

در دنیای مدرن پردازش زبان طبیعی (NLP)، نمایش کلمات به صورت بردار (Word Embeddings) نقشی حیاتی ایفا میکند. با این حال، مدلهای سنتی مانند Word2Vec معمولاً در مواجهه با کلمات خارج از واژنامه (Out-of-Vocabulary یا OOV) و زبانهایی که از نظر ساختاری و مورفولوژیکی غنی هستند (مانند فارسی یا ترکی)، با چالشهای جدی روبرو میشوند. FastText که توسط تیم تحقیقاتی فیسبوک (Meta AI) توسعه یافته، با معرفی رویکردی مبتنی بر «زیر-کلمه» (Subword-based approach)، این محدودیتها را برطرف کرده است. این مدل نه تنها معنای معنایی را در سطح کاراکترها درک میکند، بلکه کارایی محاسباتی بسیار بالایی نیز دارد. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر این مدل و نحوه عملکرد آن میپردازیم.
چرا به آموزش FastText نیاز داریم؟ ورود به دنیای پردازش متن هوشمند
در دنیای مدرن پردازش زبان طبیعی (NLP)، مدلهای سنتی مانند Word2Vec علیرغم محبوبیت، در مواجهه با کلمات ناآشنا یا زبانهای غنی از نظر ساختاری (مثل فارسی) دچار لکنت میشوند. مدل FastText، که فرزند خلفِ متدولوژیهای فیسبوک است، دقیقاً برای پر کردن همین شکاف طراحی شده است. اگر به دنبال ساخت مدلهایی هستید که نه تنها کلمات، بلکه «ریشه» و «ساختار» آنها را نیز درک کنند، یادگیری و آموزش FastText نقطه عطف مسیر حرفهای شما در حوزه هوش مصنوعی و پردازش متن است. در ادامه، این معماری قدرتمند را از لایههای زیرین تا کدنویسی در پایتون کالبدشکافی میکنیم.

درک معماری و ساختار FastText
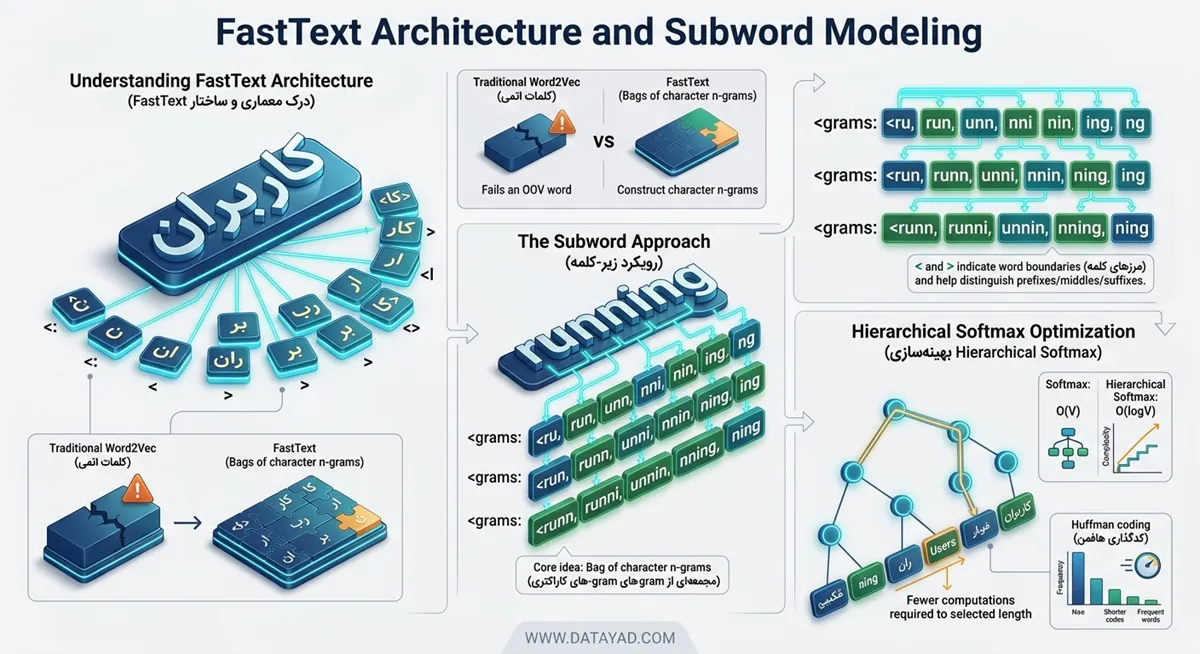
مدل FastText در واقع نسخه تکامل یافته مدلهای Skip-gram و CBOW است، اما با یک تفاوت بنیادین: در FastText، کلمات به جای اینکه به عنوان واحدهای اتمی و تجزیهناپذیر در نظر گرفته شوند، به صورت مجموعهای از n-gramهای کاراکتری (Bags of character n-grams) نمایش داده میشوند. این تغییر رویکرد به مدل اجازه میدهد تا بردارهای کلماتی را که قبلاً در دادههای آموزشی ندیده است، بر اساس اجزای سازنده آنها تولید کند و روابط مورفولوژیکی بین کلمات مشابه را به دقت استخراج نماید.
