

هوش مصنوعی به بخشی جداییناپذیر از زندگی و کسبوکار ما تبدیل شده است. برای درک عمیق این فناوری تحولآفرین و تسلط بر مهارتهای مورد نیاز بازار کار، بهرهگیری از مسیرهای تخصصی آموزش هوش مصنوعی اولین و مهمترین گام برای ورود حرفهای به این دنیای بیپایان است. در پشت صحنه هر سیستم هوشمندی، از پیشنهادگرهای نتفلیکس گرفته تا خودروهای خودران، مجموعهای از دستورالعملهای پیچیده ریاضی به نام الگوریتم های هوش مصنوعی قرار دارند.
این الگوریتمها در واقع موتور محرک حوزه علم داده (Data Science) محسوب میشوند که به ماشینها اجازه میدهند به جای اجرای ساده دستورات، از دادهها یاد بگیرند و به صورت هوشمند تصمیمگیری کنند. در این مقاله، ما به بررسی جامع انواع الگوریتمها، از یادگیری ماشین (Machine Learning) تا ساختارهای پیچیده در یادگیری عمیق (Deep Learning) میپردازیم و بررسی میکنیم که هر کدام چگونه دنیای ما را تغییر میدهند.

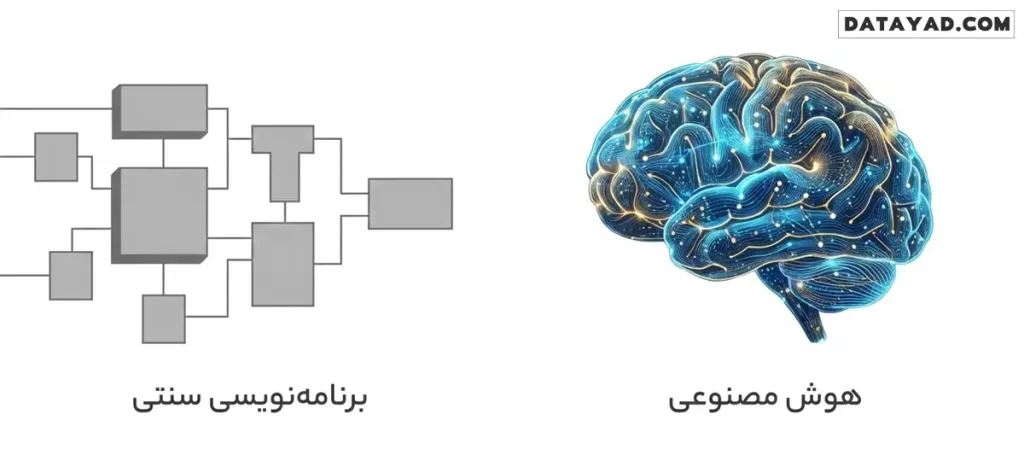
الگوریتم هوش مصنوعی چیست و چه تفاوتی با برنامهنویسی سنتی دارد؟
برای اینکه بفهمیم هوش مصنوعی دقیقاً چه کار میکند، بهتر است آن را با برنامهنویسی کلاسیک مقایسه کنیم. در برنامهنویسی سنتی، ما یک «آشپز» هستیم که دستور پخت (کد) را دقیقاً به کامپیوتر میدهیم؛ مثلاً به او میگوییم: «اگر کاربر دکمه الف را زد، خروجی ب را نشان بده.» در اینجا ماشین هیچ خلاقیتی ندارد و فقط دستورات ما را مو به مو اجرا میکند.
اما در دنیای الگوریتم های هوش مصنوعی، ماجرا کاملاً متفاوت است. در اینجا ما به جای دادن دستورات صلب، دادهها را به همراه نتایج مطلوب به الگوریتم میدهیم و از او میخواهیم که خودش «قانون» یا «الگو» را پیدا کند. این همان نقطهای است که یادگیری ماشین وارد عمل میشود.
تفاوتهای کلیدی این دو رویکرد:
- منطق یادگیری: در برنامهنویسی سنتی، منطق توسط انسان نوشته میشود، اما در هوش مصنوعی، منطق توسط الگوریتم و از دل دادهها استخراج میگردد.
