

در جلسه نهم از آموزش رایگان شبکه عصبی می خواهیم ادامه بحث Optimizer در شبکه عصبی را پیش ببریم و موضوعات جدیدی را مورد بررسی قرار دهیم.
تاثیر نرخ یادگیری (learning rate) و نرخ یادگیری بهینه
یکی از عوامل اثرگذار بر یادگیری شبکه عصبی در بحث بهینه سازی، نرخ یادگیری (learning rate) است. مقدار این کمیت باید به اندازه کافی بزرگ و به اندازه کافی کوچک باشد.
انتخاب مقادیر خیلی کوچک و یا خیلی بزرگ، هر کدام مشکلاتی برای شبکه ایجاد می کند. در شکل زیر نمودار loss بر حسب ایپاک برای حالت های مختلف نرخ یادگیری نشان داده شده است.
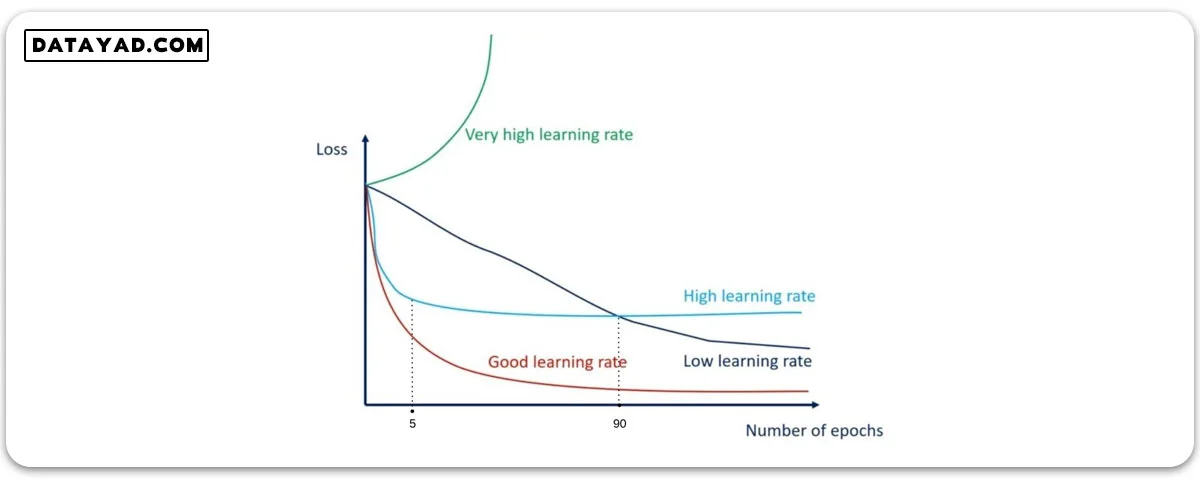
همان طور که در شکل می بینیم، در حالتی که نرخ یادگیری بالا باشد (نمودار آبی روشن) خیلی سریع به یک نقطه بهینه می رسیم و از آن به بعد آموزش متوقف می شود.
همچنین نرخ یادگیری پایین (نمودار آبی تیره) باعث می شود یادگیری با سرعت خیلی کمی انجام شود و همان طور که می بینیم در این حالت در ایپاک ۹۰ شبکه به میزان ضرری دست یافته که با نرخ یادگیری بالا بعد از ۵ ایپاک به آن رسیده بود.
اگر نرخ یادگیری خیلی خیلی زیاد باشد، اصلا یادگیری صورت نمی گیرد و نمودار سبز رنگ را خواهیم داشت.
تغییر نرخ یادگیری در حین آموزش شبکه
با در نظر گرفتن نمودار فوق به نظر می رسد حالت ایده آل برای تعیین میزان نرخ یادگیری از ترکیب دو حالت نرخ یادگیری بالا و پایین بدست آید. اگر در ابتدا نرخ یادگیری را بالا در نظر گرفته و به تدریج آن را کم کنیم، می توانیم تا ایپاک های بالاتری همچنان یادگیری را در شبکه داشته باشیم.
برای درک بهتر این موضوع نمودار زیر را در نظر بگیرید. اگر مقدار نرخ یادگیری بزرگ باشد، گام های هر پرش روی نمودار زیر به همان نسبت بزرگ خواهد بود.
