

بیگ دیتا به مجموعههای عظیم و پیچیدهای از اطلاعات اطلاق میشود که سیستمهای مدیریت داده سنتی توانایی ذخیرهسازی و پردازش آنها را ندارند. این پدیده که با گسترش اینترنت و فناوریهای متصل ظهور کرده، به سازمانها کمک میکند تا با تحلیل حجم انبوهی از دادههای متنوع، الگوهای پنهان را کشف کرده و تصمیمات هوشمندانهتری اتخاذ کنند.
امروزه بیگ دیتا به عنوان سوخت اصلی تحول دیجیتال شناخته میشود و نقش مستقیمی در توسعه هوش مصنوعی و یادگیری ماشین دارد. درک ابعاد مختلف این مفهوم، از یادگیری علم داده تا ابزارهای تحلیلی، برای دانشجویان ضروری است تا بتوانند دادههای خام را به بینشهای ارزشمند و استراتژیک تبدیل کنند.
تفاوت دادههای سنتی و کلان داده
دادههای سنتی معمولا در قالبهای ساختاریافته و در پایگاههای داده رابطهای مدیریت میشوند، در حالی که بیگ دیتا شامل مجموعههای عظیم و پیچیدهای است که سیستمهای مدیریت داده قدیمی توان ذخیرهسازی و پردازش آنها را ندارند. تفاوت اصلی این دو در حجم، تنوع و سرعت تولید اطلاعات نهفته است که رویکردهای متفاوتی را در تحلیل داده میطلبد.
| ویژگی | دادههای سنتی | کلان داده (بیگ دیتا) |
|---|---|---|
| حجم | معمولا در مقیاس گیگابایت و ترابایت است. | شامل حجمهای بسیار انبوه در مقیاس پتابایت و اگزابایت است. |
| ساختار | اغلب ساختاریافته و دارای طرحواره (Schema) ثابت است. | شامل دادههای غیرساختاریافته و نیمهساختاریافته (متن، تصویر، ویدیو) است. |
| سرعت | تولید دادهها به صورت دستهای و با سرعت پایین انجام میشود. | جریان دادهها بسیار سریع و اغلب به صورت لحظهای (Real-time) است. |
| معماری پردازش | مبتنی بر سیستمهای متمرکز و عمودی است. | مبتنی بر سیستمهای توزیعشده و پردازش موازی است. |
| روش تحلیل | بر تحلیلهای آماری و گزارشگیریهای ساده تمرکز دارد. | از تکنیکهای پیشرفته دیتا ساینس و یادگیری ماشین استفاده میکند. |
هر دانشمند داده برای انتخاب زیرساخت مناسب باید ابتدا ماهیت ورودیهای سازمان را ارزیابی کند. در حالی که ابزارهای سنتی برای پردازش تراکنشهای مالی با ساختار مشخص مناسب هستند، پروژههای حوزه علم داده که با دادههای حسگرها یا شبکههای اجتماعی سروکار دارند، لزوما به ابزارهای تخصصی بیگ دیتا نیاز خواهند داشت.
تسلط بر این تمایزها به دیتا ساینتیست کمک میکند تا استراتژیهای ذخیرهسازی را بهینه کرده و مدلهای پیشبینی دقیقتری طراحی کند. در نهایت، تفاوت اصلی تنها در اندازه نیست، بلکه در توانایی استخراج ارزش از دادههای نامنظم و پرسرعت تعریف میشود.
