

داده پرت (Outliers) دادههایی هستند که بهطور قابلتوجهی با بقیه رکوردهای یک مجموعهداده تفاوت دارند و از الگوی کلی پیروی نمیکنند. این نقاط ممکن است بهدلیل خطاهای اندازهگیری، رویدادهای نادر یا تغییرپذیری طبیعی در دادهها رخ دهند. بهطور کلی، نقاط پرت ویژگیهای زیر را دارند:
بهصورت مقادیر غیرعادیِ بسیار بالا یا بسیار پایین ظاهر میشوند.
میتوانند بر شاخصهای آماری مانند میانگین و واریانس و همچنین عملکرد مدلهای پیشبینی اثر مخرب بگذارند.
با استفاده از روشهای آماری و ابزارهای بصری (مانند نمودار جعبهای یا Boxplot) شناسایی میشوند.
پیش از حذف یا اعمال هرگونه تکنیک جایگزینی، تحلیل دقیق علت بروز آنها بسیار مهم است.
یادگیری تکنیکهای پیشرفته برای شناسایی و مدیریت اصولی این دادههای غیرعادی، یکی از مهارتهای کلیدی در پیشپردازش دادهها است که در آموزش علم داده با پایتون بهطور کامل و عملی به آن پرداخته میشود.
چرا شناخت داده پرت در تحلیل داده اهمیت دارد؟
در بسیاری از پروژههای تحلیل داده، وجود چند مقدار غیرعادی میتواند میانگین، واریانس، نتایج آماری و حتی عملکرد مدلهای یادگیری ماشین را تحت تأثیر قرار دهد. به همین دلیل، بعد از اینکه فهمیدیم داده پرت چیست، باید بدانیم چرا بهوجود میآید، چگونه شناسایی میشود و بهترین روش برخورد با آن چیست. در این مورد یک مقاله جامع با عنوان تشخیص و حذف Outlier ها با استفاده از پایتون در دیتایاد نگارش شده است.
چرا داده پرت (Outliers) رخ میدهند؟
داده پرت میتوانند به دلایل مختلفی ایجاد شوند. شناسایی منشأ آنها برای تحلیل دقیق داده ضروری است.
- خطاهای ورود داده (Data Entry Errors): اشتباهاتی که هنگام وارد کردن دستی داده رخ میدهند میتوانند مقادیر بسیار شدید یا ناسازگار تولید کنند.
- خطاهای اندازهگیری (Measurement Errors): ابزارهای معیوب یا تنظیمات نادرست آزمایش میتوانند باعث ایجاد خوانشهای غیرعادیِ خیلی بالا یا خیلی پایین شوند.
- خطاهای آزمایشی (Experimental Errors): آزمایشهای با طراحی ضعیف ممکن است نتایجی تولید کنند که بهدرستی پدیده زیربنایی را نمایش نمیدهند.
- داده پرت عمدی (Intentional Outliers): گاهی Outliers عمداً وارد داده میشوند؛ مثل موارد تقلب یا دستکاری داده.
- خطاهای پردازش داده (Data Processing Errors): خطا در جمعآوری، پاکسازی یا تبدیل داده میتواند مقادیر غیرمعمول ایجاد کند.
- تغییرات طبیعی (Natural Variation): برخی Outliers بهطور طبیعی و بهعلت تغییرپذیری ذاتی در جامعه/فرایند مورد مطالعه ایجاد میشوند.
چرا حذف داده پرت (Outliers) ضروری است؟
تأثیر بر تحلیل (Impact on Analysis)
- Outliers میتوانند معیارهای آماری مانند میانگین، واریانس و همبستگی را بهشدت دچار اعوجاج کنند و به نتایج سوگیرانه یا گمراهکننده منجر شوند.
- حذف مقادیر بسیار افراطی کمک میکند تحلیل، روند مرکزی و رفتار معمول مجموعهداده را با دقت بیشتری نشان دهد.
اعتبار آماری (Statistical Validity)
- داده پرت میتوانند قابلیت اتکای آزمون فرض را تضعیف کنند و عملکرد مدلهای پیشبینی را کاهش دهند.
- رسیدگی درست به داده پرت، پایداری مدل، دقت، و قابلاعتماد بودن نتیجهگیریهای آماری را بهبود میدهد.
عملکرد و تفسیرپذیری مدل (Model Performance and Interpretability)
- داده پرت ممکن است باعث شوند مدلهای یادگیری ماشین بیشبرازش (Overfit) کنند یا از روی مقادیر نادر و بسیار افراطی، الگوهای نادرست یاد بگیرند.
- حذف Outliers نامرتبط باعث میشود مدلها تفسیرپذیرتر شوند و تعمیمپذیری آنها به دادههای جدید بهتر شود.
انواع داده پرت
داده پرت میتوانند بسته به نحوه انحراف از دادهها و زمینهای که در آن رخ میدهند، به شکلهای مختلفی ظاهر شوند. هر نوع، چالشهای متفاوتی برای شناسایی و تفسیر ایجاد میکند.
