

کلان داده (Big Data) و هوش مصنوعی دو رکن جداییناپذیر در دنیای مدرن فناوری هستند که به ترتیب نقش سوخت و موتور محرک را ایفا میکنند. هوش مصنوعی برای یادگیری الگوها و اتخاذ تصمیمات دقیق، به حجم عظیمی از دادههای باکیفیت نیاز دارد؛ در حالی که کلان داده بدون ابزارهای هوشمند برای تحلیل، تنها مجموعهای بیپایان از اعداد و ارقام بدون استفاده باقی میماند. این همگرایی باعث شده است تا سیستمهای نرمافزاری از حالت قاعدهمحور خارج شده و به سمت یادگیری خودکار حرکت کنند.
درک نقش بیگ دیتا یا همان کلان داده در هوش مصنوعی برای دانشجویان و دیتاساینتیست ها اهمیت حیاتی دارد، زیرا تمامی نوآوریهای اخیر از تشخیص چهره گرفته تا خودروهای خودران، بر پایه پردازش دادههای انبوه استوار شدهاند. در این مطلب از بخش آموزش هوش مصنوعی، مسیر حرکت از دادههای خام به سمت مدلهای پیشرفته هوش مصنوعی را بررسی میکنیم و نشان میدهیم که چگونه این پیوند، استانداردهای جدیدی را در صنایع مختلف تعریف کرده و آینده شغلی برنامهنویسان و تحلیلگران را تغییر داده است.
ویژگیهای بنیادی کلان داده در هوش مصنوعی
الگوریتمهای هوش مصنوعی برای یادگیری الگوهای پیچیده به بستری از کلان داده نیاز دارند که فراتر از سیستم های ذخیره سازی معمولی است. این بستر با پنج ویژگی اصلی تعریف میشود که کیفیت و کارایی مدل های هوشمند را در پردازش اطلاعات تعیین میکند.
- حجم (Volume): هوش مصنوعی به تودههای عظیمی از اطلاعات نیاز دارد تا بتواند روابط میان پدیدهها را کشف کند. این حجم زیاد باعث میشود مدل های یادگیری ماشین با دقت بیشتری آموزش ببینند و نتایج بهتری ارائه دهند.
- سرعت (Velocity): دادهها در سیستم های هوشمند با سرعت بسیار بالایی تولید و جمعآوری میشوند. توانایی پردازش این اطلاعات در کمترین زمان ممکن، تفاوت اصلی یک سیستم هوشمند کارآمد با مدل های معمولی است.
- تنوع (Variety): بیگ دیتا شامل انواع مختلفی از فرمتها مثل متن، صدا، تصویر و ویدیو است. هوش مصنوعی با تحلیل این داده های غیرساختارمند، میتواند درک بهتری از محیط پیرامون پیدا کند و مسائل پیچیده را حل کند.
- صحت (Veracity): دقت و قابل اعتماد بودن اطلاعات ورودی برای خروجی هوش مصنوعی اهمیت زیادی دارد. داده های باکیفیت و بدون نویز، باعث میشوند پیشبینی های الگوریتم به واقعیت نزدیکتر باشد و خطاهای سیستم کاهش یابد.
- ارزش (Value): هدف نهایی از پردازش دادهها، رسیدن به یک نتیجه ی سودمند برای کسب و کار است. این ویژگی باعث میشود تا هوش مصنوعی به جای تحلیل های بیهوده، روی اطلاعاتی تمرکز کند که باعث بهبود تصمیمگیری و افزایش بهرهوری میشود.
