

در این مطلب از بخش آموزش هوش مصنوعی به بررسی یادگیری نیمه نظارتی (Semi-supervised Learning) میپردازیم؛ این رویکرد یکی از شاخههای کلیدی در یادگیری ماشین است که با ترکیب هوشمندانه دادههای برچسبدار و بدون برچسب، محدودیتهای سنتی آموزش مدل را از بین میبرد. در حالی که یادگیری نظارتی به مجموعهدادههای حجیم و با برچسب دقیق نیاز دارد، این روش به متخصصان اجازه میدهد تا با استفاده از تعداد اندکی دادهی برچسبگذاری شده و حجم وسیعی از اطلاعات خام، مدلهایی با دقت بالا و تعمیمپذیری مناسب طراحی کنند.
اهمیت این روش زمانی مشخص میشود که فرآیند برچسبگذاری دستی دادهها، هزینهبر، زمانبر یا نیازمند دانش تخصصی بسیار بالا باشد. یادگیری نیمه نظارتی با تکیه بر ساختار درونی دادههای بدون برچسب و استفاده از فرضیات آماری خاص، پل ارتباطی قدرتمندی میان یادگیری نظارتی و غیرنظارتی ایجاد کرده و در حوزههایی مانند پردازش تصویر، تحلیل متون و تشخیص پزشکی کاربردهای گستردهای یافته است.
یادگیری نیمه نظارتی چیست و چرا اهمیت دارد؟
یادگیری نیمه نظارتی (Semi-supervised Learning) یکی از پیشرفتهترین و هوشمندانهترین شاخههای هوش مصنوعی است که برای حل یکی از بزرگترین چالشهای دنیای داده طراحی شده است. در حالی که مدلهای سنتی یادگیری ماشین یا به دادههای کاملاً برچسبدار نیاز دارند و یا کاملاً بدون نظارت عمل میکنند، این روش به عنوان یک راهکار میانی ظاهر شده است.
به زبان ساده، در پروژههای بزرگ هوش مصنوعی، ما اغلب با اقیانوسی از دادههای خام روبرو هستیم، اما برچسبگذاری دستی آنها توسط انسان، هزینهبر و بسیار زمانبر است. یادگیری نیمه نظارتی به مدل اجازه میدهد با یادگیری از یک «هسته کوچک» از دادههای برچسبدار و ترکیب آن با حجم عظیمی از دادههای بدون برچسب، به دقتی دست یابد که پیش از این تنها با صرف هزینههای گزاف ممکن بود.
برای مثال، در سیستمهای تشخیص گفتار که یکی از کاربردهای جذاب هوش مصنوعی است، میتوان تنها با چند ساعت فایل صوتی برچسبگذاری شده و هزاران ساعت صدای خام، مدلی طراحی کرد که زبان انسان را با دقت بسیار بالا درک کند. این رویکرد نه تنها سرعت توسعه مدلها را افزایش میدهد، بلکه مرزهای پیادهسازی هوش مصنوعی را در صنایع مختلف جابهجا کرده است.
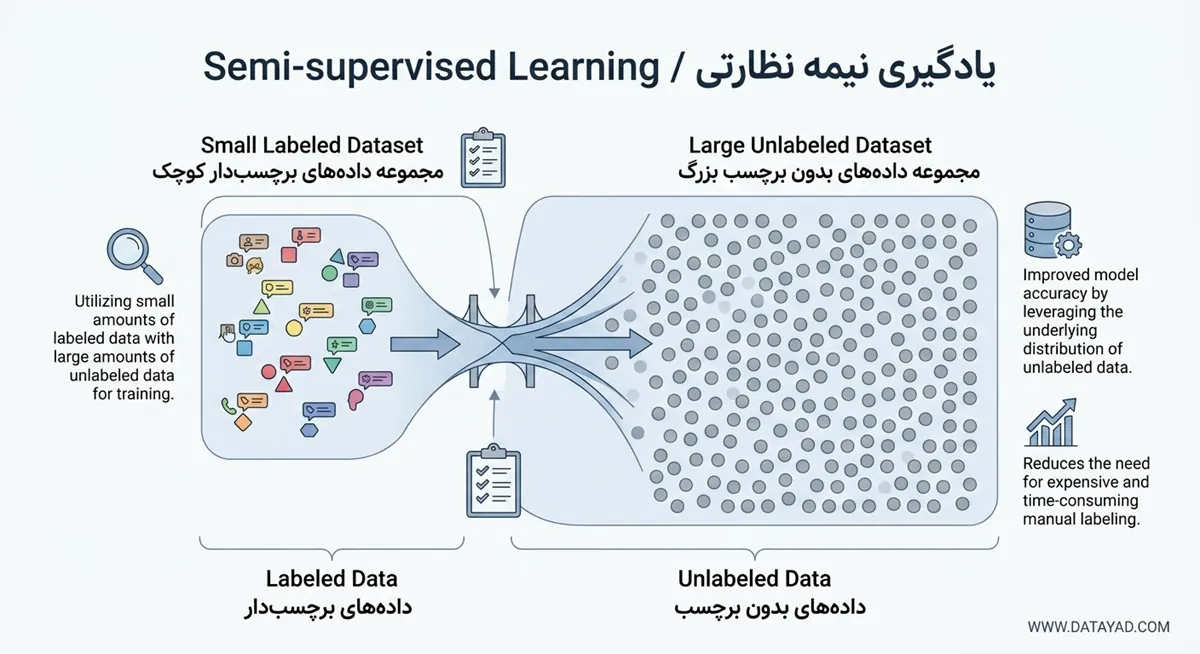