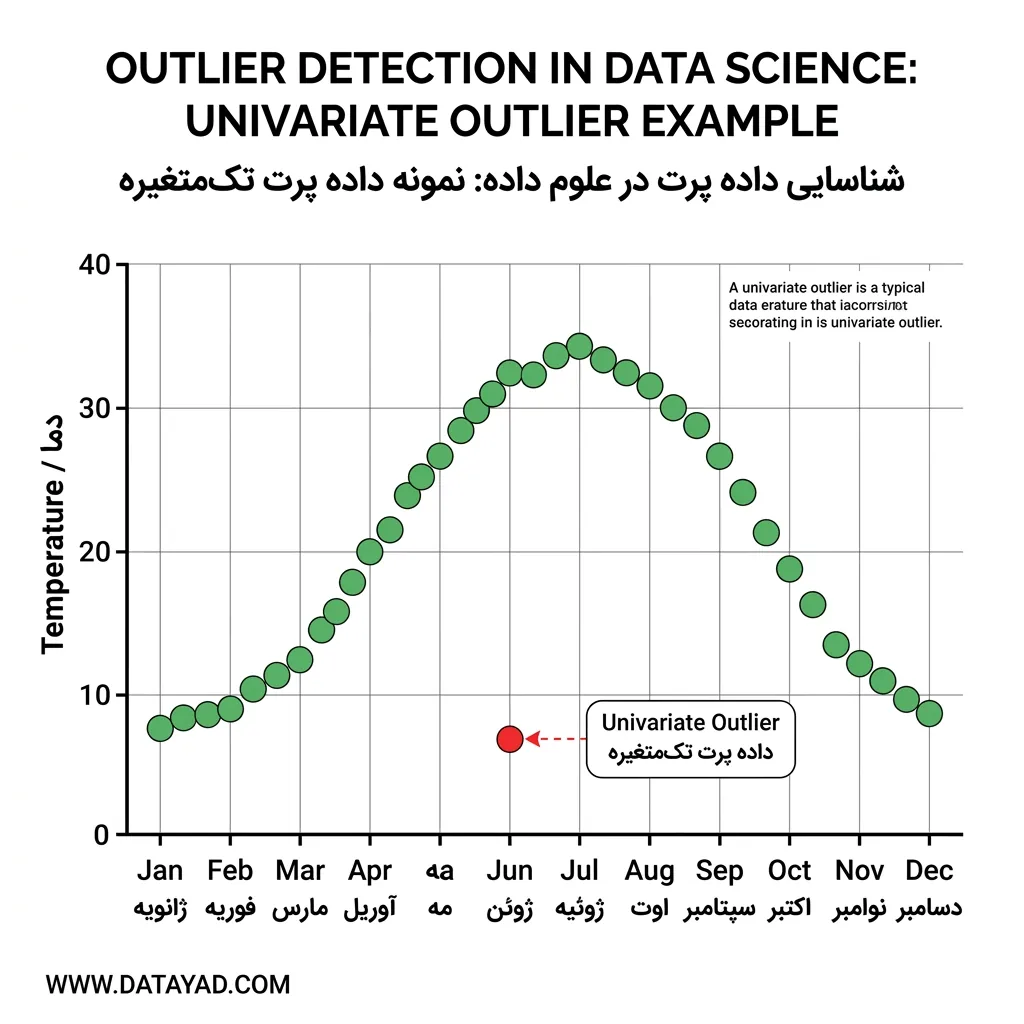
1. داده پرت تکمتغیره (Univariate Outliers)
Outliers تکمتغیره، مقادیر افراطی در یک متغیر هستند که بهطور معنیداری با بقیه دادهها تفاوت دارند.
برای مثال، در یک مجموعهداده از قد بزرگسالان که بیشتر مقادیر آن بین 5.5 تا 6 فوت قرار دارد، قد 7 فوت یک نقطه پرت تکمتغیره در نظر گرفته میشود.
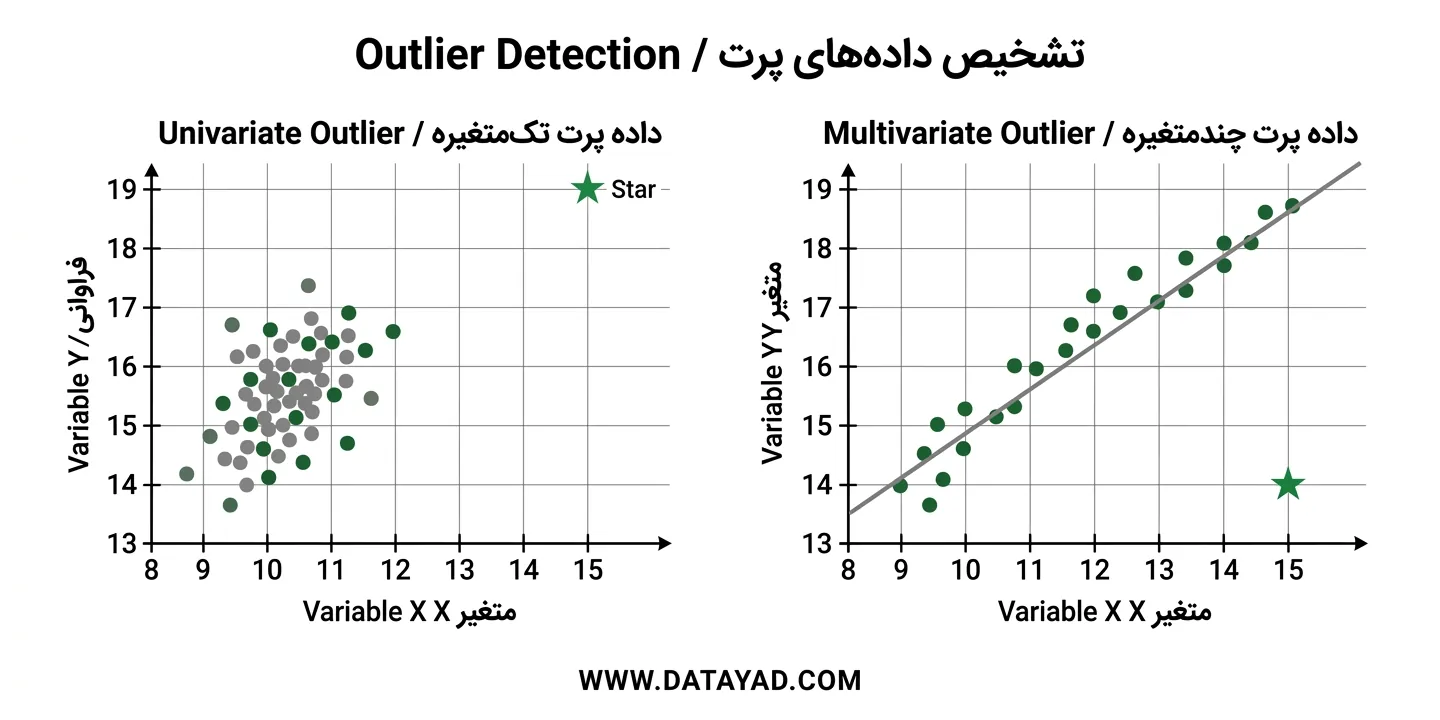
2. داده پرت چندمتغیره (Multivariate Outliers)
داده پرت چندمتغیره شامل ترکیبهای غیرعادی از مقادیر در چند متغیر هستند.
برای نمونه، هنگام تحلیل همزمان قد و وزن، فردی که بهطور استثنایی قدبلند و بهطور غیرمعمول سنگین باشد، ممکن است یک نقطه پرت چندمتغیره محسوب شود؛ حتی اگر هرکدام از این مقادیر بهتنهایی منطقی به نظر برسند.
