تحلیل سری زمانی یکی از حوزههای بنیادی در آمار و علم داده است که بر درک و پیشبینی الگوها در دادههای ترتیبی تمرکز دارد. با تحلیل مشاهداتی که در طول زمان جمعآوری میشوند، میتوان روندها (Trends)، اثرات فصلی (Seasonal Effects) و روابط در حال تغییر را شناسایی کرد؛ عناصری که برای مدلسازی و پیشبینی دقیق بسیار ضروری هستند.
دادههای سری زمانی (Time Series) شامل مشاهداتی هستند که در فواصل زمانی منظم ثبت میشوند و بهطور گسترده در حوزههایی مانند امور مالی، اقتصاد، مراقبتهای بهداشتی و اقلیمشناسی برای بررسی نحوه تغییر متغیرها در طول زمان مورد استفاده قرار میگیرند. فصلی بودن در سری زمانی نیز به الگوهای تکرارشونده و منظم در بازههای زمانی مشخص گفته میشود که معمولاً ناشی از عواملی مانند شرایط آبوهوایی، تعطیلات یا چرخههای کسبوکار هستند.
برای تسلط بر مفاهیم پیشرفتهای همچون تحلیل سریهای زمانی و یادگیری نحوه پیادهسازی مدلهای پیشبینی، استفاده از منابع کاربردی مانند آموزش علم داده با پایتون میتواند مسیر پیشرفت شما را در این حوزه بسیار هموارتر کند.
معنی فصلی بودن در سری زمانی چیست؟
فصلی بودن (Seasonality) در دادههای سری زمانی به الگوهای تکرارشوندهای گفته میشود که در بازههای زمانی مشخص مانند ماهانه، فصلی یا سالانه رخ میدهند. این الگوها معمولاً تحت تأثیر عواملی مانند شرایط آبوهوایی، تعطیلات، رفتار مشتریان یا چرخههای اقتصادی ایجاد میشوند.
برای مثال:
- افزایش فروش فروشگاهها در تعطیلات سال نو
- افزایش مصرف برق در تابستان
- افزایش تعداد مسافران خطوط هوایی در فصلهای گردشگری
تشخیص فصلی بودن یکی از مراحل مهم در تحلیل سری زمانی است، زیرا وجود این الگوها میتواند به شکل قابل توجهی بر دقت مدلهای پیشبینی تأثیر بگذارد. اگر اثرات فصلی شناسایی و مدیریت نشوند، مدلهای پیشبینی ممکن است روند واقعی دادهها را بهدرستی تشخیص ندهند.
در ادامه، روشهای تشخیص و حذف فصلی بودن در دادههای سری زمانی را بهصورت مرحلهبهمرحله بررسی میکنیم.
چرا باید فصلی بودن در سری زمانی را تشخیص دهیم؟
در علم داده دلایل مشخصی برای تشخیص فصلی بودن در دادههای سری زمانی وجود دارد که در ادامه بیان شدهاند:
- تشخیص الگو (Pattern Detection): شناسایی فصلی بودن به تحلیلگران کمک میکند الگوهای تکرارشونده را تشخیص دهند که این موضوع باعث بهبود تفسیر دادهها و پیشبینیهای آینده میشود.
- پیشبینی (Forecasting): شناسایی دقیق روندهای فصلی از توسعه مدلهای پیشبینی پایدار پشتیبانی کرده و منجر به پیشبینیهای قابل اعتمادتر میشود.
- تشخیص ناهنجاری (Anomaly Detection): درک رفتار فصلی باعث میشود ناهنجاریهایی که از الگوهای مورد انتظار منحرف میشوند و ممکن است نشاندهنده رویدادهای مهم باشند، آسانتر شناسایی شوند.
- بهینهسازی تصمیمگیری (Optimized Decision-Making): شناخت فصلی بودن به سازمانها این امکان را میدهد که منابع خود را بهینه تخصیص دهند، موجودی انبار را بهصورت کارآمد مدیریت کنند و استراتژیهای خود را مطابق با تقاضای فصلی تنظیم نمایند.
تکنیکهای حذف فصلی بودن در سری زمانی
فصلی بودن در دادههای سری زمانی را میتوان با استفاده از تفاضلگیری فصلی (Seasonal Differencing) مدیریت کرد. دانشمندان داده با این تکنیک اثرات فصلی را حذف میکند و به تبدیل دادهها به یک شکل ایستا (Stationary) کمک میکند تا پیشبینیها قابل اعتمادتر شوند.
