

شبکههای عصبی کانولوشنی سنتی (CNN) معمولاً در وظایف تشخیص اشیا با چالش مواجه میشوند؛ بهویژه زمانی که چندین شیء با اندازهها و موقعیتهای متفاوت در یک تصویر وجود داشته باشد. یک روش brute-force مانند اعمال پنجره لغزان روی تصویر برای تشخیص اشیا، از نظر محاسباتی بسیار پرهزینه است؛ زیرا با افزایش تعداد و تنوع اشیا، مقیاسپذیری مناسبی ندارد.
برای غلبه بر این چالشها، R-CNN که مخفف Regions with CNN features است، معرفی شد که در این مطلب از بخش آموزش هوش مصنوعی به بررسی آن میپردازیم. R-CNN رویکردی هوشمندانهتر ارائه میدهد که در آن از الگوریتم Selective Search برای تولید حدود 2000 ناحیه پیشنهادی از یک تصویر استفاده میشود. این نواحی بهاحتمال زیاد شامل اشیا هستند و بهصورت جداگانه پردازش میشوند تا فرایند تشخیص و مکانیابی اشیا با کارایی بیشتری انجام شود. R-CNN یک پیشرفت مهم در حوزه تشخیص اشیا بهشمار میرود و پایهای برای مدلهای سریعتر و دقیقتر تشخیص اشیا ایجاد کرد.
مدل R-CNN در هوش مصنوعی و بینایی کامپیوتر چه جایگاهی دارد؟
در دنیای هوش مصنوعی، یکی از مهمترین چالشها درک محتوای تصویر و شناسایی دقیق اشیای موجود در آن است. این مسئله در حوزه بینایی کامپیوتر اهمیت ویژهای دارد؛ زیرا مدل باید بتواند علاوه بر تشخیص نوع شیء، محل قرارگیری آن را نیز در تصویر مشخص کند.
R-CNN یکی از اولین معماریهای مهمی بود که توانست با ترکیب ناحیههای پیشنهادی و شبکههای عصبی کانولوشنی، تشخیص اشیا را با دقت بالاتری انجام دهد و مسیر توسعه مدلهای پیشرفتهتر این حوزه را هموار کند.
مدل R-CNN چگونه کار میکند؟
نحوه کار R-CNN
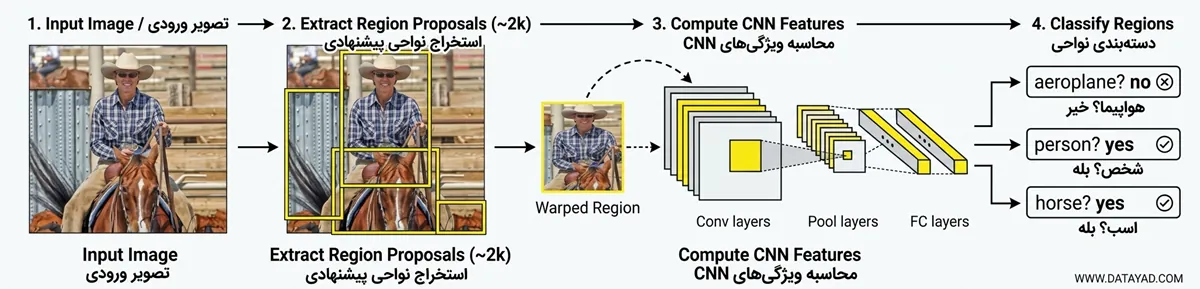
- تصویر ورودی: کار با یک تصویر ورودی آغاز میشود که شامل یک یا چند شیء است.
- تولید ناحیههای پیشنهادی: از الگوریتم Selective Search برای تولید حدود 2000 ناحیه پیشنهادی (مکانهای احتمالی اشیا) استفاده میشود.
- تغییر اندازه و استخراج ویژگی: هر ناحیه پیشنهادی برش داده شده و به یک اندازه ثابت resize / warp میشود. سپس هر ناحیه از یک شبکه عصبی کانولوشنی استاندارد (CNN) عبور داده میشود تا بردارهای ویژگی استخراج شوند.
- دستهبندی ناحیه: از ویژگیهای استخراجشده برای دستهبندی هر ناحیه با استفاده از SVMها در دستههای شیء (برای مثال انسان یا خودرو) یا پسزمینه استفاده میشود.