3. داده پرت نقطهای یا سراسری (Point / Global Outliers)
داده پرت نقطهای که با نام Outliers سراسری نیز شناخته میشوند، نقاط دادهی منفردی هستند که از بیشتر مشاهدات موجود در مجموعهداده فاصله زیادی دارند.
اینها سادهترین نوع داده پرت هستند و معمولاً بیشتر روشهای شناسایی Outliers روی آنها تمرکز دارند.
برای مثال، مصرف بسیار بالای انرژی خانگی در مقایسه با سایر خانوارها میتواند نشاندهنده یک نقطه پرت سراسری باشد.
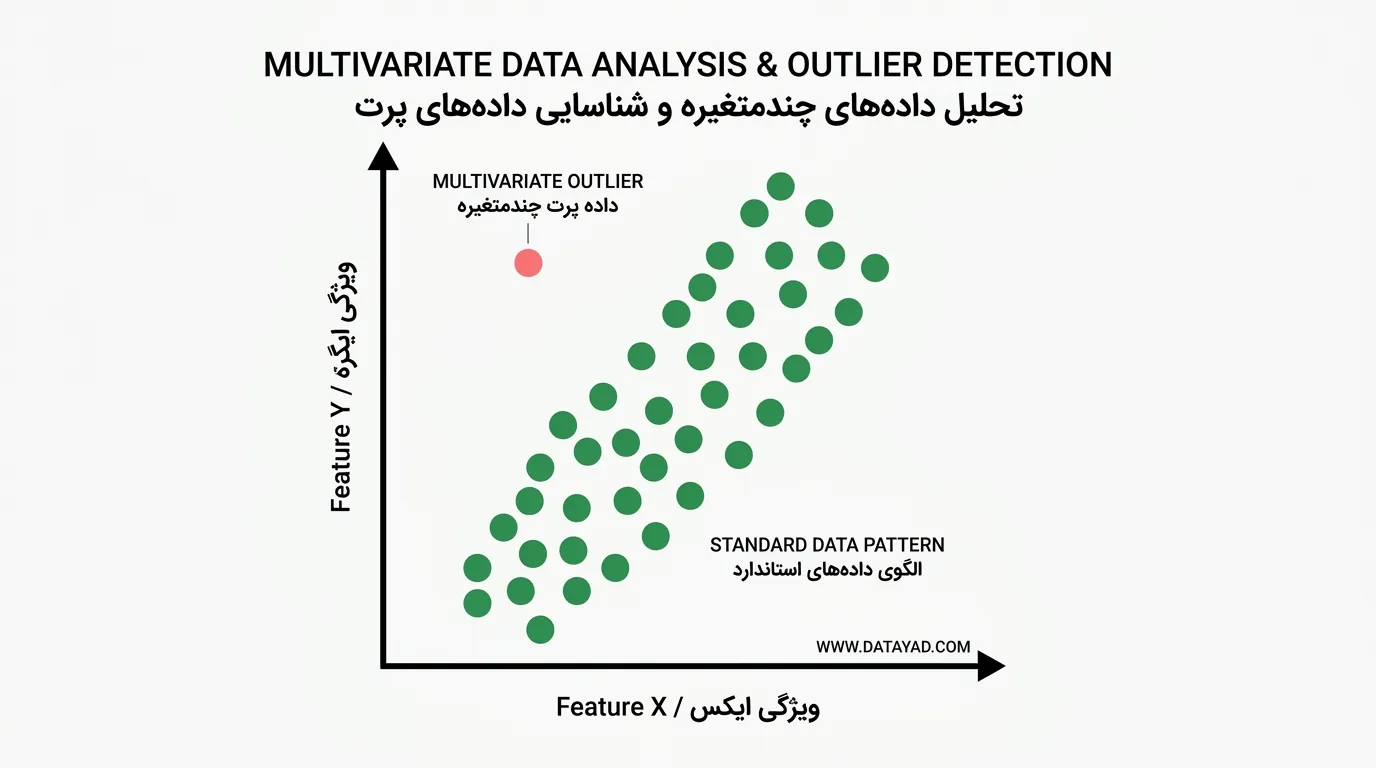
4. داده پرت زمینهای یا شرطی (Contextual / Conditional Outliers)
داده پرت زمینهای، نقاط دادهای هستند که فقط در شرایط یا زمینههای خاص غیرعادی به نظر میرسند.