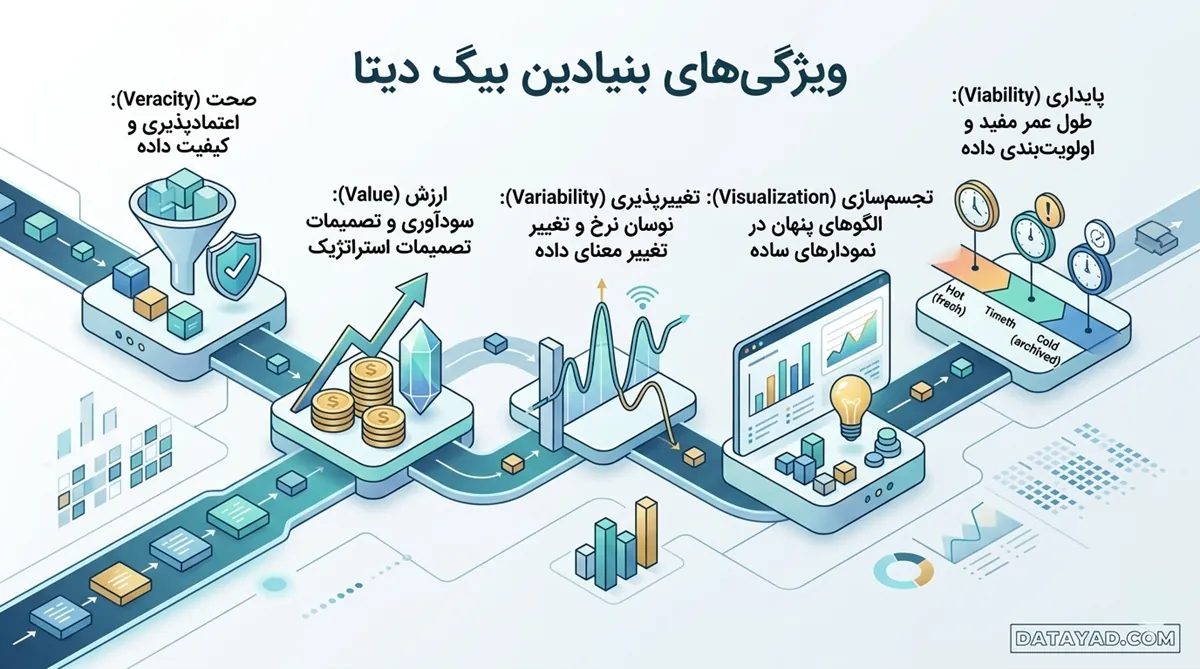
ویژگیهای بنیادین بیگ دیتا
شناسایی ابعاد کیفی در مدیریت کلان داده، مرز بین تحلیلهای فنی دقیق و خروجیهای گمراهکننده را مشخص میکند. فرآیند استخراج بینش از بیگ دیتا زمانی به بازدهی عملیاتی میرسد که علاوه بر زیرساختهای ذخیرهسازی، ویژگیهای ساختاری و معنایی دادهها نیز در چرخه پردازش مدنظر قرار گیرد.
- صحت (Veracity): این ویژگی به میزان اعتمادپذیری و کیفیت دادهها اشاره دارد. به دلیل تنوع منابع، ورود دادههای ناقص، تکراری یا دارای نویز در محیطهای بیگ دیتا امری رایج است. یک دانشمند داده با ارزیابی صحت، اطمینان حاصل میکند که تحلیل داده بر پایه اطلاعات معتبر انجام شده و نتایج نهایی فاقد سوگیریهای ناشی از دادههای مخرب است.
- ارزش (Value): هدف نهایی از انباشت و پردازش اطلاعات، استخراج الگوهایی است که منجر به سودآوری یا بهبود تصمیمات استراتژیک شود. دادههای خام به تنهایی فاقد ارزش هستند و هزینههای نگهداری بالایی دارند؛ بنابراین متخصصان علم داده بر شناسایی بخشهایی از داده تمرکز میکنند که بیشترین تأثیر را بر بهینهسازی هزینهها یا کشف فرصتهای جدید بازار دارد.
- تغییرپذیری (Variability): این مولفه به نوسان در نرخ تولید داده و تغییر معنای مفاهیم در بسترهای مختلف اشاره دارد. برای مثال، یک اصطلاح در شبکههای اجتماعی ممکن است در بازههای زمانی مختلف، بار معنایی متفاوتی پیدا کند. سیستمهای تحلیل داده باید توانایی تشخیص این ناپایداریها و انطباق مدلهای پردازشی با شرایط جدید را داشته باشند.
