

پیشرفت شتابان هوش مصنوعی و اتکای آن به حجم عظیمی از دادههای کاربران، مرزهای سنتی حریم خصوصی را جابهجا کرده است. مسئله حریم خصوصی در هوش مصنوعی، دیگر صرفاً نحوهی ذخیرهسازی اطلاعات نیست، بلکه چگونگی استنتاج ویژگیهای حساس از دادههای بهظاهر بیخطر و بازتولید احتمالی آنها توسط مدلهای مولد به دغدغهای حیاتی تبدیل شده است.
دانشجویان و متخصصان این حوزه باید بدانند که هوش مصنوعی چالشهای نوظهوری مانند پروفایلسازی گسترده و نظارت پنهان را به همراه دارد. برای مقابله با این تهدیدات، شناخت دقیق مفاهیمی همچون حریم خصوصی در طراحی و اصول حکمرانی داده ضروری است تا بتوان تعادلی میان نوآوری تکنولوژیک و حقوق بنیادین کاربران برقرار کرد. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی عمیق این چالشها و راهکارهای حفظ حریم خصوصی میپردازیم.
مفهوم حریم خصوصی در هوش مصنوعی
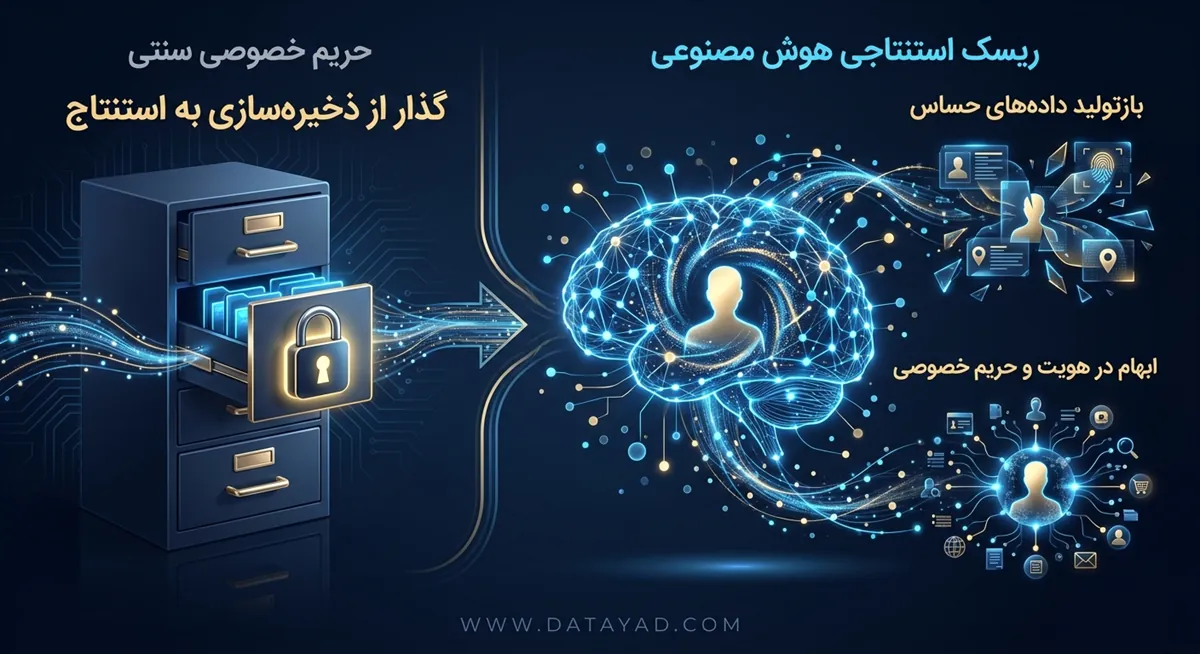
در سیستمهای هوش مصنوعی، حفاظت از حریم خصوصی از قالب سنتی «جلوگیری از دسترسی به داده» خارج شده و به مدیریت ریسکهای استنتاجی تغییر پیدا کرده است. مدلهای یادگیری ماشین در هوش مصنوعی به جای ذخیره مستقیم اطلاعات، الگوهای نهفته در دادهها را شناسایی میکنند که این موضوع ردیابی و پاکسازی دادههای شخصی را با چالشهای فنی جدیدی روبرو میکند. این تغییر باعث شده تا تمرکز نهادهای نظارتی از مرحله جمعآوری، به مرحله آموزش و خروجی مدل منتقل شود. در مورد مفاهیم و تعریف AI، مقاله “هوش مصنوعی چیست؟“ را مطالعه کنید.