برای مثال، یک دمای بسیار پایین ممکن است در زمستان طبیعی باشد، اما در تابستان یک نقطه پرت محسوب شود.
این نوع Outliers به ویژگیهای زمینهای مانند زمان، مکان یا شرایط محیطی وابسته هستند.
شناسایی داده پرت زمینهای، هم ویژگیهای زمینهای (مثل فصل، زمان، مکان) و هم ویژگیهای رفتاری (مثل دما، رطوبت، فشار) را در نظر میگیرد. این رویکرد امکان شناسایی منعطفتر و معنادارتر Outliers را در شرایط مختلف فراهم میکند.
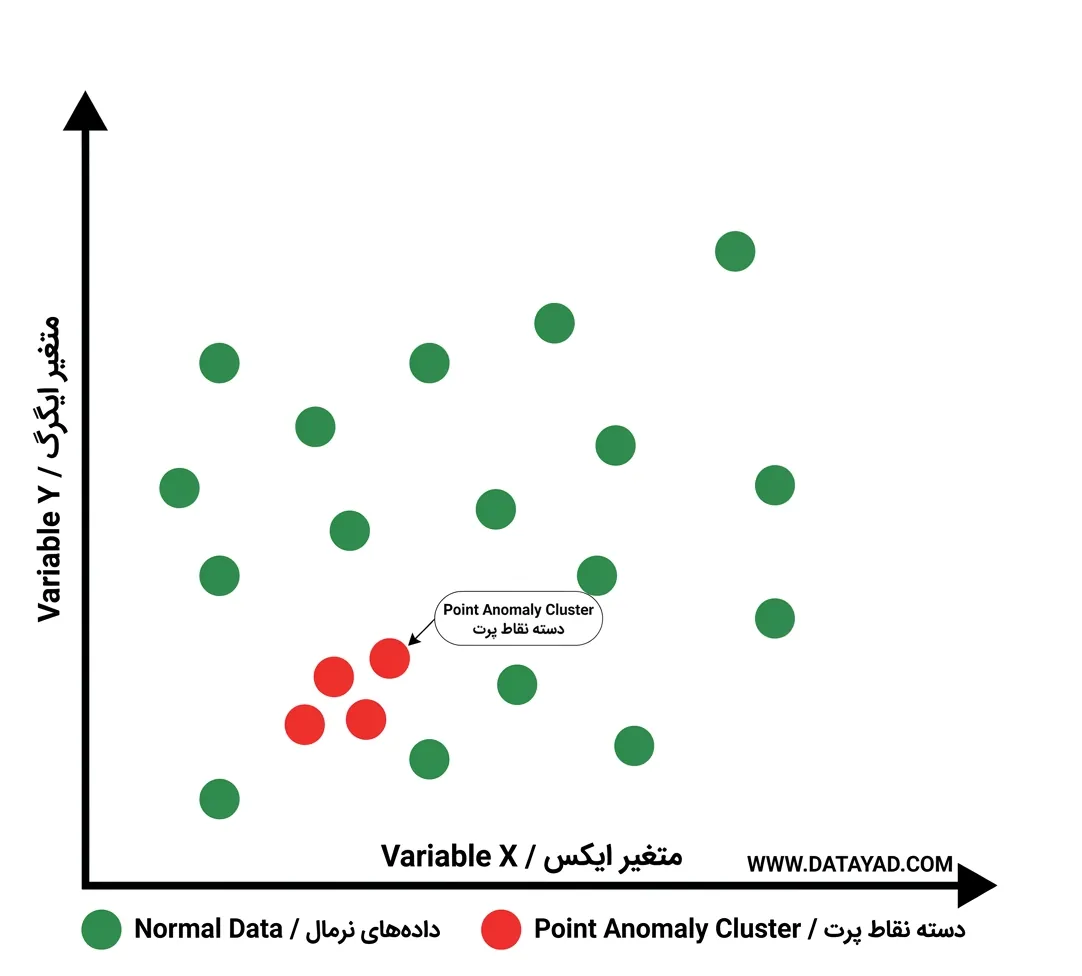
5. داده پرت جمعی (Collective Outliers)
داده پرت جمعی زمانی رخ میدهند که گروهی از نقاط داده در کنار هم از رفتار عادی منحرف شوند، حتی اگر هر نقطه بهصورت جداگانه خیلی افراطی به نظر نرسد.