- تفاضلگیری فصلی الگوهای تکرارشونده فصلی را با کم کردن هر نقطه داده از مقدار متناظر آن در فصل قبلی حذف میکند.
- برای مثال، در دادههای ماهانه با فصلی بودن سالانه، مقدار ماه جاری از مقدار همان ماه در ۱۲ ماه قبل کم میشود.
- این فرایند رفتار چرخهای دادهها را کاهش میدهد و باعث میشود دادهها پایدارتر شده و برای آموزش مدلهای پیشبینی مناسبتر شوند.
- این روش را میتوان بهسادگی با استفاده از متد
.diff()در کتابخانه Pandas و تعیین یک دوره مناسب (مثلاً 12) اعمال کرد.
پیادهسازی مرحلهبهمرحله تشخیص فصلی بودن در سری زمانی
مرحله ۱: وارد کردن ماژولهای موردنیاز
در این مرحله، ماژولهای ضروری پایتون برای تحلیل داده، مصورسازی و تجزیه سری زمانی را وارد میکنیم:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from statsmodels.tsa.seasonal import seasonal_decompose
مرحله ۲: بارگذاری داده و مصورسازی سری زمانی
در این مرحله، مطابق متن اصلی، دادهی مسافران خطوط هوایی آمریکا (AirPassengers) از فایل CSV بارگذاری میشود. سپس ستون «Month» به فرمت تاریخ تبدیل شده و به عنوان ایندکس سری زمانی تنظیم میگردد. پس از آمادهسازی داده، سری زمانی اصلی رسم میشود تا الگوها، روند و احتمال وجود فصلی بودن بهصورت بصری قابل مشاهده باشد.
data = pd.read_csv('AirPassengers.csv')
data['Month'] = pd.to_datetime(data['Month'], format='%Y-%m')
data.set_index('Month', inplace=True)
# Plot the original time series data
plt.figure(figsize=(7, 5))
plt.plot(data, label='Original Time Series')
plt.title('Air Passengers Time Series')
plt.xlabel('Year')
plt.ylabel('Number of Passengers')
plt.legend()
plt.show()
خروجی: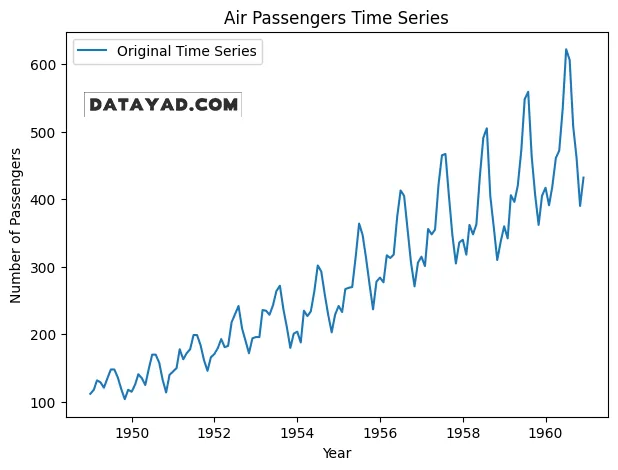
مرحله ۳: تجزیه سری زمانی (Trend، Seasonal و Residual)
در این مرحله سری زمانی به سه مؤلفه اصلی روند (Trend)، فصلی (Seasonal) و باقیمانده (Residual) تجزیه میشود. برای این کار از مدل Multiplicative استفاده میکنیم، زیرا الگوی فصلی در سطوح مختلف سری زمانی تقریباً ثابت در نظر گرفته میشود.