جایگاه یادگیری نیمه نظارتی در یادگیری ماشین
یادگیری نیمه نظارتی به عنوان یک رویکرد میانی، شکاف عملیاتی بین روشهای نظارت شده و بدون نظارت را پر میکند. این متدولوژی زمانی اولویت پیدا میکند که استخراج برچسب برای حجم انبوه دادهها نیازمند تخصص دامنه بالا و صرف هزینههای گزاف باشد. در این ساختار، مدل با استفاده از تعداد محدودی داده برچسبدار، مرز تصمیمگیری اولیه را تشکیل میدهد و سپس از ساختار دادههای بدون برچسب برای بهبود تعمیمپذیری استفاده میکند.
| ویژگی محور | یادگیری نظارت شده | یادگیری بدون نظارت | یادگیری نیمه نظارتی |
|---|---|---|---|
| نوع داده ورودی | دادههای کاملاً برچسبدار | دادههای کاملاً بدون برچسب | ترکیبی (حجم کمی برچسبدار) |
| هدف اصلی | طبقهبندی و رگرسیون دقیق | خوشهبندی و کاهش ابعاد | استخراج الگو از دادههای انبوه |
| هزینه آمادهسازی | بسیار بالا و زمانبر | حداقلی | بهینه و اقتصادی |
| اتکا به دانش انسانی | حداکثری (برای برچسبگذاری) | حداقلی | متوازن و هدفمند |
این جایگاه استراتژیک به الگوریتمها اجازه میدهد تا از فرضهایی مانند «فرض خوشه» و «فرض همواری» برای استخراج الگوهای پنهان استفاده کنند. در واقع، یادگیری نیمه نظارتی با ترکیب دقت متدهای نظارت شده و مقیاسپذیری متدهای بدون نظارت، راهکاری کارآمد برای پروژههای بزرگمقیاس ارائه میدهد. این روش به ویژه در سناریوهایی که برچسبگذاری دادهها نیازمند تحلیل تخصصی است، کارایی فنی بالایی از خود نشان میدهد.
ضرورت استفاده از دادههای بدون برچسب
در بسیاری از پروژههای هوش مصنوعی، تعداد دادههای بدون برچسب بسیار بیشتر از دادههای برچسبدار است. استفاده از این دادهها فقط برای صرفهجویی در زمان و هزینه نیست؛ بلکه مدل برای فهمیدن «ساختار واقعی داده» به آنها نیاز دارد. دادههای بدون برچسب کمک میکنند مدل تصویر کاملتری از شکلگیری الگوها، خوشهها و روابط داخلی دادهها به دست آورد و در نتیجه تصمیمهای دقیقتری بگیرد.
- دقت در تعیین مرز تصمیمگیری: وقتی فقط با دادههای برچسبدار کار میکنیم، ممکن است مدل مرز بین کلاسها را اشتباه قرار دهد. دادههای بدون برچسب نشان میدهند تراکم نقاط در کدام نواحی بیشتر یا کمتر است و مدل مجبور میشود مرز تصمیم را از مناطق خلوتتر عبور دهد. این کار دقت دستهبندی را بالاتر میبرد.