این نوع معمولاً نشاندهنده تغییر در الگوهای داده یا پدیدههای نوظهور است؛ مانند یک دنباله ناگهانی از فعالیتهای غیرعادی شبکه.
تکنیکهای شناسایی داده پرت
شناسایی Outliers، یک گام ضروری در تحلیل داده است؛ زیرا کمک میکند مشاهدات غیرعادیای که ممکن است بهدلیل خطاهای اندازهگیری، اشتباهات ورود داده یا رویدادهای نادر واقعی ایجاد شده باشند، مشخص شوند. این مقادیر غیرعادی میتوانند بهطور قابلتوجهی بر نتایج آماری و عملکرد مدل اثر بگذارند؛ بنابراین شناسایی آنها پیش از تحلیلهای بعدی اهمیت زیادی دارد.
1. شناسایی داده پرت با استفاده از تکنیکهای بصریسازی
روشهای مبتنی بر بصریسازی، درکی شهودی از توزیع داده فراهم میکنند و به تحلیلگران اجازه میدهند مقادیر افراطی یا غیرعادی را بهراحتی تشخیص دهند.
A. شناسایی داده پرت با استفاده از نمودار جعبهای
نمودارهای جعبهای توزیع یک مجموعهداده را با استفاده از میانه، چارکها و دامنه بین چارکی (IQR) بهصورت بصری خلاصه میکنند. هر نقطه دادهای که بیرون از سبیلها (whiskers) قرار بگیرد — که معمولاً بهصورت 1.5 برابر IQR از چارک اول یا سوم تعریف میشوند — یک نقطه پرت بالقوه در نظر گرفته میشود.
این روش بهویژه برای شناسایی سریع مقادیر افراطی در یک متغیر بسیار مؤثر است.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = {"IQ": [95, 102, 98, 110, 105, 99, 101, 97, 150, 72]}
df = pd.DataFrame(data)
sns.boxplot(x=df["IQ"])
plt.title("Box Plot for IQ Data")
plt.show()
خروجی: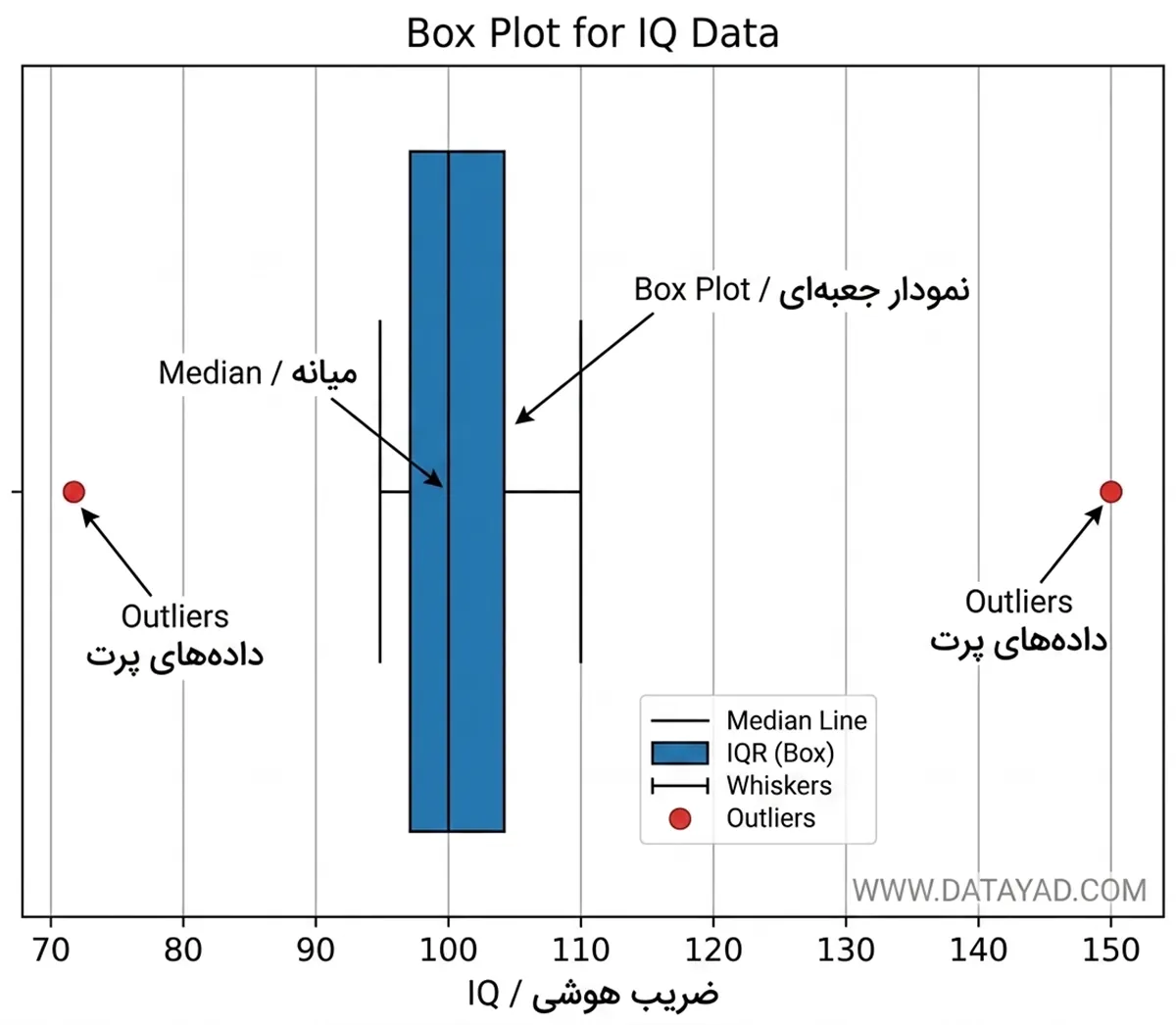
نمودار جعبهای، Outliers را بهصورت نقاطی خارج از سبیلها نشان میدهد؛ بهطوریکه 72 و 150 بهعنوان مقادیر غیرعادی پایین و بالا برای IQ مشخص میشوند.