- انعطافپذیری: برنامههای سنتی در مواجهه با شرایط جدید که برایشان تعریف نشده، از کار میافتند. در مقابل، الگوریتمهای هوشمند قابلیت تعمیمدهی دارند و میتوانند درباره دادههای جدیدی که قبلاً ندیدهاند، اظهار نظر کنند.
- حل مسائل پیچیده: مسائلی مثل تشخیص چهره یا ترجمه زبان، به قدری پیچیده هستند که نمیتوان برای آنها میلیونها دستور «اگر-آنگاه» نوشت؛ اینجاست که قدرت یادگیری عمیق و شبکههای عصبی نمایان میشود.
در واقع، هدف اصلی هر الگوریتم هوشمند این است که با کمترین خطا، الگوهای نهفته در دادههای بزرگ را پیدا کند. به همین دلیل است که امروزه متخصصان علم داده زمان زیادی را صرف انتخاب و بهینهسازی این الگوریتمها میکنند تا به دقیقترین پیشبینی ممکن برسند.
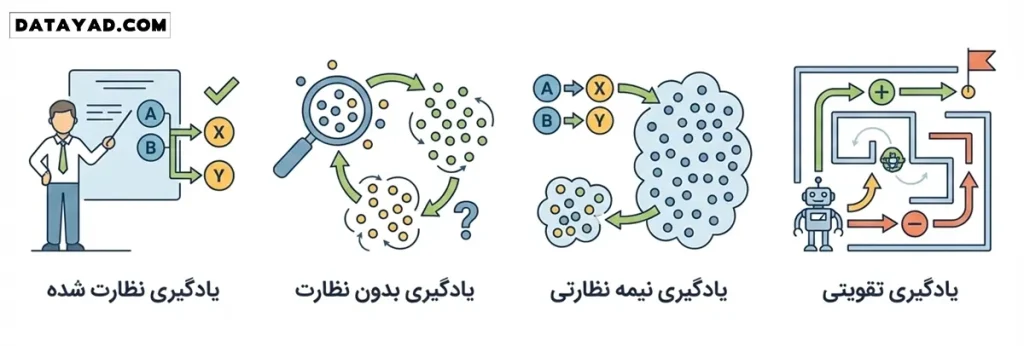
طبقهبندی الگوریتم های هوش مصنوعی بر اساس شیوه یادگیری
در دنیای علم داده، الگوریتمها را بر اساس نوع دسترسی به دادهها و نحوه یادگیریشان به دستههای مختلفی تقسیم میکنند. این تقسیمبندی به شما کمک میکند تا بدانید برای هر مسئله خاص، از کدام جعبهابزار باید استفاده کنید.
۱. یادگیری نظارت شده (Supervised Learning)
یادگیری نظارت شده رایجترین نوع یادگیری در یادگیری ماشین است. در این مدل، ما دادههایی را در اختیار الگوریتم قرار میدهیم که قبلاً برچسبگذاری شدهاند؛ یعنی ورودی و خروجیِ درست هر دو مشخص هستند. الگوریتم تلاش میکند رابطهای میان ورودی و خروجی پیدا کند تا در آینده برای دادههای جدید، خروجی را پیشبینی کند.
مثال بارز: تشخیص ایمیلهای اسپم. ما هزاران ایمیل را به سیستم میدهیم و مشخص میکنیم کدام اسپم است و کدام نیست. الگوریتم با یادگیری ویژگیهای این ایمیلها، در دفعات بعد خودش تصمیم میگیرد.
الگوریتمهای معروف: رگرسیون خطی، درخت تصمیم و SVM.
۲. یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت خبری از برچسب یا خروجی مشخص نیست. الگوریتم هوش مصنوعی باید خودش دست به کار شود و الگوهای پنهان یا ساختارهای مشابه را در حجم عظیمی از دادهها پیدا کند. این روش برای زمانی که نمیدانیم به دنبال چه چیزی هستیم اما میخواهیم دادهها را دستهبندی کنیم، فوقالعاده است.
