

امروزه، هوش مصنوعی (AI) و یادگیری ماشین (ML) دیگر مفاهیم آیندهنگرانه نیستند، آنها در حال تصمیمگیریهای روزمره برای ما هستند. از پیشنهاد شغلی که در شبکههای اجتماعی میبینید، تا وامی که بانک به شما میدهد و حتی تشخیصهای پزشکی، همه جا الگوریتمها نقش کلیدی دارند. اما آیا تا به حال فکر کردهاید که این تصمیمات تا چه حد منصفانه هستند؟ چه اتفاقی میافتد اگر این سیستمهای هوشمند، به طور پنهان و سیستماتیک، علیه گروهی از مردم جانبداری کنند؟ این پدیده خطرناک،سوگیری الگوریتمی (Algorithmic Bias) نام دارد.
سوگیری الگوریتمی به زبان ساده یعنی تولید نتایج ناعادلانه و تبعیضآمیز که از دادههای جانبدارانه یا طراحیهای معیوب در هوش مصنوعی ناشی می شود. این مشکل فقط یک بحث تئوری یا اخلاقی نیست، بلکه یک چالش واقعی با پیامدهای جدی در دنیای واقعی است. در این مقاله، ما به طور عمیق بررسی میکنیم که سوگیری الگوریتمی چیست، از کجا ریشه میگیرد، چرا یک تهدید جدی محسوب میشود، و چطور میتوانیم جلوی آن را بگیریم.

سوگیری الگوریتمی چیست؟
سوگیری الگوریتمی (Algorithmic Bias) به زبان ساده یعنی نتایج ناعادلانه. این اتفاق زمانی رخ میدهد که یا دادههای ورودی ما از ابتدا جانبدارانه یا ناقص بودهاند، یا خود الگوریتمها ناعادلانه طراحی شدهاند، یا اینکه در فرآیند توسعه هوش مصنوعی، برخی گروهها نادیده گرفته شدهاند.
اگر بخواهیم دقیقتر بگوییم، سوگیری الگوریتمی یک جور خطای سیستمی و تکرارشونده در کامپیوتر است که باعث میشود خروجیهای غیرمنصفانه تولید کند، مثلا، یک گروه از کاربران را بیدلیل به گروهی دیگر ترجیح دهد.
این روزها که ردپای هوش مصنوعی (AI) و یادگیری ماشین (ML) تقریبا در همهجای زندگی ما باز شده است، این سوگیری به یک دغدغه بسیار جدی تبدیل شده است.
توضیح ساده سوگیری الگوریتمی
بیایید با یک مثال ساده شروع کنیم. یک ابزار تصمیمگیر را تصور کنید، مثلا یک سیستم هوشمند که قرار است افراد را دستهبندی کند. حالا چه اتفاقی میافتد اگر این سیستم، در زمان آموزش، فقط یک نوع خاص از آدمها را دیده باشد؟
طبیعتا، وقتی با افرادی مواجه میشود که با آن معیارهای “همیشگی” جور در نمیآیند، در قضاوتش دچار اشتباه میشود و نسبت به گروهی که شبیهشان آموزش دیده، جانبداری نشان میدهد. این دقیقا خلاصهی سوگیری الگوریتمی است.
همانطور که قبلا اشاره شد، ریشه این سوگیری یا در دادههای ورودی جانبدارانه و ناقص است، یا در الگوریتمهای ناعادلانه، یا در روشهایی که در طول توسعه هوش مصنوعی باعث نادیده گرفتن برخی گروهها شدهاند.
حل این مشکل فوقالعاده حیاتی است، چون امروزه سیستمهای هوش مصنوعی در حوزههای بسیار مهمی مانند بهداشت و درمان، امور مالی، و سیستم قضایی نقش دارند و یک تصمیمگیری جانبدارانه در این بخشها میتواند عواقب بسیار مخربی داشته باشد.