گذار از ذخیرهسازی به استنتاج
بزرگترین مشکل در مدلهای هوش مصنوعی این است که سیستم میتواند اطلاعات حساس را بدون دریافت مستقیم آنها حدس بزند. برای مثال، یک الگوریتم میتواند بر اساس تاریخچه خرید یا الگوهای رفتاری ساده، وضعیت سلامتی یا تمایلات شخصی فرد را استنتاج کند. این یعنی حریم خصوصی دیگر فقط به معنای فاش نشدن دادههای ورودی نیست، بلکه به معنای جلوگیری از تولید دانش جدید و حساس درباره کاربران است.
سیستمهای هوش مصنوعی مولد گاهی دادههای آموزشی را در حافظه خود نگه میدارند و ممکن است در پاسخ به پرسشهای دیگران، اطلاعات شخصی افراد را بازتولید کنند. این پدیده باعث میشود که حتی اگر دادههای اولیه به درستی ذخیره شده باشند، خروجی نهایی مدل همچنان تهدیدی برای حریم خصوصی باشد. در این شرایط، روشهای قدیمی مثل حذف نام یا شماره ملی، کارایی خود را در برابر قدرت تحلیل الگوها از دست میدهند.
ابهام در مرز دادههای شخصی
در فضای پردازش الگوریتمیک، مرز مشخصی میان دادههای معمولی و دادههای حساس وجود ندارد. هوش مصنوعی قادر است چندین منبع دادهای بهظاهر بیخطر را با هم ترکیب کرده و هویت واقعی افراد را در مجموعههای دادهای ناشناس بازشناسی کند. این موضوع باعث میشود بسیاری از دادههایی که پیش از این «غیرشخصی» تلقی میشدند، پتانسیل تبدیل شدن به دادههای شخصی را پیدا کنند.
مشکل اصلی زمانی رخ میدهد که دادههای عمومی در ترکیب با مدلهای پیچیده، منجر به پروفایلسازی دقیق و نظارت پنهان میشوند. این ابهام باعث شده است که سازمانها نتوانند به راحتی از انطباق سیستمهای خود با قوانین محافظت از داده اطمینان حاصل کنند. هوش مصنوعی ثابت کرده است که حتی با رعایت اصول ناشناسسازی، همچنان ریسک اتصال دوباره دادهها به اشخاص حقیقی به قوت خود باقی است.
ریسکها و تهدیدهای اصلی حریم خصوصی
سیستمهای هوش مصنوعی برای رسیدن به دقت مطلوب به تغذیه مداوم با حجم عظیمی از دادهها وابسته هستند که این فرآیند اصل «حداقلسازی داده» را به چالش میکشد. انباشت بیپروای اطلاعات در پایگاههای داده، اهداف جدیدی برای مهاجمان ایجاد میکند و کنترل افراد بر داراییهای دیجیتال خود را کاهش میدهد.
- جمعآوری بیش از حد و تهاجمی: تمایل توسعهدهندگان به استفاده از تمامی منابع موجود باعث میشود مرز بین دادههای ضروری و غیرضروری از بین برود و فضای خصوصی کاربران تحت فشار قرار بگیرد.
- استفاده ثانویه از دادهها: اطلاعاتی که برای یک هدف خاص جمعآوری شدهاند، اغلب بدون اطلاع یا رضایت شفاف کاربران، برای آموزش مدلهای جدید یا تحلیلهای تجاری دیگر به کار گرفته میشوند.
- ابهام در مسئولیت حقوقی و پاسخگویی: در صورت نشت اطلاعات یا استفاده نادرست، به دلیل پیچیدگی زنجیره تامین هوش مصنوعی، مشخص کردن مقصر اصلی بین توسعهدهنده، تامینکننده داده یا ارائهدهنده سرویس دشوار است.
- عدم شفافیت در پردازش و خروج: بسیاری از کاربران نمیدانند دادههای آنها در کدام بخش از معماری مدل استفاده میشود و معمولاً مسیر فنی مشخصی برای پس گرفتن یا حذف کامل این دادهها از بدنه مدل وجود ندارد.