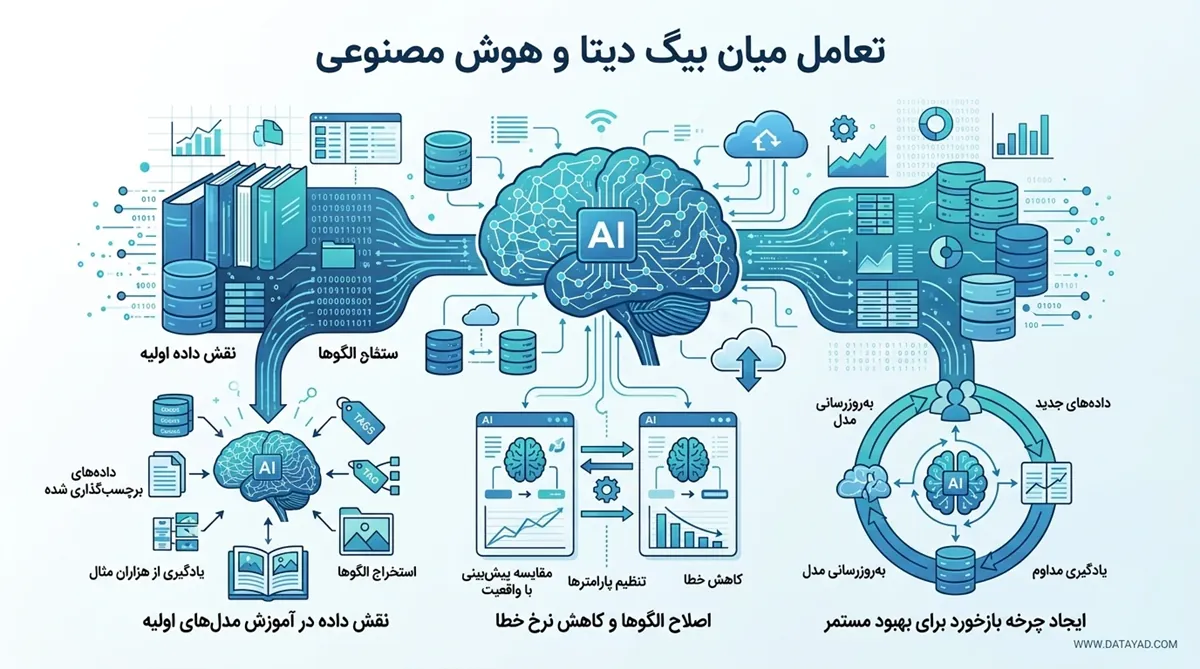
تعامل میان بیگ دیتا و هوش مصنوعی
الگوریتمهای هوش مصنوعی با تحلیل دادههای خام، الگوهای نهفته در آنها را کشف میکنند. این فرآیند به مدل اجازه میدهد تا از یک ماشین ساده به یک سیستم تصمیمگیرنده تبدیل شود. در واقع، کیفیت و مقدار اطلاعات ورودی مستقیما بر دقت خروجیهای نهایی تاثیر میگذارد.
نقش داده در آموزش مدلهای اولیه
در شروع کار، دادهها به عنوان کتاب درسی برای الگوریتم عمل میکنند. سیستم با مشاهده ی هزاران مثال مختلف، ویژگیهای مشترک و تفاوتها را یاد میگیرد. برای مثال، الگوریتم باید حجم زیادی از اطلاعات برچسبگذاری شده را ببیند تا بفهمد هر دسته بندی چه ویژگیهایی دارد. این مرحله ی یادگیری، پایه ی اصلی تمام پیشبینیهای بعدی سیستم است.
اصلاح الگوها و کاهش نرخ خطا
هیچ مدلی در اولین مرحله ی یادگیری کامل نیست و معمولا با اشتباهات زیادی روبرو میشود. با مقایسه ی پیشبینیهای مدل با نتایج واقعی، میزان خطاها شناسایی میشود. الگوریتم از این خطاها درس میگیرد و پارامترهای ریاضی خود را دوباره تنظیم میکند. این تکرار مداوم باعث میشود تا سیستم به مرور زمان پاسخهای دقیقتری ارائه دهد و اشتباهاتش به حداقل برسد.