مثال بارز: بخشبندی مشتریان (Customer Segmentation). یک فروشگاه اینترنتی دادههای خرید هزاران نفر را به الگوریتم میدهد تا مشتریان را بر اساس رفتارهای مشابه در گروههای مختلف دستهبندی کند.
الگوریتمهای معروف: خوشهبندی K-Means و تحلیل مولفه اصلی (PCA).
۳. یادگیری نیمه نظارتی (Semi-supervised Learning)
این روش ترکیبی از دو مورد قبلی است و زمانی کاربرد دارد که ما مقدار کمی داده برچسبدار و حجم زیادی داده بدون برچسب داریم. از آنجایی که برچسبگذاری دادهها توسط انسان هزینهبر و زمانبر است، یادگیری نیمه نظارتی با استفاده از همان دادههای اندک، شروع به یادگیری کرده و سپس آن را به دادههای بدون برچسب تعمیم میدهند.
۴. یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی متفاوتترین و جذابترین نوع یادگیری است که شباهت زیادی به یادگیری انسان دارد. در اینجا الگوریتم (که به آن Agent میگوییم) در یک محیط قرار میگیرد و با آزمون و خطا، سعی میکند به هدف برسد. اگر حرکت درستی انجام دهد، «پاداش» میگیرد و اگر اشتباه کند، «جریمه» میشود.
مثال بارز: یادگیری بازی شطرنج توسط هوش مصنوعی یا آموزش رباتها برای حرکت در محیطهای ناهموار.
تمرکز: این بخش پایه و اساس بسیاری از پیشرفتهای جدید در یادگیری عمیق و سیستمهای خودمختار است.
انتخاب میان این روشها، اولین قدم در طراحی یک پروژه هوشمند است. متخصصان با بررسی نوع صورتمسئله و دادههای در دسترس، تصمیم میگیرند که کدام یک از این مسیرها میتواند به دقیقترین نتیجه منجر شود.
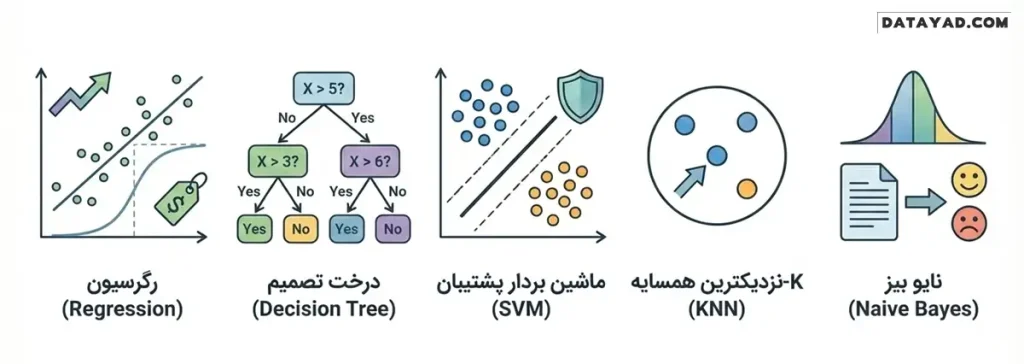
بررسی محبوبترین الگوریتمهای یادگیری ماشین (Machine Learning)
زمانی که صحبت از پیادهسازی پروژههای هوشمند میشود، انتخاب الگوریتم مناسب نیمی از راه است. در دنیای یادگیری ماشین، ما با طیف گستردهای از مدلها روبرو هستیم که هر کدام برای حل نوع خاصی از مسائل (رگرسیون یا طبقهبندی) طراحی شدهاند. در ادامه، پرکاربردترین الگوریتمهای یادگیری ماشین را بررسی میکنیم.
۱. الگوریتمهای رگرسیون (Regression)
هدف اصلی در رگرسیون، پیشبینی یک عدد دقیق است؛ مثلاً قیمت مسکن یا میزان فروش یک محصول در ماه آینده.
- رگرسیون خطی (Linear Regression): سادهترین و در عین حال یکی از قدرتمندترین الگوریتمها که سعی میکند رابطهای خطی میان متغیرهای ورودی و خروجی پیدا کند.
