

در دنیای بینایی کامپیوتر (Computer Vision)، شناسایی اشیاء تنها نیمی از مسیر است؛ اما درک دقیق مرزهای هر شیء، جایی است که جادو اتفاق میافتد. Mask R-CNN یکی از پیشرفتهترین مدلهای بینایی کامپبیوتر است که برای تشخیص اشیاء (Object Detection) و بخشبندی نمونهها (Instance Segmentation) استفاده میشود. این مدل در واقع نسخه تکاملیافتهای از معماری Faster R-CNN است که با اضافه کردن یک شاخه اختصاصی برای پیشبینی «ماسک»، توانایی استخراج پیکسلبهپیکسل اشیاء را پیدا کرده است. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر این مدل و نحوه عملکرد آن میپردازیم.
آشنایی با Mask R-CNN؛ انقلابی در بینایی کامپیوتر
Mask R-CNN یکی از پیشرفتهترین مدلهای هوش مصنوعی در بینایی کامپیوتر است که برای تشخیص اشیاء (Object Detection) و بخشبندی تصاویر (Instance Segmentation) استفاده میشود. این مدل در واقع نسخه تکاملیافتهای از معماری R-CNN و Faster R-CNN است که با اضافه کردن یک شاخه اختصاصی برای پیشبینی «ماسک»، توانایی استخراج جزئیات بسیار دقیق را پیدا کرده است.
قبل از اینکه به عمق مباحث فنی نفوذ کنیم، بیایید نگاهی به ویژگیهای کلیدی این الگوریتم بیندازیم که آن را از سایر مدلها متمایز میکند:
- تشخیص چندمنظوره: همزمان اشیاء را شناسایی کرده و Bounding Boxes آنها را پیشبینی میکند.
- بخشبندی دقیق: برای هر نمونه از اشیاء موجود در تصویر، یک ماسک بخشبندی (Segmentation Mask) در سطح پیکسل تولید میکند.
- معماری FCN: از شبکههای کاملا کانولوشنالی برای پیشبینی ماسک استفاده میکند.
- دقت بالا: مرزهای اشیاء را با دقت بسیار بالایی مشخص میکند.
- کاربرد گسترده: از پزشکی تا خودروهای خودران، در تمامی پروژههای تراز اول دنیا حضور دارد.
Instance Segmentation چیست؟
بخشبندی نمونهها یا Instance Segmentation فرآیندی پیشرفته در بینایی کامپیوتر است که نه تنها اشیاء موجود در تصویر را شناسایی میکند، بلکه هر یک از آنها را به صورت مجزا از یکدیگر تفکیک کرده و با اختصاص دادن ماسکهای پیکسلی منحصربهفرد، مرز دقیق هر شیء را مشخص میکند. برخلاف بخشبندی معنایی (Semantic Segmentation) که همهی اشیاء از یک نوع (مثلاً همهی ماشینها) را با یک رنگ نشان میدهد، در Instance Segmentation هر ماشین به عنوان یک موجودیت (Instance) جداگانه شناسایی میشود.
ویژگیهای کلیدی این فرآیند:
- تشخیص و تفکیک مجزا: هر شیء به صورت کاملاً مستقل شناسایی و بخشبندی میشود.
- طبقهبندی در سطح پیکسل: هر پیکسل متعلق به یک شیء خاص، دستهبندی و برچسبگذاری میشود.
- تولید ماسک اختصاصی: برای هر نمونه (Instance)، یک ماسکِ بخشبندی دقیق تولید میگردد.
- تعیین مرزهای دقیق: مرزها و موقعیت مکانی اشیاء با جزئیات بسیار بالا مشخص میشوند.
- درک عمیقتر از تصویر: این روش به بهبود درک کلی سیستم از محتوای بصری و روابط بین اشیاء کمک شایانی میکند.

