

Outliers دادههایی هستند که تفاوت بسیار زیادی با سایر مقادیر موجود در یک مجموعه داده دارند. این مقادیر میتوانند به دلیل خطاهای اندازهگیری، رویدادهای غیرمعمول یا تغییرات طبیعی در دادهها ایجاد شوند. اگر به درستی مدیریت نشوند، میتوانند بر نتایج تحلیل تأثیر بگذارند و عملکرد مدلهای یادگیری ماشین را کاهش دهند. برای یادگیری اصولی نحوه تشخیص و حذف Outlier ها و مدیریت صحیح این دادههای پرت، شرکت در یک دوره علم داده با پایتون میتواند بسیار کمککننده باشد.
تشخیص و حذف Outlier ها
روشهای مختلفی برای شناسایی و مدیریت Outlier ها در Python وجود دارد. بسته به نوع داده میتوان از روشهای تصویری (Visualization) یا تکنیکهای آماری استفاده کرد. در این بخش از کتابخانههای Pandas و Matplotlib روی مجموعه داده Diabetes dataset که در کتابخانه Scikit-learn موجود است استفاده میکنیم.
تشخیص و حذف Outlier ها با استفاده از Box Plot
یک Box Plot نحوه توزیع دادهها را با استفاده از چارکها نمایش میدهد. هر نقطهای که خارج از خطوط سبیل (whiskers) قرار بگیرد به عنوان Outlier در نظر گرفته میشود. این روش سادهای برای مشاهده محل قرارگیری بیشتر دادهها و شناسایی مقادیر غیرعادی است.
import sklearn
from sklearn.datasets import load_diabetes
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
diabetes = load_diabetes()
column_name = diabetes.feature_names
df_diabetics = pd.DataFrame(diabetes.data, columns=column_name)
sns.boxplot(x=df_diabetics['bmi'])
plt.title('Boxplot of BMI')
plt.show()
خروجی:
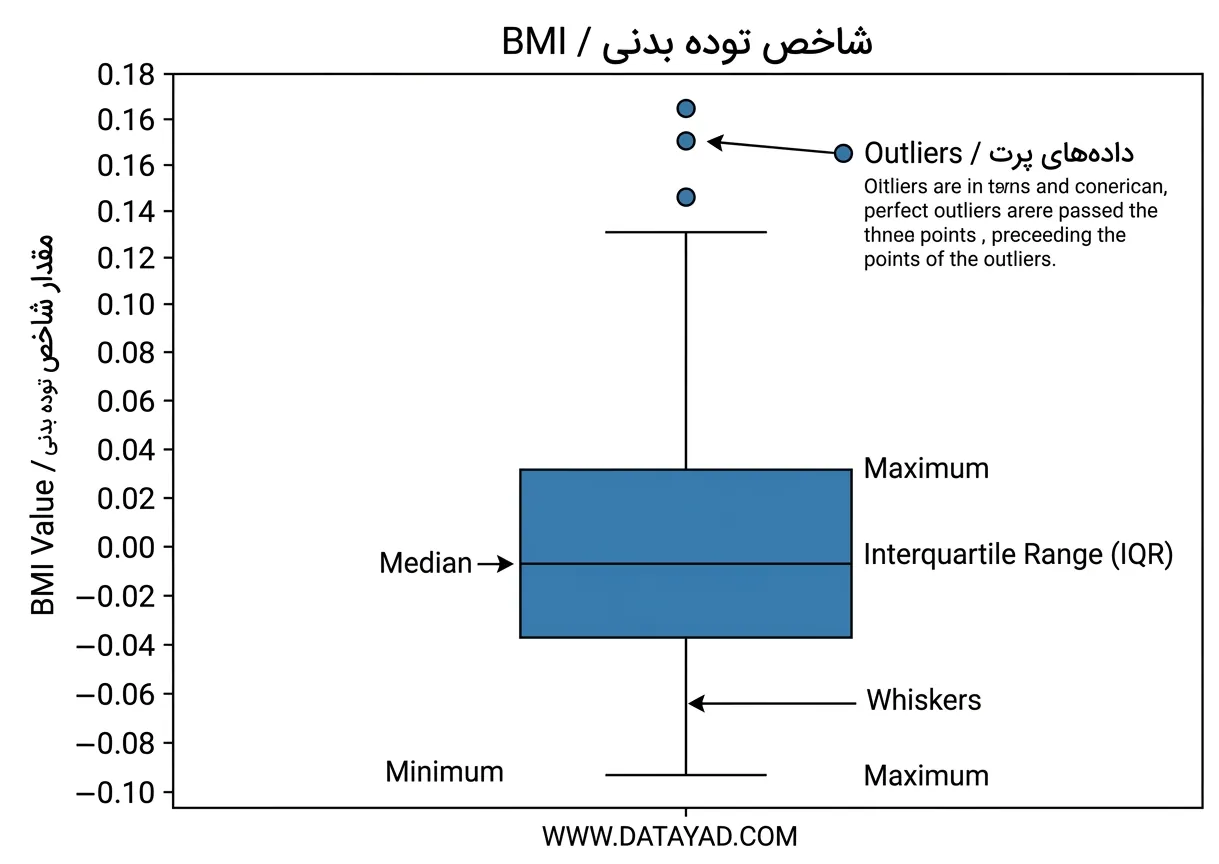
در Box Plot، Outlier ها به صورت نقاطی خارج از whisker ها نمایش داده میشوند. این مقادیر بسیار بزرگتر یا کوچکتر از اکثر دادهها هستند. برای مثال، مقادیر BMI بزرگتر از 0.12 میتوانند به عنوان Outlier در نظر گرفته شوند.
حذف Outlier ها
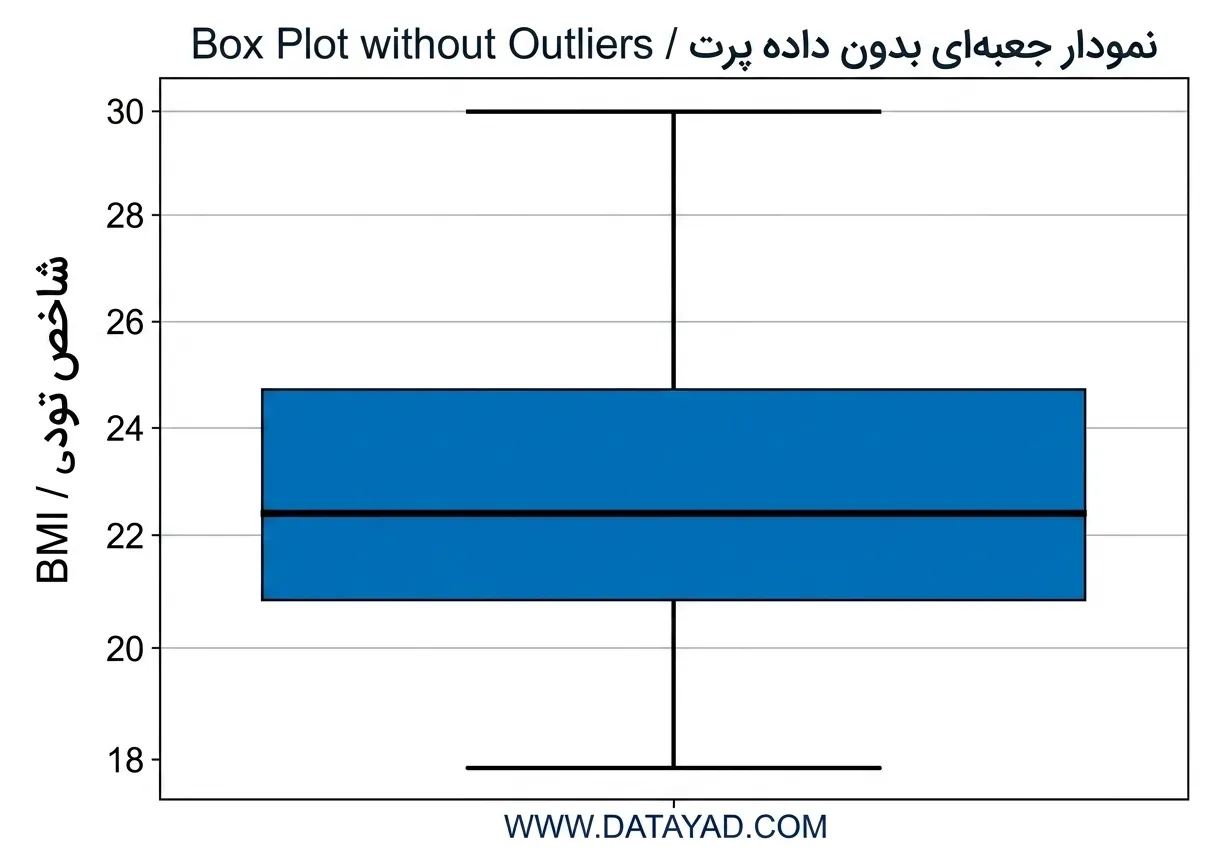
برای حذف Outlier ها میتوان یک مقدار آستانه (threshold) تعریف کرد و دادهها را فیلتر نمود.