- بهرهبرداری از ساختار پنهان دادهها: بسیاری از دادهها روی ساختارهای کمبعدتر (منیفولدها) قرار میگیرند. تحلیل تعداد زیادی داده خام باعث میشود مدل این ساختار واقعی را بهتر شناسایی کند و ویژگیهای دقیقتری از دادهها استخراج کند؛ کاری که با دادههای محدود برچسبدار بهتنهایی ممکن نیست.
- انتقال دانش از طریق انتشار برچسب: دادههای بدون برچسب نقش پل را بازی میکنند. اگر چند نمونه برچسبدار داشته باشیم، مدل میتواند با کمک فرض همواری، برچسب آنها را به نقاط مشابه اطرافشان منتقل کند. این کار محدوده یادگیری مدل را گسترش میدهد.
- کاهش خطای تعمیمپذیری: وقتی دادههای برچسبدار کم باشند، مدل احتمالاً دچار بیشبرازش میشود و فقط همان نمونههای محدود را به خاطر میسپارد. دادههای بدون برچسب کمک میکنند مدل با نمونههای متنوعتری روبهرو شود و الگوهای واقعیتری را یاد بگیرد.
- تکمیل اطلاعات p(y|x) با کمک p(x): ساختار دادههای خام به مدل نشان میدهد هر نمونه در فضای ویژگیها چگونه توزیع شده است. این موضوع باعث میشود پیشبینی اینکه هر نمونه به چه کلاسی تعلق دارد دقیقتر انجام شود و مدل در مواجهه با دادههای جدید عملکرد پایدارتری داشته باشد.
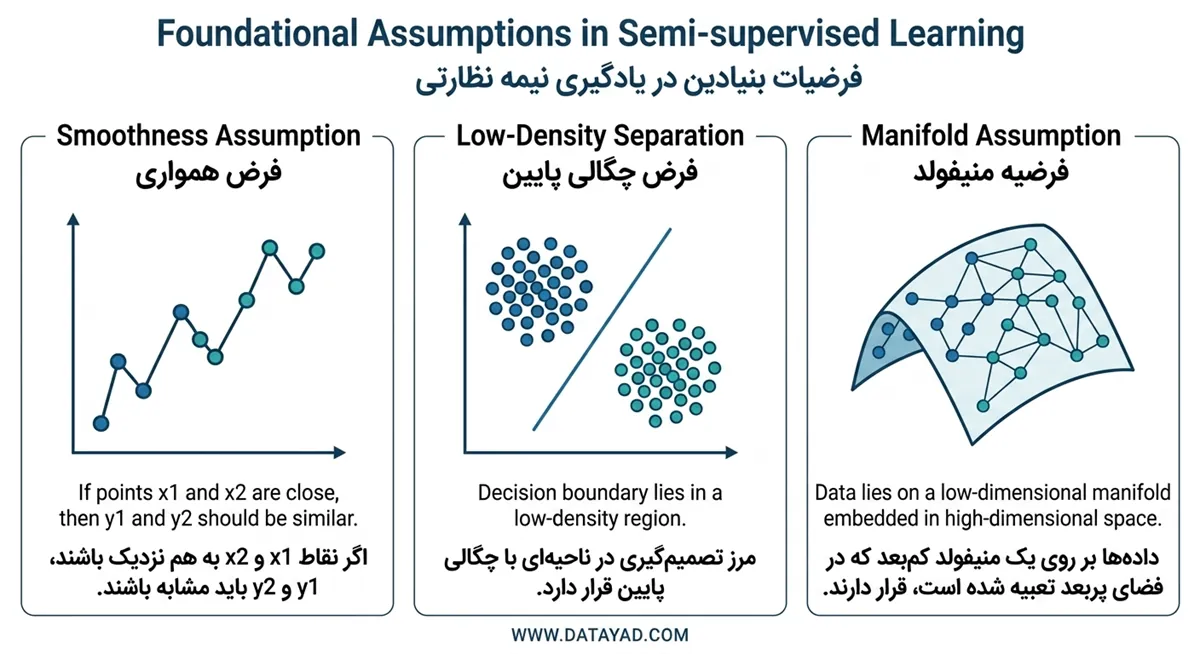
فرضیات بنیادین در تحلیل هوشمند داده
در یادگیری نیمه نظارتی، ارتباط میان توزیع دادههای ورودی p(x) و برچسبهای هدف p(y|x) بر پایه مجموعهای از پیشفرضهای ریاضی بنا شده است. این فرضیات به الگوریتم اجازه میدهند تا ساختار نهفته در دادههای بدون برچسب را کشف کرده و از آن برای بهبود دقت پیشبینی استفاده کند. بدون این چارچوبهای منطقی، استفاده از دادههای خام صرفاً باعث افزایش نویز در مدل میشود.