رویکرد زیر-کلمه (The Subword Approach)
در مدلهای سنتی، هر کلمه یک موجودیت مستقل است. اما FastText کلمات را به قطعات کوچکتر (n-grams) تقسیم میکند. این کار باعث میشود مدل ساختار درونی کلمات را بهتر درک کند.
به عنوان مثال، کلمه “running” را در نظر بگیرید:
- <grams: <ru, run, unn, nni, nin, ing, ng
- <grams: <run, runn, unni, nnin, ning, ing
- <grams: <runn, runni, unnin, nning, ning
علامتهای < و > نشاندهنده مرزهای کلمه هستند که به مدل کمک میکنند تفاوت بین زیر-کلماتی که در ابتدا، وسط یا انتهای کلمه میآیند را تشخیص دهد.
بهینهسازی Hierarchical Softmax
برای افزایش سرعت محاسبات، FastText به جای استفاده از Softmax استاندارد، از Hierarchical Softmax استفاده میکند. در این روش، به جای محاسبه احتمالات برای تکتک کلمات واژنامه، یک درخت باینری (Binary Tree) ساخته میشود که در آن هر برگ نشاندهنده یک کلمه است.
مزایای کلیدی Hierarchical Softmax:
- کاهش پیچیدگی زمانی از به (که V اندازه واژنامه است).
- استفاده از کدگذاری هافمن (Huffman coding) برای دسترسی سریعتر به کلمات پرتکرار.
- حفظ دقت پیشبینی در کنار افزایش چشمگیر سرعت آموزش مدل.
پیادهسازی گامبهگام FastText در پایتون
برای شروع کار با FastText در محیط پایتون، باید مراحل زیر را به ترتیب دنبال کنیم. این کتابخانه به دلیل سرعت بالا و سادگی در استفاده، برای پروژههای مقیاسپذیر بسیار محبوب است.
گام اول: نصب و فراخوانی کتابخانهها
ابتدا باید کتابخانه FastText را نصب کنید. توجه داشته باشید که برای سازگاری کامل، بهتر است از نسخه خاصی از کتابخانه Numpy استفاده کنید.
pip install fasttext pip install numpy==1.24.4
سپس کتابخانههای مورد نیاز را در اسکریپت خود فراخوانی میکنیم:
import fasttext import os
گام دوم: ساخت دادههای آموزشی
در این مرحله، مجموعهای از جملات نمونه درباره موضوعاتی مانند پادشاهی، ورزش و مطالعه ایجاد میکنیم. FastText برای آموزش نیاز دارد که دادهها در یک فایل متنی ذخیره شوند و هر جمله در یک خط جداگانه قرار بگیرد. همچنین نرمالسازی متن (تبدیل به حروف کوچک) به دقت مدل کمک میکند.
def create_sample_data():
# جملات نمونه برای آموزش مدل
sentences = [
"The king rules the kingdom",
"The queen helps the king",
"Running is good exercise",
"The runner runs fast",
"Walking is healthy activity",
"The walker walks slowly",
"Reading books is fun",
"The reader reads daily"
]
# ذخیره در فایل متنی (هر جمله در یک خط)
with open('training_data.txt', 'w') as f:
for sentence in sentences:
f.write(sentence.lower() + '\n') # تبدیل به حروف کوچک برای یکدستی
print("دادههای آموزشی در فایل 'training_data.txt' ساخته شد.")
