

تشخیص اشیا (Object Detection) یکی از چالشبرانگیزترین حوزههای بینایی ماشین است که نه تنها باید چیستی یک شیء را تشخیص دهد، بلکه باید کجایی آن را نیز با دقت تعیین کند. مدل Faster R-CNN که نسخه تکاملیافته مدلهای R-CNN و Fast R-CNN است، با معرفی یک نوآوری بزرگ به نام Region Proposal Network (RPN)، فرآیند شناسایی مناطق مهم تصویر را به درون خود مدل منتقل کرد. این یکپارچگی باعث شد تا سرعت و دقت تشخیص اشیا به شکل خیرهکنندهای افزایش یابد و امکان پردازش بلادرنگ (Real-time) فراهم شود. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر این مدل و نحوه عملکرد آن میپردازیم.
Faster R-CNN چه جایگاهی در تشخیص اشیا دارد؟
اگر به دنیای هوش مصنوعی، بینایی کامپیوتر و تشخیص اشیا علاقهمند باشید، احتمالاً با این سوال روبهرو شدهاید که مدلها چگونه میتوانند هم نوع یک شیء را تشخیص دهند و هم موقعیت دقیق آن را در تصویر مشخص کنند. در دانش بینای کامپیوتر، آشنایی با مدلهای تشخیص اشیا یکی از مهمترین قدمهاست؛ چون بسیاری از پروژههای واقعی مانند خودروهای خودران، تحلیل ویدیویی، ردیابی بازیکنان فوتبال، و تحلیل تصاویر پزشکی بر پایه همین مدلها ساخته میشوند.
در این مقاله میخواهیم ببینیم Faster R-CNN چیست، چگونه کار میکند، چه مزایا و محدودیتهایی دارد و چرا هنوز یکی از مدلهای مهم در یادگیری تشخیص اشیا به شمار میرود.
تکامل مدلهای خانواده R-CNN
برای درک بهتر اهمیت Faster R-CNN، باید نگاهی به مسیر پیشرفت این مدلها داشته باشیم:
۱. مدل R-CNN (سال ۲۰۱۳)
R-CNN اولین نسل از این خانواده بود که از الگوریتم Selective Search برای ایجاد حدود ۲۰۰۰ پیشنهاد منطقه (Region Proposals) استفاده میکرد.
- مشکل: هر منطقه به صورت جداگانه وارد شبکه CNN میشد که باعث کندی بسیار زیاد در مرحله استنتاج (Inference) بود.
- طبقهبندی: از ماشین بردار پشتیبان (SVM) برای دستهبندی استفاده میکرد.
۲. مدل Fast R-CNN (سال ۲۰۱۵)
در این نسخه Fast R-CNN، کل تصویر فقط یکبار از شبکه CNN عبور میکرد تا نقشههای ویژگی (Feature Maps) تولید شوند.
- نوآوری: معرفی RoI Pooling که اجازه میداد ویژگیهایی با اندازه ثابت از مناطق پیشنهادی استخراج شود.
- بهبود: جایگزینی SVM با لایههای کاملاً متصل (Fully Connected) عصبی.
- نقطه ضعف: هنوز برای تولید پیشنهادها به الگوریتم کند Selective Search وابسته بود.
۳. مدل Faster R-CNN (سال ۲۰۱۵)
Faster R-CNN با حذف Selective Search و معرفی RPN، فرآیند تولید پیشنهادها را هم به یک شبکه عصبی سپرد.
- ویژگی اصلی: آموزش سرتاسری (End-to-End) هر دو بخشِ “پیشنهاد منطقه” و “تشخیص شیء”.
- نتیجه: بهبود چشمگیر در سرعت و دقت.
۴. بهبودهای پس از Faster R-CNN (۲۰۱۷ تا کنون)
پس از موفقیت این مدل، نسخههای پیشرفتهتری مانند Mask R-CNN برای بخشبندی اشیا (Segmentation) و استفاده از بدنه (Backbone) های قدرتمندی مثل ResNet و Vision Transformers معرفی شدند که دقت مدل را به سطوح بالاتری رساندند.