def removal_box_plot(df, column, threshold):
removed_outliers = df[df[column] <= threshold]
sns.boxplot(removed_outliers[column])
plt.title(f'Box Plot without Outliers of {column}')
plt.show()
return removed_outliers
threshold_value = 0.12
no_outliers = removal_box_plot(df_diabetics, 'bmi', threshold_value)
خروجی:
تشخیص و حذف Outlier ها با استفاده از Scatter Plot
Scatter Plot رابطه بین دو متغیر را نمایش میدهد. این نمودار زمانی مفید است که با دادههای عددی جفتشده کار میکنیم. در Scatter Plot، Outlier ها به صورت نقاطی ظاهر میشوند که فاصله زیادی از خوشه اصلی دادهها دارند.
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(df_diabetics['bmi'], df_diabetics['bp'])
ax.set_xlabel('BMI')
ax.set_ylabel('Blood Pressure')
plt.title('Scatter Plot of BMI vs Blood Pressure')
plt.show()
خروجی:
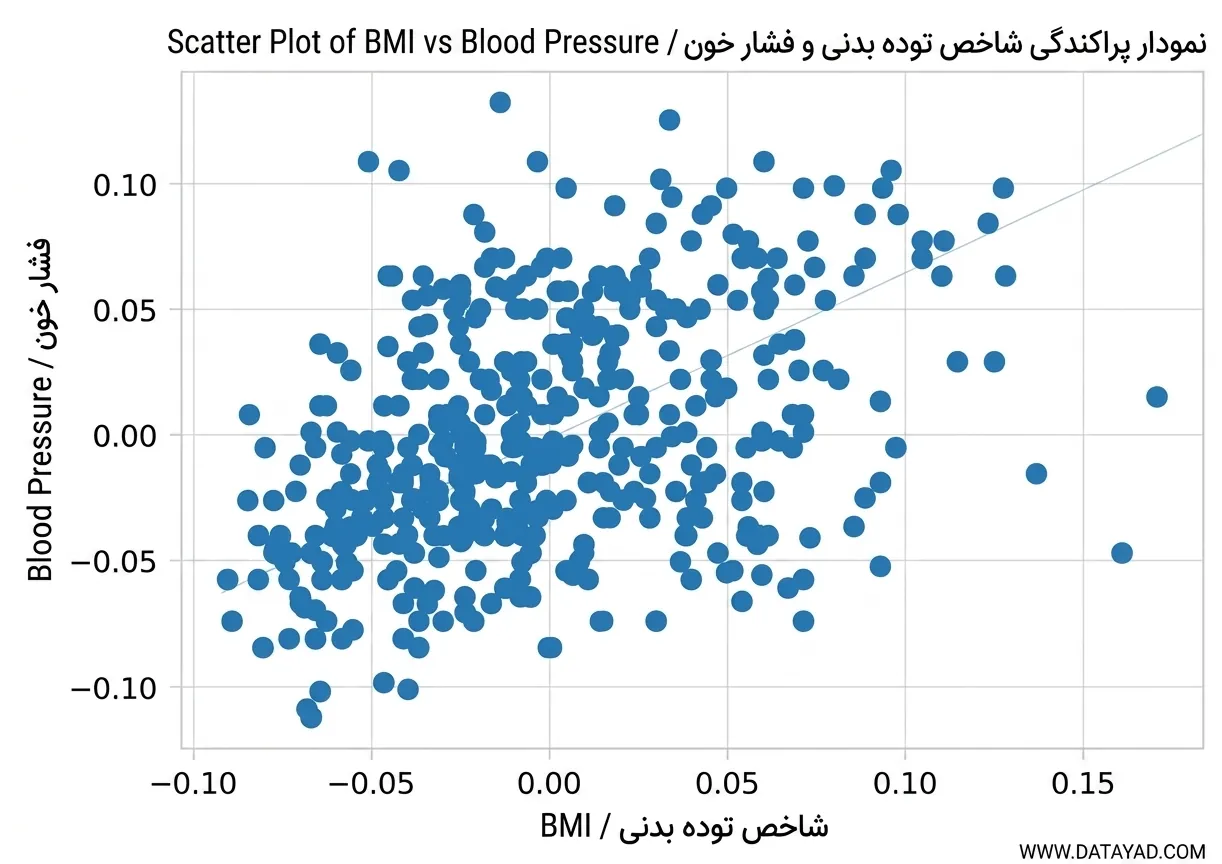
در نمودار مشاهده میشود که بیشتر دادهها در گوشه پایین سمت چپ قرار دارند. اما چند نقطه در گوشه بالا سمت راست دیده میشوند. این نقاط به عنوان Outlier در نظر گرفته میشوند زیرا از خوشه اصلی فاصله دارند.