ایجاد چرخه بازخورد برای بهبود مستمر
همکاری میان داده و الگوریتم در محیطهای عملیاتی هم ادامه مییابد و هرگز متوقف نمیشود. هر بار که سیستم با اطلاعات جدیدی روبرو میشود، نتایج حاصل از آن دوباره به مدل برمیگردد. این چرخه ی بازخورد به مدل کمک میکند تا با تغییرات محیطی یا رفتارهای جدید کاربران هماهنگ شود. به این ترتیب، سیستم هوشمند با گذشت زمان تجربهی بیشتری کسب میکند و همیشه بهروز باقی میماند.
مقایسه زیرساختهای ذخیرهسازی و پردازش
سیستمهای مدرن داده، وظایف نگهداری اطلاعات را از بخش محاسبات جدا کردهاند تا سرعت و هزینه بهتر مدیریت شود. این جداسازی اجازه میدهد دادهها در مخازن بزرگ باقی بمانند و فقط هنگام نیاز، توسط موتورهای پردازشی برای انجام عملیاتهای پیچیده فراخوانی شوند.
| ویژگی | زیرساخت ذخیرهسازی (Storage) | زیرساخت پردازشی (Processing) |
|---|---|---|
| هدف اصلی | نگهداری امن و پایدار حجم عظیمی از دادهها | اجرای محاسبات، تحلیل و استخراج نتیجه از داده |
| ابزارهای نمونه | اسنوفلیک، گوگل بیگکوئری، انبار داده ابری | آپاچی اسپارک، آپاچی فلینک |
| نحوه عملکرد | دادهها را به صورت ساختارمند یا خام در خود جای میدهد | داده را از مخزن میگیرد و با الگوریتمها تغییر میدهد |
| تمرکز فنی | پایداری فایلها و دسترسی راحت به اطلاعات | سرعت محاسبات و استفاده بهینه از حافظه موقت |
| خروجی نهایی | بایگانی منظم از سوابق و تعاملات | گزارشهای تحلیلی و مدلهای آماده برای پیشبینی |
انتخاب ابزار مناسب در هر بخش به این بستگی دارد که حجم دادههای شما چقدر است و با چه سرعتی به پاسخ نیاز دارید. ترکیب درست این دو زیرساخت باعث میشود سیستمهای هوشمند بدون اتلاف وقت و با هزینه کمتر، بیشترین بازدهی را از اطلاعات موجود به دست آورند.
مراحل توسعه یک سیستم دادهمحور
ساخت یک سیستم دادهمحور شامل یک چرخه منظم است که اطلاعات خام را به گزارشهای کاربردی تبدیل میکند. این مسیر از تعیین اهداف دقیق شروع شده و با آموزش مدلها و ایجاد یک چرخه یادگیری دائمی به پایان میرسد.
- مشخص کردن اهداف و نیازها: در اولین قدم باید بدانید که این سیستم قرار است چه مشکلی را حل کند. برای مثال، هدف ممکن است پیشبینی زمان خرابی دستگاهها در یک کارخانه یا پیشنهاد محصولات مرتبط به مشتریان یک فروشگاه باشد.
- جمعآوری و ذخیره اطلاعات: دادهها از منابع مختلفی مثل رفتار کاربران در اپلیکیشن، تراکنشهای مالی یا سنسورهای هوشمند جمع میشوند. این اطلاعات در فضاهای ابری ذخیره میشوند تا تیمهای مختلف به راحتی به آنها دسترسی داشته باشند.
- آموزش و پیادهسازی مدلهای هوشمند: متخصصان با استفاده از دادههای جمعآوری شده به مدلها یاد میدهند که الگوها را شناسایی کنند. در این مرحله مدل آنقدر تمرین میکند تا بتواند تفاوت بین اطلاعات مهم و نویزهای اضافی را بفهمد.
- تولید بینش و خروجیهای قابل فهم: پس از آموزش، سیستم میتواند به سوالات پاسخ دهد یا نمودارهای سادهای از وضعیت کسبوکار ارائه کند. این بخش به مدیران کمک میکند تا بدون درگیر شدن با پیچیدگیهای فنی، بر اساس واقعیتها تصمیم بگیرند.