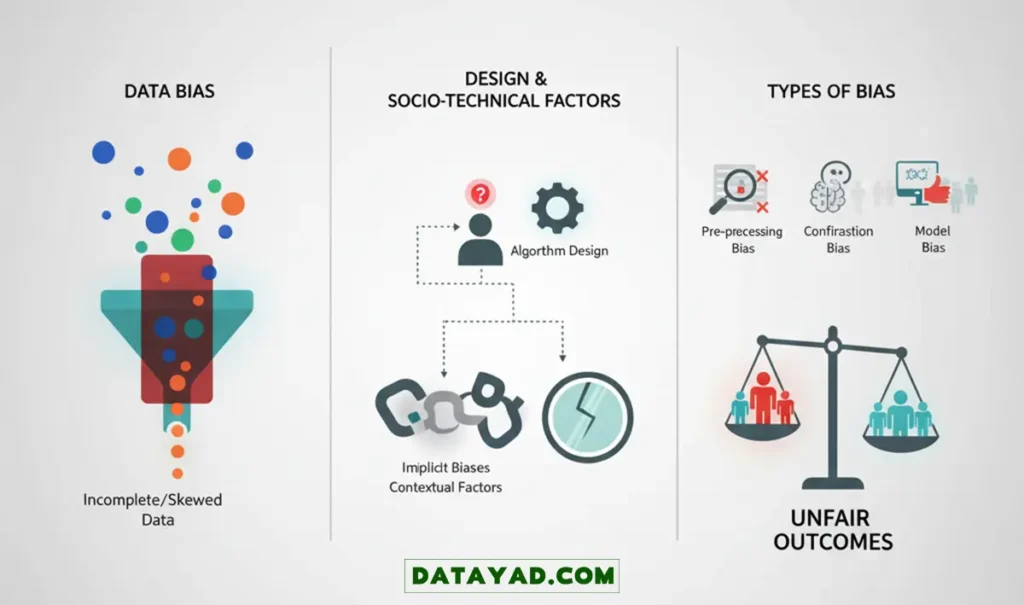
چندین عامل کلیدی در به وجود آمدن سوگیری الگوریتمی نقش دارند:
- سوگیری داده (Data Bias): اگر دادهای که برای آموزش هوش مصنوعی استفاده میشود، نماینده واقعی کل جامعه نباشد، تصمیمات الگوریتم به نفع گروهی خواهد بود که بیشترین داده را از آن دیده است.
- جانبداری در طراحی: اگر طراحان هوش مصنوعی، خودشان تعصبات پنهان داشته باشند، این تعصبات ممکن است ناخواسته به رفتار و تصمیمات سیستم منتقل شوند.
- عوامل اجتماعی-فنی: این مورد به تاثیر زمینههای اجتماعی، اقتصادی و فرهنگی بر نحوه طراحی، پیادهسازی و استفاده از سیستمهای هوش مصنوعی اشاره دارد، که این زمینهها نیز میتوانند باعث ایجاد سوگیری شوند.
انواع مختلفی از سوگیری الگوریتمی وجود دارد که ممکن است در طول فرآیند یادگیری ماشین وارد سیستم شوند. برای مثال، سوگیری پیشپردازش (Pre-processing Bias) ناشی از فرآیندهای پاکسازی جانبدارانه داده است. سوگیری تاییدی (Confirmation Bias) زمانی رخ میدهد که سیستم هوش مصنوعی، باورها یا کلیشههای قبلی ما را تایید میکند. سوگیری حذفی (Exclusion Bias) یعنی گروههای خاصی به طور سیستماتیک از دادههای آموزشی کنار گذاشته میشوند، و در نهایت سوگیری الگوریتمی یا سوگیری مدل (Model Bias) زمانی پیش میآید که خود مدل، نتایج یا گروههای خاصی را ترجیح میدهد.
درک عمیق این سوگیریها برای ساختن سیستمهای هوش مصنوعی منصفانه و عادلانه کاملا ضروری است.
مثالهایی از سوگیری الگوریتمی در دنیای واقعی
برای اینکه این مفهوم کاملا جا بیفتد، بیایید چند مثال واقعی را بررسی کنیم:
- الگوریتمهای استخدام: شرکت آمازون زمانی یک سیستم هوش مصنوعی ساخت تا فرآیند استخدام خود را خودکار کند. این الگوریتم با رزومههایی آموزش دیده بود که در طول ده سال به شرکت ارسال شده بودند، و اکثر این رزومهها متعلق به مردان بودند. در نتیجه، سیستم به طور خودکار شروع به ترجیح دادن نامزدهای مرد نسبت به نامزدهای زن کرد، که این یک سوگیری واضح را نشان میداد.
- سیستمهای تشخیص چهره: مطالعات متعددی نشان دادهاند که الگوریتمهای تشخیص چهره، مانند آنهایی که در سیستمهای نظارتی یا برای باز کردن قفل گوشیهای هوشمند استفاده میشوند، اغلب در تشخیص چهرههای تیرهپوستتر و چهرههای زنان عملکرد ضعیفی دارند. دلیل اصلی این مشکل، نبود تنوع کافی در مجموعه دادههای آموزشی است.