حذف Outlier ها
np.where(): برای یافتن اندیسهایی که شرط مشخصی برقرار است استفاده میشود.- شرط
(df_diabetics['bmi'] > 0.12) & (df_diabetics['bp'] < 0.8)دادههایی را مشخص میکند که bmi بزرگتر از 0.12 و bp کوچکتر از 0.8 دارند.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
outlier_indices = np.where((df_diabetics['bmi'] > 0.12) & (df_diabetics['bp'] < 0.8))
no_outliers = df_diabetics.drop(outlier_indices[0])
fig, ax_no_outliers = plt.subplots(figsize=(6, 4))
ax_no_outliers.scatter(no_outliers['bmi'], no_outliers['bp'])
ax_no_outliers.set_xlabel('(body mass index of people)')
ax_no_outliers.set_ylabel('(bp of the people )')
plt.show()
خروجی:
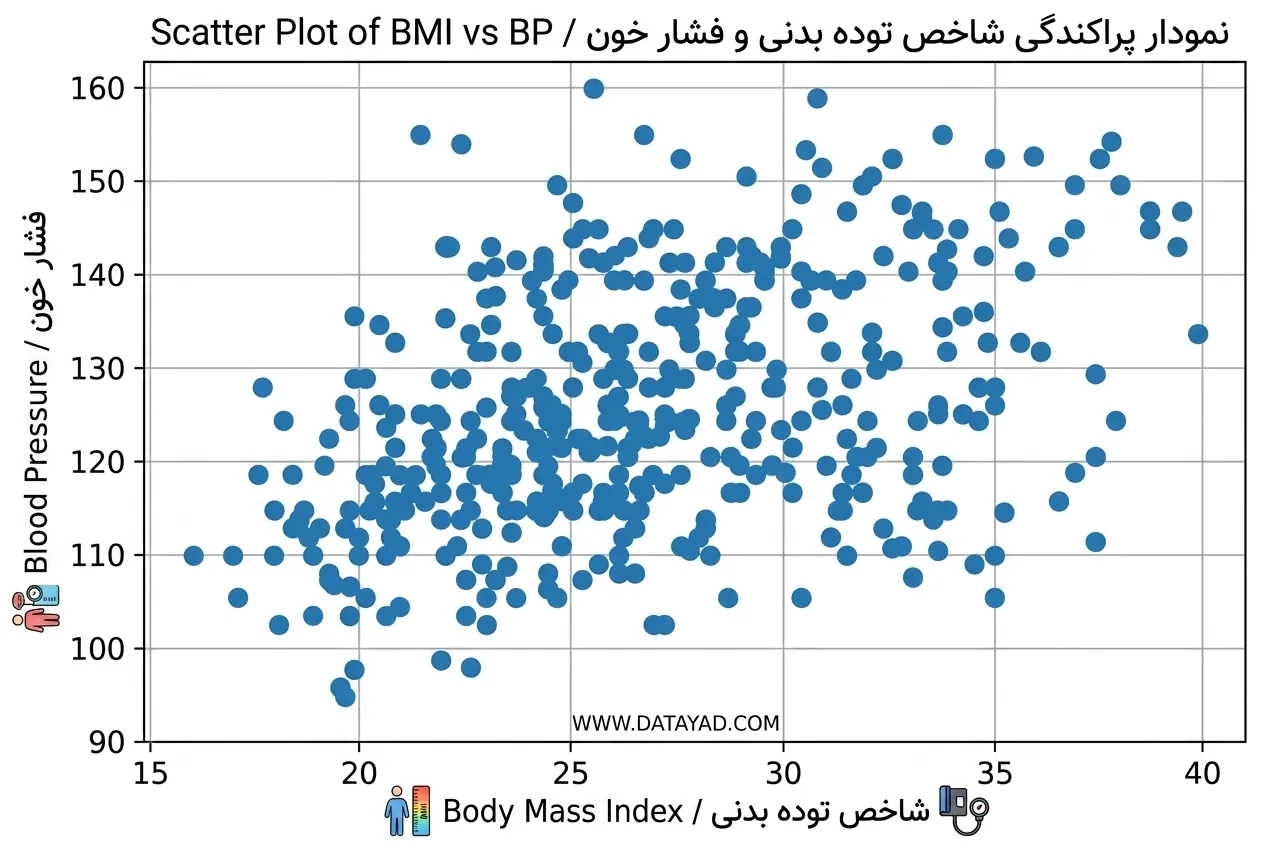
این کد ردیفهایی را حذف میکند که شرایط BMI > 0.12 و BP < 0.8 را داشته باشند؛ شرایطی که از مشاهده بصری نمودار استخراج شدهاند.
روش Z-Score برای تشخیص و حذف Outlier
Z-score که با نام نمره استاندارد نیز شناخته میشود، نشان میدهد یک داده چند انحراف معیار از میانگین فاصله دارد. اگر مقدار Z-score از یک آستانه مشخص بیشتر باشد، آن مقدار به عنوان Outlier در نظر گرفته میشود.
- Z-score برای ستون
'age'درdf_diabeticsمحاسبه میشود. - از تابع
zscore()در SciPy استفاده میشود. - نتیجه
zفاصله هر مقدار از میانگین را بر حسب انحراف معیار نشان میدهد.
from scipy import stats import numpy as np z = np.abs(stats.zscore(df_diabetics['age'])) print(z)
خروجی:
معمولاً آستانه 3.0 در نظر گرفته میشود، زیرا حدود 99.7٪ دادهها در یک توزیع نرمال (Gaussian) در بازه ±3 انحراف معیار از میانگین قرار دارند.

حذف Outlier ها: Trimming و Capping
