

معماری U-Net یکی از قدرتمندترین و پرکاربردترین شبکههای عصبی در حوزه یادگیری عمیق (Deep Learning) است که به طور تخصصی برای وظایف بخشبندی تصویر (Image Segmentation) طراحی شده است. برخلاف مدلهای طبقهبندی معمولی که کل تصویر را برچسبگذاری میکنند، U-Net با تفکیک دقیق هر پیکسل، میتواند مرزهای اشیاء را در تصویر شناسایی کند.
نام U-Net به دلیل ساختار متقارن آن است که در هنگام ترسیم، شباهت زیادی به حرف انگلیسی U دارد. این مدل به ویژه در تصویربرداریهای پزشکی (مانند تفکیک تومور از بافت سالم) انقلابی ایجاد کرده است؛ چرا که حتی با دادههای برچسبگذاری شده اندک نیز عملکردی خیرهکننده از خود نشان میدهد. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر این معماری و کاربردهای آن میپردازیم.
از تئوری تا پیادهسازی معماری U-Net
برای اینکه بتوانید از قدرت یادگیری عمیق در تحلیل دقیق تصاویر استفاده کنید، درک جزئیات معماری U-Net یکی از مهمترین قدم ها است. دنیای بینایی کامپیوتر بدون این معماری، در تشخیص مرزهای دقیق اشیاء (بهویژه در تصاویر حساس پزشکی) با چالشهای بزرگی روبرو بود.
ما در این مقاله، مسیر یادگیری را به گونهای طراحی کردهایم که ابتدا با مفهوم و فلسفه وجودی این شبکه آشنا شوید و بدانید چرا نام U برای آن انتخاب شده است. سپس، لایه به لایه وارد بخشهای فنی یعنی انکودر (Encoder)، دیکودر (Decoder) و اتصالات میانبر (Skip Connections) میشویم تا منطق ریاضی و مهندسی پشت آن را درک کنید. در نهایت، برای اینکه این آموزش کاملاً کاربردی باشد، کل این ساختار را با استفاده از کتابخانه TensorFlow و زبان پایتون به صورت خطبهخط پیادهسازی میکنیم تا آماده استفاده در پروژههای شخصی خودتان باشد.
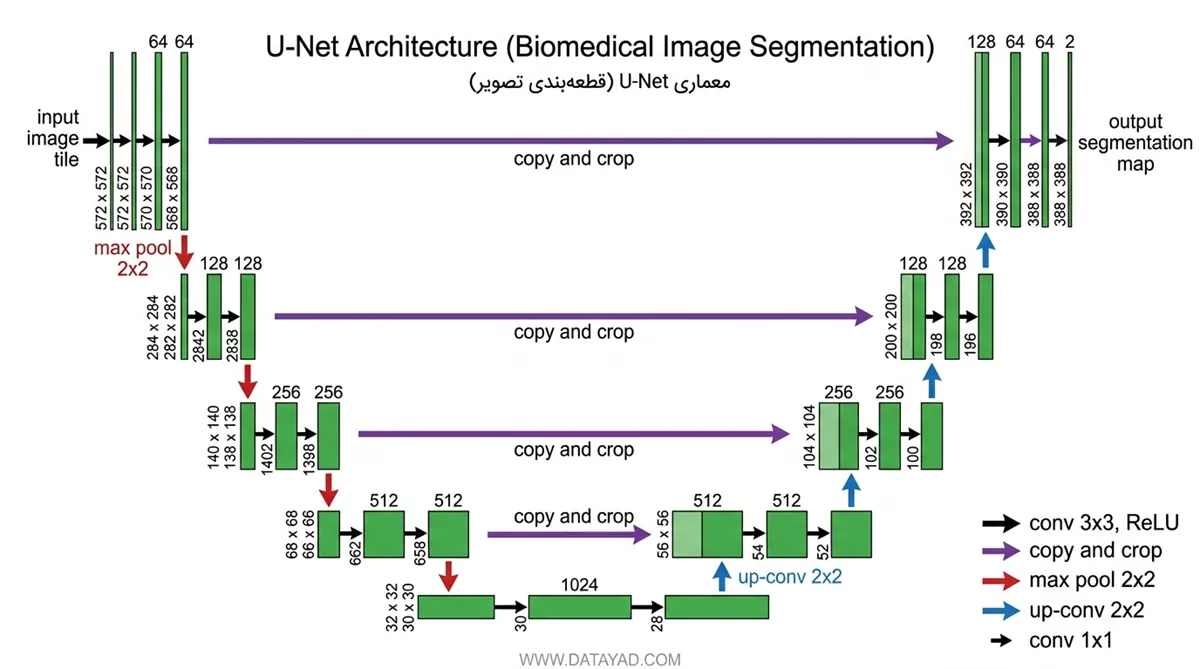
بررسی ساختار معماری U-Net: سه بخش کلیدی
معماری U-Net در یادگیری عمیق به دلیل تقارن کامل خود شناخته میشود. این ساختار به گونهای مهندسی شده است که اطلاعات را به صورت سلسلهمراتبی پردازش کرده و در نهایت بازسازی میکند. این معماری از سه بخش اصلی تشکیل شده است:
۱. مسیر Encoder
این بخش وظیفه استخراج ویژگیها را بر عهده دارد. عملکرد آن مشابه یک شبکه عصبی کانولوشنی استاندارد (CNN) است:
- استفاده از فیلترهای کوچک (3×3): برای اسکن تصویر و شناسایی الگوهای محلی.
- تابع فعالساز ReLU: برای افزودن غیرخطیبودن به مدل و یادگیری بهتر روابط پیچیده.
- لایه Max Pooling (2×2): تصویر را کوچک میکند تا ابعاد فضایی کاهش یابد، در حالی که مهمترین ویژگیها (مانند لبهها و بافتها) حفظ شوند. این کار به شبکه کمک میکند تا روی ویژگیهای بزرگتر و انتزاعیتر تمرکز کند.
۲. گلوگاه (Bottleneck)
این بخش، پایینترین نقطه در حرف U است. در اینجا، تصویر به بیشترین میزان فشردهسازی رسیده است. این بخش حاوی فشردهترین و انتزاعیترین اطلاعات تصویر است که به عنوان پلی میان بخش رمزگذار (Encoder) و رمزگشا (Decoder) عمل میکند.
۳. مسیر Decoder
هدف این بخش بازسازی ابعاد اصلی تصویر و تعیین دقیق مکان اشیاء است:
- Upsampling: افزایش اندازه تصویر برای بازگشت به ابعاد اولیه (Resolution).
- اتصالات میانبر (Skip Connections): این مهمترین بخش در بازسازی دقیق است. این اتصالات اطلاعاتِ مکانی (Spatial details) را که در طول فرآیند Max Pooling در مسیر Decoder از دست رفته بود، مستقیماً به بخش انکودر منتقل میکنند.
- لایههای کانولوشنی: برای تصفیه و بهبود خروجی نهایی پس از ادغام دادهها استفاده میشوند.
در نهایت، U-Net تصویر ورودی (مثلاً 572×572) را به یک نقشه بخشبندی (Segmentation Map) تبدیل میکند که در آن هر پیکسل به درستی دستهبندی شده است.
اگر مفاهیم شبکه های عصبی براتون جذاب است یا میخواهید درک کاملی از شبکه های عصبی داشته باشید، آموزش رایگان شبکه عصبی و یادگیری عمیق دیتایاد بهترین منبع برای شماست. در این دوره رایگان با ساده ترین زبان ممکن مفاهیم شبکه عصبی قدم به قدم شرح داده شده است.