# اجرای تابع برای ایجاد فایل
create_sample_data()
خروجی:
Training data created in ‘training_data.txt’
گام سوم: آموزش یک مدل پایه FastText
در این بخش، یک مدل unsupervised (بدون نظارت) از نوع skipgram آموزش میدهیم. مدل skipgram تلاش میکند کلمات همسایه (Context) را بر اساس کلمه هدف پیشبینی کند.
def train_simple_model():
# آموزش مدل skipgram
# این مدل بردارهای کلمات را بر اساس محتوای متنی یاد می گیرد
model = fasttext.train_unsupervised(
'training_data.txt', # فایل ورودی
model='skipgram', # نوع معماری
dim=50, # ابعاد بردار کلمات (Embedding Dimension)
epoch=10, # تعداد دفعات تکرار آموزش روی کل داده ها
minCount=1, # حداقل تعداد تکرار کلمه برای دیده شدن
minn=3, # حداقل طول n-gram کاراکتری
maxn=6 # حداکثر طول n-gram کاراکتری
)
# ذخیره مدل آموزش دیده برای استفاده های بعدی
model.save_model('word_vectors.bin')
print("مدل آموزش دیده و با نام 'word_vectors.bin' ذخیره شد.")
return model
# شروع فرآیند آموزش
model = train_simple_model()
خروجی:
Model trained and saved as ‘word_vectors.bin’
گام چهارم: دریافت بردار کلمات (Word Vectors)
در این بخش کدی مینویسیم که بردار یک کلمه موجود در متن (مانند king) و یک کلمه کاملاً جدید که در دادههای آموزشی نبوده (مانند kingdom) را استخراج کند.
def get_word_embeddings(model):
# دریافت بردار کلمه 'king' که در داده های آموزشی وجود داشت
king_vector = model.get_word_vector('king')
print(f"Vector for 'king': {king_vector[:5]}...") # نمایش 5 المان اول بردار
print(f"Vector shape: {king_vector.shape}")
# دریافت بردار کلمه 'kingdom' که یک کلمه OOV (خارج از واژنامه) است
# مدل FastText بر اساس زیر-کلمه های 'king' این بردار را می سازد
kingdom_vector = model.get_word_vector('kingdom')
print(f"Vector for 'kingdom' (OOV): {kingdom_vector[:5]}...")
return king_vector, kingdom_vector
# فراخوانی تابع
king_vec, kingdom_vec = get_word_embeddings(model)
خروجی نمونه:
Vector for ‘king’: [-0.0001826 -0.00033079 0.0004302 0.00088911 -0.00164602]…
Vector shape: (50,)
Vector for ‘kingdom’ (OOV): [ 0.00122273 0.00092931 -0.00018005 -0.00013839 -0.00051276]…
گام پنجم: یافتن کلمات مشابه (Finding Similar Words)
مدل FastText میتواند بر اساس شباهت کسینوسی (Cosine Similarity)، کلماتی که از نظر معنایی یا ساختاری به یک کلمه نزدیک هستند را پیدا کند.
def find_similar_words(model, word, k=3):
print(f"\nWords similar to '{word}':")
try:
# دریافت k همسایه نزدیک
neighbors = model.get_nearest_neighbors(word, k)
for i, (similarity, similar_word) in enumerate(neighbors, 1):
print(f"{i}. {similar_word}: {similarity:.4f}")
except Exception as e:
print(f"Error: {e}")
# تست برای کلمات مختلف
find_similar_words(model, 'king')
find_similar_words(model, 'running')
خروجی نمونه:
Words similar to ‘king’:
- walks: 0.2693
- running: 0.1971
- queen: 0.1912
Words similar to ‘running’:
- runner: 0.4778
- the: 0.3344
- runs: 0.2653
نکته تخصصی: دقت کنید که در مثال بالا، کلمه running با runner و runs شباهت بالایی دارد. این دقیقاً همان قدرت FastText در درک ساختار مورفولوژیکی کلمات است.
