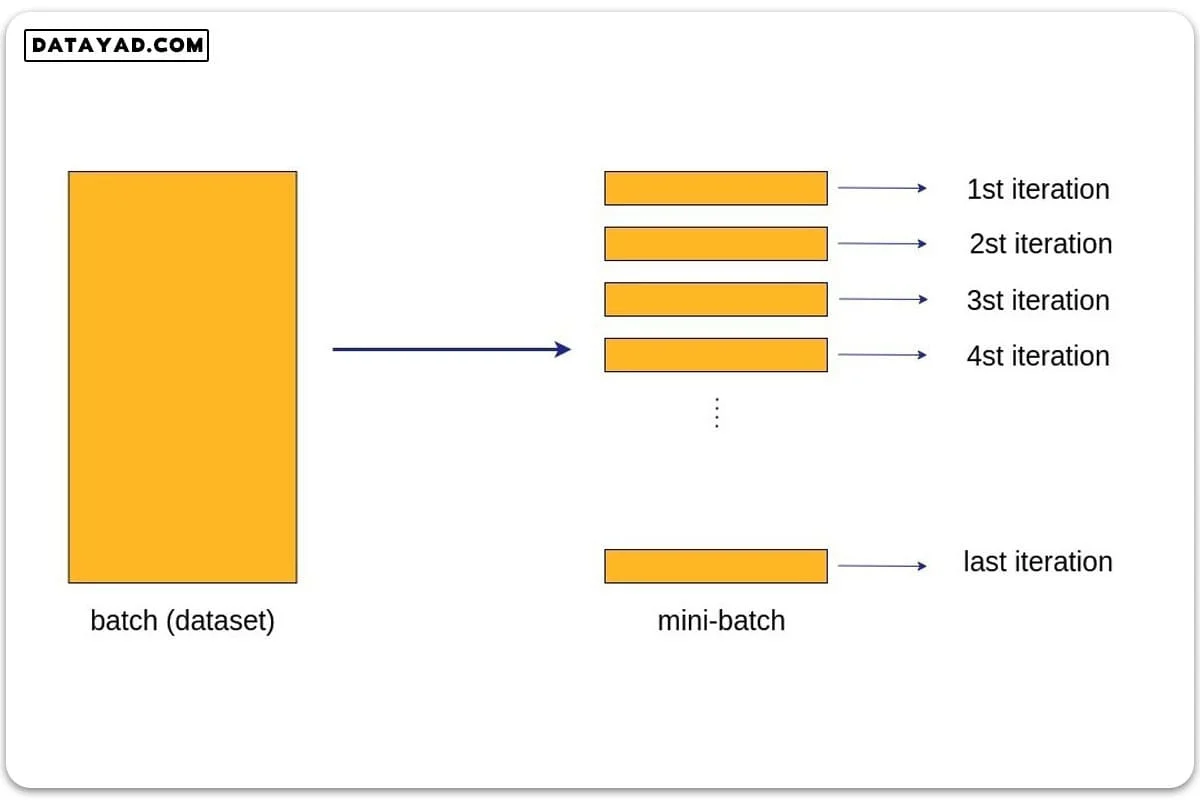
به عنوان مثال اگر کل دیتاست ما شامل ۱۰۰۰ نمونه داده و batch_size ما برابر ۲۰ باشد، به این معناست که کل دیتاست را به دسته های ۲۰ تایی تقسیم می کنیم و هر بار یک دسته از داده ها را به شبکه وارد کرده و خطای مربوطه را محاسبه می کنیم. سپس وزن ها را بر اساس این خطا آپدیت کرده و سراغ دسته ۲۰ تایی بعدی می رویم.
به همین ترتیب پیش می رویم تا شبکه کل دیتاست را یک بار ببیند. در این حالت یک دوره کامل طی می شود و به دوره بعدی می رویم. در این مثال، هر ایپاک شامل آموزش شبکه روی ۵۰ دسته از داده است (20×50=1000). به عبارت دیگر از نگاه کدنویسی، در هر ایپاک، ۵۰ چرخه روی دسته ها باید طی شود. انتخاب batch_size کاملا اختیاریست و بسته به شرایط می تواند تغییر کند.