پس از شناسایی Outlier ها با روش Z-score، دو روش متداول برای مدیریت آنها وجود دارد:
- Trimming: حذف کامل ردیفهای دارای Outlier
- Capping: نگه داشتن ردیفها ولی جایگزینی مقادیر افراطی با یک مقدار حدی مشخصر
Trimming
import numpy as np
threshold_z = 2
outlier_indices = np.where(z > threshold_z)[0]
no_outliers = df_diabetics.drop(outlier_indices)
print("Original DataFrame Shape:", df_diabetics.shape)
print("DataFrame Shape after Removing Outliers:", no_outliers.shape)
خروجی:
Original DataFrame Shape: (442, 10)
DataFrame Shape after Removing Outliers: (426, 10)
Capping Outliers
threshold_z = 2
df_capped = df_diabetics.copy()
df_capped['age'] = np.where(z > threshold_z,
df_diabetics['age'].mean() + threshold_z * df_diabetics['age'].std(),
df_diabetics['age'])
print("Original DataFrame Shape:", df_diabetics.shape)
print("DataFrame Shape after Capping Outliers:", df_capped.shape)
خروجی:
Original DataFrame Shape: (442, 10)
DataFrame Shape after Capping Outliers: (442, 10)
روش Interquartile Range (IQR)
روش IQR (Interquartile Range) یکی از تکنیکهای رایج و قابلاعتماد برای تشخیص Outlier ها است. این روش حتی زمانی که دادهها چولگی (skewed) داشته باشند نیز عملکرد خوبی دارد و مقادیر بسیار افراطی را با استفاده از چارکها (quartiles) شناسایی میکند.
مقدار IQR به صورت اختلاف بین چارک سوم (Q3) و چارک اول (Q1) محاسبه میشود:
IQR = Q3 − Q1
در اینجا مقدار IQR برای ستون 'bmi' در دیتافریم df_diabetics محاسبه میشود. ابتدا مقدار Q1 و Q3 به دست میآید، سپس با محاسبه IQR = Q3 − Q1 میتوان میزان پراکندگی ۵۰٪ میانی دادهها را مشاهده کرد.