ویژگیهای کلیدی R-CNN
1. ناحیههای پیشنهادی
R-CNN کار را با تولید ناحیههای پیشنهادی آغاز میکند؛ این ناحیهها بخشهای کوچکتری از تصویر هستند که ممکن است اشیایی را که بهدنبال آنها هستیم در خود داشته باشند. این الگوریتم از روشی به نام Selective Search استفاده میکند؛ یک رویکرد حریصانه که برای هر تصویر تقریباً 2000 ناحیه پیشنهادی تولید میکند. Selective Search بهطور مؤثر بین تعداد ناحیههای پیشنهادی و حفظ بازیابی بالای اشیا تعادل برقرار میکند و به این ترتیب، تشخیص شیء را کارآمدتر میسازد.
با محدود کردن تعداد ناحیههایی که باید با جزئیات تحلیل شوند، این روش عملکرد کلی R-CNN را در تشخیص اشیا درون تصاویر بهبود میدهد.
2. جستوجوی انتخابی (Selective Search)
Selective Search یک الگوریتم حریصانه است که با ترکیب ناحیههای کوچکترِ بخشبندیشده، ناحیههای پیشنهادی تولید میکند. این روش یک تصویر را بهعنوان ورودی میگیرد و ناحیههای پیشنهادیای تولید میکند که برای تشخیص اشیا حیاتی هستند. این روش در مقایسه با تولید تصادفی ناحیههای پیشنهادی، مزیتهای مهمی دارد؛ زیرا تعداد آنها را به حدود 2000 محدود میکند و در عین حال، بازیابی بالای اشیا را حفظ میکند.
مراحل الگوریتم:
- تولید بخشبندی اولیه: الگوریتم با اجرای یک زیربخشبندی اولیه روی تصویر ورودی شروع میکند.
- ترکیب ناحیههای مشابه: سپس بهصورت بازگشتی جعبههای مرزی مشابه را در جعبههای بزرگتر ادغام میکند. شباهتها بر اساس عواملی مانند رنگ، بافت و اندازه ناحیه ارزیابی میشوند.
- تولید ناحیههای پیشنهادی: در نهایت، از این جعبههای مرزی بزرگتر برای ایجاد ناحیههای پیشنهادی جهت تشخیص شیء استفاده میشود.
الگوریتم Selective Search روشی کارآمد برای شناسایی ناحیههای بالقوه اشیا فراهم میکند و اثربخشی کلی فرایند تشخیص را افزایش میدهد.
3. آمادهسازی ورودی در R-CNN
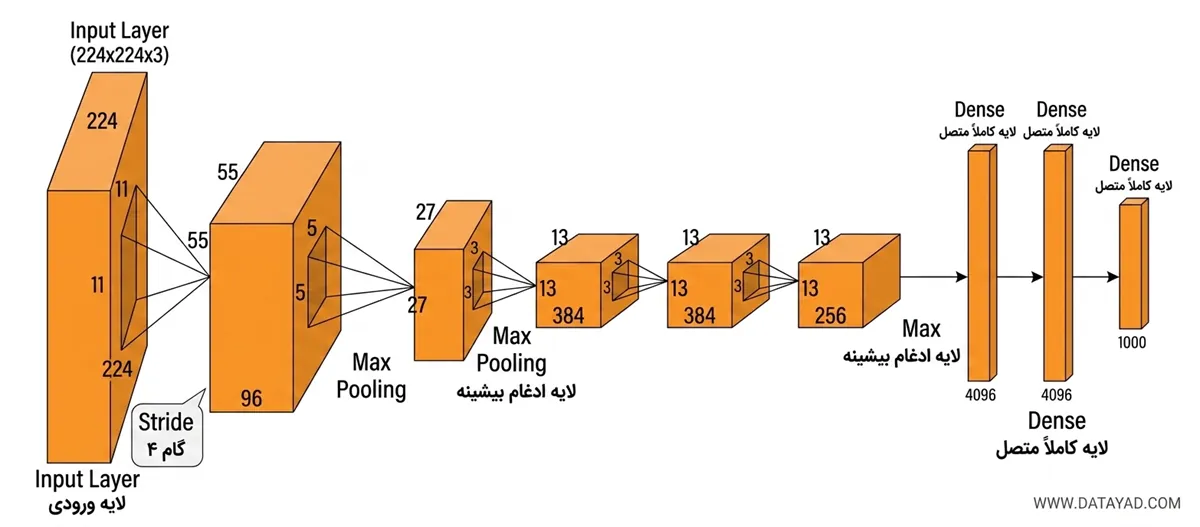
پس از تولید ناحیههای پیشنهادی، این ناحیهها به شکل مربع یکنواخت warp میشوند تا با ابعاد ورودی موردنیاز مدل CNN مطابقت داشته باشند. در اینجا از مدل از پیش آموزشدیده AlexNet استفاده میشود که در آن زمان، بهعنوان پیشرفتهترین CNN برای طبقهبندی تصویر در نظر گرفته میشد.