- تجسمسازی (Visualization): تبدیل حجم عظیم اطلاعات به قالبهای بصری قابل درک، یکی از ارکان کاربردی کلان داده است. تا زمانی که نتایج پیچیده حاصل از پردازشهای سنگین به صورت نمودارهای ساده و شفاف نمایش داده نشود، ذینفعان کسبوکار قادر به درک الگوهای پنهان و اتخاذ تصمیمهای هوشمندانه نخواهند بود.
- پایداری (Viability): این ویژگی بر روی طول عمر مفید دادهها تمرکز دارد. در جریانهای پرسرعت دادهای، برخی اطلاعات تنها در لحظه تولید ارزشمند هستند و پس از مدتی منقضی میشوند. معماریهای مدرن بیگ دیتا باید توانایی اولویتبندی دادهها را بر اساس میزان ماندگاری و اهمیت آنها در تحلیلهای بلندمدت داشته باشند.
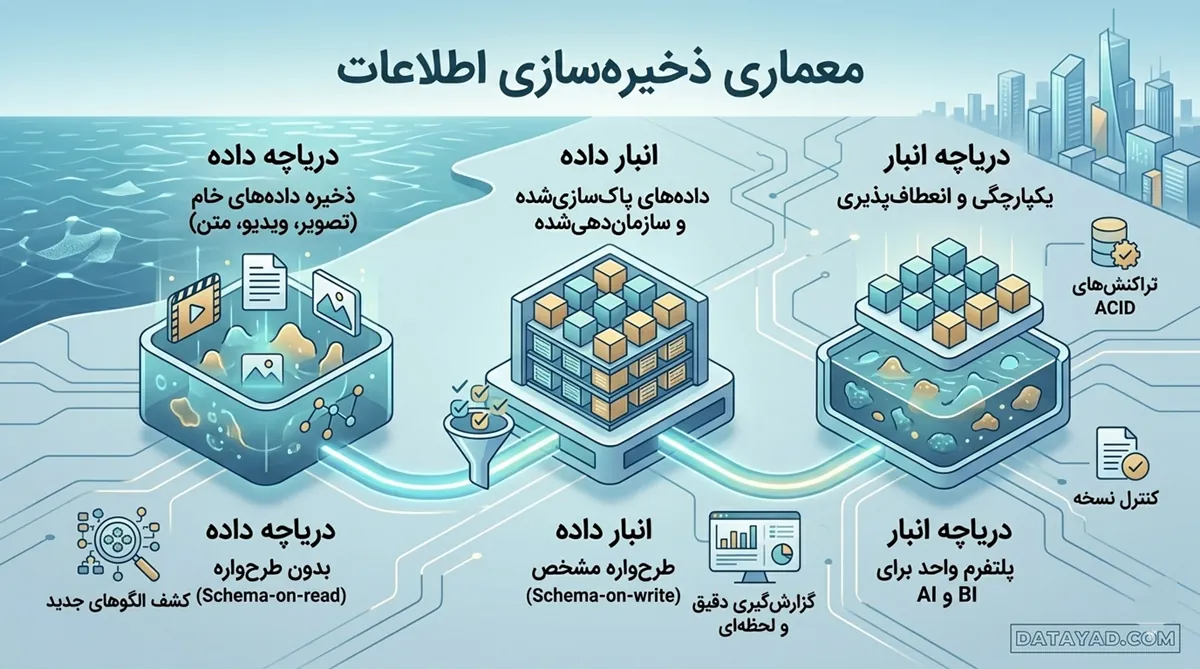
معماری ذخیرهسازی اطلاعات
سیستمهای مدیریت سنتی توانایی ذخیره و پردازش حجم عظیم ورودیهای غیرساختاریافته را ندارند. معماری ذخیرهسازی در اکوسیستم کلان داده باید امکان مقیاسپذیری افقی و دسترسی سریع به لایههای مختلف اطلاعات را برای پردازشهای بعدی فراهم کند. انتخاب نوع زیرساخت مستقیماً بر سرعت پروژههای علم داده و دقت خروجیهای نهایی تاثیر میگذارد.