- رگرسیون لجستیک (Logistic Regression): برخلاف نامش، بیشتر برای مسائل «طبقهبندی دو کلاسه» استفاده میشود (مثلاً بله یا خیر، موفق یا ناموفق).
۲. درخت تصمیم (Decision Tree)
درخت تصمیم ساختاری شبیه به درخت دارد که در هر گره آن، یک سوال درباره دادهها پرسیده میشود. با پاسخ به این سوالات، در نهایت به شاخههای انتهایی (برگها) میرسیم که نتیجه نهایی را مشخص میکنند. درک منطق درخت تصمیم بسیار ساده است و به همین دلیل در علم داده برای مدلسازیهای بصری بسیار محبوب است.
۳. ماشین بردار پشتیبان (SVM)
الگوریتم SVM یکی از دقیقترین روشها برای دستهبندی دادههای پیچیده است. وظیفه اصلی آن، پیدا کردن بهترین «مرز» یا ابرصفحه (Hyperplane) است که بتواند دادههای دو کلاس مختلف را با بیشترین فاصله ممکن از هم جدا کند. این الگوریتم در تشخیص تصویر و متن کاربرد فراوانی دارد.
۴. الگوریتم K-نزدیکترین همسایه (KNN)
منطق KNN بسیار شهودی است: «بگو دوستانت کیستند تا بگویم کیستی!». این الگوریتم برای پیشبینی وضعیت یک داده جدید، به دادههای مشابه و نزدیک به آن نگاه میکند. اگر اکثر همسایههای یک نقطه متعلق به گروه A باشند، آن نقطه هم به گروه A نسبت داده میشود.
۵. نایو بیز (Naive Bayes)
این الگوریتم بر پایه قضایای احتمالات (قانون بیز) کار میکند. با وجود سادگی، در پردازش زبان طبیعی (NLP) و به ویژه در طبقهبندی متن و تشخیص احساسات، عملکرد خیرهکنندهای دارد.
انتخاب هوشمندانه؛ کلید موفقیت پروژهها
بسیاری از دانشجویان در ابتدای مسیر آموزش الگوریتم های هوش مصنوعی تصور میکنند که همیشه باید سراغ پیچیدهترین الگوریتم بروند. اما واقعیت این است که در بسیاری از پروژههای سبک، یک رگرسیون ساده یا درخت تصمیم بهینهسازی شده، نتایج بسیار بهتری نسبت به مدلهای سنگین ارائه میدهد.
نکته مهم این است که تمامی این الگوریتمها برای یادگیری بهتر، به فرآیندی به نام «بهینهسازی» نیاز دارند تا خطای خود را به حداقل برسانند. در واقع، اینجاست که نقش الگوریتمهای بهینهسازی به عنوان مکملهای حیاتی در یادگیری ماشین پررنگ میشود.
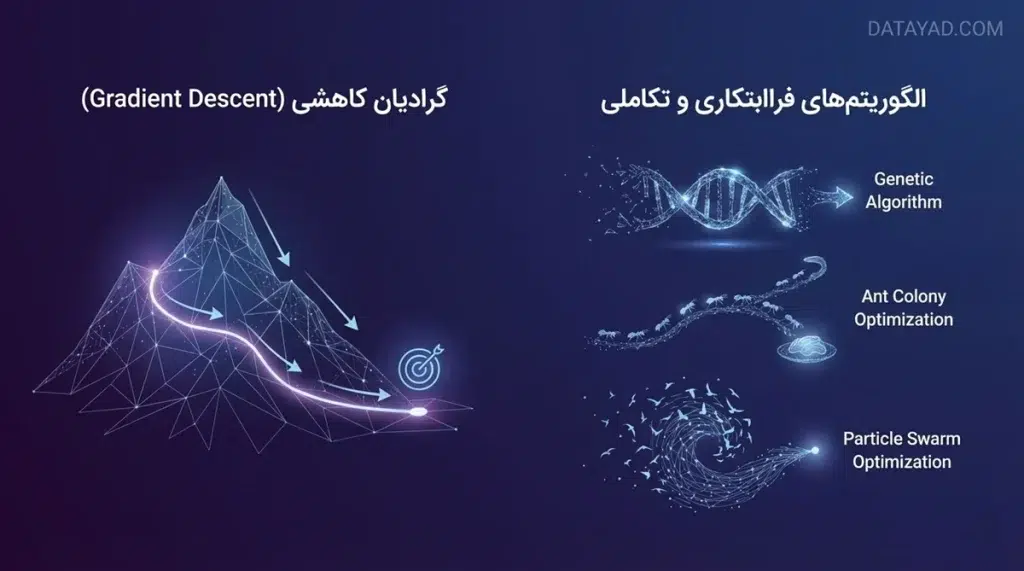
یادگیری عمیق (Deep Learning)؛ الگوریتمهایی با ساختار عصبی
اگر یادگیری ماشین را یک گام بزرگ رو به جلو بدانیم، یادگیری عمیق یک جهش کوانتومی در دنیای محاسبات است. در حالی که الگوریتمهای سنتی یادگیری ماشین در مواجهه با دادههای بسیار حجیم و پیچیده (مثل تصاویر با کیفیت بالا یا فایلهای صوتی) ممکن است دچار محدودیت شوند، مدلهای یادگیری عمیق هرچه داده بیشتری دریافت کنند، عملکرد خیرهکنندهتری از خود نشان میدهند.