کالبدشکافی معماری Faster R-CNN
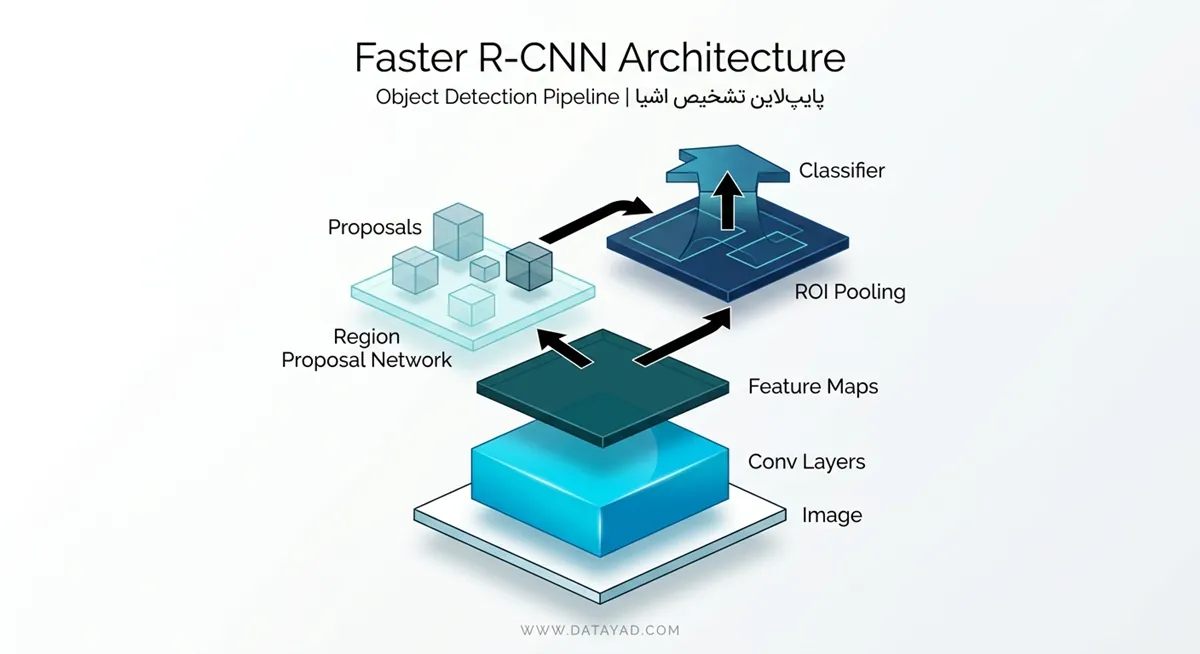
معماری Faster R-CNN از چهار بخش اصلی تشکیل شده است که به صورت یکپارچه با هم کار میکنند تا تصویر ورودی را تحلیل کرده و اشیا را شناسایی کنند.
۱. شبکه بدنه (Backbone Network)
این بخش وظیفه استخراج ویژگیهای بصری از تصویر خام را بر عهده دارد.
- عملکرد: تصویر ورودی از یک شبکه عصبی کانولوشنی عمیق (CNN) عبور میکند. مدلهای محبوبی مثل VGG16، ResNet یا ResNeXt معمولاً به عنوان Backbone استفاده میشوند.
- خروجی: خروجی این مرحله یک «نقشه ویژگی» (Feature Map) است. نکته طلایی اینجاست که این نقشه ویژگی بین دو بخش بعدی (RPN و شبکه تشخیص) به اشتراک گذاشته میشود که باعث صرفهجویی عظیم در محاسبات میگردد.