- تصمیمگیری خودکار ناعادلانه: تحلیل دادههای شخصی توسط الگوریتمها میتواند به نتایج تبعیضآمیز در فرآیندهای حساسی مثل استخدام یا سیستمهای اعتبارسنجی منجر شود که بر حقوق مدنی افراد اثر منفی میگذارد.
چارچوبهای قانونی حریم خصوصی در هوش مصنوعی
نهادهای بینالمللی برای کنترل ریسکهای هوش مصنوعی دو مسیر متفاوت را دنبال میکنند: تدوین قوانین الزامآور حقوقی و ارائه چارچوبهای داوطلبانه مدیریتی. ناهماهنگی میان این دو رویکرد باعث شده است که سازمانها در مرحله اجرا با تضادهای عملیاتی روبرو شوند و نتوانند مسیر مشخصی برای حفاظت از حریم خصوصی پیدا کنند.
| نام چارچوب | ماهیت اصلی | تمرکز عملیاتی | چالش اجرایی در این حوزه |
|---|---|---|---|
| GDPR (اروپا) | قانون سختگیرانه | حفاظت از حقوق کاربران و محدودسازی پردازش | انطباق ناپذیری برخی بندها با ماهیت یادگیری ماشین. |
| NIST AI RMF | مدیریت ریسک | نقشهبرداری و اندازهگیری فنی خطرات مدل | نبود اجبار قانونی که باعث بیتوجهی شرکتهای کوچک میشود. |
| اصول OECD | سیاستگذاری کلان | ایجاد زبان مشترک برای حکمرانی جهانی | کلیگویی و نبود راهکارهای فنی دقیق برای مهندسان. |
| راهنماهای ICO | نظارتی و اجرایی | شفافسازی نحوه استفاده از دادههای شخصی | تفسیرهای متفاوت و پیچیدگی در اثبات رعایت عدالت. |
بزرگترین مشکل در این بخش، شکاف عمیق بین استانداردهای فنی و الزامات حقوقی است. در حالی که چارچوبهای مدیریتی بر انعطافپذیری و نوآوری تاکید دارند، قوانین حقوقی به دنبال ایجاد مرزهای صلب و تغییرناپذیر هستند. این تضاد باعث میشود تیمهای توسعه برای فرار از جریمههای سنگین، بخش زیادی از قابلیتهای تحلیلی هوش مصنوعی را قربانی کنند یا به دلیل ابهام در متون قانونی، امنیت کاربران را به خطر بیندازند.
راهکارهای صیانت از داده در مدلها
حفاظت از اطلاعات در مدلهای هوش مصنوعی با ابزارهای قدیمی مثل فایروال یا رمزگذاری ساده تامین نمیشود. مشکل اصلی اینجاست که مدل برای یادگیری به دسترسی مستقیم نیاز دارد، اما همین دسترسی میتواند باعث فاش شدن جزئیات حساس شود. ایجاد تعادل بین دقت خروجی و امنیت ورودی، اصلیترین چالش مهندسان در این مرحله است.