نحوه عملکرد Mask R-CNN
الگوریتم Mask R-CNN در واقع معماری دو مرحلهای (Two-stage) مدل Faster R-CNN را گسترش میدهد. تفاوت بنیادی در اینجاست که در مرحله دوم، علاوه بر پیشبینی کلاس شیء و مختصات جعبه (Bounding Box)، یک شاخه موازی برای پیشبینی “ماسک بخشبندی” در سطح پیکسل نیز اضافه شده است. این مدل به طور همزمان سه خروجی اصلی تولید میکند: برچسب کلاس (Class Label)، جعبه محصورکننده (Bounding Box) و ماسک پیکسلی (Segmentation Mask).
فرآیند گامبهگام عملکرد مدل:
- تولید پیشنهادات منطقه (Region Proposals): مدل از یک شبکه پیشنهاد منطقه یا RPN (Region Proposal Network) استفاده میکند. این شبکه تصویر را اسکن کرده و مناطقی که احتمال حضور شیء در آنها بالاست را به عنوان کاندیدا معرفی میکند.
- طبقهبندی و رگرسیون جعبه: برای هر یک از مناطق پیشنهادی، مدل همزمان نوع شیء (مثلاً انسان، ماشین یا صندلی) را تشخیص داده و ابعاد دقیق جعبه محصورکننده را اصلاح میکند.
- شاخه موازی پیشبینی ماسک: برخلاف مدلهای قدیمی، در اینجا یک شاخه موازی وجود دارد که برای هر ناحیه (RoI)، یک ماسک باینری تولید میکند. این شاخه از یک شبکه کاملاً کانولوشنالی (FCN) برای حفظ اطلاعات فضایی استفاده میکند.