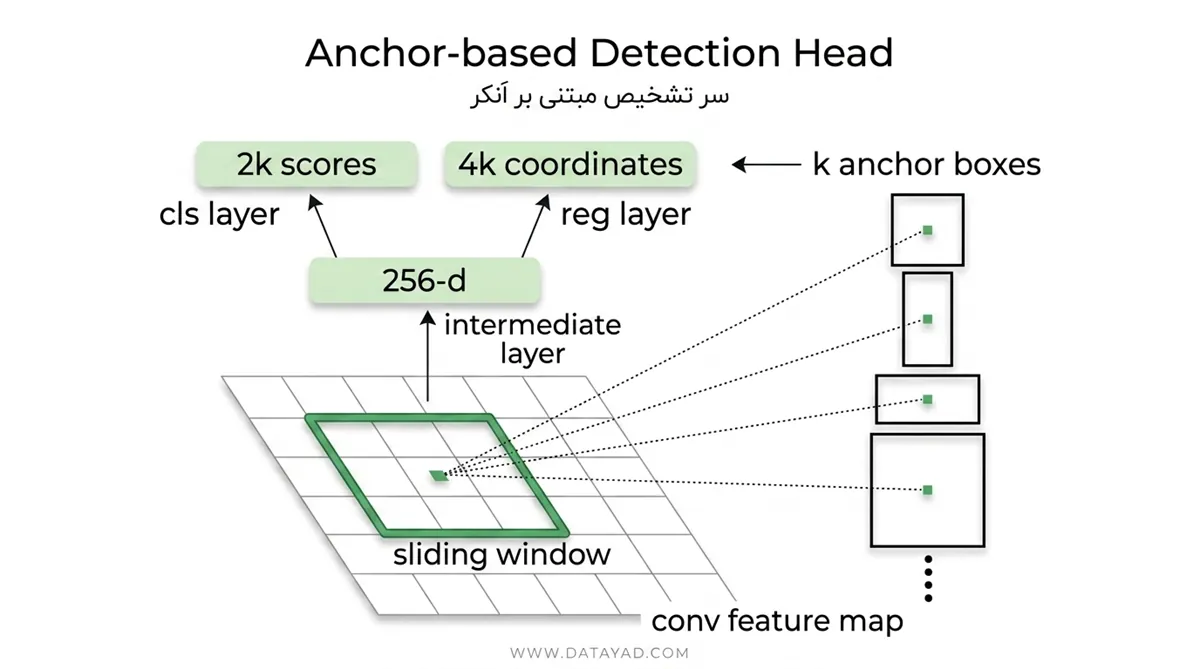
۲. شبکه پیشنهاد منطقه (Region Proposal Network – RPN)
این قلب تپنده Faster R-CNN و وجه تمایز آن با نسلهای قبلی است. RPN یک شبکه کوچک است که روی نقشه ویژگی میلغزد (Sliding Window).
لنگرها (Anchors): RPN از جعبههای پیشفرض با مقیاسها و نسبتهای ابعاد مختلف (Aspect Ratios) استفاده میکند تا مناطق احتمالی حضور اشیا را حدس بزند.
خروجیهای RPN:
- Objectness Score: یک امتیاز احتمالی که نشان میدهد آیا در این منطقه شیئی وجود دارد یا فقط پسزمینه است.
- Bounding Box Regression: اصلاح مختصات جعبهها برای انطباق دقیقتر با شیء.
- آموزش End-to-End: به دلیل یکپارچگی، RPN و شبکه تشخیص همزمان یاد میگیرند که کدام ویژگیها برای پیشنهاد منطقه مهمتر هستند.