فرض همواری و تداوم دادهها
طبق این اصل، اگر دو نقطه در فضای ویژگیها فاصله کمی از یکدیگر داشته باشند، به احتمال زیاد برچسب یکسانی خواهند داشت. این ویژگی به مدل اجازه میدهد تا دانش خود را از نمونههای برچسبدار به همسایگان نزدیک آنها منتقل کند. در واقع، همواری باعث میشود که تغییرات در خروجی مدل به صورت تدریجی رخ دهد و از تغییرات ناگهانی در نواحی پرتراکم جلوگیری شود.
این فرآیند زیربنای روشهایی مانند انتشار برچسب است که در آن برچسبها به صورت زنجیرهای به دادههای مشابه سرایت میکنند. در این حالت، دادههای بدون برچسب به عنوان پلهای ارتباطی عمل کرده و انتقال دانش را میان نقاط دورتر تسهیل میکنند.
فرض چگالی پایین در مرز تصمیم
این فرضیه بر این باور استوار است که مرز تصمیمگیری بین کلاسهای مختلف نباید از نواحی با تراکم بالای داده عبور کند. به عبارت سادهتر، مرز جداکننده باید در شکافها یا مناطقی که دادههای کمتری در آنجا حضور دارند، قرار بگیرد. این رویکرد به مدل کمک میکند تا خوشههای طبیعی داده را شناسایی کرده و مرزها را به گونهای تنظیم کند که هر خوشه به طور کامل در یک سمت مرز قرار گیرد.
استفاده از این فرض در مدلهایی مانند ماشینهای بردار پشتیبان نیمه نظارتی، منجر به ایجاد مرزهای پایدارتر میشود. وقتی مرز از نواحی کمتراکم عبور کند، مدل در برابر تغییرات جزئی دادهها حساسیت کمتری نشان داده و خطای تعمیمپذیری آن کاهش مییابد.
فرضیه منیفولد و کاهش ابعاد
دادههای با ابعاد بالا، مانند تصاویر یا متون پیچیده، معمولاً بر روی یک زیرفضای کمبعد به نام منیفولد قرار میگیرند. فرض منیفولد بیان میکند که نقاطی که روی یک منیفولد مشترک هستند، دارای ویژگیهای مشابهی بوده و برچسب یکسانی دریافت میکنند. با تمرکز بر این فضای فشرده، مدل میتواند ویژگیهای نامرتبط و نویزها را فیلتر کرده و تنها بر روی مولفههای اثرگذار تمرکز کند.
این رویکرد باعث میشود تا روابط پیچیده در فضای اصلی، در فضای کمبعد به شکل سادهتری قابل تفکیک باشند. الگوریتمهای هوشمند با استفاده از این فرض، ساختار هندسی دادهها را یاد گرفته و از آن برای دستهبندی دقیقتر نمونههای ناشناخته استفاده میکنند.
متدولوژیها و الگوریتمهای پیادهسازی یادگیری نیمه نظارتی
الگوریتمهای یادگیری نیمه نظارتی بر اساس نحوه استخراج اطلاعات از دادههای بدون برچسب و استراتژی ترکیب آنها با دادههای برچسبدار به دستههای فنی مختلفی تقسیم میشوند. انتخاب هر یک از این متدولوژیها به ساختار توزیع داده، ابعاد فضای ویژگی و میزان تداخل کلاسها بستگی دارد. فرآیند پیادهسازی در این مدلها معمولا بر پایه تکرار و بهبود تدریجی مرزهای تصمیمگیری شکل میگیرد.
- خودآموزی (Self-Training): این روش سادهترین شکل پیادهسازی است که در آن یک مدل پایه (Base Learner) ابتدا با دادههای برچسبدار آموزش میبیند. در مرحله بعد، مدل برای تخمین برچسب دادههای خام استفاده میشود و نمونههایی که با اطمینان بالا پیشبینی شدهاند، به عنوان دادههای آموزشی جدید (Pseudo-labels) وارد چرخه یادگیری میشوند تا مدل در تکرارهای بعدی تقویت شود.