اگر نگاهی به آینده بیندازیم، میبینیم که هوش مصنوعی روزبهروز بیشتر با زندگی ما عجین میشود. اگر جلوی سوگیری الگوریتمی گرفته نشود، تاثیرات مخرب آن در آینده بسیار شدیدتر هم خواهد شد.
تصور کنید سیستمهای تشخیص جرائم به شکلی ناعادلانه روی محلهها یا جوامع خاصی زوم کنند، یا الگوریتمهای اعتبارسنجی، حق گروههایی با وضعیت اقتصادی-اجتماعی ضعیفتر را پایمال کنند، یا ابزارهای آموزش شخصیسازیشده، جلوی پیشرفت تحصیلی برخی دانشآموزان را بگیرند.
قدرت و نفوذی که هوش مصنوعی در آیندهی جامعه خواهد داشت، به ما نشان میدهد که چقدر همین حالا باید فکری به حال سوگیری الگوریتمی بکنیم. ما باید مطمئن شویم که تصمیمهایی که هوش مصنوعی میگیرد، منصفانه، عادلانه و بازتابدهنده واقعیت تمام گروههای جامعه است، نه فقط بخشی از آن.
چگونه «سوگیری» را به صورت فنی شناسایی و اندازهگیری کنیم؟
بسیار خب، ما مثالهای نگرانکننده را دیدیم. اما قبل از اینکه بتوانیم سوگیری را برطرف کنیم، اول باید بتوانیم آن را پیدا کنیم. در دنیای علم داده، پیدا کردن به معنای اندازهگیری است. ما نمیتوانیم چیزی را که اندازهگیری نمیکنیم، مدیریت کنیم.
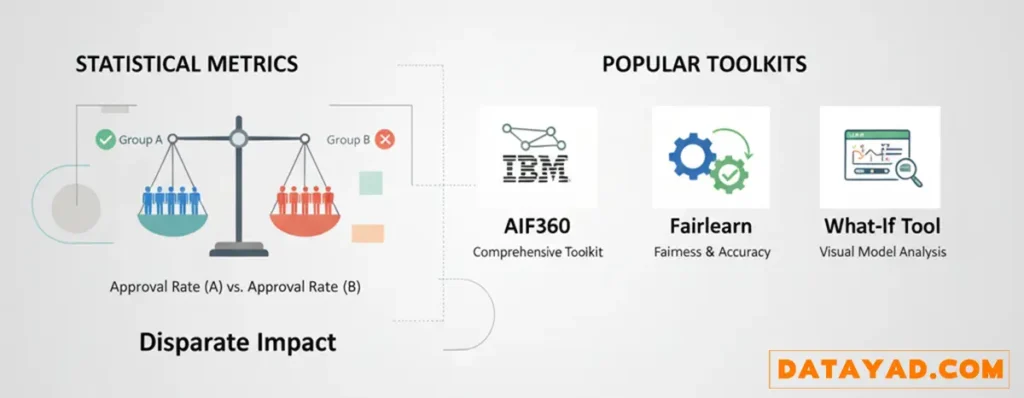
خوشبختانه، شناسایی سوگیری یک کار سلیقهای یا حسی نیست. ما برای این کار شاخصهای آماری و معیارهای منصفانه مشخصی داریم. ایده اصلی این است: ما خروجیهای مطلوب (مثلا، «تایید وام» یا «استخدام») را بین گروههای مختلف مقایسه میکنیم تا ببینیم آیا تفاوت معناداری وجود دارد یا نه.
برای مثال، یکی از معروفترین معیارها، تاثیر نامتوازن (Disparate Impact) است. این شاخص به سادگی نرخ نتایج مثبت برای یک گروه (مثلا، گروه الف) را با نرخ نتایج مثبت برای گروه دیگر (مثلا، گروه ب) مقایسه میکند. اگر الگوریتم شما ۸۰ درصد از گروه الف را تایید کند، ولی فقط ۵۰ درصد از گروه ب را تایید کند، شما با یک سوگیری واضح و قابل اندازهگیری مواجه هستید.
نکته مهم اینجاست که لازم نیست شما این محاسبات پیچیده را از صفر انجام دهید. امروزه ابزارها و کتابخانههای قدرتمندی برای این کار وجود دارند که به تیمهای فنی کمک میکنند سوگیری را در پایپلاین یادگیری ماشین خود شناسایی کنند:
- AIF360 (محصول IBM): یک جعبه ابزار بسیار جامع و متنباز است که دهها معیار مختلف برای شناسایی و حتی الگوریتمهایی برای کاهش سوگیری ارائه میدهد.