گام ششم: آمادهسازی دادههای طبقهبندی
در این مرحله، مجموعهای از نظرات فیلم را به دو دسته مثبت (positive) و منفی (negative) تقسیم کرده و در یک فایل متنی ذخیره میکنیم.
def create_classification_data():
# لیستی از نظرات به همراه برچسب آن ها
reviews = [
("This movie is amazing and fun", "positive"),
("Great acting and story", "positive"),
("Excellent film with good plot", "positive"),
("Wonderful cinematography", "positive"),
("Terrible movie very boring", "negative"),
("Bad acting and poor story", "negative"),
("Worst film ever made", "negative"),
("Boring and predictable plot", "negative")
]
# ذخیره داده ها با فرمت استاندارد FastText (__label__name text)
with open('movie_reviews.txt', 'w') as f:
for text, label in reviews:
f.write(f"__label__{label} {text.lower()}\n")
print("داده های طبقه بندی در فایل 'movie_reviews.txt' ساخته شد.")
# اجرای تابع
create_classification_data()
خروجی:
Classification data created in ‘movie_reviews.txt’
گام هفتم: آموزش مدل طبقهبند (Text Classifier)
اکنون مدل را با استفاده از متد train_supervised آموزش میدهیم. در اینجا از پارامتر wordNgrams استفاده میکنیم که به مدل اجازه میدهد ترکیبات دو کلمهای (Bigrams) را هم ببیند، که برای درک معانی مثل “not good” بسیار حیاتی است.
def train_text_classifier():
# آموزش مدل نظارت شده
classifier = fasttext.train_supervised(
input='movie_reviews.txt',
epoch=25, # تعداد دورهای آموزش
lr=0.1, # نرخ یادگیری (Learning Rate)
wordNgrams=2, # استفاده از ترکیبات دو کلمه ای برای دقت بیشتر
verbose=2
)
# ذخیره مدل برای استفاده در آینده
classifier.save_model('text_classifier.bin')
print("مدل طبقه بند آموزش دیده و ذخیره شد.")
return classifier
# شروع فرآیند آموزش
classifier = train_text_classifier()
گام هشتم: پیشبینی و تحلیل نتایج
پس از آموزش، میتوانیم جملات جدید را به مدل بدهیم تا برچسب و میزان اطمینان (Confidence) خود را اعلام کند.
def test_classifier(classifier):
# جملات جدید برای تست مدل
test_sentences = [
"This is a fantastic movie",
"Boring and terrible film",
"Great story and acting",
"Worst movie I have seen"
]
print("\nنتایج طبقه بندی (Classification Results):")
print("-" * 40)
for sentence in test_sentences:
# پیش بینی برچسب (k=1 یعنی فقط بهترین برچسب را برگردان)
labels, probabilities = classifier.predict(sentence, k=1)
# پاکسازی نام برچسب برای نمایش بهتر
predicted_label = labels[0].replace('__label__', '')
confidence = probabilities[0]
print(f"متن: '{sentence}'")
print(f"پیش بینی: {predicted_label} (میزان اطمینان: {confidence:.4f})\n")
# اجرای تست
test_classifier(classifier)
خروجی نمونه:
Classification Results:
Text: ‘This is a fantastic movie’
Prediction: positive (confidence: 1.0000)
Text: ‘Boring and terrible film’
Prediction: negative (confidence: 1.0000)
چالشها، کاربردها و ارزیابی نهایی FastText
هرچند FastText ابزاری بسیار قدرتمند است، اما مانند هر تکنولوژی دیگری، نکات ظریفی در پیادهسازی و محدودیتهایی در اجرا دارد که باید به آنها توجه کرد.
موارد خاص و چالشهای فنی (Edge Cases)
در هنگام کار با FastText، سه چالش اصلی وجود دارد که میتواند بر کیفیت مدل شما تأثیر بگذارد:
- رمزگذاری کاراکترها (Character Encoding): FastText به شدت به رمزگذاری UTF-8 وابسته است. اگر دادههای آموزشی شما با فرمتهای مختلف (مثل Windows-1252 یا ISO-8859-1) مخلوط شده باشند، فرآیند تولید زیر-کلمهها (n-grams) دچار اختلال شده و بردارهای ناسازگاری تولید میشود. همیشه قبل از آموزش، از یکدستی انکودینگ دادهها اطمینان حاصل کنید.