اندازه ورودی AlexNet برابر (227, 227, 3) است؛ به این معنا که هر تصویر ورودی باید به این ابعاد resize شود. در نتیجه، چه ناحیههای پیشنهادی کوچک باشند و چه بزرگ، باید متناسب با این اندازه ورودی تنظیم شوند.
از معماری بالا، لایه softmax نهایی حذف میشود تا یک بردار ویژگی با ابعاد (1, 4096) بهدست آید. سپس این بردار ویژگی هم به ماشین بردار پشتیبان (SVM) برای طبقهبندی و هم به رگرسور جعبه مرزی برای مکانیابی بهتر داده میشود.
4. SVM (ماشین بردار پشتیبان)
سپس بردار ویژگی تولیدشده توسط CNN توسط یک ماشین بردار پشتیبان دودویی (SVM) استفاده میشود که برای هر کلاس بهصورت مستقل آموزش داده میشود. این مدل SVM بردار ویژگی تولیدشده توسط معماری CNN قبلی را دریافت میکند و یک امتیاز اطمینان خروجی میدهد که نشان میدهد حضور یک شیء در آن ناحیه چقدر محتمل است.
با این حال، در فرایند آموزش SVM یک چالش وجود دارد: این مدل برای هر کلاس به بردارهای ویژگی AlexNet نیاز دارد. در نتیجه، نمیتوان AlexNet و SVM را بهصورت مستقل و موازی آموزش داد.
5. رگرسور جعبه مرزی
برای مکانیابی دقیق جعبه مرزی در تصویر، از یک مدل رگرسیون خطی نسبت به مقیاس استفاده میشود که با نام bounding box regressor شناخته میشود. برای آموزش این مدل، از جفتهای مقادیر پیشبینیشده و ground truth برای چهار بُعد مکانیابی استفاده میشود:
(x, y, w, h)
در اینجا، x و y مختصات پیکسلی مرکز جعبه مرزی را نشان میدهند، در حالی که w و h بهترتیب نشاندهنده عرض و ارتفاع جعبههای مرزی هستند.
بهینهسازی تشخیص، نتایج مدل R-CNN و تکامل آن
این روش، میانگین دقت متوسط (mAP) نتایج را 3 تا 4 درصد بهبود میدهد.
برای بهینهسازی بیشتر فرایند تشخیص، R-CNN از Non-Maximum Suppression (NMS) استفاده میکند:
- ناحیههای پیشنهادی با امتیاز اطمینان کمتر از یک آستانه (برای مثال 0.5) حذف میشوند.
- برای هر شیء، ناحیهای که بالاترین احتمال را دارد از میان گزینهها انتخاب میشود.
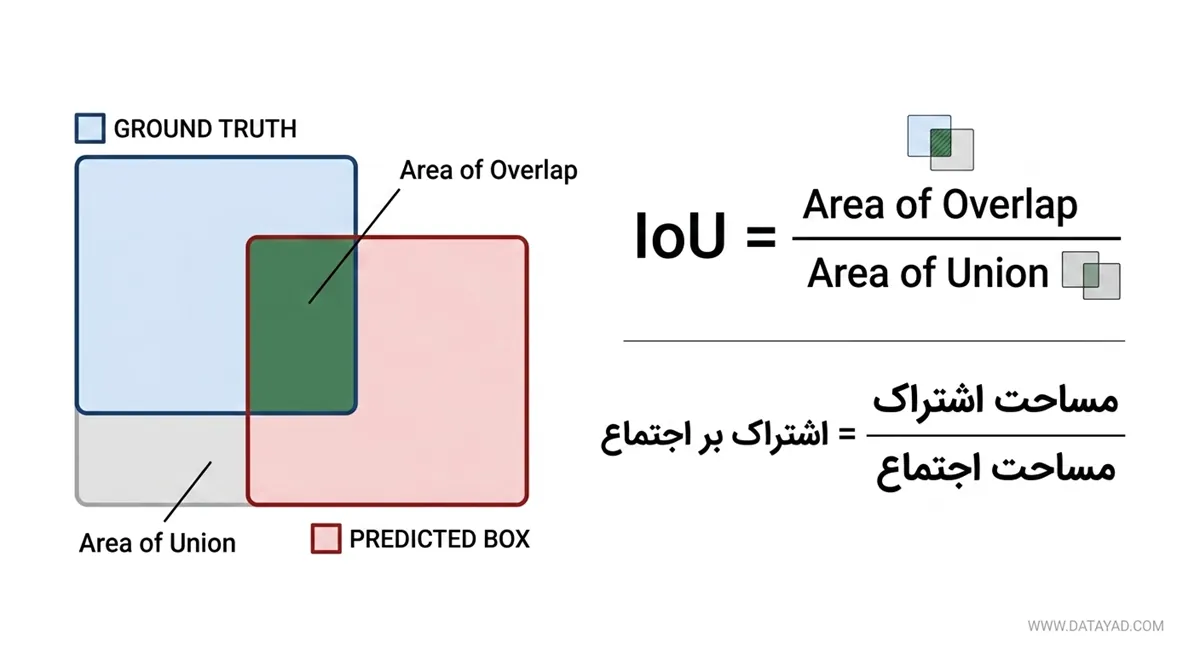
- ناحیههای همپوشان با مقدار IoU (Intersection over Union) بیشتر از 0.5 حذف میشوند تا تشخیصهای تکراری از بین بروند. تعریف IoU بهصورت زیر است:
با ترکیب ناحیههای پیشنهادی، Selective Search، استخراج ویژگی مبتنی بر CNN، طبقهبندی با SVM و اصلاح جعبه مرزی، R-CNN به دقت بالایی در تشخیص اشیا دست پیدا میکند و همین موضوع آن را برای کاربردهای مختلف مناسب میسازد.