با وجود اینکه این حالت باعث می شود با تعداد قدم های کمتری (تعداد ایپاک کمتر) به نقطه بهینه نزدیک شویم، اما این عیب را هم دارد که به دلیل بلند بودن گام ها، از یک حدی بیشتر نمی توانیم به نقطه بهینه نزدیک شویم.
در نتیجه افزایش میزان ایپاک ها تاثیری در یادگیری بهتر نخواهد داشت و عملا loss با فاصله ای حول نقطه بهینه نوسان می کند. این گام ها که متناظر با نرخ یادگیری بالا هستند، با فلش های قرمز رنگ روی شکل نشان داده شده اند.
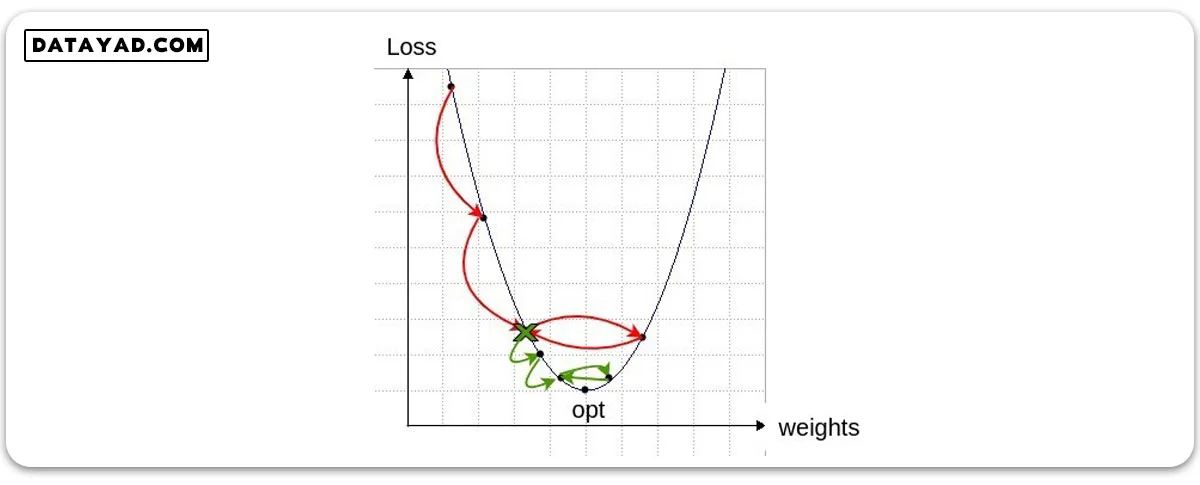
برای اینکه شبکه بتواند از این نقطه به بعد هم آموزش دیده و باز هم به نقطه بهینه نزدیک تر شود، باید برای ایپاک های بعدی گام ها را کوچک تر کنیم. این نقطه و گام های کوچک تر پس از آن با رنگ سبز در شکل بالا نشان داده شده اند.
با این نرخ یادگیری جدید باز هم تا حدی به نقطه بهینه نزدیک می شویم. اما مجددا به فاصله ای از این نقطه می رسیم که این میزان گام جدید نیز برای نزدیک تر شدن به نقطه بهینه خیلی بزرگ بوده و مجددا حول نقطه بهینه نوسان می کنیم. در این نقطه می توانیم یک مرحله دیگر نرخ یادگیری را کاهش دهیم.
بدین ترتیب با نرخ یادگیری متغیر می توانیم بهتر مسأله را پیش ببریم.
الگوریتم های بهینه سازی متناسب با نرخ یادگیری داینامیک
در جلسات گذشته الگوریتم هایی را برای بهینه سازی وزن ها و بایاس ها در شبکه عصبی معرفی کردیم. اما در تمامی این الگوریتم ها نرخ یادگیری ثابت بود. برای اینکه بتوانیم نرخ یادگیری متغیر در مسأله داشته باشیم، نیازمند الگوریتم های جدیدی برای بهینه سازی هستیم.
در نمودار ابتدای این جلسه، منحنی قرمز رنگ، حالت بهینه را نشان می دهد. یعنی حالتی در زمان کمتر به دقت های بهتری می رسیم. این موضوع اهمیت زیادی دارد، زیرا آموزش شبکه عصبی فرایند بسیار هزینه بر و زمان بریست. در نتیجه از هر روشی که بتواند ما را کمی زودتر به نقطه بهینه نزدیک کند استقبال می کنیم.