- تکنولوژی RoI Align: یکی از نوآوریهای کلیدی Mask R-CNN استفاده از RoI Align به جای RoI Pooling است. این تکنیک باعث میشود همترازی دقیق پیکسلبهپیکسل حفظ شود که برای دقت ماسکهای خروجی حیاتی است.
- خروجی نهایی: در نهایت، سیستم مجموعهای از کلاسها، جعبههای محصورکننده و ماسکهای دقیق پیکسلی را به عنوان نتیجه نهایی ارائه میدهد.
معماری Mask R-CNN
معماری Mask R-CNN در سال ۲۰۱۷ توسط Kaiming He و تیمش به عنوان توسعهای بر مدل Faster R-CNN معرفی شد. هدف اصلی این معماری، اضافه کردن قابلیت بخشبندی نمونهها (Instance Segmentation) به قابلیتهای قبلی یعنی تشخیص شیء و پیشبینی جعبههای محصورکننده (Bounding Box) بود. در این مدل، برای هر شیء شناسایی شده، یک ماسک بخشبندی باینری (Binary Segmentation Mask) نیز تولید میشود.
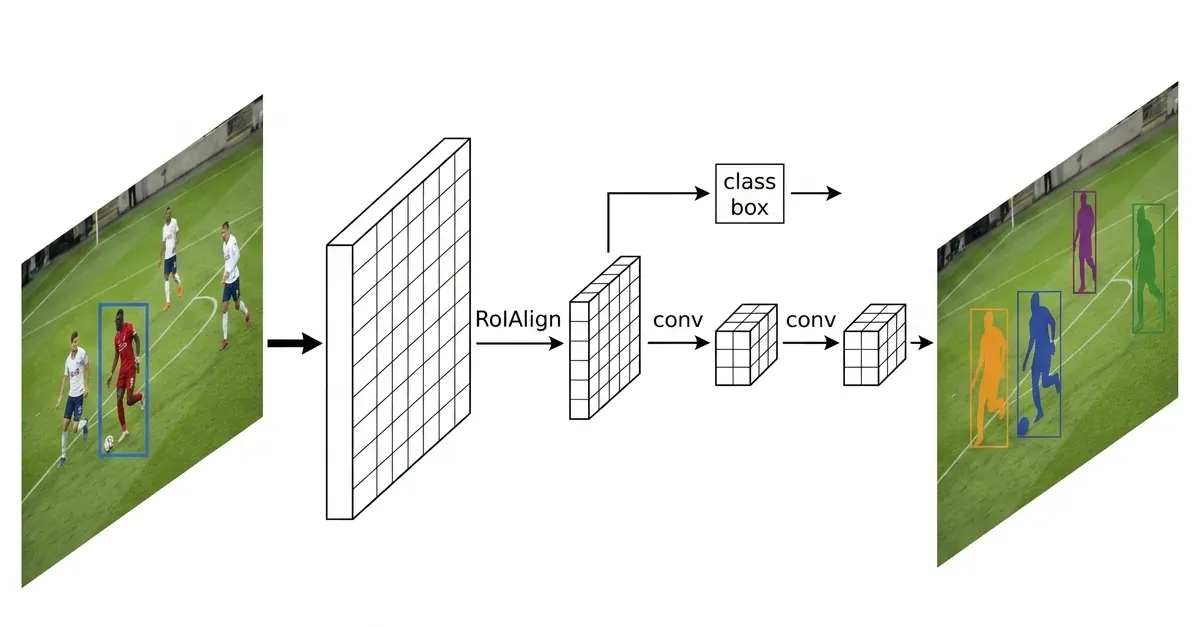
این معماری از ۴ جزء یا کامپوننت اصلی تشکیل شده است که در ادامه به تشریح دقیق هر یک میپردازیم:
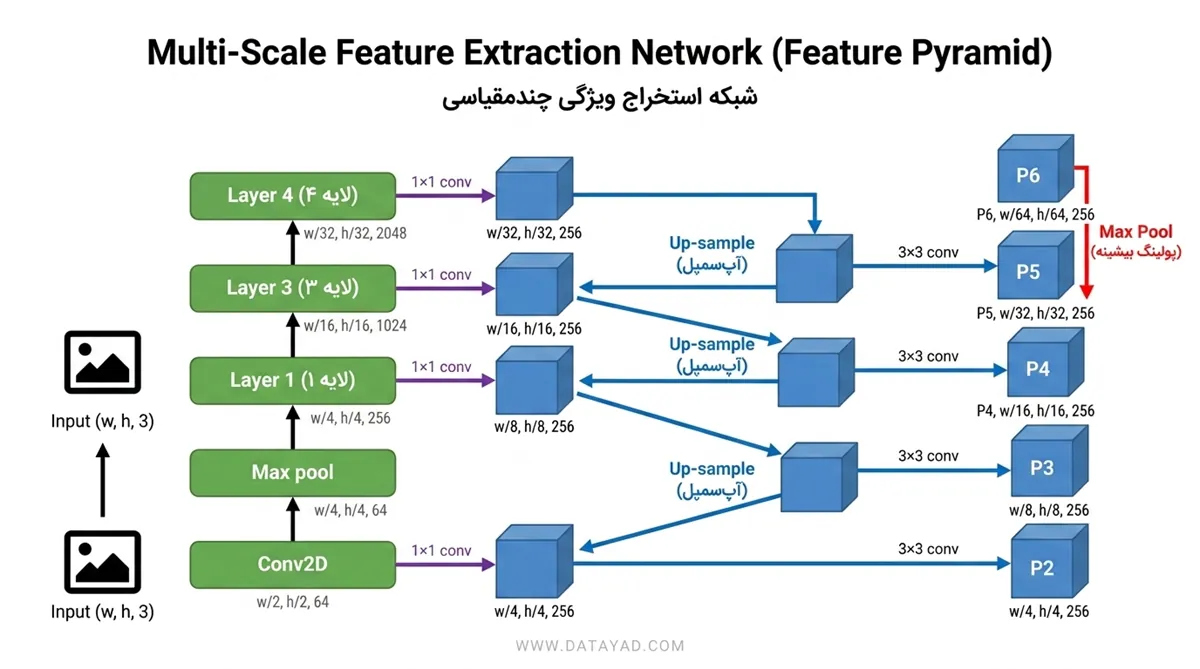
۱. شبکه (Backbone Network)
این بخش وظیفه استخراج نقشههای ویژگی (Feature Maps) از تصویر ورودی را بر عهده دارد.
- معماریهای مورد استفاده: معمولاً از شبکههای عصبی پیچشی عمیق (CNN) مانند ResNet-C4 یا ResNet-FPN استفاده میشود.