شبکههای عصبی مصنوعی (ANN) چگونه کار میکنند؟
هسته اصلی این فناوری، شبکههای عصبی مصنوعی هستند. این شبکهها از لایههای مختلفی از «نورونها» تشکیل شدهاند:
- لایه ورودی: دادههای خام (مثل پیکسلهای یک عکس) را دریافت میکند.
- لایههای پنهان (Hidden Layers): جادوی اصلی اینجا اتفاق میافتد. هرچه تعداد این لایهها بیشتر باشد، شبکه «عمیقتر» میشود. این لایهها ویژگیهای پیچیده دادهها را استخراج میکنند.
- لایه خروجی: نتیجه نهایی (مثلاً تشخیص اینکه عکس مربوط به یک خودرو است) را ارائه میدهد.
معماریهای برتر در یادگیری عمیق
برای حل مسائل مختلف، معماران علم داده از ساختارهای متفاوتی استفاده میکنند:
- شبکههای عصبی کانولوشن (CNN): متخصص تحلیل تصاویر هستند. از باز کردن قفل گوشی با تشخیص چهره تا پردازش تصاویر پزشکی، همگی مدیون الگوریتمهای CNN هستند.
- شبکههای عصبی بازگشتی (RNN): این مدلها دارای «حافظه» هستند و برای دادههایی که توالی دارند (مثل زمان یا متن) عالی عمل میکنند. ترجمه متون و پیشبینی سریهای زمانی در بورس از کاربردهای اصلی آن است.
- ترنسفورمرها (Transformers): انقلابیترین الگوریتمهای سالهای اخیر که زیربنای مدلهایی مثل GPT هستند. این الگوریتمها به جای بررسی کلمه به کلمه، به کل متن به صورت همزمان نگاه میکنند و ارتباط میان کلمات را درک میکنند.
چرا یادگیری عمیق آینده هوش مصنوعی است؟
واقعیت این است که بدون یادگیری عمیق، پیشرفتهایی مثل دستیارهای صوتی هوشمند یا خودروهای خودران هرگز ممکن نبود. این الگوریتمها به ماشینها اجازه میدهند تا ظرافتهای زبان انسان و پیچیدگیهای محیط فیزیکی را درک کنند.
تسلط بر این مباحث، قلهای است که بسیاری از علاقمندان به علم داده قصد فتح آن را دارند. ما در دیتایاد، نقشه راه یادگیری هوش مصنوعی را به گونهای طراحی کردهایم که شما گامبهگام از مفاهیم پایهای یادگیری ماشین عبور کرده و به پیادهسازی پروژههای واقعی با استفاده از فریمورکهای قدرتمند یادگیری عمیق برسید.