- بازه بهینه n-gram: انتخاب پارامترهای
minn(حداقل طول n-gram) وmaxn(حداکثر طول) به زبان هدف بستگی دارد. برای زبان انگلیسی، بازه ۳ تا ۶ معمولاً عالی عمل میکند. اما برای زبانهای غنی از نظر مورفولوژیکی (مانند فارسی که دارای پیشوندها و پسوندهای متعدد است)، ممکن است نیاز باشد این بازه را کمی طولانیتر انتخاب کنید تا ریشههای کلمات بهتر استخراج شوند. - کیفیت پیشپردازش: FastText به نحوه توکنبندی (Tokenization) و نرمالسازی بسیار حساس است. برای مثال، اگر در یک جا کلمه را با نیمفاصله و در جای دیگر با فاصله کامل بنویسید، n-gramهای متفاوتی تولید شده و دقت مدل در تسکهای حساس کاهش مییابد.
کاربردهای عملی (Practical Applications)
FastText در سناریوهایی که درک ساختار کلمه و سرعت اولویت دارند، بیرقیب است:
- سیستمهای چندزبانه: عالی برای زمانی که دادههای آموزشی در برخی زبانها محدود است (مدل از شباهت ساختاری کلمات در زبانهای همخانواده استفاده میکند).
- متون تخصصی و دامنه خاص: مناسب برای حوزههای پزشکی یا مهندسی که واژگان تخصصی زیادی دارند و در مجموعههای داده عمومی یافت نمیشوند.
- سیستمهای بلادرنگ (Real-time): به دلیل سرعت بالای استنتاج (Inference) و مصرف بهینه حافظه در زمان اجرا، برای چتباتها و فیلترهای اسپم لحظهای ایدهآل است.
- طبقهبندی متن: در مواردی که اطلاعات زیر-کلمهای میتواند ویژگیهای تمایزدهنده (Discriminative Features) ایجاد کند.
مزایا و محدودیتها (Advantages and Limitations)
نقاط قوت (Key Advantages):
- مدیریت کلمات OOV: توانایی تولید بردار برای کلمات ندیده شده.
- آگاهی مورفولوژیکی: درک رابطه بین مشتقات کلمات (مثل: “دوید”، “دویدن”، “دوان”).
- کارایی محاسباتی: آموزش و پیشبینی بسیار سریع به لطف Hierarchical Softmax.
- انعطافپذیری زبانی: عملکرد فوقالعاده در زبانهای پیچیده از نظر ساختاری.
محدودیتها (Limitations):
- مصرف حافظه: به دلیل ذخیرهسازی اطلاعات مربوط به تمام n-gramها، فایلهای مدل FastText معمولاً حجم بیشتری نسبت به Word2Vec دارند.
- حساسیت به هایپرپارامترها: عملکرد مدل به شدت به تنظیم درست
minnوmaxnوابسته است. - عمق معنایی محدود: در مقایسه با مدلهای مبتنی بر ترانسفورمر (مانند BERT)، FastText ممکن است در درک روابط معنایی بسیار پیچیده و طولانیمدت در جمله ضعیفتر عمل کند.
بعد از FastText، قدم بعدی چیست؟ مسیر کامل NLP و LLM
FastText یک نقطه عطف مهم در مسیر یادگیری NLP است؛ چون به شما یاد میدهد چطور «کلمات» را به بردار تبدیل کنید، با OOV کنار بیایید و ساختار زیر-کلمهای زبانهایی مثل فارسی را بهتر مدل کنید. اما واقعیت این است که برای ورود جدی به بازار کار و اجرای پروژههای امروزی، باید یک مسیر کامل را جلو بروید: از Embeddingهای کلاسیک مثل Word2Vec و FastText تا معماریهای مدرن Transformer و مدلهای زبانی بزرگ (LLM).
اگر میخواهید این مسیر را اصولی، پروژهمحور و یکجا یاد بگیرید، پیشنهاد میکنیم از دوره جامع آموزش LLM و NLP استفاده کنید.
در این دوره چه چیزهایی یاد میگیرید؟
- Word Embeddings از پایه: از ایده بردارسازی کلمات تا کاربردهای عملی
- Word2Vec (CBOW/Skip-gram) و تحلیل نقاط قوت/ضعف آن
- FastText و رویکرد Subword برای زبانهای مورفولوژیک مثل فارسی + کار با OOV
- پل ورود به مدلهای عمیقتر: Transformer و منطق Attention
- آشنایی کاربردی با مسیر LLMها و استفاده از آنها در پروژههای واقعی




