راه حل نرخ یادگیری داینامیک باید به صورتی باشد که در ابتدا با سرعت زیاد ما را به نقطه بهینه نزدیک کند و سپس با کوچک تر کردن گام ها، به نزدیک تر شدن به این نقطه کمک کند. این نرخ یادگیری متغیر سپس در رابطه زیر قرار گرفته و وزن ها و بایاس های هر مرحله را برای ما آپدیت می کند:
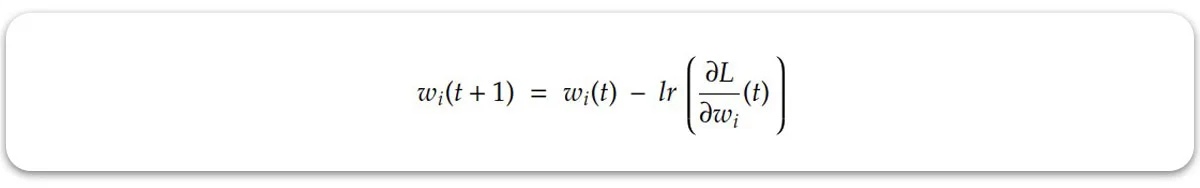
یک راه حل می تواند این باشد که به صورت دستی رابطه ای برای نرخ یادگیری در نظر بگیریم که در هر ایپاک نرخ یادگیری را برای ما کاهش دهد. اصطلاحا به این رابطه learning rate schedule می گویند.
به عنوان مثال می توانیم رابطه نرخ یادگیری را به صورت نمایی زیر در نظر بگیریم:
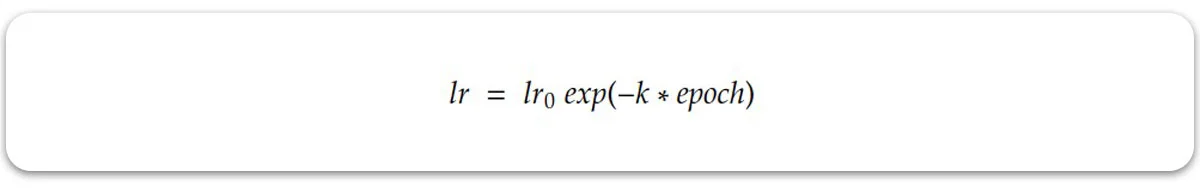
در رابطه فوق k هایپرپارامتری است که تعیین می کند میزان کاهش lr با چه نرخی انجام شود. ایرادی که این رابطه دارد اینست که خیلی سریع نرخ یادگیری را کاهش می دهد.
در صورتی که همان طور که در شکل های فوق برای رابطه loss با weight مشاهده می شود، گاهی نیاز داریم تا نرخ یادگیری را ثابت نگه داریم و یا به مرور و متناسب با شرایط میزان آن را کاهش دهیم. برای حل این مسأله روش های دیگری پیشنهاد شد که پویایی راه حل را باز هم بیشتر می کند.
الگوریتم AdaGrad (Adaptive Gradient)
این روش نرخ یادگیری را با توجه به میزان گرادیان تغییر می دهد. به این ترتیب که اگر گرادیان زیاد باشد، نرخ یادگیری را بالا نگه می دارد. زیرا همانطور که در شکل زیر مشخص است، زیاد بودن میزان گرادیان (شیب خط مماس) به این معناست که از نقطه بهینه دور هستیم. با نزدیک شدن به نقطه بهینه، شیب خط مماس کم کم کاهش می یابد.