- استفاده از FPN: بهرهگیری از Feature Pyramid Network (FPN) باعث میشود مدل در شناسایی اشیاء با مقیاسهای مختلف (بسیار کوچک تا بسیار بزرگ) عملکرد فوقالعادهای داشته باشد.
- تولید نقشههای ویژگی: این شبکه نقشههای ویژگی مختلفی را در سطوح P2, P3, P4, P5 و P6 تولید میکند.
- عملیات کانولوشن: از لایههای کانولوشن ۱×۱ و ۳×۳ برای پردازش بهینه ویژگیها استفاده میکند.
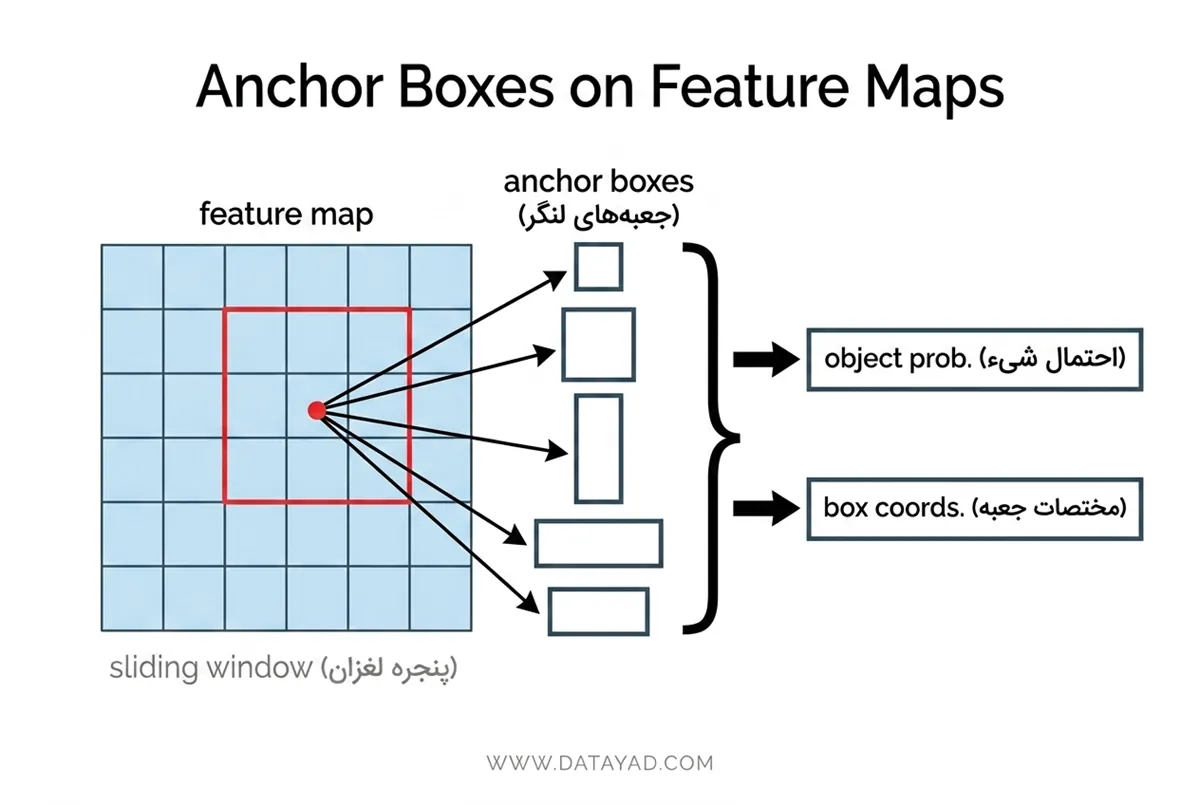
۲. شبکه (Region Proposal Network – RPN)
این شبکه بر روی نقشههای ویژگی استخراج شده توسط Backbone کار میکند تا مناطقی که احتمال حضور شیء در آنها بالاست را پیدا کند.