- یادگیری مشترک (Co-Training): این متدولوژی زمانی کاربرد دارد که ویژگیهای داده را بتوان به دو زیرمجموعه مستقل و کافی تقسیم کرد. دو مدل مجزا روی هر یک از این مجموعهها آموزش میبینند و هر کدام نمونههای بدون برچسبی را که با دقت بالا شناسایی کردهاند، برای آموزش در اختیار مدل مقابل قرار میدهند تا دانش میان دو نمای مختلف داده مبادله شود.
- منظمسازی ثبات (Consistency Regularization): این رویکرد بر پایه این اصل استوار است که اگر به یک ورودی بدون برچسب، نویز کوچکی اضافه شود، خروجی مدل نباید تغییر معناداری داشته باشد. در پیادهسازی این روش، مدل تلاش میکند فاصله بین پیشبینیهای مربوط به نسخه اصلی و نسخه تغییر یافته داده را به حداقل برساند تا نسبت به تغییرات جزئی مقاوم شود.
- شبکههای متخاصم نیمه نظارتی (S-GANs): در این معماری، بخش تشخیصدهنده (Discriminator) به گونهای تغییر مییابد که به جای تشخیص صرف بین داده واقعی و جعلی، وظیفه طبقهبندی کلاسهای مختلف را نیز بر عهده بگیرد. این کار باعث میشود مدل از دادههای بدون برچسب برای درک بهتر ساختار زیربنایی و ویژگیهای بصری یا متنی استفاده کند.
- مدلهای مبتنی بر گراف (Graph-based Methods): این الگوریتمها دادهها را به عنوان گرههایی در یک گراف در نظر میگیرند که یالهای بین آنها نشاندهنده میزان شباهت است. در فرآیند پیادهسازی، برچسبها از گرههای دارای هویت به سمت گرههای همسایه که ویژگیهای مشابهی دارند جریان مییابند تا خوشههای طبیعی دادهها شناسایی شوند.
- یادگیری انتقالی (Transductive Learning): برخلاف مدلهای استقرایی که به دنبال یافتن یک قانون کلی برای تمام دادههای آینده هستند، روشهای انتقالی مستقیما بر روی پیشبینی برچسب برای همان مجموعه دادههای بدون برچسب موجود تمرکز میکنند. این متدولوژی در سناریوهایی که مجموعه داده ثابت است و نیاز به تعمیم به دادههای خارج از محیط فعلی وجود ندارد، کارایی بالایی دارد.
تفاوت یادگیری نیمه نظارتی با یادگیری خودنظارتی
یادگیری خودنظارتی برچسبهای آموزشی را از ساختار درونی خودِ دادهها استخراج میکند. در این روش، مدل با انجام وظایف بهانهای مانند پیشبینی بخشهای حذف شده تصویر یا کلمات غایب در متن، ویژگیهای داده را میآموزد. یادگیری نیمه نظارتی برخلاف این الگو، برای شروع فرآیند آموزش و تعریف صحیح کلاسها، همواره به وجود یک هسته کوچک از دادههای برچسبگذاری شده توسط انسان وابسته است.
در یادگیری خودنظارتی، حقیقت پایه از دلِ نمونههای بدون برچسب به دست میآید و نیازی به نظارت خارجی نیست. در مقابل، یادگیری نیمه نظارتی برای هدایت دقیق مدل و جلوگیری از انحراف در تشخیص مرزها، به دانش متخصص تکیه میکند. متدهای خودنظارتی بیشتر برای یادگیری بازنمایی در حجم عظیمی از دادههای خام کاربرد دارند. یادگیری نیمه نظارتی این بازنماییها را با دادههای برچسبدار ترکیب میکند تا عملکرد مدل در وظایف نهایی بهبود یابد.
هدف اصلی در یادگیری خودنظارتی، درک منطق زیربنایی و ساختار داده بدون دخالت انسانی است. یادگیری نیمه نظارتی اما با استفاده از برچسبهای محدود، تلاش میکند مرزهای تصمیمگیری را در نواحی کمتراکم فضای ویژگیها اصلاح کند. به همین دلیل، متدهای خودنظارتی اغلب به عنوان یک مرحله پیشآموزش در پروژههای یادگیری نیمه نظارتی بزرگمقیاس مورد استفاده قرار میگیرند.