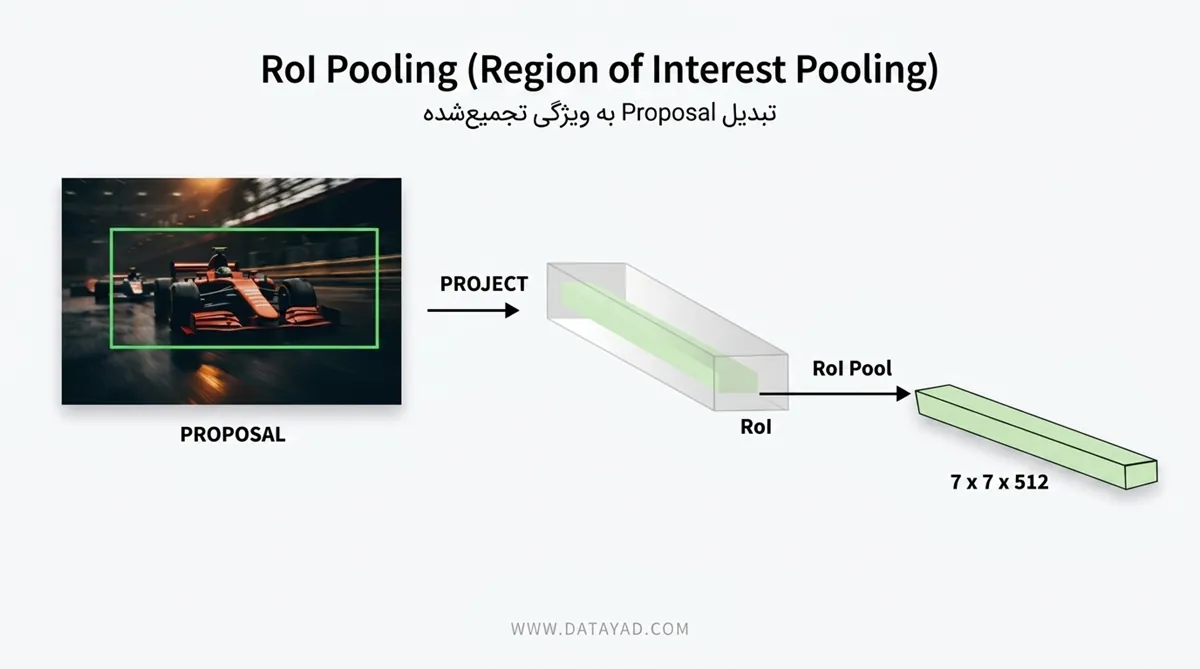
۳. لایه RoI Pooling (Region of Interest Pooling)
از آنجایی که پیشنهادهای ارائه شده توسط RPN ابعاد متفاوتی دارند، اما لایههای کاملاً متصل (Fully Connected) در انتهای شبکه نیاز به ورودی با اندازه ثابت دارند، از RoI Pooling استفاده میشود.
- وظیفه: این لایه، بخشهای مختلف نقشه ویژگی (که توسط RPN پیشنهاد شده) را میگیرد و آنها را به یک اندازه استاندارد و ثابت (مثلاً ۷×۷) تبدیل میکند. این کار باعث میشود مهم نیست شیء چقدر بزرگ یا کوچک باشد، دادههای ارسالی به بخش نهایی یکسان باشند.
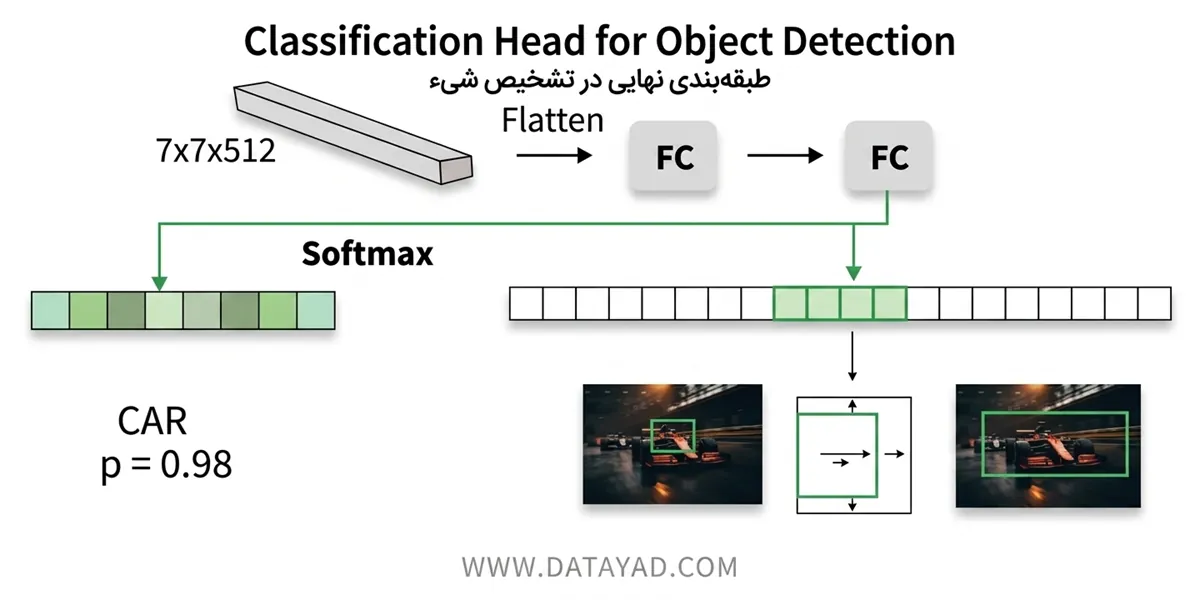
۴. شبکه تشخیص (Detection Network)
این بخش مرحله نهایی است که دو کار اصلی انجام میدهد:
- طبقهبندی (Classification): تشخیص میدهد که شیء داخل جعبه چیست (سگ، ماشین، فرد و …). معمولاً از تابع Softmax برای این کار استفاده میشود.