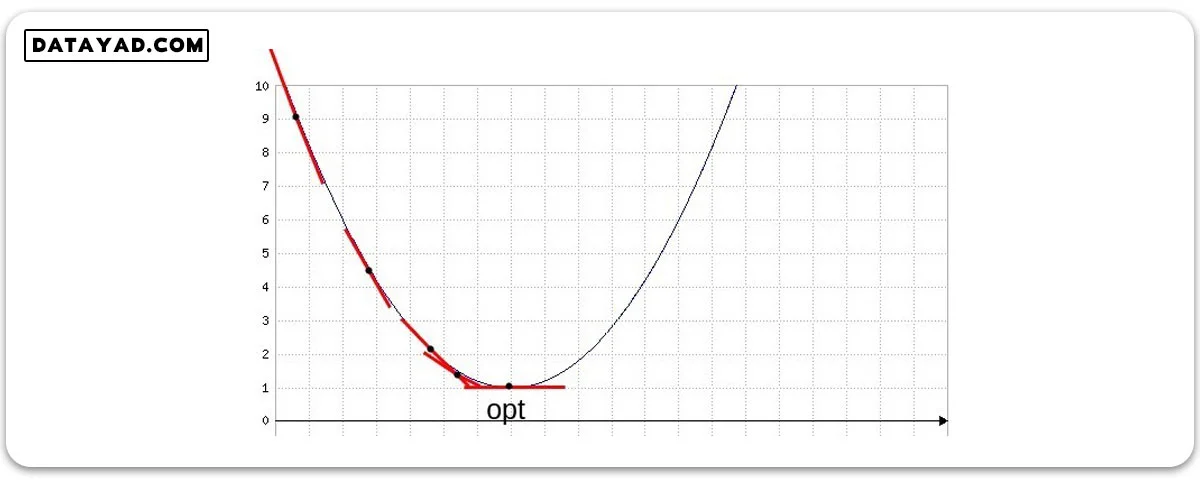
بدن ترتیب الگوریتم AdaGrad با نزدیک شدن به نقطه بهینه نرخ یادگیری را به تدریج کم می کند. در این الگوریتم نرخ یادگیری به این صورت تعریف می شود:
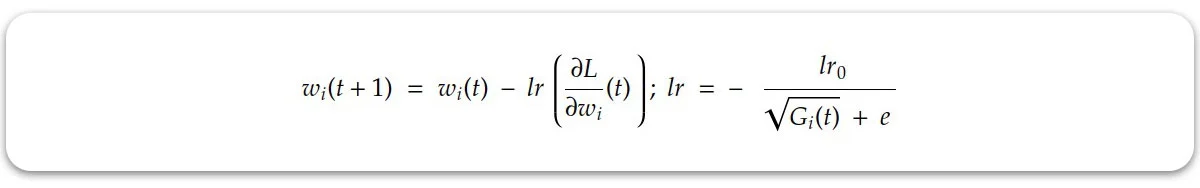
در این رابطه اپسیلون عدد کوچکیست که از صفر شدن مخرج و ایجاد خطا جلوگیری می کند. lr0 میزان نرخ یادگیری اولیه بوده و ثابت است. اما Gi همان عبارتیست که به این رابطه پویایی می بخشد. مقدار این عبارت برابرست با:

در نتیجه در الگوریتم AdaGrad، گرادیان به صورت مستقیم در تعیین میزان نرخ یادگیری تاثیر می گذارد.
الگوریتم (Root Mean Squared Propagation) RMSProp
این الگوریتم مشابه AdaGrad بوده و تفاوت آن در رابطه آپدیت گرادیان است. در این الگوریتم، گرادیان با رابطه زیر آپدیت می شود:
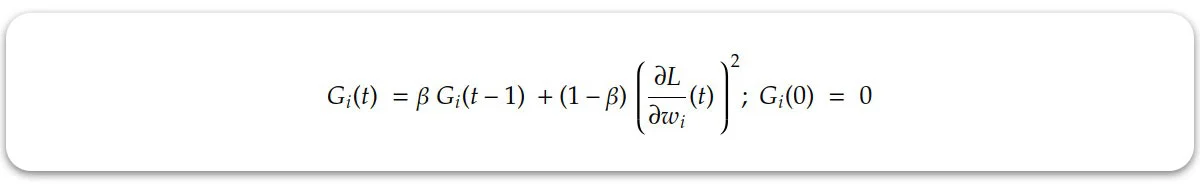
تجربه نشان می دهد آپدیت نرخ یادگیری در این حالت موثرتر از حالت قبل اتفاق می افتد.
الگوریتم های AdaGrad و RMSProp الگوریتم های قدرتمندی هستند که نرخ یادگیری را هوشمندانه تغییر می دهند. همچنین از مهم ترین دستاوردهای این دو الگوریتم، اینست که برای هر المان وزن متناسب با همان المان آپدیت انجام می شود (per weight هستند).