مزایا و چالشهای پیادهسازی مدل
پیادهسازی مدلهای نیمهنظارتی امکان بهرهبرداری حداکثری از دادههای خام را در کنار تعداد محدودی نمونه برچسبدار فراهم میکند. این رویکرد تعادلی فنی میان هزینه جمعآوری داده و قدرت تعمیمپذیری مدل برقرار میکند که در پروژههای مقیاسبزرگ کارایی بالایی دارد. با این حال، تکیه بر دادههای بدون برچسب ریسکهای محاسباتی و خطاهای احتمالی در پیشبینی را نیز به همراه دارد.
| جنبه پیادهسازی | مزایای عملیاتی | چالشهای فنی |
|---|---|---|
| مدیریت منابع و هزینه | کاهش چشمگیر هزینههای مالی و زمانی مربوط به استخدام متخصص برای برچسبگذاری دستی دادهها. | نیاز به زیرساختهای محاسباتی قویتر برای پردازش حجم انبوه دادههای بدون برچسب در طول آموزش. |
| عملکرد و دقت | بهبود مرزهای تصمیمگیری و افزایش دقت مدل در مواجهه با دادههای خارج از توزیع آموزشی اولیه. | احتمال کاهش کارایی مدل در صورت عدم انطباق توزیع دادههای بدون برچسب با دادههای برچسبدار (Class Mismatch). |
| اعتبار برچسبها | استخراج الگوهای پنهان از دادههای خام که به طور معمول در یادگیری نظارتی نادیده گرفته میشوند. | انباشت و انتشار خطا (Error Propagation) ناشی از تولید برچسبهای کاذب اشتباه توسط خود مدل. |
| پایداری ریاضی | تقویت فرضیات هندسی دادهها و ایجاد مدلهای مقاومتر در برابر نویزهای جزئی ورودی. | حساسیت بالا به پارامترهای تنظیمکننده (Hyperparameters) و احتمال ناپایداری در فرآیند همگرایی مدل. |
گزینش این روش به نسبت دادههای موجود و حساسیت خروجی نهایی بستگی دارد. ارزیابی دقیق توازن میان این فاکتورها، موفقیت مدل را در محیطهای عملیاتی تضمین میکند. استفاده هوشمندانه از این مزایا میتواند محدودیتهای رایج در کمبود دادههای باکیفیت را به طور کامل مرتفع سازد.
سوالات متداول درباره یادگیری نیمه نظارتی
یادگیری نیمه نظارتی دقیقا چه تفاوتی با یادگیری نظارتی دارد؟
در یادگیری نظارتی تمام دادهها باید برچسبگذاری شده باشند، اما در یادگیری نیمه نظارتی تنها بخش کوچکی از دادهها برچسبدار هستند و مدل از حجم زیادی داده بدون برچسب برای بهبود دقت و تعمیمپذیری استفاده میکند.
چه زمانی باید از یادگیری نیمه نظارتی استفاده کنیم؟
زمانی که حجم زیادی داده خام در اختیار دارید اما برچسبگذاری آنها پرهزینه، زمانبر یا نیازمند تخصص بالا است، استفاده از یادگیری نیمه نظارتی گزینهای بهینه و اقتصادی محسوب میشود.
آیا یادگیری نیمه نظارتی همیشه دقت مدل را افزایش میدهد؟
خیر. اگر توزیع دادههای بدون برچسب با دادههای برچسبدار همخوانی نداشته باشد یا مدل برچسبهای اشتباه تولید کند، ممکن است خطا افزایش یابد. تنظیم صحیح پارامترها و اعتبارسنجی دقیق ضروری است.
تفاوت یادگیری نیمه نظارتی با یادگیری خودنظارتی چیست؟
در یادگیری خودنظارتی مدل برچسبها را از ساختار داخلی داده استخراج میکند، اما در یادگیری نیمه نظارتی وجود مقدار محدودی داده برچسبدار انسانی برای هدایت فرآیند آموزش ضروری است.
آیا یادگیری نیمه نظارتی برای پروژههای صنعتی مناسب است؟
بله. در حوزههایی مانند پزشکی، پردازش تصویر، تحلیل متن و سیستمهای توصیهگر که داده خام فراوان ولی داده برچسبدار محدود است، این روش کاربرد گستردهای دارد.




