- دقیقسازی نهایی (Refinement): بار دیگر مختصات جعبه (Bounding Box) را برای دقت حداکثری بازبینی و اصلاح میکند. در این مرحله از تابع زیان Smooth L1 loss استفاده میشود.
پیادهسازی عملی Faster R-CNN در پایتون
برای اجرای این مدل، ما از اکوسیستم torchvision استفاده میکنیم که پیادهسازیهای بهینه و استانداردی از Faster R-CNN را در اختیار ما قرار میدهد.
گام اول: نصب نیازمندیها (Install Dependencies)
ابتدا باید کتابخانههای اصلی را نصب کنید. ما برای پردازش تصویر از PIL و برای مصورسازی از matplotlib استفاده میکنیم.
!pip install torch torchvision matplotlib
گام دوم: فراخوانی کتابخانهها و ماژولها
در این بخش، ابزارهای لازم برای بارگذاری مدل، تبدیل تصاویر به تنسور و ترسیم جعبههای تشخیص داده شده را وارد میکنیم.
import torch from torchvision.models.detection import fasterrcnn_resnet50_fpn from torchvision.transforms import functional as F from PIL import Image import matplotlib.pyplot as plt import matplotlib.patches as patches
گام سوم: بارگذاری و پیشپردازش تصویر
مدل Faster R-CNN انتظار دارد تصاویر به صورت تنسور با مقادیر نرمال شده بین ۰ و ۱ باشند.
def load_and_prep_image(image_path):
# بارگذاری تصویر و تبدیل به فرمت رنگی RGB
image = Image.open(image_path).convert("RGB")
# تبدیل تصویر به تنسور (حذف نیاز به پیشپردازش دستی سنگین)
image_tensor = F.to_tensor(image)
return image, image_tensor
# مسیر تصویر خود را اینجا قرار دهید
image_path = "sample_image.jpg"
original_img, img_tensor = load_and_prep_image(image_path)
گام چهارم: بارگذاری مدل پیشآموزشدیده (Pretrained Model)
ما از مدلی استفاده میکنیم که قبلاً روی میلیونها تصویر آموزش دیده و قادر است ۸۰ کلاس مختلف از اشیا (مثل انسان، ماشین، صندلی و غیره) را تشخیص دهد.