الگوریتمهای جستجو و هوش مصنوعی کلاسیک (Symbolic AI)
بسیاری از افراد تصور میکنند هوش مصنوعی فقط در یادگیری ماشین خلاصه میشود، اما شاخه بزرگی از این علم وجود دارد که بر پایه «جستجوی هوشمندانه» و «منطق استنتاجی» بنا شده است. این الگوریتمها که به هوش مصنوعی نمادین معروف هستند، در مسائلی که دارای قوانین مشخص و فضای حالت گستردهای هستند (مانند بازی شطرنج یا مسیریابی جیپیاس)، بیرقیب عمل میکنند.
۱. الگوریتمهای جستجوی آگاهانه و ناآگاهانه
در این دسته، هدف پیدا کردن بهترین مسیر از یک نقطه شروع به یک هدف مشخص است.
- جستجوی اول سطح (BFS) و اول عمق (DFS): اینها روشهای پایهای هستند که بدون داشتن اطلاعات اضافی، کل فضای مسئله را برای یافتن پاسخ جستجو میکنند.
الگوریتم A (A-Star)*: یکی از هوشمندانهترین الگوریتمهای مسیریابی است. A* با استفاده از توابع هزینه و تخمین (Heuristics)، کوتاهترین و بهینهترین مسیر را پیدا میکند. این الگوریتم قلب تپنده اکثر بازیهای ویدیویی و سیستمهای نقشه آنلاین است.
۲. سیستمهای خبره (Expert Systems)
سیستمهای خبره به جای یادگیری، از دانشِ ثبت شده متخصصان انسانی استفاده میکنند. با استفاده از مجموعهای از قوانین منطقی (اگر-آنگاه)، این الگوریتمها میتوانند در حوزههای خاصی مثل تشخیص بیماریهای خاص یا تحلیلهای حقوقی، مانند یک متخصص انسانی نظر بدهند.
۳. الگوریتمهای بازی (Minimax)
آیا تا به حال فکر کردهاید که کامپیوتر چگونه در بازیهایی مثل دوز یا شطرنج برنده میشود؟ الگوریتم Minimax با تحلیل تمام حرکات ممکن خود و حریف در چندین مرحله آینده، حرکتی را انتخاب میکند که احتمال پیروزی را بیشینه و احتمال شکست را کمینه کند.
چرا هوش مصنوعی کلاسیک هنوز مهم است؟
در حالی که یادگیری عمیق در تشخیص الگوها عالی است، اما اغلب نمیتواند توضیح دهد که «چرا» به یک نتیجه خاص رسیده است. در مقابل، الگوریتمهای کلاسیک کاملاً منطقپذیر و شفاف هستند. امروزه در بسیاری از پروژههای پیشرفته علم داده، از ترکیب این دو رویکرد (هوش مصنوعی هیبریدی) برای رسیدن به دقت و قابلیت اطمینان بالاتر استفاده میشود.
درک این الگوریتمها به شما کمک میکند تا دید بازتری نسبت به حل مسئله داشته باشید. در واقع، اینجاست که متوجه میشویم هر مسئلهای نیاز به شبکههای عصبی سنگین ندارد و گاهی یک الگوریتم جستجوی بهینه، راهکاری بسیار سریعتر و ارزانتر ارائه میدهد.

الگوریتم های بهینهسازی؛ منطق پنهان پشت یادگیری
تا اینجا درباره چگونگی یادگیری و ساختار مدلها صحبت کردیم، اما یک سوال اساسی باقی میماند: یک الگوریتم هوش مصنوعی چگونه متوجه میشود که در حال اشتباه کردن است و چطور خودش را اصلاح میکند؟ پاسخ این سوال در الگوریتمهای بهینهسازی نهفته است.
در واقع، یادگیری در هوش مصنوعی چیزی نیست جز تلاش برای کمینه کردن «خطا». بهینهسازی، فرآیندی است که در آن الگوریتم با تغییر پارامترهای داخلی خود، سعی میکند بهترین پاسخ ممکن را برای یک مسئله پیدا کند.