- استفاده از لایههای ۳×۳: برای تولید پیشنهادات (Proposals) از لایههای کانولوشن ۳×۳ استفاده میکند.
- امتیازدهی (Objectness Scores): برای هر منطقه، یک امتیاز احتمال شیء بودن و مختصات اولیه جعبه را پیشبینی میکند.
- جعبههای لنگر (Anchor Boxes): از لنگرهایی با نسبتهای ابعادی (Aspect Ratios) متفاوت برای شناسایی اشکال مختلف اشیاء استفاده میکند تا هیچ موردی از قلم نیفتد.
۳. بازنمایی ماسک (Mask Representation)
این لایه همان نوآوری اصلی است که شاخه ماسک را به معماری اضافه میکند.
- ساختار FCN: این شاخه از یک شبکه کاملاً کانولوشنالی (Fully Convolutional Network) استفاده میکند تا اطلاعات فضایی (Spatial Information) پیکسلها حفظ شود.
- خروجی m×m: برای هر ناحیه مورد نظر (RoI) و برای هر کلاس، یک ماسک با ابعاد ثابت m×m تولید میکند.
- دقت پیکسلی: به جای استفاده از لایههای Fully Connected که باعث از دست رفتن ساختار فضایی میشوند، FCN اجازه میدهد که پیکسلها به درستی مکانیابی شوند.
۴. لایه RoI Align (نوآوری کلیدی)
در مدلهای قدیمیتر از RoI Pool استفاده میشد که به دلیل “کوانتیزه کردن” (Quantization)، باعث جابهجاییهای کوچک اما مخرب در مرزهای اشیاء میشد. RoI Align این مشکل را حل کرد:
- هدف: تولید نقشههای ویژگی با اندازه ثابت از پیشنهادهای منطقه، بدون از دست دادن دقت مکانی.
- الگوریتم عملکرد: اگر یک نقشه ویژگی با ابعاد h×w داشته باشیم، RoI Align آن را به شبکهای از گریدها با ابعاد M×N تقسیم میکند.
- اجتناب از اعداد صحیح: برخلاف RoI Pool، این متد از مقادیر اعشاری استفاده کرده و با استفاده از درونیابی دوفطی (Bilinear Interpolation)، مقدار دقیق هر پیکسل را محاسبه میکند که منجر به تراز پیکسلی (Pixel-to-pixel alignment) بسیار دقیق میشود.
نکته فنی: سرعت استنتاج (Inference) در این مدل حدود 2 fps (فریم بر ثانیه) است که با توجه به پیچیدگی اضافه شدن شاخه بخشبندی، سرعت بسیار مطلوبی محسوب میشود.
کاربردها، مزایا و محدودیتهای مدل Mask R-CNN
الگوریتم Mask R-CNN به دلیل دقت بسیار بالا در سطح پیکسل، از یک مدل تئوری فراتر رفته و در صنایع استراتژیک مختلفی به کار گرفته شده است. در ادامه، این موارد را بر اساس دادههای فنی بررسی میکنیم:
کاربردهای گسترده
توانایی این مدل در تشخیص همزمان «مکان» و «مرز» اشیاء، آن را برای حوزههای زیر ایدهآل کرده است:
- تخمین ژست انسانی (Human Pose Estimation): تشخیص نقاط کلیدی بدن و بخشبندی اعضای مختلف بدن انسان در تصاویر و ویدیوها.
- خودروهای خودران (Self-driving Cars): شناسایی دقیق اشیاء محیطی، عابران پیاده، خودروهای دیگر و به ویژه تشخیص لاینهای جاده (Lane Detection) برای ناوبری ایمن.
- نقشهبرداری هوایی و پهپادی: تحلیل تصاویر ثبت شده توسط پهپادها برای نقشهبرداری دقیق از اراضی و تحلیل عوارض زمین.
- پزشکی و سلامت: بخشبندی تصاویر پزشکی (مانند MRI یا CT Scan) برای شناسایی تومورها، بافتهای سرطانی و تحلیل دقیق ساختارهای آناتومیک.