نحوه عملکرد U-Net: از پیکسلهای خام تا Segmentation Map
پس از درک ساختار کلی، نوبت به بررسی این موضوع میرسد که دادهها چگونه در این شبکه جریان مییابند. فرآیند پردازش در U-Net را میتوان به ۵ مرحله کلیدی تقسیم کرد:
۱. تصویر ورودی (Input Image)
فرآیند با دریافت یک تصویر ورودی آغاز میشود. در کاربردهای پزشکی، این تصاویر معمولاً خاکستری (Grayscale) هستند. شبکه آماده است تا هر پیکسل را به تنهایی تحلیل کند.
۲. استخراج ویژگی در مسیر Encoder
در این مرحله، شبکه با استفاده از عملیات کانولوشن و کاهش ابعاد (Downsampling)، ویژگیهای انتزاعی تصویر را استخراج میکند.
- نکته فنی: در هر مرحله از این مسیر، ابعاد فضایی تصویر (عرض و ارتفاع) کاهش مییابد، اما تعداد کانالهای ویژگی (Feature Channels) افزایش پیدا میکند. این کار به مدل اجازه میدهد تا الگوهای سطح بالا (مانند شکل کلی یک اندام) را شناسایی کند.
۳. پردازش در گلوگاه (Bottleneck)
این بخش عمیقترین قسمت شبکه است. در اینجا تصویر به کوچکترین حالت ممکن تبدیل شده اما حاوی غنیترین اطلاعات مفهومی است. گلوگاه در واقع عصاره و معنای تصویر را در خود نگه میدارد.
۴. بازسازی و مکانیابی در مسیر Decoder
حالا نوبت به بازسازی ابعاد تصویر میرسد. دیکودر با استفاده از Upsampling ابعاد را بزرگ میکند. نکته اصلی U-Net در اینجاست: در هر سطح، ویژگیهای بازسازی شده با ویژگیهای مشابه از مسیر Encoder (از طریق Skip Connections) ترکیب میشوند. این کار باعث میشود جزئیات دقیق مکانی که در مرحله فشردهسازی گم شده بودند، دوباره به دست آیند.
۵. پیشبینی نهایی
در آخرین لایه، یک کانولوشن ۱x۱ اعمال میشود. وظیفه این لایه نهایی این است که نقشههای ویژگیِ تصفیه شده را به یک نقشه بخشبندی نهایی تبدیل کند. در این نقشه، هر پیکسل طبقهبندی میشود (مثلاً تعیین میشود که آیا این پیکسل متعلق به تومور است یا پسزمینه). خروجی نهایی دارای همان رزولوشن و ابعاد تصویر ورودی است.
پیادهسازی معماری U-Net با پایتون و TensorFlow
برای پیادهسازی این مدل قدرتمند، ما از کتابخانه محبوب TensorFlow و رابط Keras استفاده میکنیم. اولین قدم، ساخت «بلوک Encoder» است. وظیفه این بخش، دریافت تصویر و استخراج ویژگیهای کلیدی از طریق کاهش ابعاد (Downsampling) است.
ساختار بلوک انکودر (Encoder Block)
هر بلوک در مسیر Encoder شامل مراحل زیر است:
- دو لایه کانولوشن (Convolutional Layers): از فیلترهای 3×3 برای شناسایی الگوها استفاده میشود. در اینجا از
padding='valid'استفاده شده که باعث میشود ابعاد تصویر در هر مرحله کمی کاهش یابد (مطابق با مقاله اصلی U-Net). - تابع فعالساز ReLU: برای ایجاد غیرخطیبودن و اجازه دادن به شبکه برای یادگیری الگوهای پیچیده.
- لایه Max Pooling: با اندازه 2×2 و گام (Stride) 2، که اندازه تصویر را نصف کرده و باعث میشود مدل روی ویژگیهای بزرگتر و مهمتر تمرکز کند.