۱. گرادیان کاهشی (Gradient Descent)؛ قلب تپنده یادگیری ماشین
تقریباً تمام مدلهای یادگیری ماشین و یادگیری عمیق از این روش برای یادگیری استفاده میکنند. تصور کنید در بالای یک کوه مهآلود هستید و میخواهید به پایینترین نقطه (کمترین میزان خطا) برسید. گرادیان کاهشی به شما میگوید که در هر قدم، در کدام جهت حرکت کنید تا سریعتر به پایین برسید. این الگوریتم با تنظیم مداوم وزنها در شبکههای عصبی، دقت مدل را افزایش میدهد.
۲. الگوریتمهای فراابتکاری (Metaheuristic) و تکاملی
گاهی اوقات فضای مسئله به قدری پیچیده و وسیع است که روشهای سنتی مانند گرادیان کاهشی در آن کارایی ندارند. در اینجاست که ما از طبیعت الهام میگیریم:
- الگوریتم ژنتیک (Genetic Algorithm): این الگوریتم با الهام از تئوری تکامل داروین، مجموعهای از پاسخهای احتمالی را ایجاد کرده و با ترکیب و جهش آنها، در نهایت به «بهترین پاسخ» میرسد.
- بهینهسازی کلونی مورچگان (ACO): با الهام از رفتار مورچهها در پیدا کردن کوتاهترین مسیر به غذا، برای حل مسائل پیچیده مسیریابی و لجستیک استفاده میشود.
- الگوریتم تجمع ذرات (PSO): که از حرکت دستهجمعی پرندگان یا ماهیها الگوبرداری شده است.
چگونه الگوریتم مناسب را انتخاب کنیم؟ (راهنمای تصمیمگیری)
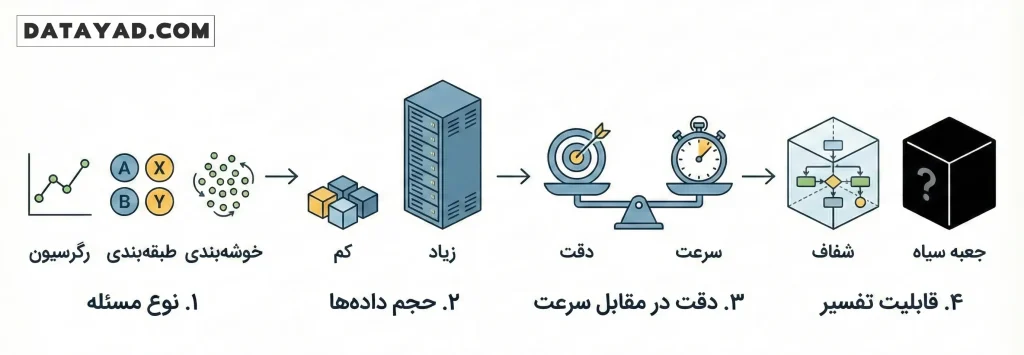
با وجود تنوع گسترده در الگوریتم های هوش مصنوعی، انتخاب یک گزینه از میان دهها مدل موجود در یادگیری ماشین و یادگیری عمیق میتواند چالشبرانگیز باشد. هیچ الگوریتمی وجود ندارد که برای همه مسائل بهترین باشد (قانون No Free Lunch). برای انتخاب آگاهانه، باید به چند فاکتور کلیدی توجه کنید:
۱. نوع مسئله و هدف نهایی
اولین قدم این است که بدانید به دنبال چه چیزی هستید:
- اگر به دنبال پیشبینی یک مقدار عددی هستید، سراغ الگوریتمهای رگرسیون بروید.
- اگر قصد دارید دادهها را در دستههای مشخص طبقهبندی کنید (مثلاً تشخیص مشتریان وفادار از غیروفادار)، الگوریتمهای طبقهبندی مثل SVM یا درخت تصمیم بهترین گزینهاند.
- برای پیدا کردن ساختارهای پنهان در دادههایی که برچسب ندارند، از روشهای خوشهبندی (Clustering) استفاده کنید.
۲. حجم و کیفیت دادهها
میزان دادهای که در اختیار دارید، نقش تعیینکنندهای دارد.
- برای مجموعهدادههای کوچک، الگوریتمهای سادهتر مانند نایو بیز یا رگرسیون خطی معمولاً عملکرد بهتری دارند و دچار بیشبرازش (Overfitting) نمیشوند.