Data Lake و انعطافپذیری
(Data Lake) مخزنی برای نگهداری مقادیر عظیمی از دادههای خام با فرمتهای متنوع است. در این مدل، یک دانشمند داده میتواند بدون نیاز به تعریف ساختار اولیه یا طرحواره (Schema)، تصاویر، ویدیوها و متون را به صورت دستنخورده ذخیره کند. این ویژگی باعث میشود تا هزینه نگهداری اطلاعات کاهش یابد و مسیر برای اجرای مدلهای پیچیده یادگیری ماشین هموار شود.
مهمترین مزیت دریاچه داده در پروژههای دیتا ساینس، حفظ جزئیات اولیه است. این موضوع به تحلیلگران اجازه میدهد تا در هر زمان، با بازخوانی مجدد اطلاعات، الگوهای جدیدی را کشف کنند که در مراحل اولیه استخراج نادیده گرفته شده بود. این محیطها معمولاً بر پایه سیستمهای فایل توزیعشده بنا میشوند تا پایداری اطلاعات تضمین شود.
Data Warehouse و ساختاریافتگی
(Data Warehouse) میزبان اطلاعاتی است که پیشتر پاکسازی، یکپارچه و سازماندهی شدهاند. این سیستمها برای تحلیل دادههای ساختاریافته بهینهسازی شدهاند و سرعت بسیار بالایی در پاسخگویی به پرسوجوهای (Queries) پیچیده دارند. در این معماری، اطلاعات قبل از ورود به مخزن باید از فیلترهای کنترلی عبور کنند تا با الگوی مشخص کسبوکار مطابقت داشته باشند.
یک دانشمند داده از انبار برای دسترسی به گزارشهای دقیق و تاریخی استفاده میکند. برخلاف دریاچه، در اینجا تمرکز بر کیفیت و صحت اطلاعات است تا ریسک خطای انسانی در تحلیلهای آماری به حداقل برسد. این زیرساخت معمولاً برای ابزارهای گزارشساز و داشبوردهای مدیریتی که نیاز به پاسخدهی لحظهای دارند، استفاده میشود.
یکپارچگی در دریاچه انبار
Data Lakehouse (معماری نوین و ترکیبی که انعطافپذیری دریاچه داده را با قابلیتهای مدیریتی انبار داده ادغام میکند) این معماری محدودیتهای جدایی میان مخازن خام و ساختاریافته را از بین میبرد. این رویکرد ویژگیهای مدیریتی انبار داده را به انعطافپذیری دریاچه اضافه میکند. با استفاده از این مدل، تیمهای تحلیل داده میتوانند بر روی یک پلتفرم واحد، هم عملیات هوش تجاری و هم آموزش مدلهای هوش مصنوعی را پیش ببرند.
در این ساختار، لایههای فراداده (Metadata) وظیفه برقراری نظم را بر عهده دارند. هر دیتا ساینتیست در این محیط به قابلیتهایی مثل کنترل نسخه و پشتیبانی از تراکنشهای ACID دسترسی دارد. این یکپارچگی باعث میشود تا فرآیندهای مهندسی سادهتر شده و قابلیت اطمینان به اطلاعات در مقیاس پتابایت افزایش یابد.
ابزارهای پردازش و مدیریت
سیستمهای مدیریت داده سنتی توان پردازش حجم عظیم کلان داده را ندارند و در مواجهه با ورودیهای نامنظم دچار گلوگاه میشوند. استفاده از معماری توزیعشده به دیتا ساینتیست اجازه میدهد تا پردازش را بین چندین گره (Node) تقسیم کرده و سرعت خروجی را افزایش دهد. این اکوسیستم از ابزارهای متنوعی برای انتقال، فیلتر و مدلسازی دادهها استفاده میکند.