- بهبود مستمر و چرخه بازخورد: سیستم با دریافت دادههای جدید، به طور مداوم خودش را اصلاح میکند. هر چقدر اطلاعات بیشتری وارد چرخه شود، مدلها با گذشت زمان دقیقتر میشوند و اشتباهات کمتری انجام میدهند.
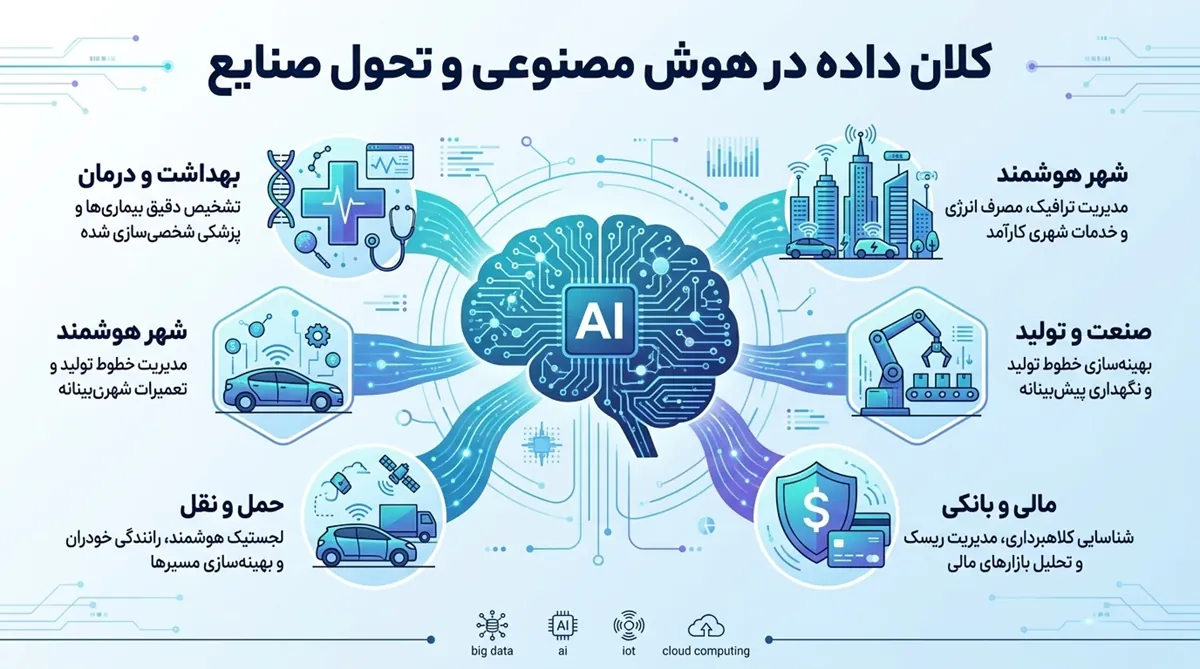
کلان داده در هوش مصنوعی و تحول صنایع
شرکتهای پیشرو دادههای خام را به ابزارهای تصمیمگیر تبدیل میکنند تا هزینههای عملیاتی را کاهش و سرعت خروجی کار را افزایش دهند. این فرآیند باعث میشود مدیران به جای تکیه بر حدس و گمان، بر اساس الگوهای واقعی موجود در بازار تصمیم بگیرند. هر صنعت با توجه به نوع دادههایی که در اختیار دارد، روش متفاوتی برای بهرهگیری از این قدرت پیدا کرده است.
پیشبینی و تشخیصهای دقیق پزشکی
بیمارستانها با تحلیل پروندههای پزشکی و نتایج آزمایشها، بیماریها را پیش از بروز علائم جدی تشخیص میدهند. ابزارهای هوشمند میتوانند وخامت حال بیمار را چند ساعت زودتر از وقوع بحران پیشبینی کنند تا کادر درمان سریعتر وارد عمل شوند. این سیستمها با بررسی عکسهای رادیولوژی و نتایج ژنتیک، دقیقترین مسیر درمان را برای هر فرد به صورت اختصاصی پیشنهاد میدهند.