این بدین معناست که هر کدام از وزن های موجود در شبکه، بر اساس تابع گرادیان خود قدم هایشان را تعیین می کنند. این موضوع اهمیت زیادی دارد، زیرا وزن های مختلف به طور همزمان به نقطه بهینه نمی رسند. اما در این الگوریتم ها همان طور که می بینیم در رابطه آپدیت وزن فوق، تکانه وارد نشده است.
الگوریتم (Adaptive moment estimation) Adam
در سال های بعد الگوریتم قدرتمند دیگری با تلفیق ایده های تکانه (moment) و تغییر نرخ یادگیری بر اساس گرادیان متولد شد که Adam نام گرفت. در این الگوریتم، اثر تکانه به رابطه RMSProp اضافه می شود.

بدین ترتیب پس از اعمال پاره ای تبدیلات، رابطه آپدیت وزن ها در الگوریتم Adam به شکل زیر در می آید:
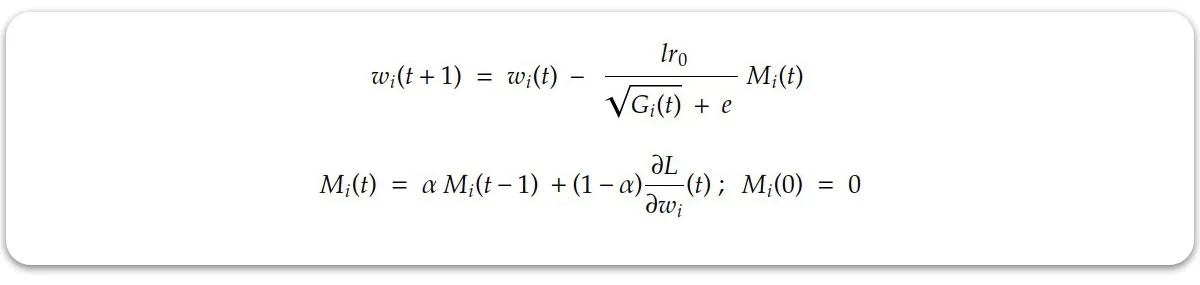
این الگوریتم سرعت و بازدهی مطلوبی داشته و در حال حاضر بهترین عملکرد را در بین الگوریتم های معرفی شده دارد.





















6 پاسخ
سلام.
ممنون از توضیحات خوبتون.
لطفا در مورد AdamW هم توضیح بدید و فرقش رو با Adam بیان بفرمایید.
پیشاپیش ممنونم.
سلام و ارادت
تفاوت اصلی Adam و AdamW در بخش مدیریت کاهش وزن هست که در AdamW سعی شده عملکرد نرخ بهینه سازی رو بهبود بدن.
با سلام و تشکر بابت پاسخگوییتون.
بله، میخوام اگه امکانش هست همین مدیریت وزن و عملکرد نرخ بهینهسازی بهبودیافته رو دقیقتر توضیح بدید.
حتی اگه امکانش هست، در ادامه همین آموزشتون اضافه بفرمایید.
پیشاپیش سپاسگزارم.
خواهش میکنم،
این بخش از دوره به پایان رسیده و درحال حاضر برنامه ای برای پوشش مباحث تکمیلی تر رو نداریم.
سلام دوره ی رایگان مفیدی بود بخوص که گفتید هر نورون در واقع همون معادله خط هست که با یک اکتیویشن فانکشن ترکیب شده ، از این که علمتون رو با ما به اشتراک گذاشتید سپاس گذارم، امیدوارم همواره شاد و سلامت باشید پس من میرم بقیه سوالامو از هوش مصنوعی بپرسم خداحافظ
سلام، تشکر از لطف و محبت شما.
خوشحالم که مطالب این دوره برای شما مفید بود.
اگر دانش کافی درمورد مساله ای ندارید، بهتره صرفا با پرسیدن از هوش مصنوعی رفع اشکال نکنید، برای خودم بارها پیش اومده به مساله ای تسلط داشتم و برای فهم یک نکته تکمیلی از این ابزارها کمک گرفتم و متوجه شدم خطای این مدلها کم نیست و نمیشه کامل به پاسخ هایی که میدن اعتماد کرد.
موفق باشید