- Apache Hadoop: یک فریمورک متنباز است که ذخیرهسازی و پردازش توزیعشده مجموعههای بزرگ را روی سختافزارهای ارزان ممکن میکند. سیستم فایل HDFS در این ابزار، داده را به قطعات کوچک تقسیم و در کلاسترهای مختلف تکثیر میکند تا دسترسیپذیری و امنیت اطلاعات حفظ شود.
- Apache Spark: این موتور پردازشی با تکیه بر محاسبات درونحافظهای (In-memory)، سرعت تحلیل را نسبت به مدلهای دیسکمحور تا چندین برابر افزایش میدهد. یک دانشمند داده برای انجام پروژههای پیچیده در علم داده و تحلیل داده لحظهای، این ابزار را به دلیل پشتیبانی از کتابخانههای پیشرفته یادگیری ماشین انتخاب میکند.
- پایگاههای داده NoSQL: این دیتابیسها برخلاف مدلهای رابطهای، بدون طرحواره (Schema-less) هستند و برای مدیریت دادههای غیرساختاریافته بیگ دیتا طراحی شدهاند. ابزارهایی مثل MongoDB و Cassandra با قابلیت مقیاسپذیری افقی، مدیریت حجم پتابایتی اطلاعات را که ساختار ثابتی ندارند، تسهیل میکنند.
- Apache Kafka: این ابزار برای مدیریت جریانهای داده ای (Data Streams) در مقیاس وسیع به کار میرود و نقش واسط را در انتقال سریع اطلاعات ایفا میکند. کافکا به متخصصان دیتا ساینس کمک میکند تا دادههای تولید شده در لحظه را از منابع مختلف جمعآوری کرده و بدون وقفه به موتورهای پردازشی ارسال کنند.
- Apache NiFi: ابزاری برای اتوماسیون جریان داده بین سیستمهای مختلف است که مدیریت انتقال اطلاعات را بصری میکند. این پلتفرم با فراهم کردن امکان ردیابی دادهها، فرآیند پاکسازی و آمادهسازی ورودیها را برای تحلیلهای بعدی در علم داده سادهتر میکند.
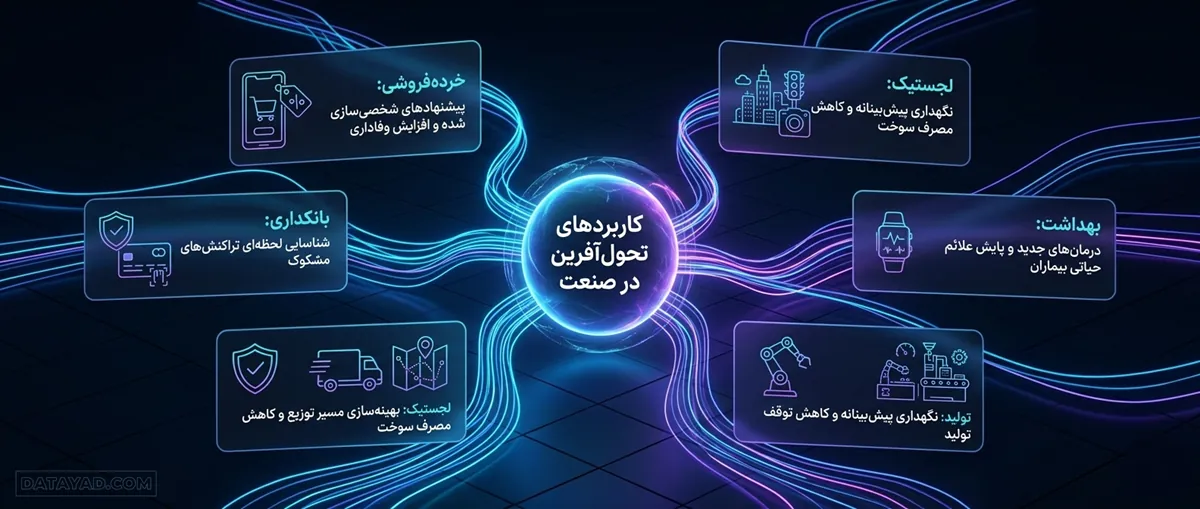
کاربردهای تحولآفرین در صنعت
سازمانها برای استخراج ارزش عملیاتی از جریانهای اطلاعاتی، از مدلهای پیشرفته تحلیل داده استفاده میکنند. این رویکرد باعث میشود فرآیند تصمیمگیری از حالت واکنشی به حالت پیشبینانه تغییر جهت دهد. پیادهسازی پروژههای دیتا ساینس در لایههای مختلف صنعت، منجر به کشف گلوگاههای هزینهبر و ایجاد فرصتهای جدید درآمدی میشود.