در ادامه، کد مربوط به این بخش را مشاهده میکنید:
import tensorflow as tf
def encoder_block(inputs, num_filters):
"""
ایجاد بلوک انکودر
inputs: دادههای ورودی
num_filters: تعداد فیلترهای لایه کانولوشن
"""
# لایه کانولوشن اول
x = tf.keras.layers.Conv2D(num_filters, 3, padding='valid')(inputs)
x = tf.keras.layers.Activation('relu')(x)
# لایه کانولوشن دوم
x = tf.keras.layers.Conv2D(num_filters, 3, padding='valid')(x)
x = tf.keras.layers.Activation('relu')(x)
# لایه Max Pooling برای کاهش ابعاد
x = tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=2)(x)
return x
در این کد، با افزایش num_filters در هر سطح، شبکه میتواند جزئیات پیچیدهتری را در ابعاد کوچکتر استخراج کند.
بخش دوم، (Decoder و اتصالات میانبر)
در مسیر بازگشت یا همان Decoder، هدف ما بازیابی ابعاد تصویر اصلی و ترکیب آن با جزئیات دقیق مکانی است که در لایههای انکودر استخراج شده بود. این کار از طریق Skip Connections انجام میشود که کلید اصلی دقت بالای U-Net در مرزبندی اشیاء است.
ساختار بلوک دیکودر (Decoder Block)
این بلوک فرآیند معکوس انکودر را انجام میدهد:
- Conv2DTranspose: با استفاده از کانولوشن معکوس، ابعاد تصویر را افزایش میدهد (Upsampling).
- اتصال میانبر (Skip Connection): خروجیِ مربوط به مرحله مشابه در انکودر را با دادههای فعلی ترکیب (Concatenate) میکند.
- Resizing: در صورتی که ابعاد تفاوت ناچیزی داشته باشند، با لایه
Resizingآنها را منطبق میکند. - لایههای کانولوشن: پس از ترکیب، دو لایه کانولوشن برای تصفیه و بازیابی جزئیات دقیق اعمال میشود.
در ادامه، کد این بخش را مشاهده میکنید:
def decoder_block(inputs, skip_features, num_filters):
"""
ایجاد بلوک دیکودر
inputs: نقشه ویژگی از لایه قبلی
skip_features: ویژگیهای انتقال داده شده از انکودر
"""
# 1. افزایش ابعاد (Upsampling)
x = tf.keras.layers.Conv2DTranspose(num_filters, (2, 2), strides=2, padding='valid')(inputs)
# 2. انطباق ابعاد برای الحاق (Concatenation)
skip_features = tf.keras.layers.Resizing(x.shape[1], x.shape[2])(skip_features)
# 3. ترکیب ویژگیها (Skip Connection)
x = tf.keras.layers.Concatenate()([x, skip_features])
# 4. لایههای کانولوشن برای بازیابی جزئیات
x = tf.keras.layers.Conv2D(num_filters, 3, padding='valid')(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(num_filters, 3, padding='valid')(x)
x = tf.keras.layers.Activation('relu')(x)
return x
بخش سوم، تعریف مدل کامل U-Net (ساختار یکپارچه)
این تابع، قلب تپنده پروژه است. در اینجا با استفاده از بلوکهایی که قبلاً تعریف کردیم، یک معماری متقارن ایجاد میکنیم. گلوگاه (Bottleneck) در مرکز قرار میگیرد و اتصالات میانبر (Skip Connections) مسیرهای حیاتی برای بازیابی اطلاعات مکانی را فراهم میکنند.