پس از آن، میتوان با رسم این جعبههای مرزی روی تصویر ورودی و برچسبگذاری اشیایی که درون این جعبهها حضور دارند، خروجی را بهدست آورد.
نتایج مدل R-CNN
مدل R-CNN روی مجموعهداده VOC 2010 به mAP برابر با 53.7% دست پیدا میکند. همچنین روی مجموعهداده تشخیص شیء ILSVRC 2013 با 200 کلاس، به mAP برابر با 31.4% میرسد که در مقایسه با بهترین نتیجه قبلی یعنی 24.3%، یک بهبود چشمگیر محسوب میشود. با این حال، این معماری برای آموزش بسیار کند است و تولید نتایج آزمون برای یک تصویر واحد از مجموعهداده VOC 2007 حدود 49 ثانیه زمان میبرد.
تکامل R-CNN
پس از معرفی R-CNN، چندین نسخه متفاوت برای رفع محدودیتهای آن ارائه شدند:
1. Fast R-CNN
Fast R-CNN معماری R-CNN را با اشتراکگذاری محاسبات بین ناحیههای پیشنهادی بهینه میکند. بهبودهای کلیدی آن شامل موارد زیر است:
- پردازش تکمرحلهای: بهجای استخراج مستقل ویژگیها برای هر ناحیه پیشنهادی، Fast R-CNN کل تصویر را یکبار از طریق CNN پردازش میکند تا یک feature map تولید شود. سپس ناحیههای پیشنهادی از همین feature map مشترک استخراج میشوند.
- طبقهبند Softmax: بهجای SVM از یک طبقهبند softmax استفاده میکند و این امکان را فراهم میسازد که شبکه بهصورت end-to-end آموزش داده شود.
- رگرسیون بهبودیافته جعبه مرزی: Fast R-CNN فرایند bounding box regression را بهبود میدهد و در نتیجه، دقت مکانیابی بهتر میشود.
2. Faster R-CNN
Faster R-CNN با افزودن یک Region Proposal Network (RPN)، چارچوب R-CNN را یک مرحله جلوتر میبرد. ویژگیهای کلیدی آن عبارتاند از:
- شبکه تولید ناحیه پیشنهادی: RPN مستقیماً از روی feature mapهای تولیدشده توسط CNN، ناحیههای پیشنهادی باکیفیت تولید میکند و نیاز به Selective Search را از بین میبرد.
- اشتراک ویژگیهای کانولوشنی: هم RPN و هم شبکه تشخیص، از ویژگیهای کانولوشنی مشترک استفاده میکنند که باعث کاهش چشمگیر زمان محاسبه میشود.
- سرعت بالاتر: Faster R-CNN به سرعت پردازشی حدود 0.1 ثانیه برای هر تصویر دست پیدا میکند و در عین حال، دقت تشخیص بالایی را حفظ میکند.
3. Mask R-CNN
Mask R-CNN بر پایه Faster R-CNN توسعه داده شد تا مدل را برای انجام instance segmentation نیز گسترش دهد. ویژگیهای کلیدی آن شامل موارد زیر است:
- ماسکهای سگمنتیشن: علاوه بر جعبههای مرزی، Mask R-CNN برای هر شیء شناساییشده یک ماسک سگمنتیشن نیز پیشبینی میکند و در نتیجه، دقت در سطح پیکسل فراهم میشود.