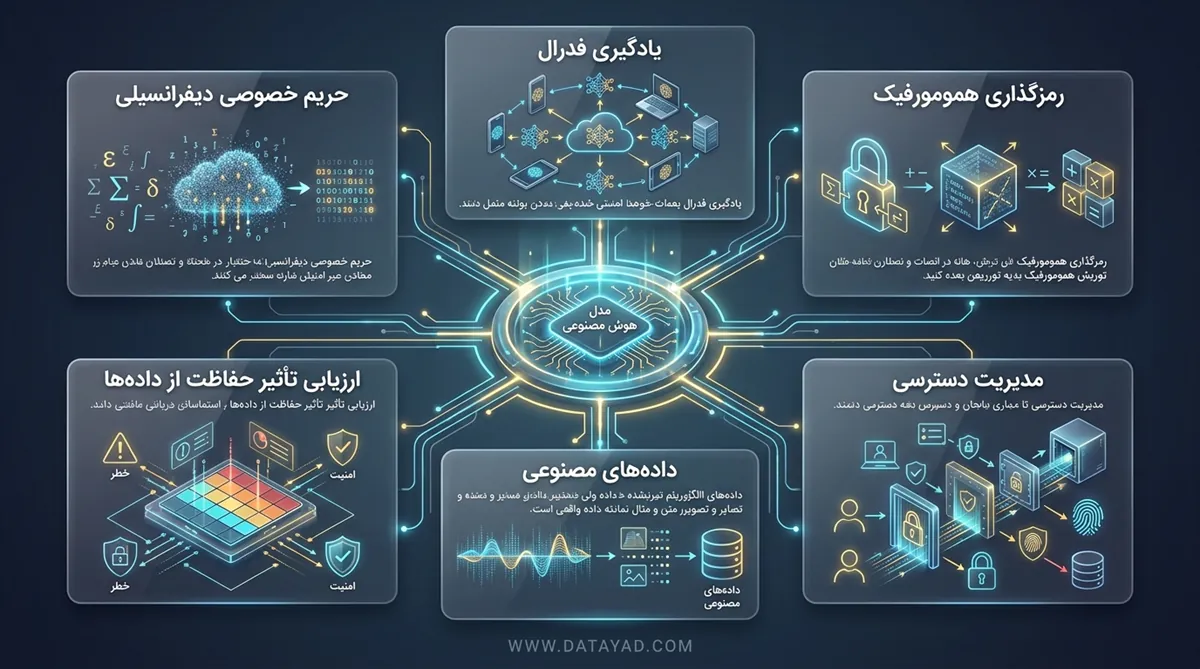
- حریم خصوصی افتراقی (Differential Privacy): در این روش، نویزهای ریاضی به مجموعهداده اضافه میشود تا الگوهای کلی حفظ شوند اما شناسایی هویت تکتک افراد غیرممکن شود. مشکل اصلی اینجاست که اگر مقدار نویز زیاد باشد، کیفیت یادگیری مدل به شدت کاهش مییابد و خروجیها غیردقیق میشوند.
- یادگیری فدرال (Federated Learning): به جای انتقال دادههای شخصی به یک سرور مرکزی، مدل آموزشدیده به سمت دستگاه کاربر فرستاده میشود تا فرآیند یادگیری همانجا انجام شود. با این کار، داده خام هرگز از دستگاه خارج نمیشود؛ اما هماهنگ کردن هزاران دستگاه مختلف و احتمال حملات سایبری به نسخههای محلی مدل، از چالشهای جدی این روش است.
- رمزنگاری همومورفیک: این فناوری اجازه میدهد محاسبات ریاضی مستقیما روی دادههای رمزگذاری شده انجام شود، بدون اینکه نیاز به باز کردن رمز آنها باشد. اگرچه این روش امنیت بسیار بالایی دارد، اما به دلیل نیاز به توان پردازشی فوقالعاده زیاد، برای مدلهای سنگین هوش مصنوعی بسیار کند و هزینهبر است.
- ارزیابی اثرات حریم خصوصی (DPIA): سازمانها پیش از شروع آموزش، باید تمام مسیرهای احتمالی نشت اطلاعات را شبیهسازی و تحلیل کنند. سختی کار در اینجاست که رفتار مدلهای پیچیده همیشه قابل پیشبینی نیست و ممکن است در طول زمان حفرههای امنیتی جدیدی در خروجیهای مدل ظاهر شود.
- استفاده از دادههای مصنوعی (Synthetic Data): ساخت دادههای جدیدی که ویژگیهای آماری دادههای واقعی را دارند اما به هیچ شخص حقیقی مرتبط نیستند. چالش اینجاست که دادههای مصنوعی ممکن است تمام پیچیدگیهای دنیای واقعی را نداشته باشند و باعث سوگیری یا کاهش دقت مدل در مواجهه با واقعیت شوند.
- مدیریت دسترسی و لایههای حفاظتی: محدود کردن دسترسی تیمهای توسعه به دادههای حساس و استفاده از محیطهای ایزوله برای آموزش مدل. مشکل اینجاست که محدودیتهای شدید، سرعت تحقیق و توسعه را پایین میآورد و همکاری بین تیمهای مختلف را دشوار میکند.
انتخاب هر یک از این روشها به میزان حساسیت دادهها و توان فنی سازمان بستگی دارد. در واقعیت، رسیدن به امنیت کامل بدون قربانی کردن بخشی از کارایی یا سرعت مدل، همچنان بزرگترین مانع در مسیر صیانت از دادهها است.