# بارگذاری مدل با وزنهای از پیش آموزش دیده model = fasterrcnn_resnet50_fpn(pretrained=True) # تغییر وضعیت مدل به حالت ارزیابی (Evaluation Mode) # این کار لایههایی مثل Dropout یا Batch Normalization را تنظیم میکند model.eval()
گام پنجم: استنتاج (Inference) و استخراج نتایج
در این مرحله تصویر را به شبکه میدهیم تا مختصات جعبهها، برچسبها و امتیاز اطمینان (Confidence Score) را استخراج کند.
def get_predictions(model, img_tensor):
# غیرفعال کردن محاسبات گرادیان برای صرفهجویی در حافظه و افزایش سرعت
with torch.no_grad():
# مدل لیستی از تصاویر را میگیرد، ما یک تصویر را در لیست میفرستیم
outputs = model([img_tensor])
# استخراج خروجیها
boxes = outputs[0]['boxes'] # مختصات جعبهها [x1, y1, x2, y2]
labels = outputs[0]['labels'] # شناسه عددی کلاسها
scores = outputs[0]['scores'] # امتیاز اطمینان (بین 0 تا 1)
return boxes, labels, scores
boxes, labels, scores = get_predictions(model, img_tensor)
گام ششم: مصورسازی هوشمند نتایج (Visualization)
در نهایت، فقط اشیایی را نمایش میدهیم که مدل با اطمینان بالای ۸۰٪ (Score > 0.8) آنها را تشخیص داده است.
def visualize_results(image, boxes, scores, threshold=0.8):
fig, ax = plt.subplots(1, figsize=(12, 8))
ax.imshow(image)
for box, score in zip(boxes, scores):
if score > threshold:
x1, y1, x2, y2 = box.numpy() # تبدیل تنسور به اعداد معمولی
# ایجاد مستطیل (جعبه احاطهکننده)
rect = patches.Rectangle(
(x1, y1), x2 - x1, y2 - y1,
linewidth=2, edgecolor='r', facecolor='none'
)
ax.add_patch(rect)
# نمایش امتیاز اطمینان بالای جعبه
plt.text(x1, y1, f'{score:.2f}', color='white',
verticalalignment='top', bbox={'color': 'red', 'alpha': 0.5})
plt.axis('off')
plt.show()
# اجرای تابع نهایی
visualize_results(original_img, boxes, scores)
کاربردها، مزایا و چالشهای Faster R-CNN
مدل Faster R-CNN به دلیل تعادل بسیار خوب بین سرعت و دقت، در طیف گستردهای از صنایع به کار گرفته شده است. در اینجا به بررسی جزئیات این موارد میپردازیم:
کاربردهای عملی (Practical Applications)
- تشخیص اشیا در تصاویر و ویدیوها: این مدل به طور گسترده برای شناسایی و محلیسازی چندین شیء در تصاویر استاتیک و جریانهای ویدیویی بلادرنگ استفاده میشود. این ویژگی در سیستمهای نظارتی، برچسبگذاری خودکار تصاویر و مدیریت محتوا حیاتی است.
- خودروهای خودران (Autonomous Vehicles): در این صنعت، Faster R-CNN به تشخیص عابران پیاده، سایر وسایل نقلیه، علائم راهنمایی و رانندگی و موانع کمک میکند تا مسیریابی ایمن تضمین شود.
- تصویربرداری پزشکی (Medical Imaging): یکی از کاربردهای حساس این مدل در تشخیص تومورها، تعیین محل ارگانها و شناسایی ناهنجاریها در تصاویر X-ray، MRI و CT اسکن است که به دقت تشخیصی پزشکان کمک شایانی میکند.
- خردهفروشی و مدیریت موجودی: سیستمهای بصری خودکار از این مدل برای تشخیص محصولات در قفسهها یا نظارت بر سطح موجودی انبارها استفاده میکنند.
مزایای کلیدی (Key Advantages)
- دقت بسیار بالا: این مدل همچنان عملکردی در سطح بالاترین استانداردهای تشخیص اشیا (State-of-the-art) ارائه میدهد.
- آموزش سرتاسری (End-to-End): بهینهسازی همزمان شبکه RPN و شبکه تشخیص، باعث هماهنگی کامل اجزای مدل میشود.
- سرعت بالاتر نسبت به پیشینیان: با حذف روشهای استخراج منطقه خارجی (مانند Selective Search)، سرعت پردازش به طرز چشمگیری افزایش یافته است.
- انعطافپذیری در بدنه (Backbone): شما میتوانید بسته به نیاز خود از معماریهای مختلف CNN (مانند ResNet یا VGG) به عنوان استخراجکننده ویژگی استفاده کنید.