- خردهفروشی و تجارت الکترونیک: فروشگاهها با رهگیری دقیق عادتهای خرید و تحلیل رفتار کاربران، پیشنهادهای شخصیسازی شده ارائه میدهند. این کار باعث افزایش نرخ تبدیل و وفاداری مشتریان میشود.
- بانکداری و امور مالی: الگوهای پرداخت به صورت لحظهای با سوابق تاریخی مقایسه میشوند تا تراکنشهای مشکوک و کلاهبرداریها بلافاصله شناسایی شوند. این فرآیند امنیت سیستمهای پرداخت را به شکل قابل توجهی ارتقا میدهد.
- لجستیک و مدیریت زنجیره تأمین: یک دانشمند داده با ترکیب اطلاعات مکانی، وضعیت ترافیکی و دادههای جوی، مسیرهای توزیع کالا را بهینهسازی میکند. این اقدام مصرف سوخت را کاهش داده و سرعت تحویل محصول به مشتری را افزایش میدهد.
- تولید و نگهداری تجهیزات: سنسورهای نصب شده روی ماشینآلات صنعتی، دادههای لرزش و دما را ارسال میکنند. تحلیل این اطلاعات به تیمهای فنی اجازه میدهد خرابی قطعات را پیشبینی کرده و پیش از توقف خط تولید، تعمیرات لازم را انجام دهند.
- بهداشت و درمان: متخصصان با استفاده از ابزارهای علم داده، سوابق پزشکی پیچیده و نتایج آزمایشگاهی را برای کشف روشهای درمانی جدید تحلیل میکنند. همچنین پایش لحظهای علائم حیاتی بیماران از طریق ابزارهای پوشیدنی، امکان مداخله سریع پزشکی را فراهم میکند.
- مدیریت شهری و خدمات عمومی: پردازش دادههای جیپیاس و تصاویر دوربینهای نظارتی برای کنترل هوشمند ترافیک و شناسایی نقاط آسیبدیده در زیرساختهای شهری به کار میرود.
هر دیتا ساینتیست با تمرکز بر این حوزهها، کلان داده را به یک دارایی استراتژیک تبدیل میکند. هدف نهایی در تمامی این بخشها، حذف حدس و گمان و جایگزینی آن با شواهد آماری دقیق برای ارتقای بهرهوری است.
چالشهای پیادهسازی و مدیریت بیگ دیتا
مدیریت بیگ دیتا در سطح سازمانی با موانع فنی و عملیاتی متعددی همراه است که میتواند خروجی نهایی پروژهها را تحت تاثیر قرار دهد. بسیاری از استراتژیهای علم داده به دلیل عدم تطابق زیرساختهای فعلی با نرخ ورود اطلاعات، در مرحله اجرا با شکست مواجه میشوند. این چالشها شامل جنبههای فنی، انسانی و قانونی است که در ادامه بررسی شدهاند.