- Fairlearn (محصول مایکروسافت): این کتابخانه محبوب به شما اجازه میدهد انصاف را در کنار دقت مدل خود ارزیابی کنید و بین این دو، توازن برقرار نمایید.
- What-If Tool (محصول گوگل): ابزاری فوقالعاده برای درک بصری رفتار مدل است. به شما اجازه میدهد به صورت تعاملی ببینید اگر ورودیها را تغییر دهید (مثلا، سن یا جنسیت را عوض کنید)، خروجی مدل چه تغییری میکند.
بنابراین، با استفاده از این معیارهای ارزیابی و ابزارها، ما میتوانیم از سطح «احساس میکنم سیستم ناعادلانه است» به سطح «میتوانم با دادهها ثابت کنم که کدام بخش ناعادلانه کار میکند» برویم. این دقیقا اولین قدم فنی و ضروری برای ساختن هوش مصنوعی مسئولانه (Responsible AI) است.
چطور جلوی سوگیری الگوریتمی را بگیریم؟
مقابله با سوگیری الگوریتمی نیازمند تلاشی آگاهانه در مراحل مختلف توسعه هوش مصنوعی است:
- دادههای متنوع: باید مطمئن شویم دادههایی که برای آموزش مدلهای یادگیری ماشین استفاده میکنیم، بازتابدهنده واقعی تمام گروههای جمعیتی باشند که قرار است از این سیستم استفاده کنند.
- ممیزی سوگیری: باید مرتبا سیستمهای هوش مصنوعی را آزمایش و بازبینی کنیم تا سوگیری احتمالی و عملکرد منصفانه آنها را بسنجیم.
- شفافیت: باید مستندات شفافی داشته باشیم که به وضوح نشان دهد سیستم هوش مصنوعی چطور تصمیم میگیرد.
- تیمهای توسعه فراگیر: حضور یک تیم متنوع از توسعهدهندگان هوش مصنوعی کمک میکند تا تعصباتی که ممکن است از چشم بقیه پنهان بمانند، شناسایی و متعادل شوند.
یادداشت نویسنده: رویکردی متفاوت برای غلبه بر سوگیری الگوریتمی
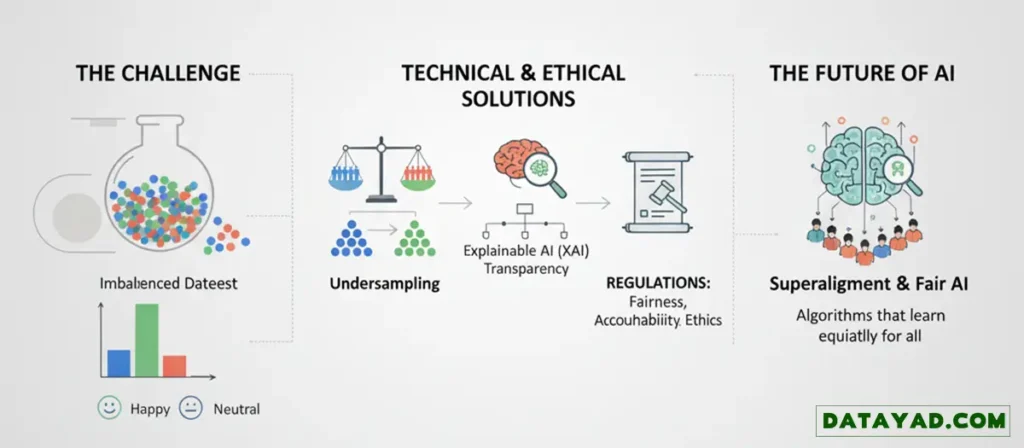
اولین باری که متوجه شدم Dataset من سوگیری دارد، زمانی بود که داشتم یک مدل تحلیل احساسات (Sentiment Analysis) را آموزش میدادم. فهمیدم که حتی توزیع نامتعادل بین کلاسها هم میتواند منجر به نتایج جانبدارانه شود، طوری که مدل من برچسب «خوشحال» را خیلی دقیقتر از «خنثی» پیشبینی میکرد.