محدودیتها و چالشها (Limitations)
- سرعت در مقایسه با مدلهای Single-stage: در مقایسه با مدلهایی مثل YOLO یا SSD، این مدل برای کاربردهایی که نیاز به نرخ فریم بسیار بالا دارند، کمی کندتر است.
- هزینه محاسباتی: پردازش تصاویر با رزولوشن بسیار بالا در این مدل نیاز به سختافزار قدرتمندی دارد.
- وابستگی به لنگرها (Anchors): عملکرد نهایی مدل به شدت به انتخاب درست اندازه و نسبت ابعاد لنگرها و کیفیت شبکه بدنه بستگی دارد.
مسیر یادگیری و تبدیل شدن به متخصص بینایی کامپیوتر
آیا میخواهید به یک متخصص پردازش تصویر و بینایی کامپیوتر تبدیل شوید؟ پیادهسازی کدهایی که خواندید تنها شروع راه است. برای اینکه بتوانید پروژههایی نظیر خودروهای خودران، track کردن بازیکنان فوتبال در ویدیو و یا سیستمهای حساس تشخیص تومور و پولیپ را از صفر تا صد طراحی کنید، نیاز به درک عمیق از ریاضیات پشت شبکه، بهینهسازی مدلها و کار با دیتاستهای واقعی دارید.
ما در دوره جامع «آموزش پردازش تصویر و بینایی کامپیوتر» تمام مفاهیم گفته شده در این مقاله + هر چیزی که برای تخصص در حوزه بینایی کامپیوتر لازم دارید را به صورت پروژهمحور به شما آموزش میدهیم. در این دوره، شما فقط تئوری نمیخوانید، بلکه چالشهای دنیای واقعی را حل میکنید. همین حالا یادگیری حرفهای را شروع کنید و با ساخت پروژههایی که در بالا ذکر شد، خود را از رقبا متمایز کنید.

سوالات متداول درباره Faster R-CNN
۱. آیا Faster R-CNN برای سیستمهای بلادرنگ (Real-time) مناسب است؟
بله، با وجود اینکه مدلهای Single-stage مثل YOLO ممکن است سرعت بالاتری داشته باشند، اما Faster R-CNN تعادل بسیار خوبی بین دقت و سرعت برقرار میکند و برای بسیاری از کاربردهای صنعتی که دقت اولویت بالایی دارد، انتخاب اول است.
۲. پیشنیازهای لازم برای یادگیری این مدل چیست؟
شما باید دانش مقدماتی در مورد کتابخانههای پایتون (NumPy، Pandas) و تسلط کافی بر اصول شبکه عصبی مصنوعی و یادگیری عمیق (Deep Learning) با استفاده از PyTorch یا TensorFlow داشته باشید.
۳. آیا برای آموزش این مدل حتماً به GPU قوی نیاز دارم؟
برای یادگیری و تست روی تصاویر کوچک یا دیتاسِتهای آموزشی، سیستمهای معمولی با CPU کافی هستند. اما برای آموزش مدل روی دیتاسِتهای بزرگ و کاربردهای واقعی، داشتن یک GPU با حافظه VRAM مناسب (مانند سری RTX انویدیا) اکیداً توصیه میشود.
۴. چرا Faster R-CNN نسبت به نسخههای قدیمیتر خود بهتر است؟
تفاوت اصلی در حذف الگوریتم Selective Search و جایگزینی آن با Region Proposal Network (RPN) است. این کار باعث شد کل پروسه پیشنهادی مناطق (Proposals) در داخل شبکه عصبی انجام شود و سرعت مدل به شدت افزایش یابد.
۵. یادگیری این مدل در چه حوزههای کاری کاربرد دارد؟
در صنایع خودروسازی (خودروهای خودران)، پزشکی (تشخیص بیماری)، ورزش (تحلیل مسابقات) و سیستمهای نظارتی و امنیتی، تقاضای بسیار بالایی برای متخصصان مسلط به این معماری وجود دارد.




