B. شناسایی داده پرت با استفاده از نمودار پراکنش (Identifying Outliers Using Scatter Plots)
نمودارهای پراکنش ابزارهای مهمی برای شناسایی Outliers در مجموعهدادهها هستند، بهویژه زمانی که بخواهیم رابطه بین دو متغیر پیوسته را بررسی کنیم. در این نمودارها، هر نقطه داده بهصورت یک نقطه روی نمودار رسم میشود و هر محور نماینده یک متغیر است.
در نمودارهای پراکنش، Outliers معمولاً بهصورت نقاطی ظاهر میشوند که نسبت به الگو یا روند کلی موجود در بیشتر نقاط داده، انحراف قابلتوجهی دارند.
plt.scatter(df.index, df["IQ"])
plt.xlabel("Index")
plt.ylabel("IQ")
plt.title("Scatter Plot for IQ Data")
plt.show()
خروجی:
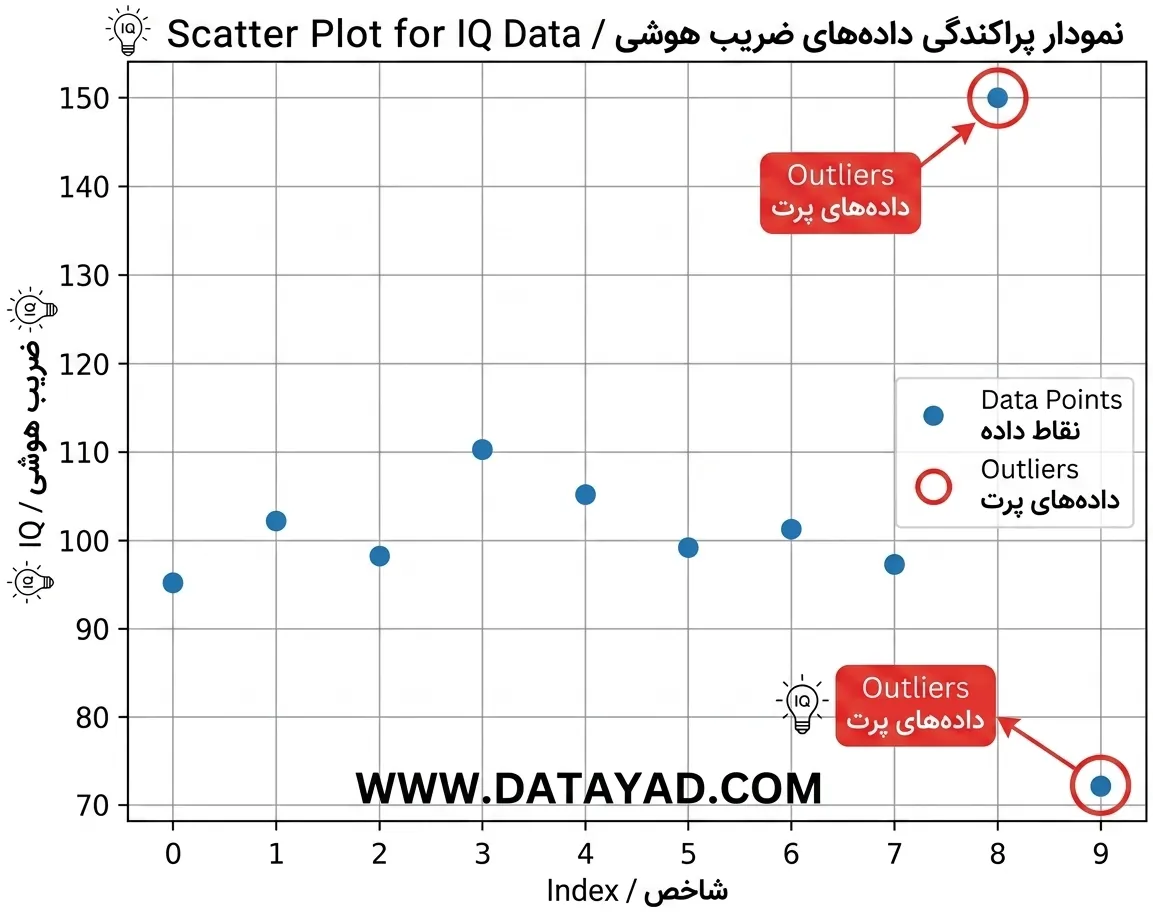
این نمودار پراکنش نشان میدهد که بیشتر مقادیر IQ در بازه 95 تا 110 متمرکز هستند، درحالیکه نقاط نزدیک به 72 و 150 در مقایسه با بقیه دادهها بهوضوح بهعنوان Outliers دیده میشوند.