اصول طراحی سیستمهای هوش مصنوعی امن
طراحی یک سیستم هوش مصنوعی امن فراتر از اضافه کردن چند لایه حفاظتی به نرمافزار است. امنیت باید در تار و پود معماری سیستم تنیده شود تا از بروز حفرههای غیرقابل جبران جلوگیری کند. در بسیاری از موارد، نادیده گرفتن پروتکلهای امنیتی در ابتدای مسیر، باعث میشود مدل نهایی در برابر حملات تزریق دستور یا استخراج داده کاملاً بی دفاع باشد.
مشکل اصلی اینجاست که اصلاح یک مدل آموزشدیده بسیار سختتر از طراحی درست آن از روز اول است. وقتی یک سیستم بدون رعایت اصول پایه ساخته میشود، هر تغییری در آینده میتواند دقت مدل را کاهش دهد یا هزینههای نگهداری را به شدت بالا ببرد. بنابراین، امنیت باید به عنوان یک ویژگی اصلی و نه یک گزینه جانبی در نظر گرفته شود.
حریم خصوصی در مرحله طراحی
ایده اصلی «حریم خصوصی در طراحی» این است که حفاظت از اطلاعات کاربران به یک ویژگی پیشفرض در سیستم تبدیل شود. در حال حاضر، بسیاری از تیمهای فنی ابتدا مدل را به طور کامل توسعه میدهند و سپس به فکر ایمنسازی آن میافتند. این رویکرد اشتباه باعث میشود که دادههای حساس به راحتی در لایههای مختلف مدل نفوذ کنند و راهی برای حذف آنها وجود نداشته باشد.
برای پیادهسازی درست این اصل، باید از تکنیکهایی استفاده کرد که دسترسی به دادههای خام را در طول فرآیند آموزش به حداقل برساند. برخی از اقدامات عملی در این زمینه عبارتند از:
- ناشناسسازی هوشمند: جایگزین کردن دادههای واقعی با شناسههای تصادفی پیش از ورود به چرخه آموزش.
- ایمنسازی محیط آموزش: استفاده از بسترهای پردازشی ایزوله که اجازه خروج هیچ دادهای را به محیط بیرون نمیدهند.
- فیلتر کردن خروجیها: طراحی لایههای کنترلی که از نمایش اطلاعات شخصی در پاسخهای نهایی هوش مصنوعی جلوگیری میکنند.
شفافیت و پاسخگویی الگوریتمی
سیستمهای هوش مصنوعی اغلب شبیه به یک جعبه سیاه عمل میکنند که ورودی را میگیرند و بدون توضیح مشخص، خروجی میدهند. این عدم شفافیت بزرگترین مانع برای برقراری امنیت است. وقتی تیم توسعه نتواند مسیر تصمیمگیری مدل را ردیابی کند، شناسایی رفتارهای مخرب یا خطاهای سیستماتیک عملاً غیرممکن میشود. در مورد هوش مصنوعی توضیح پذیر که نقطه مقابل جعبه سیاه هست مقاله هوش مصنوعی تفسیر پذیر Explainable AI را مطالعه کنید.
شفافیت به این معناست که فرآیند استدلال مدل برای متخصصان قابل فهم باشد. این کار کمک میکند تا اگر هوش مصنوعی دچار سوگیری شد یا تصمیمی برخلاف پروتکلهای امنیتی گرفت، ریشه مشکل به سرعت شناسایی شود. پاسخگویی هم مکمل شفافیت است؛ یعنی باید مشخص باشد در صورت بروز خطا، کدام بخش از سیستم و چه کسی مسئول جبران یا اصلاح آن است.
بدون وجود مکانیزمهای پاسخگویی، اعتماد کاربران به سیستم از بین میرود. سیستمهای امن باید ابزارهایی برای گزارشدهی دقیق داشته باشند تا هرگونه فعالیت مشکوک در لحظه ثبت و بررسی شود. این کار باعث میشود که هوش مصنوعی به جای یک ابزار پیشبینیناپذیر، به یک سیستم قابل مدیریت و کنترلشده تبدیل شود.




