- کمبود متخصصان باتجربه: استخدام دانشمند داده و مهندسانی که توانایی کار با اکوسیستمهای پیچیده را داشته باشند، به یکی از بزرگترین دغدغههای سازمانها تبدیل شده است. کمبود نیرو باعث میشود تحلیل داده به درستی انجام نشود و ابزارهای گرانقیمت بلااستفاده بمانند.
- مدیریت کیفیت و صحت: ورود اطلاعات از منابع غیرمتمرکز، ریسک نویز و خطاهای ساختاری را افزایش میدهد. یک دیتا ساینتیست زمان زیادی را صرف پاکسازی اطلاعات میکند؛ زیرا ورودی نامعتبر منجر به تصمیمات تجاری اشتباه میشود.
- امنیت و الزامات قانونی: نگهداری کلان داده در محیطهای ابری یا توزیعشده، سطح حملات سایبری را گسترش میدهد. شرکتها برای جلوگیری از نشت اطلاعات حساس و رعایت استانداردهای بینالمللی، با پیچیدگیهای فنی زیادی در رمزنگاری و مدیریت دسترسیها روبرو هستند.
- یکپارچهسازی سیستمهای قدیمی: ادغام اطلاعات موجود در پایگاههای داده سنتی با معماریهای نوین کلان داده دشوار است. این ناهماهنگی باعث میشود فرآیند استخراج و تبدیل اطلاعات زمانبر و هزینهبر باشد و سیلوهای اطلاعاتی ایجاد کند.
- هزینههای ذخیره و پردازش: با افزایش تصاعدی حجم اطلاعات، تقاضا برای منابع محاسباتی به شدت بالا میرود. مدیریت بهینه بودجه برای تامین سرورهای قدرتمند یا خدمات ابری، نیازمند معماری دقیق است تا از اتلاف منابع جلوگیری شود.
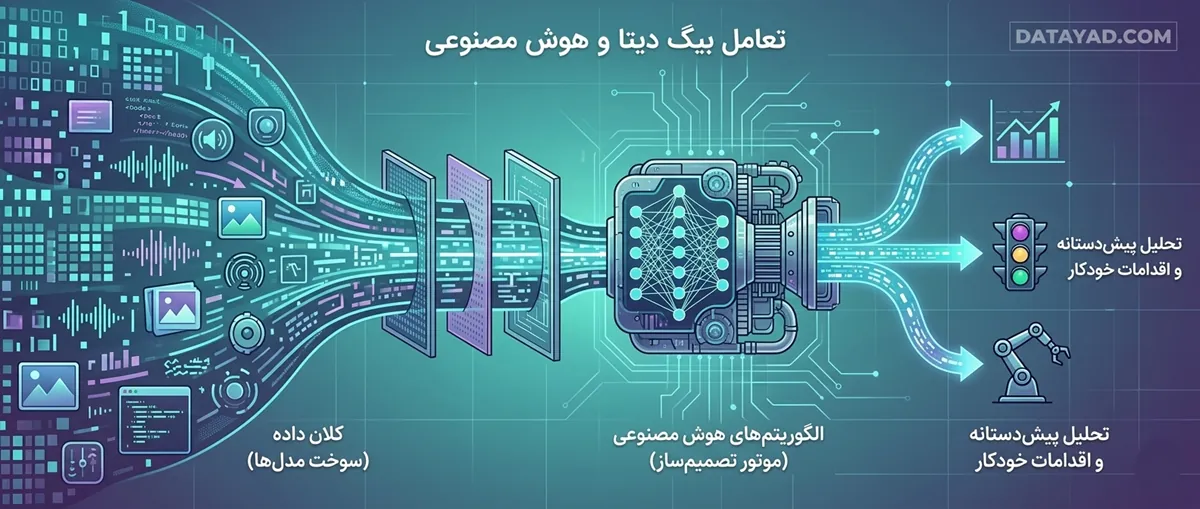
تعامل بیگ دیتا و هوش مصنوعی
نقش کلان داده ها در توسعه هوش مصنوعی بسیار پررنگ و جدی است. الگوریتم های هوش مصنوعی برای رسیدن به دقت عملیاتی، به مجموعههای عظیم و متنوع اطلاعاتی وابستهاند. پردازش این حجم از داده در سیستمهای سنتی غیرممکن است و دقیقاً در همین نقطه، زیرساختهای بیگ دیتا وارد عمل میشوند. این تعامل دوطرفه باعث میشود تا الگوریتمها از حالت تئوری خارج شده و به ابزارهای تصمیمساز تبدیل شوند.