2. شناسایی داده پرت با استفاده از روشهای آماری
روشهای آماری، Outliers را با اندازهگیری میزان انحراف نقاط داده از توزیع کلی داده و با استفاده از آستانههای ریاضی شناسایی میکنند.
A. شناسایی داده پرت با استفاده از Z-Score
روش Z-score اندازه میگیرد که یک نقطه داده، چند انحراف معیار با میانگین مجموعهداده فاصله دارد. مقادیری که Z-score آنها بزرگتر از +3 یا کوچکتر از -3 باشد، معمولاً بهعنوان نقطه پرت در نظر گرفته میشوند؛ بنابراین این روش برای دادههایی که توزیع نرمال دارند مناسب است.
import pandas as pd
import numpy as np
from scipy.stats import zscore
np.random.seed(0)
normal_iq = np.random.normal(100, 5, 100)
outliers = [30, 250]
iq_data = np.concatenate([normal_iq, outliers])
df = pd.DataFrame({"IQ": iq_data})
df["Z_Score"] = zscore(df["IQ"])
outliers_z = df[np.abs(df["Z_Score"]) > 3]
print(outliers_z)
خروجی:
خروجی نشان میدهد که مقادیر IQ برابر با 30 و 250 فاصله زیادی از میانگین دارند و Z-score آنها از بازه ±3 فراتر رفته است. این موضوع نشان میدهد که این دو مقدار، داده پرت بسیار افراطی هستند و بهطور معنیداری با سایر دادهها تفاوت دارند.
B. شناسایی داده پرت با استفاده از روش IQR
روش IQR داده پرت را بهصورت مقادیری تعریف میکند که کمتر از Q1 − 1.5 × IQR یا بیشتر از Q3 + 1.5 × IQR باشند. از آنجا که این روش فرض نمیکند دادهها دارای توزیع نرمال هستند، روشی مقاوم و پرکاربرد در مجموعهدادههای واقعی است.
Q1 = df["IQ"].quantile(0.25)
Q3 = df["IQ"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers_iqr = df.query("IQ < @lower_bound or IQ > @upper_bound")
print(outliers_iqr)
خروجی:
روش IQR مقادیری را که خارج از بازه مجاز تعیینشده بر اساس چارکها قرار بگیرند، بهعنوان Outliers شناسایی میکند.
C. شناسایی داده پرت با استفاده از DBSCAN
DBSCAN با گروهبندی نواحی متراکم داده و برچسبگذاری نقاطی که به هیچ خوشهای تعلق ندارند بهعنوان نویز (noise)، داده پرت را شناسایی میکند. این رویکرد مبتنی بر چگالی، برای مجموعهدادههایی با شکلهای نامنظم و چگالیهای متفاوت مؤثر است.
from sklearn.cluster import DBSCAN dbscan = DBSCAN(eps=5, min_samples=2) df["Cluster"] = dbscan.fit_predict(df[["IQ"]]) outliers_dbscan = df[df["Cluster"] == -1] print(outliers_dbscan)
خروجی:
این خروجی نشان میدهد که مقادیر IQ برابر با 30 و 250 توسط DBSCAN بهعنوان نویز با برچسب Cluster = -1 مشخص شدهاند.
D. شناسایی داده پرت با استفاده از Isolation Forest
Isolation Forest با ایزولهکردن نقاط داده از طریق درختهای تصمیم تصادفی، Outliers را شناسایی میکند. ناهنجاریها با تعداد تقسیمهای کمتری جدا میشوند؛ زیرا نادر هستند و با دادههای عادی تفاوت دارند. این ویژگی باعث میشود این روش برای مجموعهدادههای بزرگمقیاس و چندبعدی سریع، مقیاسپذیر و مؤثر باشد.
from sklearn.ensemble import IsolationForest iso = IsolationForest(contamination=0.2, random_state=42) df["Outlier"] = iso.fit_predict(df[["IQ"]]) outliers_iso = df[df["Outlier"] == -1] print(outliers_iso)
خروجی:
این خروجی نشان میدهد که Isolation Forest غیرعادیترین مقادیر IQ را بهعنوان نقطه پرت با برچسب Outlier = -1 علامتگذاری میکند؛ زیرا آنها را از توزیع عادی داده جدا میسازد.
میتوانید کد کامل را از اینجا دانلود کنید.
چگونه با داده پرت (Outliers) در داده برخورد کنیم؟
بعد از اینکه داده پرت شناسایی شدند، مرحله بعد این است که تصمیم بگیریم چطور با آنها برخورد کنیم. رویکرد مناسب به علت ایجاد آوتلایر، اندازه دیتاست و هدف تحلیل بستگی دارد. راهکارهای رایج شامل موارد زیر است:
حذف (Removal / Trimming)
- اگر Outliers بهوضوح خطا باشند یا برای تحلیل نامرتبط باشند، میتوان آنها را کامل حذف کرد.