- شبکههای Feature Pyramid (FPN): از FPN استفاده میکند تا عملکرد روی اشیا در مقیاسهای مختلف بهبود پیدا کند و دقت تشخیص برای اشیای کوچک افزایش یابد.
- RoIAlign: این تکنیک جایگزین RoIPooling میشود تا مشکل ناهماهنگی را برطرف کند و استخراج ویژگی بهتری برای هر ناحیه مورد علاقه فراهم شود.
4. Cascade R-CNN
Cascade R-CNN یک چارچوب تشخیص شیء چندمرحلهای را برای بهبود عملکرد تشخیص پیادهسازی میکند. جنبههای کلیدی آن عبارتاند از:
- تشخیص چندمرحلهای: Cascade R-CNN از مجموعهای از آشکارسازها در مراحل مختلف استفاده میکند که بهصورت تدریجی ناحیههای پیشنهادی را اصلاح کرده و دقت مکانیابی را بهبود میدهند.
- بهبود Recall و Precision: این مدل با پرداختن به توازن میان recall و precision در هر مرحله، عملکرد کلی تشخیص را بهویژه روی مجموعهدادههای چالشبرانگیز بهبود میبخشد.
کاربردهای R-CNN
-
خودروهای خودران:
R-CNN در خودرو های خودران میتواند اشیای مختلف موجود در جاده مانند عابران پیاده، سایر وسایل نقلیه و علائم راهنمایی و رانندگی را تشخیص داده و دستهبندی کند و به ناوبری ایمنتر کمک کند.
-
سیستمهای نظارتی:
در کاربردهای امنیتی، R-CNN میتواند با تشخیص و دستهبندی افراد و اشیا بهصورت بلادرنگ، فعالیتهای مشکوک را شناسایی کند.
-
تصویربرداری پزشکی:
R-CNN در کاربردهای پزشکی و تشخیص اشیا برای شناسایی ناهنجاریها در اسکنهای پزشکی استفاده میشود و به تشخیص زودهنگام و درمان کمک میکند.
-
واقعیت افزوده:
R-CNN میتواند تشخیص شیء را در کاربردهای واقعیت افزوده ممکن سازد و با قرار دادن اطلاعات دیجیتال روی دنیای واقعی، تجربه کاربر را بهبود دهد.
چالشهای R-CNN
R-CNN در پیادهسازی خود با چندین چالش مواجه است:
-
الگوریتم Selective Search سختگیر و غیرمنعطف:
الگوریتم Selective Search انعطافپذیر نیست و هیچ فرایند یادگیری در آن وجود ندارد. این سختگیری میتواند به تولید ضعیف ناحیههای پیشنهادی برای تشخیص شیء منجر شود.
-
آموزش زمانبر:
با وجود حدود 2000 ناحیه پیشنهادی کاندید، آموزش شبکه زمانبر میشود. علاوه بر این، چندین مؤلفه باید بهصورت جداگانه آموزش داده شوند؛ از جمله معماری CNN، مدل SVM و رگرسور جعبه مرزی. این فرایند آموزشی چندمرحلهای، پیادهسازی را کند میکند.
-
ناکاراتر برای کاربردهای بلادرنگ:
R-CNN برای کاربردهای بلادرنگ مناسب نیست، زیرا پردازش یک تصویر واحد با رگرسور جعبه مرزی حدود 50 ثانیه زمان میبرد.
-
افزایش نیازمندیهای حافظه:
ذخیرهسازی feature mapها برای تمام ناحیههای پیشنهادی، مقدار حافظه دیسک موردنیاز در فاز آموزش را بهطور قابلتوجهی افزایش میدهد.
برای یادگیری کامل R-CNN و تشخیص اشیا چه چیزهایی باید یاد بگیریم؟
اگر میخواهید R-CNN و مدلهای پیشرفتهتر مانند Fast R-CNN، Faster R-CNN و Mask R-CNN را بهصورت عمیق یاد بگیرید، باید مفاهیمی مانند پردازش تصویر، شبکههای عصبی کانولوشنی، تشخیص اشیا، سگمنتیشن تصویر، استخراج ویژگی و کار با دیتاستهای بینایی را بهصورت اصولی آموزش ببینید.
برای شروع یک مسیر حرفهای و کاربردی، پیشنهاد میکنیم از آموزش جامع پردازش تصویر و بینایی کامپیوتر استفاده کنید تا این مفاهیم را از پایه تا سطح پیشرفته، بهصورت پروژهمحور یاد بگیرید.




