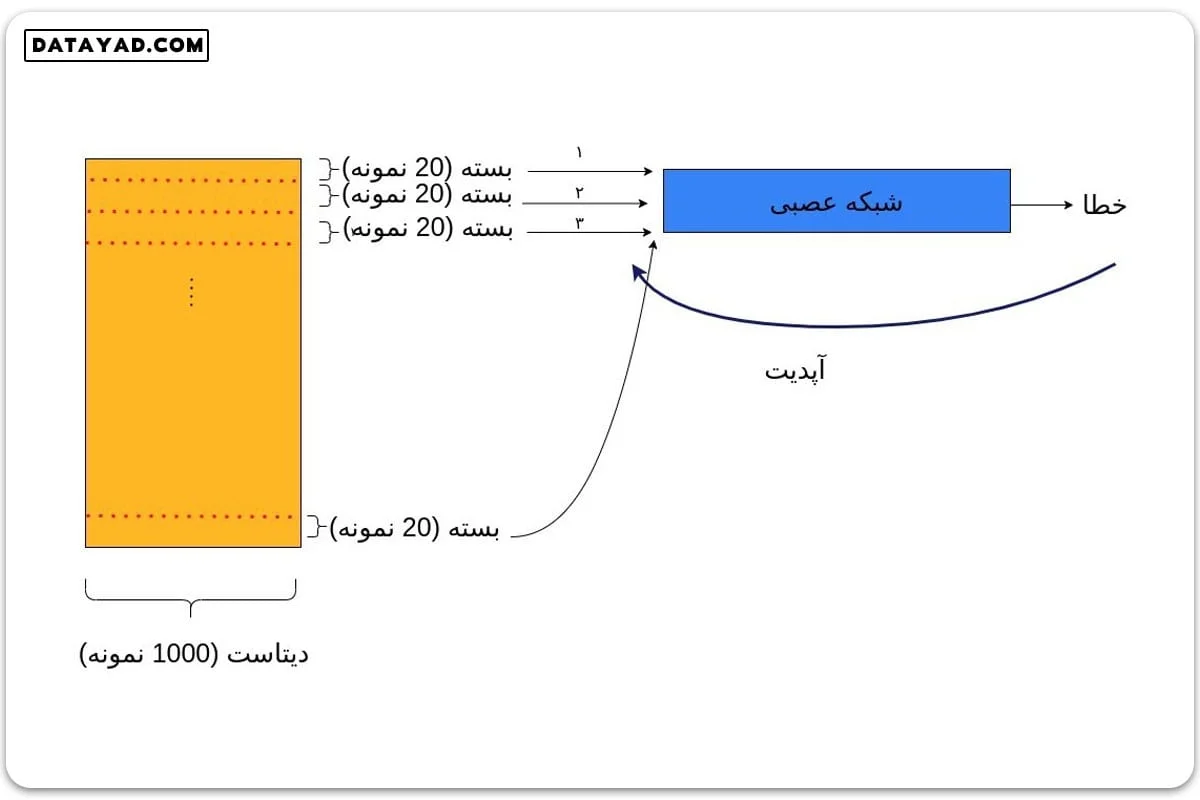
واضح است که این روش مشکل مموری را حل می کند. اما مشکل سرعت چگونه به این صورت برطرف می شود؟ برعکس، به نظر می رسد این روش خیلی سرعت آموزش را پایین بیاورد. زیرا فرایند پس انتشار، که از نظر محاسباتی یک فرایند هزینه بر است، در این مثال به جای یک بار، ۵۰ بار انجام می شود.
نکته اینجاست که در صورتی که کل دیتاست را یک باره به شبکه وارد کنیم، نمی توانیم از پردازش موازی استفاده کنیم. پردازش موازی یعنی اگر CPU هشت هسته داشته باشد، هر هسته به طور جداگانه داده گرفته و پردازش می کند.
در صورت استفاده از GPU دستمان در پردازش موازی بازتر است. پس این دلیل سخت افزاری سبب می شود با وارد کردن داده ها به صورت دسته های کوچک، سرعت آموزش شبکه نیز افزایش پیدا کند.
ضعفی که اینجا مطرح می شود اینست که الگوریتم کلی گرادیان کاهشی باید با دیدن کل داده ها شبکه را آموزش دهد. برای حل این مسأله الگوریتم های بهینه سازی دیگری مطرح شدند. به عنوان مثال SGD (Stochastic Gradient Descent) بر اساس دسته های کوچک (mini batch) تصادفی گرادیان کاهشی را حساب کرده و بهینه سازی را انجام می دهد.
در جلسات آینده درباره الگوریتم های بهینه سازی بیشتر صحبت خواهیم کرد.



















2 پاسخ
خیلی عالی بود ممنون
ممنون از آموزش خوب و مفید