- باید دقت کرد؛ چون حذف تعداد زیادی نقطه میتواند توزیع داده را تحریف کند و نمایندگیپذیری (representativeness) دیتاست را کاهش دهد.
- این روش بیشتر برای دیتاستهای بزرگ مناسب است؛ جایی که تعداد کمی مقدار افراطی، اثر معنیداری روی نتیجه کلی نگذارند.
سقفگذاری یا کفگذاری (Capping or Flooring / Quantile-Based Treatment)
- میتوان Outliersرا با حد بالا و حد پایین جایگزین کرد.
- مقادیر بالاتر از حد بالا سقفگذاری میشوند و مقادیر پایینتر از حد پایین کفگذاری میشوند.
- این روش باعث میشود همه نقاط داده حفظ شوند، اما اثرگذاری مقادیر افراطی کاهش پیدا کند.
- مناسب برای ویژگیهای عددی با توزیعهای دُمبلند (long-tailed).
جایگزینی با میانگین/میانه (Mean/Median Imputation)
- میتوان Outliers را با یک معیار مرکزی مثل میانگین یا میانه جایگزین کرد.
- معمولاً میانه ترجیح داده میشود، چون نسبت به میانگین کمتر تحت تأثیر مقادیر افراطی قرار میگیرد.
- این روش اندازه دیتاست را ثابت نگه میدارد و در عین حال اثر Outliers را کم میکند.
- مناسب برای دیتاستهایی که داده پرت در آنها کم هستند و احتمالاً به دلیل خطا ایجاد شدهاند.
تبدیل (Transformation)
تبدیل داده میتواند اثر مقادیر افراطی را کاهش دهد. تبدیلهای رایج شامل:
- تبدیل لگاریتمی (Logarithmic transformation): وقتی داده چندین مرتبه بزرگی (orders of magnitude) را پوشش میدهد مفید است.
- تبدیل باکس-کاکس (Box-Cox transformation): دادههای چوله (skewed) را به توزیعی نزدیکتر به نرمال تبدیل میکند.
این روش زمانی مفید است که حفظ همه نقاط داده مهم باشد، اما لازم باشد نفوذ/اثر آنها کنترل و تعدیل شود.
برای یادگیری کامل مدیریت داده پرت، بعد از این چه چیزهایی باید یاد بگیرید؟
شناسایی و مدیریت Outliers فقط یکی از مهارتهای ضروری در مسیر تحلیل داده و ساخت مدلهای دقیق است. اگر میخواهید بهصورت حرفهای در حوزه داده فعالیت کنید، باید در کنار Outliers، مباحث مهم دیگری مثل پاکسازی داده، تحلیل اکتشافی داده، آمار، مصورسازی، Feature Engineering، یادگیری ماشین و ارزیابی مدلها را هم یاد بگیرید.
اگر هدفتان این است که این مهارتها را بهصورت پروژهمحور و کاربردی یاد بگیرید و به یک متخصص واقعی در حوزه دیتا تبدیل شوید، پیشنهاد میکنیم از مسیر جامع و اصولی آموزش متخصص علم داده شروع کنید. در این آموزش، علاوه بر مفاهیم مهمی مثل Outliers، با تمام مهارتهای لازم برای ورود حرفهای به دنیای علم داده آشنا میشوید.
سوالات متداول
داده پرت (Outlier) چیست؟
داده پرت به مقداری گفته میشود که فاصله قابلتوجهی با الگوی کلی دادهها دارد و در مقایسه با سایر رکوردها غیرعادی به نظر میرسد.
آیا همیشه باید Outliers را حذف کنیم؟
خیر. حذف داده پرت همیشه بهترین تصمیم نیست. ابتدا باید مشخص شود که این مقدار غیرعادی ناشی از خطا است یا یک رویداد واقعی و مهم در دادهها را نشان میدهد.
بهترین روش شناسایی داده پرت چیست؟
بهترین روش به نوع داده و هدف تحلیل بستگی دارد. برای دادههای ساده، روشهایی مثل Boxplot، IQR و Z-Score مناسب هستند و برای دادههای پیچیدهتر میتوان از DBSCAN یا Isolation Forest استفاده کرد.
تفاوت روش IQR و Z-Score در شناسایی Outliers چیست؟
روش Z-Score بر پایه میانگین و انحراف معیار است و معمولاً برای دادههایی با توزیع نرمال مناسبتر است. روش IQR به چارکها متکی است و برای دادههای واقعی و توزیعهای غیرنرمال مقاومت بیشتری دارد.
داده پرت چه تأثیری بر مدلهای یادگیری ماشین دارد؟
Outliers میتواند باعث کاهش دقت مدل، افزایش خطا، ایجاد بیشبرازش و کاهش تفسیرپذیری نتایج شود؛ به همین دلیل مدیریت درست آن در پیشپردازش داده اهمیت زیادی دارد.
بعد از شناسایی داده پرت، چه کارهایی میتوان انجام داد؟
بسته به شرایط، میتوان Outliers را حذف کرد، سقفگذاری یا کفگذاری انجام داد، آن را با میانگین یا میانه جایگزین کرد یا از تبدیلهایی مثل لگاریتم و Box-Cox استفاده کرد.




