کد زیر برای انجام تجزیه سری زمانی استفاده میشود:
# Decompose the time series into trend, seasonal and residual components
result = seasonal_decompose(
data, model='multiplicative', extrapolate_trend='freq')
result.plot()
plt.suptitle('Seasonal Decomposition of Air Passengers Time Series')
plt.tight_layout()
plt.show()
خروجی:
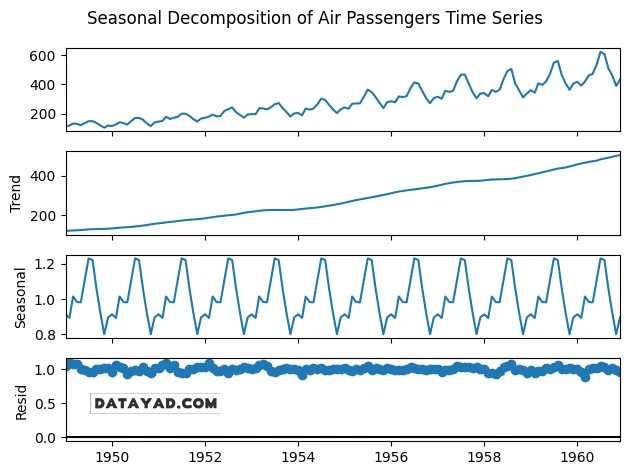
مرحله ۴: مشاهده و مصورسازی مؤلفه فصلی
در این مرحله، تنها مؤلفه Seasonal (فصلی) را از نتایج تجزیه استخراج کرده و آن را بهصورت جداگانه رسم میکنیم تا الگوی تکرارشونده در بازههای زمانی مشخص بهوضوح قابل مشاهده باشد.
# Plot the seasonal component
plt.figure(figsize=(6, 4))
plt.plot(result.seasonal, label='Seasonal Component')
plt.title('Seasonal Component of Air Passengers Time Series')
plt.xlabel('Year')
plt.ylabel('Seasonal Component')
plt.legend()
plt.show()
خروجی:
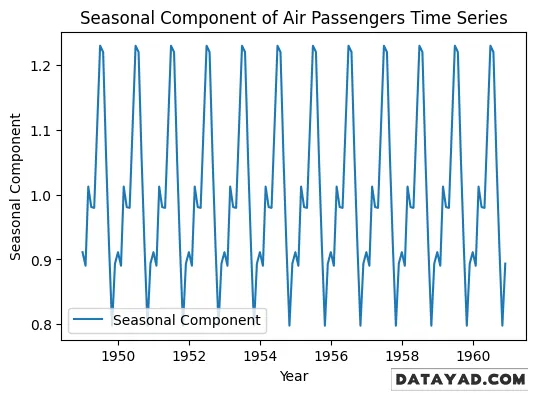
مرحله ۵: حذف فصلی بودن از دادهها
برای استفاده از دادههای سری زمانی در کاربردهای مختلف از جمله آموزش مدل (Model Training)، لازم است دادهها فاقد مؤلفه فصلی باشند.
معادله:
d(t) = y(t) – y(t – m)
که در آن:
- d(t) مقدار تفاضلگرفتهشده در زمان t است.
- y(t) مقدار سری در زمان t است.
- y(t – m) مقدار داده در فصل قبلی است.
- m طول یک فصل است (در این مثال، چون فصلی بودن سالانه است، m = 12 در نظر گرفته میشود).
این معادله بیانگر تفاضلگیری فصلی (Seasonal Differencing) است که برای حذف مؤلفه فصلی از دادهها استفاده میشود.
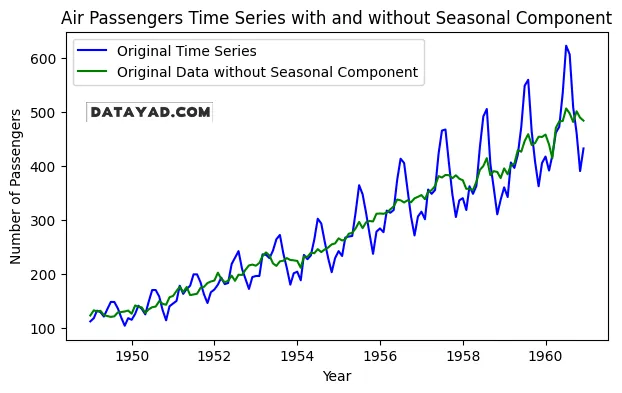
در ادامه مشاهده میکنیم که پس از حذف فصلی بودن، دادهها تا چه اندازه منظمتر به نظر میرسند.