def unet_model(input_shape=(256, 256, 3), num_classes=1):
inputs = tf.keras.layers.Input(shape=input_shape)
# مسیر (Encoder)
s1 = encoder_block(inputs, 64)
s2 = encoder_block(s1, 128)
s3 = encoder_block(s2, 256)
s4 = encoder_block(s3, 512)
# گلوگاه (Bottleneck)
b1 = tf.keras.layers.Conv2D(1024, 3, padding='valid')(s4)
b1 = tf.keras.layers.Activation('relu')(b1)
b1 = tf.keras.layers.Conv2D(1024, 3, padding='valid')(b1)
b1 = tf.keras.layers.Activation('relu')(b1)
# مسیر (Decoder)
d1 = decoder_block(b1, s4, 512)
d2 = decoder_block(d1, s3, 256)
d3 = decoder_block(d2, s2, 128)
d4 = decoder_block(d3, s1, 64)
# لایه خروجی نهایی با فعالساز Sigmoid برای بخشبندی
outputs = tf.keras.layers.Conv2D(num_classes, 1, padding='valid', activation='sigmoid')(d4)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs, name='U-Net')
return model
# اجرای مدل برای ابعاد تصویر 572x572
if __name__ == '__main__':
model = unet_model(input_shape=(572, 572, 3), num_classes=2)
model.summary()
بخش چهارم، اعمال مدل روی تصویر (پیشبینی عملیاتی)
پس از ساخت مدل، نوبت به استفاده از آن برای جداسازی اشیاء میرسد. در این کد، یک تصویر لود شده، نرمالسازی میشود و سپس مدل با پردازش آن، ماسک بخشبندی (Segmentation Mask) را استخراج میکند.
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing import image
# لود و پیشپردازش تصویر
img = Image.open('cat.png').convert('RGB')
img = img.resize((572, 572))
img_array = image.img_to_array(img) / 255.0
img_array = np.expand_dims(img_array, axis=0)
# فراخوانی مدل
model = unet_model(input_shape=(572, 572, 3), num_classes=2)
# دریافت پیشبینی
predictions = model.predict(img_array)
# تبدیل خروجی به ماسک نهایی
pred_mask = np.squeeze(predictions, axis=0)
pred_mask = np.argmax(pred_mask, axis=-1).astype(np.uint8) * 255
pred_mask_img = Image.fromarray(pred_mask)
pred_mask_img = pred_mask_img.resize(img.size)
# ذخیره و نمایش نتیجه
pred_mask_img.save('predicted_image.jpg')
pred_mask_img.show()
چرا U-Net اینقدر کاربردی است؟
همانطور که در نتایج مشاهده میکنید، این مدل قادر است مرزهای دقیق (مانند دور یک گربه در تصویر) را شناسایی کند. انعطافپذیری U-Net باعث شده تا در حوزههای فراتر از پزشکی، مانند:
- پاکسازی تصاویر (Image Cleaning)
- ترجمه تصاویر (Image Translation)
- ارتقای کیفیت (Enhancement)
- تشخیص اشیاء (Object Detection)
و بسیاری از وظایف پردازش زبان و تصویر دیگر مورد استفاده قرار بگیرد.
چگونه به یک متخصص هوش مصنوعی و علم داده تبدیل شویم؟
یادگیری معماریهایی مثل U-Net تنها بخشی از دنیای بزرگ علم داده است. برای اینکه بتوانید چنین مدلهایی را از صفر طراحی کنید، بر روی دادههای واقعی اجرا کنید و به درآمدزایی برسید، به یک نقشه راه جامع نیاز دارید.
چه چیزهایی باید یاد بگیرید؟
- پایتون (Python): زبان اول هوش مصنوعی.
- ریاضیات، آمار و احتمال: برای درک منطق پشت الگوریتمها.
- تحلیل و پاکسازی داده: چون مدل خوب از داده خوب ساخته میشود.
- یادگیری ماشینی و یادگیری عمیق: تسلط بر انواع شبکههای عصبی (CNN, RNN, U-Net).
اگر میخواهید تمام این مسیر را به صورت یکپارچه، پروژه محور و از سطح صفر تا پیشرفته یاد بگیرید، آموزش جامع متخصص علم داده بهترین انتخاب برای شماست. در این دوره، نه تنها تئوری، بلکه پیادهسازی عملی انواع مدلهای پیچیدهای مثل U-Net را در قالب پروژههای واقعی تمرین خواهید کرد.





