اگر با میلیونها رکورد داده، تصویر یا صوت سر و کار دارید، حتماً باید به سراغ مدلهای یادگیری عمیق و شبکههای عصبی بروید.
۳. دقت در مقابل سرعت (Trade-off)
در دنیای واقعی، همیشه زمان و منابع محاسباتی محدود است.
- برخی الگوریتمها مثل KNN در هنگام پیشبینی بسیار کند عمل میکنند.
- در مقابل، الگوریتمهایی مثل جنگل تصادفی (Random Forest) ممکن است زمان آموزش طولانیتری داشته باشند اما سرعت پیشبینی آنها بسیار بالاست. برای سیستمهای بلادرنگ (Real-time)، سرعت اجرا بر دقتِ اندکی بالاتر اولویت دارد.
۴. قابلیت تفسیر (Explainability)
در برخی صنایع مثل پزشکی یا بانکداری، فقط رسیدن به جواب کافی نیست؛ شما باید بدانید «چرا» الگوریتم این تصمیم را گرفته است.
- الگوریتمهایی مثل درخت تصمیم کاملاً شفاف هستند و مسیر تصمیمگیری آنها قابل ردیابی است.
- در مقابل، مدلهای یادگیری عمیق شبیه به یک «جعبه سیاه» عمل میکنند که تحلیل منطق درونی آنها بسیار دشوار است.
آینده الگوریتم های هوش مصنوعی و مسیر پیش رو
دنیای الگوریتم های هوش مصنوعی با سرعتی غیرقابل تصور در حال تغییر است. آنچه امروز به عنوان تکنولوژی پیشرو میشناسیم، ممکن است در چند سال آینده تنها یک پایه برای نوآوریهای بزرگتر باشد. اما چه روندهایی آینده این حوزه را شکل میدهند؟
۱. هوش مصنوعی مولد (Generative AI) و ترنسفورمرها
انقلابی که با مدلهای زبانی بزرگ (LLM) شروع شد، تنها نوک کوه یخ است. آینده متعلق به الگوریتمهایی است که نه تنها دادهها را تحلیل میکنند، بلکه قادر به خلق محتوای جدید (متن، تصویر، کد و حتی ساختارهای پروتئینی) هستند. توسعه معماریهای پیشرفتهتر در یادگیری عمیق، مرزهای خلاقیت ماشین را جابهجا خواهد کرد.
۲. هوش مصنوعی قابل تفسیر (XAI)
همانطور که در بخشهای قبلی اشاره کردیم، یکی از چالشهای مدلهای پیچیده، «جعبه سیاه» بودن آنهاست. در آینده، تمرکز ویژهای بر روی الگوریتمهایی خواهد بود که میتوانند تصمیمات خود را برای انسان توضیح دهند. این موضوع به ویژه در حوزههای حساس مثل پزشکی و قضاوتهای حقوقی اهمیت حیاتی دارد.
۳. هوش مصنوعی سبز و بهینهسازی مصرف انرژی
آموزش مدلهای بزرگ یادگیری ماشین به توان پردازشی و انرژی بسیار زیادی نیاز دارد. نسل بعدی الگوریتمها به گونهای طراحی خواهند شد که با مصرف انرژی کمتر و روی سختافزارهای ضعیفتر (مثل گوشیهای موبایل)، همان کارایی مدلهای عظیم را داشته باشند. در اینجا باز هم نقش الگوریتمهای بهینهسازی برای رسیدن به بهرهوری حداکثری، پررنگتر از همیشه خواهد بود.
جمعبندی: نقشه راه شما برای تسلط بر الگوریتمها
مسیر تبدیل شدن به یک متخصص در حوزه علم داده، از درک همین الگوریتمها میگذرد. فرقی نمیکند که به دنبال پیادهسازی یک رگرسیون ساده باشید یا طراحی یک شبکه عصبی عمیق؛ نکته کلیدی این است که بدانید هر الگوریتم، ابزاری برای حل یک چالش خاص است. و تسلط بر آنها تنها با یک برنامه اموزش هوش مصنوعی اصولی و پروژهمحور امکانپذیر خواهد بود.



