# Plotting the original data and original data without the seasonal component
plt.figure(figsize=(7, 4))
# Plot the original time series data
plt.plot(data, label='Original Time Series', color='blue')
data_without_seasonal = data['#Passengers'] / result.seasonal
# Plot the original data without the seasonal component
plt.plot(data_without_seasonal,
label='Original Data without Seasonal Component', color='green')
plt.title('Air Passengers Time Series with and without Seasonal Component')
plt.xlabel('Year')
plt.ylabel('Number of Passengers')
plt.legend()
plt.show()
خروجی:
مرحله ۶: اعمال آزمون Augmented Dickey-Fuller (ADF)
پس از حذف مؤلفه فصلی از دادهها، مرحله مهم بعدی بررسی این است که آیا سری زمانی ایستا (Stationary) شده است یا خیر. برای این کار معمولاً از آزمون Augmented Dickey-Fuller (ADF) استفاده میشود.
این آزمون فرض صفر (Null Hypothesis) را بررسی میکند که میگوید سری زمانی دارای ریشه واحد (Unit Root) است؛ وجود ریشه واحد به این معنی است که دادهها غیرایستا (Non‑stationary) هستند.
در ادامه نحوه اجرای آزمون ADF در پایتون آورده شده است:
from statsmodels.tsa.stattools import adfuller
adf_result = adfuller(data_without_seasonal)
print('ADF Statistic:', adf_result[0])
print('p-value:', adf_result[1])
#Interpreting the results
if
adf_result[1] < 0.05 : print("The data is stationary (p-value < 0.05).")
else:
print("The data is not stationary (p-value >= 0.05).")
ADF Statistic: 1.1415289777074211
p-value: 0.9955559262862962
The data is not stationary (p-value >= 0.05).
نتیجه آزمون نشان میدهد که حتی پس از حذف فصلی بودن، مقدار p-value بزرگتر از 0.05 است. این موضوع نشان میدهد که دادهها هنوز غیرایستا هستند. علت این مسئله معمولاً وجود روند (Trend) در دادهها است.
در چنین شرایطی برای رسیدن به ایستایی، لازم است تفاضلگیری بیشتری (Additional Differencing) روی دادهها انجام شود تا روند نیز حذف گردد.
بنابراین در این مرحله دادهها هنوز برای آموزش مدلهای پیشبینی سری زمانی آماده نیستند و نیاز به تبدیلهای بیشتری دارند. استفاده از تفاضلگیری مرتبه اول (First Differencing) یا روشهای دیگر تجزیه میتواند به آمادهسازی کامل دادهها برای پیشبینی کمک کند.
مرحله ۷: تفاضلگیری از دادهها
در این مرحله برای حذف روند باقیمانده در دادهها، از تفاضلگیری (Differencing) استفاده میکنیم و مجدداً با استفاده از آزمون ADF ایستایی سری زمانی را بررسی میکنیم.
data_diff = data_without_seasonal.diff().dropna()
adf_result = adfuller(data_diff)
print('ADF Statistic:', adf_result[0])
print('p-value:', adf_result[1])
ADF Statistic: -2.9058136872756286
p-value: 0.04467610954112502
پس از تعدیل فصلی (Seasonal Adjustment)، آزمون ADF در ابتدا نشان داد که دادهها غیرایستا هستند (p-value = 0.9955) که بیانگر وجود روند باقیمانده در دادهها بود.
با اعمال تفاضلگیری، مقدار p-value به 0.0447 کاهش یافت که نشان میدهد اکنون دادهها ایستا (Stationary) شدهاند و برای پیشبینی مناسب هستند.
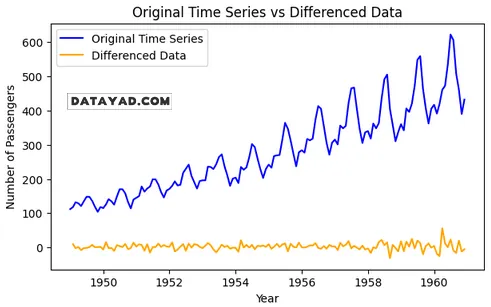
مصورسازی دادهها پس از تفاضلگیری
plt.figure(figsize=(7, 4))
plt.plot(data, label='Original Time Series', color='blue')
plt.plot(data_diff, label='Differenced Data', color='orange')
plt.title('Original Time Series vs Differenced Data')
plt.xlabel('Year')
plt.ylabel('Number of Passengers')
plt.legend()
plt.show()
خروجی