- نظارت تصویری (Video Surveillance): ردیابی اشیاء (Object Tracking) و تشخیص رفتارهای مشکوک در سیستمهای امنیتی هوشمند.
- ویرایش تصویر و واقعیت افزوده (AR): جداسازی دقیق سوژه از پسزمینه برای کاربردهای خلاقانه و واقعیت افزوده.
مزایای کلیدی
چرا Mask R-CNN همچنان یکی از محبوبترین انتخابهاست؟
- کاهش هزینههای محاسباتی: نسبت به روشهای جستجوی فراگیر (Exhaustive Search)، این مدل با استفاده از مکانیزم پیشنهاد منطقه (RPN) بسیار بهینهتر عمل میکند.
- انعطافپذیری معماری: این مدل از معماریهای مختلف در بخش ستون فقرات (Backbone) مانند ResNet50 یا ResNet101 پشتیبانی میکند که اجازه میدهد بین سرعت و دقت تعادل برقرار کنید.
- پیشرو در صنعت: در اکثر وظایف مربوط به Instance Segmentation، این مدل همچنان به عنوان یک معیار (Benchmark) برای دقت بالا شناخته میشود.
محدودیتها و چالشها
با وجود قدرت بالا، محدودیتهایی نیز وجود دارد که باید در پروژههای عملیاتی لحاظ شوند:
- نیاز به منابع پردازشی سنگین: برای آموزش و اجرای بهینه، حتماً به پردازندههای گرافیکی قدرتمند (High-end GPUs) نیاز دارد.
- وابستگی به دادههای برچسبگذاری شده: آموزش این مدل به مجموعهدادههایی نیاز دارد که به صورت پیکسلی (Pixel-level annotation) برچسبگذاری شده باشند که تهیه آنها بسیار زمانبر و هزینهبر است.
- سرعت استنتاج: با سرعت تقریبی 2 فریم بر ثانیه (2 fps)، این مدل ممکن است برای کاربردهای “کاملاً آنی” (Real-time) که محدودیت تاخیر (Latency) شدیدی دارند، گزینه اول نباشد.
- پیچیدگی آموزش: فرآیند آموزش و تنظیم پارامترهای آن نسبت به مدلهای سادهتر تشخیص شیء (مانند YOLO)، طولانیتر و پیچیدهتر است.
از تئوری تا پروژههای واقعی: از کجا شروع کنیم؟
اگر میخواهی از سطح توضیحات تئوری Mask R-CNN فراتر بروی و واقعاً بتوانی این مدلها را در پروژههای واقعی پیادهسازی کنی، نقطه شروع درست، یادگیری اصولی آموزش پردازش تصویر و بینایی کامپیوتر است.
در این مسیر آموزشی:
- از مبانی پردازش تصویر شروع میکنیم؛مفاهیمی مثل فیلترها، نویز، آستانهگذاری، تشخیص لبه و… را با مثالهای عملی، تمرینها و مینیپروژهها پیش میبریم.
- قدمبهقدم وارد دنیای شبکههای عصبی کانولوشنی (CNN) و مدلهای پایه بینایی ماشین میشوی.
- در ادامه، به پیشرفتهترین شبکههای بینایی کامپیوتر مثل Faster R-CNN و مدلهای روز میرسیم.
- در بخش پروژههای عملی، روی سناریوهای واقعی کار میکنیم، از جمله:
- پروژههای مرتبط با خودروهای خودران (تشخیص لاین، عابر، خودرو و علائم راهنمایی)
- پروژههای پزشکی (بخشبندی تومور، تحلیل تصاویر MRI/CT و…)
اگر میخواهی این مسیر را به صورت منظم، پروژهمحور و همراه با تمرینهای قابل اجرا طی کنی، حتماً سری به آموزش پردازش تصویر و بینایی کامپیوتر بزن و سرفصلها و ویدیو معرفی دوره را ببین. این دوره دقیقاً برای افرادی طراحی شده که میخواهند از مبانی شروع کنند و به سطح پیادهسازی حرفهای مدلهایی مثل Mask R-CNN برسند.





