هوش مصنوعی بدون دادههای حجیم، مانند موتوری بدون سوخت است که توان حرکت ندارد. از سوی دیگر، کلان داده بدون هوش مصنوعی تنها تودهای از اطلاعات خام باقی میماند که استخراج معنا از آن برای انسان غیرممکن است. این همافزایی، بنیان اصلی سیستمهای هوشمند مدرن را تشکیل میدهد.
تغذیه مدلهای یادگیری ماشین
یادگیری ماشین بدون دسترسی به مخازن بزرگ داده، توانایی شناسایی الگوها و بهبود خودکار را ندارد. بیگ دیتا با فراهم کردن تنوع و حجم لازم، به مدلها اجازه میدهد سناریوهای مختلف را شبیهسازی و درک کنند. یک دانشمند داده با استفاده از تکنیکهای علم داده، این جریانهای اطلاعاتی را تصفیه میکند تا نویزها باعث انحراف خروجی نشوند.
کیفیت ورودی مستقیماً بر خروجی هوش مصنوعی اثر میگذارد. اگر دادههای آموزشی ناقص یا سوگیرانه باشند، سیستم هوشمند دچار خطا و سوگیری الگوریتمی در قضاوت میشود. بنابراین، مدیریت صحیح کلان داده اولین قدم در توسعه هر مدل یادگیری ماشین موفق است.
دیتا ساینتیست با تکیه بر تحلیل داده، متغیرهای تاثیرگذار را شناسایی کرده و آنها را به کدهای قابل فهم برای ماشین تبدیل میکند. این فرآیند باعث میشود که مدلها با گذشت زمان و مواجهه با دادههای بیشتر، دقیقتر عمل کنند.
تحلیل پیشدستانه و یادگیری عمیق
یادگیری عمیق که لایه پیشرفتهتری از هوش مصنوعی است، به شدت به دادههای غیرساختاریافته مثل تصویر و صوت نیاز دارد. تحلیل داده در این سطح، به مدلها کمک میکند تا فراتر از گزارشهای آماری، به پیشبینی رفتارهای آتی بپردازند. دیتا ساینتیست از ترکیب قدرت پردازشی بیگ دیتا و شبکههای عصبی برای استخراج بینشهای پنهان استفاده میکند.
این فرآیند منجر به ایجاد سیستمهایی میشود که قادر به تحلیل پیشدستانه و تشخیص ناهنجاریها قبل از وقوع بحران هستند. بدون بیگ دیتا، شبکههای عصبی عمیق نمیتوانند ویژگیهای پیچیده را در لایههای مختلف خود استخراج کنند. در واقع، حجم بالای داده باعث کاهش خطای تعمیم در این مدلها میشود.
در پروژههای بزرگ دیتا ساینس، هدف نهایی تبدیل جریانهای داده لحظهای به اقدامات خودکار است. این سطح از هوشمندی تنها زمانی محقق میشود که الگوریتمهای پیشرفته دسترسی بدون محدودیت به زیرساختهای بیگ دیتا داشته باشند. این ارتباط، امکان پردازش موازی و یادگیری توزیعشده را فراهم میکند.




