من این مشکل را با افزایش داده (Oversampling) و کاهش داده (Undersampling) حل کردم، اما این تجربه باعث شد تا اهمیت حیاتی شفافیت و داشتن یک مجموعه داده متعادل را در ساخت سیستمهای خودکار منصفانه، عمیقا درک کنم.
به نظر من، علاوه بر دادههای متنوع، ممیزی سوگیری، شفافیت و تیمهای فراگیر، ما به سیستمهایی مانند هوش مصنوعی قابل توضیح (Explainable AI) نیاز داریم تا سوگیری را در دل الگوریتمها شناسایی کنیم. فراتر از آن، باید قوانینی تصویب شود که شرکتها را مجبور کند تا از اصول انصاف، پاسخگویی، شفافیت و اخلاق در هوش مصنوعی پیروی کنند.
از دیدگاه من، تقریبا تمام دادهها به نوعی سوگیری دارند، چون این دادهها از انسانها جمعآوری میشوند و ما انسانها ذاتا نسبت به نژاد، رنگ، مذهب، سیستمها و باورها تعصبات ذاتی داریم. در حال حاضر حذف کامل این مشکل تقریبا غیرممکن است.
با این حال، با ظهور هوش مصنوعی پیشرفتهتر، شاید شاهد الگوریتمهایی باشیم که بتوانند به شکل متعادلتری از محیط خود یاد بگیرند و اپلیکیشنهایی بسازند که برای همه مردم عادلانه کار کنند. برای مثال، پروژه Superalignment شرکت OpenAI دقیقا با این هدف کار میکند که مطمئن شود سیستمهای هوش مصنوعی که از هوش انسانی فراتر میروند، همچنان با ارزشها و اهداف انسانی همسو باقی بمانند.
سوالات متداول
اگر جلوی سوگیری را نگیریم چه عواقبی دارد؟
سوگیری الگوریتمی کنترلنشده، مستقیما به نتایج ناعادلانه و تبعیضآمیز منجر میشود. این اتفاق به افرادی یا گروههایی آسیب میزند که در دادههای آموزشی یا به خوبی دیده نشدهاند یا به اشتباه بازنمایی شدهاند.
آیا سوگیری الگوریتمی را میتوان به طور کامل از بین برد؟
حذف کامل سوگیری الگوریتمی کار بسیار دشواری است. اما میتوان با اقداماتی مانند (Bias Auditing)، استفاده از مجموعه دادههای متنوع و تشکیل تیمهای توسعه فراگیر، آن را به میزان قابل توجهی کاهش داد.
قانونگذاری چه نقشی در مقابله با سوگیری الگوریتمی دارد؟
قانونگذاری میتواند نقش بسیار حیاتی ایفا کند. قوانین میتوانند استانداردهایی برای شفافیت، پاسخگویی و انصاف تعیین کنند که سیستمهای هوش مصنوعی ملزم به رعایت آنها باشند. این کار به کنترل سوگیری الگوریتمی کمک زیادی میکند.
آیا سوگیری قابل شناسایی و اندازهگیری است؟
بله، سوگیری الگوریتمی را میتوان با تکنیکهای مختلفی شناسایی و اندازهگیری کرد. این روشها اغلب شامل مقایسه عملکرد الگوریتم در گروههای مختلف است تا مشخص شود آیا گروههای خاصی به طور نامتناسبی تحت تاثیر قرار میگیرند یا نه.
یک مثال واقعی از تاثیر سوگیری الگوریتمی چیست؟
یک نمونه برجسته از تاثیر سوگیری الگوریتمی در حوزه بهداشت و درمان دیده شد. الگوریتمی که برای هدایت تصمیمات درمانی میلیونها بیمار استفاده میشد، سوگیری نژادی داشت. این الگوریتم، بیماران سیاهپوست را در مقایسه با بیماران سفیدپوست که دقیقا به همان اندازه بیمار بودند، کمتر به برنامههای مراقبت ویژه ارجاع میداد.
کاربران عادی چطور میتوانند سوگیری را تشخیص دهند؟
اگرچه تحلیل عمیق سوگیری به تخصص فنی نیاز دارد، اما کاربران عادی هم میتوانند مراقب الگوهای تکرارشونده از نتایج ناعادلانه باشند، به خصوص اگر این نتایج همیشه به ضرر یک گروه خاص تمام میشود. اگر چنین الگویی را مشاهده کردید، باید آن را به سازمان مربوطه یا در صورت لزوم، به نهادهای ناظر گزارش دهید.




