امنیت و کشف تقلب در بازارهای مالی
بانکها با پردازش لحظهای میلیونها تراکنش، الگوهای مشکوک را در کسری از ثانیه شناسایی میکنند. اگر رفتار خرید یک مشتری با سوابق قبلی او همخوانی نداشته باشد، سیستم به صورت خودکار عملیات را متوقف میکند. علاوه بر امنیت، هوش مصنوعی با تحلیل رفتارهای مالی و سوابق آنلاین، رتبه اعتباری دقیقتری برای پرداخت وام به مشتریان تعیین میکند.
شخصیسازی تجربه مشتری در خردهفروشی
فروشگاههای بزرگ بر اساس سوابق خرید و جستوجوی کاربران، کالاهای مورد علاقه آنها را در زمان مناسب پیشنهاد میدهند. این کار باعث میشود هر فرد دقیقا چیزی را ببیند که به آن نیاز دارد و رضایت مشتری افزایش یابد. الگوریتمها همچنین با پیشبینی میزان تقاضا در روزهای آینده، از اتمام موجودی کالا در انبار یا انباشت کالاهای بیاستفاده جلوگیری میکنند.
چالشهای اخلاقی و فنی در مسیر رشد
استفاده از سیستمهای مبتنی بر داده و هوش مصنوعی با موانع متعددی روبرو است که میتواند روند پیشرفت را کند کند. این مشکلات معمولا در دو دسته کلی زیرساختهای فنی و چالش های اخلاقی قرار میگیرند که هر کدام نیازمند مدیریت دقیق هستند. جدول زیر مهمترین این چالشها و راهکارهای مقابله با آنها را نشان میدهد.
| نوع چالش | شرح کوتاه | راهکار پیشنهادی |
|---|---|---|
| حریم خصوصی و امنیت | خطر نشت اطلاعات شخصی و حساس کاربران در حجم زیاد داده. | استفاده از پروتکلهای رمزنگاری و رعایت استانداردهای قانونی. |
| تعصب الگوریتمی | تولید نتایج ناعادلانه یا تبعیضآمیز به دلیل دادههای آموزشی ناقص. | بررسی دورهای خروجی مدلها توسط ناظران انسانی. |
| یکپارچهسازی فنی | دشواری در اتصال سیستمهای قدیمی به ابزارهای مدرن پردازش داده. | نوسازی زیرساختهای آیتی و استفاده از فضای ابری. |
| کمبود متخصص | نبود نیروی انسانی کافی برای مدیریت و تحلیل دادههای پیچیده. | سرمایهگذاری روی آموزش تیمهای داخلی و ارتقای دانش فنی. |
| عدم شفافیت | دشواری در فهمیدن چگونگی رسیدن هوش مصنوعی به یک تصمیم خاص. | به کارگیری مدلهای هوش مصنوعی قابل توضیح (XAI). |
شناخت این موانع به سازمانها کمک میکند تا قبل از شروع پروژههای بزرگ، زیرساختهای لازم را آماده کنند. نظارت مستمر بر چرخه حیات داده مانع از انحراف مدلها و بروز خطاهای پرهزینه میشود. با مدیریت درست این ریسکها، مسیر بهرهبرداری از قدرت داده هموارتر خواهد شد.
روندهای نوین و افقهای پیشرو
پردازش اطلاعات از مراکز داده بزرگ به سمت لبههای شبکه و دستگاههای مصرفکننده منتقل شده است.
این تغییر باعث میشود تحلیل دادهها در همان محل تولید، یعنی روی گوشیهای موبایل، سنسورهای کارخانه یا خودروها انجام شود. این روش سرعت واکنش سیستمها را بالا میبرد و نیاز به ارسال مداوم حجم زیادی از اطلاعات به سرورهای دوردست را از بین میبرد.