Q1 = np.percentile(df_diabetics['bmi'], 25, method='midpoint') Q3 = np.percentile(df_diabetics['bmi'], 75, method='midpoint') IQR = Q3 - Q1 print(IQR)
خروجی:
0.06520763046978838
برای شناسایی Outlier ها، با استفاده از مقدار IQR حد بالا (Upper Bound) و حد پایین (Lower Bound) تعریف میشود. هر مقداری که خارج از این بازه قرار بگیرد به عنوان Outlier در نظر گرفته میشود.
upper = Q3 + 1.5 × IQR
lower = Q1 − 1.5 × IQR
upper = Q3+1.5*IQR
upper_array = np.array(df_diabetics['bmi'] >= upper)
print("Upper Bound:", upper)
print(upper_array.sum())
lower = Q1-1.5*IQR
lower_array = np.array(df_diabetics['bmi'] <= lower)
print("Lower Bound:", lower)
print(lower_array.sum())
حذف Outlier ها: Trimming و Capping
Trimming Outliers
در روش Trimming، ردیفهایی که شامل مقادیر پرت هستند به طور کامل از دیتاست حذف میشوند.
import numpy as np
import sklearn
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
column_name = diabetes.feature_names
df_diabetes = pd.DataFrame(diabetes.data)
df_diabetes.columns = column_name
print("Old Shape:", df_diabetes.shape)
Q1 = df_diabetes['bmi'].quantile(0.25)
Q3 = df_diabetes['bmi'].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
upper_array = np.where(df_diabetes['bmi'] >= upper)[0]
lower_array = np.where(df_diabetes['bmi'] <= lower)[0]
df_diabetes.drop(index=upper_array, inplace=True)
df_diabetes.drop(index=lower_array, inplace=True)
print("New Shape:", df_diabetes.shape)
خروجی:
Old Shape: (442, 10)
New Shape: (439, 10)
Capping Outliers
در روش Capping به جای حذف ردیفها، مقادیر بسیار بزرگ یا بسیار کوچک با حد بالا یا حد پایین جایگزین میشوند.
df_capped = df_diabetes.copy()
df_capped['bmi'] = np.where(df_capped['bmi'] > upper, upper, df_capped['bmi'])
df_capped['bmi'] = np.where(df_capped['bmi'] < lower, lower, df_capped['bmi'])
print("Shape after Capping:", df_capped.shape)
خروجی:
Shape after Capping: (439, 10)
یادگیری اصولی مدیریت دادههای پرت برای تبدیل شدن به متخصص علم داده
تشخیص و حذف Outlier تنها یک تکنیک ساده در تحلیل داده نیست؛ بلکه یکی از مهارتهای پایهای است که هر متخصص علم داده باید به آن مسلط باشد. در پروژههای واقعی علم داده، کیفیت دادهها نقش مستقیمی در دقت مدلهای یادگیری ماشین دارد و اگر Outlier ها بهدرستی شناسایی و مدیریت نشوند، حتی پیشرفتهترین الگوریتمها نیز نتایج قابل اعتمادی ارائه نخواهند داد.
اما تشخیص و مدیریت دادههای پرت فقط یک بخش کوچک از مسیر تبدیل شدن به یک Data Scientist است. یک متخصص علم داده باید مجموعهای از مهارتها مانند تحلیل داده، آمار، یادگیری ماشین، کار با پایتون، پردازش داده و ساخت مدلهای پیشبینی را بهصورت عملی یاد بگیرد.
اگر میخواهید این مهارتها را بهصورت پروژهمحور و کاربردی یاد بگیرید و مسیر تبدیل شدن به یک متخصص علم داده را اصولی شروع کنید، پیشنهاد میکنیم در آموزش متخصص علم داده شرکت کنید. در این دوره از مبانی تحلیل داده تا پیادهسازی مدلهای واقعی یادگیری ماشین را بهصورت مرحلهبهمرحله یاد میگیرید.
اگر هدف شما ورود حرفهای به بازار کار داده و تبدیل شدن به یک Data Scientist است، این دوره میتواند نقطه شروعی جدی برای ساخت مهارتهای موردنیاز شما باشد.




