- هوش مصنوعی لبه (Edge AI): در این روند، یادگیری ماشین مستقیماً روی سختافزارهای محلی اجرا میشود. این کار باعث میشود حریم خصوصی کاربران بهتر حفظ شود، چون دادههای خام از دستگاه خارج نمیشوند. همچنین در مکانهایی که دسترسی به اینترنت ضعیف است، سیستم بدون وقفه به کار خود ادامه میدهد.
- هوش مصنوعی عاملمحور (Agentic AI): برخلاف سیستمهای قدیمی که فقط به سوالات پاسخ میدادند، مدلهای جدید مثل یک کارمند مستقل عمل میکنند. این عاملها میتوانند هدف نهایی را دریافت کنند، مراحل انجام کار را خودشان طراحی کنند و ابزارهای مختلف را برای رسیدن به نتیجه به کار بگیرند.
- ظهور شغلهای جدید در حوزه اخلاق و نظارت: با گسترش استفاده از دادهها، نیاز به متخصصانی پیدا شده است که فقط روی عدالت و انصاف الگوریتمها تمرکز کنند. نقشهایی مثل ارزیاب سوگیری داده یا متخصص اخلاق در هوش مصنوعی در حال شکلدهی به ساختار تیمهای فنی هستند تا از بروز تبعیض در نتایج جلوگیری کنند.
- عمومی شدن سواد داده: استفاده از تحلیلهای پیشرفته دیگر مخصوص مهندسان نیست. ابزارهای جدید به کارمندان بخشهای فروش، منابع انسانی و پشتیبانی اجازه میدهند با زبان ساده و گفتاری از دادهها گزارش بگیرند. این موضوع باعث میشود تصمیمگیری بر اساس آمار در تمام لایههای یک سازمان به یک عادت روزمره تبدیل شود.
تمرکز بر شفافیت مدلها باعث شده تا اعتماد کاربران به خروجی سیستمهای خودکار بیشتر شود. وقتی نحوه رسیدن به یک جواب مشخص باشد، مدیران با اطمینان بیشتری بر اساس پیشبینیهای ماشین سرمایهگذاری میکنند.
مسیر ورود به دنیای دادهها و هوش مصنوعی
اکنون که با اهمیت و تعاملات گسترده میان کلانداده و هوش مصنوعی آشنا شدیم، گام بعدی ورود عملی به این حوزه هیجانانگیز است. در ادامه بررسی میکنیم که چرا تسلط بر این مهارتها در دنیای امروز ضروری است و چگونه میتوانیم مسیر یادگیری خود را به شکل اصولی آغاز کنیم.
چرا باید هوش مصنوعی یاد بگیریم؟
همگرایی هوش مصنوعی و کلانداده نشان میدهد که آینده تمامی صنایع در گرو تحلیل هوشمند دادههاست. یادگیری هوش مصنوعی به شما کمک میکند تا از یک ناظرِ صرف، به متخصصی تبدیل شوید که میتواند از دل حجم عظیم و پیچیده دادهها، الگوهای پنهان را کشف کرده و سیستمهای دادهمحور خلق کند. تسلط بر این مهارتها، تضمینکننده جایگاه شغلی شما در عصر انقلاب دادهها و ارزشآفرینی در سازمانها خواهد بود.
از کجا یاد بگیریم؟
ورود به تقاطع جذاب دادهها و هوش مصنوعی نیازمند یک مسیر یادگیری ساختاریافته و اصولی است. برای مدیریت کلاندادهها و تسلط بر ابزارهای آن نظیر برنامهنویسی پایتون، آمار، الگوریتمهای یادگیری ماشین و شبکههای عصبی، به یک نقشه راه عملی نیاز دارید. شما میتوانید این مسیر یکپارچه، پروژهمحور و منطبق بر نیازهای واقعی بازار کار را در نقشه راه یادگیری هوش مصنوعی دنبال کنید تا گامبهگام و از پایه، به یک متخصص آمادهی کار در پروژههای بزرگ دادهمحور تبدیل شوید.




















