

در بسیاری از حوزهها، دادهها فقط مجموعهای از اعداد نیستند؛ بلکه در طول زمان تغییر میکنند و همین بُعد زمانی، تحلیل آنها را به موضوعی تخصصی و بسیار مهم تبدیل میکند. تحلیل سری زمانی (Time Series Analysis) و پیشبینی سری زمانی (Time Series Forecasting) به ما کمک میکنند تا رفتار گذشته دادهها را بررسی کنیم، الگوهای پنهان را شناسایی کنیم و بر اساس آن، مقادیر آینده را تخمین بزنیم.
این نوع تحلیل در حوزههای مختلفی مثل مالی، پیشبینی فروش، آبوهوا، دادههای سنسوری، مدیریت موجودی، ترافیک و حتی سلامت کاربرد گستردهای دارد. وقتی دادهها در بازههای زمانی منظم ثبت میشوند، میتوان با استفاده از روشهای آماری و مدلهای یادگیری ماشین، روندها، نوسانات فصلی، تغییرات ناگهانی و الگوهای تکرارشونده را شناسایی کرد.
بهطور کلی، تحلیل و پیشبینی سری زمانی روی دادههایی تمرکز دارد که:
- در فواصل زمانی منظم جمعآوری شدهاند،
- امکان شناسایی روند، فصلی بودن و تغییرات ناگهانی را فراهم میکنند،
- و برای برنامهریزی، تصمیمگیری، پیشبینی و کاهش ریسک بسیار ارزشمند هستند.
از رایجترین روشهای مورد استفاده در این حوزه میتوان به ARIMA، هموارسازی نمایی (Exponential Smoothing) و همچنین مدلهای Machine Learning اشاره کرد. تسلط بر این تکنیکهای پیشرفته، یکی از مباحث کلیدی در آموزش علم داده با پایتون محسوب میشود. در ادامه این مقاله، بهصورت مرحلهبهمرحله با مفهوم سری زمانی، اجزای آن، انواع مختلف، روشهای پیشپردازش، تکنیکهای تحلیل، ابزارهای بصریسازی و الگوریتمهای پیشبینی آشنا میشویم.
اهمیت تحلیل سری زمانی
- پیشبینی روندهای آینده: به پیشبینی نتایجی مثل تقاضا، درآمد یا قیمت سهام کمک میکند.
- تشخیص الگوها و ناهنجاریها: چرخهها، اثرات فصلی و رفتارهای غیرعادی را شناسایی میکند.
- کاهش ریسک: هشدارهای زودهنگام برای جلوگیری از زیانهای احتمالی فراهم میکند.
- برنامهریزی استراتژیک: از بودجهبندی، نیروی انسانی، موجودی و تصمیمهای سیاستی پشتیبانی میکند.
- مزیت رقابتی: امکان واکنش سریعتر و بهینهسازی عملیات را فراهم میسازد.
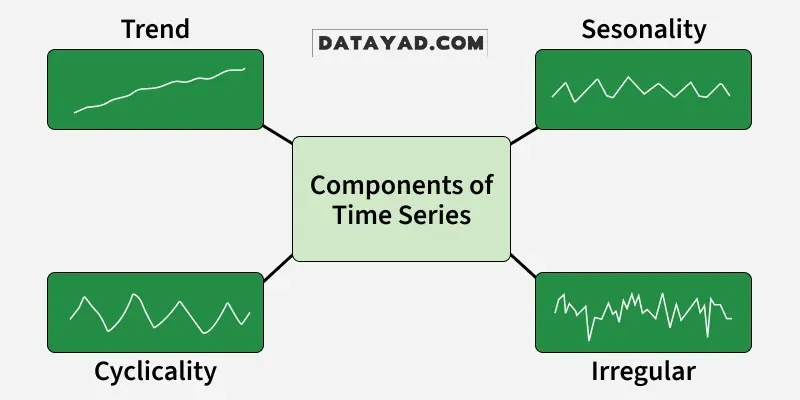
اجزای دادههای سری زمانی
دادههای سری زمانی معمولاً از چند مؤلفه اصلی تشکیل میشوند که شناخت آنها برای تحلیل و پیشبینی دقیق ضروری است:
- روند: حرکت بلندمدت داده که میتواند نشاندهنده افزایش، کاهش یا ثبات باشد و ممکن است خطی یا غیرخطی باشد.
- فصلی بودن: الگوهای منظمی که در فواصل ثابت مثل روزانه، ماهانه یا سالانه تکرار میشوند و اغلب به فصلها یا رویدادها مربوطاند.
- نوسانات چرخهای: نوسانات بلندمدتی که دوره ثابت ندارند و معمولاً به چرخههای اقتصادی یا کسبوکار مرتبط هستند.
- بینظمی یا نویز: تغییرات تصادفی و غیرقابلپیشبینی که به دلیل رویدادها، خطاها یا عوامل پیشبینینشده ایجاد میشوند.
زمان مناسب استفاده از پیشبینی سری زمانی
چه زمانی از پیشبینی سری زمانی استفاده کنیم:
- دادههای تاریخی ثابت و قابلاعتماد هستند.
- الگوها یا روندهای زمانی (Temporal patterns/trends) در داده وجود دارد.
- رفتار آینده به مشاهدات گذشته وابسته است.
چه زمانی از پیشبینی سری زمانی استفاده نکنیم:
- دادهها بسیار پرنویز یا بیثبات (noisy/erratic) هستند.
- هیچ الگوی تاریخی معناداری در داده دیده نمیشود.
- عوامل کلیدی اثرگذار ناشناخته یا غیرقابلپیشبینی هستند.
انواع سری زمانی
سریهای زمانی را میتوان بر اساس ساختار، بازه زمانی، و رفتار آماری گروهبندی کرد. این دستهبندیها به انتخاب روش مناسب پیشبینی کمک میکنند.
1. تکمتغیره در برابر چندمتغیره
- تکمتغیره: سری زمانی تکمتغیره فقط یک متغیر را در طول زمان ثبت میکند، بنابراین تحلیل و مدلسازی آن سادهتر است.
- چندمتغیره: سری زمانی چندمتغیره چند متغیر مرتبط را همزمان دنبال میکند تا نشان دهد چگونه این متغیرها در طول زمان روی هم اثر میگذارند.
2. سری زمانی پیوسته در برابر گسسته
- پیوسته: سری زمانی پیوسته در هر لحظه یا با فرکانس بسیار بالا مشاهده میشود؛ مثل سیگنال ECG یا دادههای سنسورها.
- گسسته: سری زمانی گسسته در بازههای ثابت مثل ساعتی، روزانه یا ماهانه ثبت میشود و رایجترین قالب است.
3. ایستا در برابر ناایستا
- ایستا: یک سری ایستا در طول زمان میانگین، واریانس و الگوی ثابت دارد و روند یا فصلیبودن ندارد.
- ناایستا: یک سری ناایستا الگوهای در حال تغییر مثل روند یا فصلیبودن نشان میدهد و معمولاً قبل از مدلسازی به تبدیل نیاز دارد.
درک عمیق رفتار دادهها، یکی از ستونهای اصلی علم داده مدرن است که به کسبوکارها اجازه میدهد از دل تاریخچه، استراتژی آینده را استخراج کنند.
پیشپردازش دادههای سری زمانی
پیشپردازش سری زمانی یعنی پاکسازی، تبدیل و آمادهسازی دادهها برای تحلیل یا پیشبینی. هدف اصلی این مرحله این است که کیفیت داده بهتر شود، نویز حذف شود و سری زمانی برای مدلسازی مناسب گردد. کارهای رایج در پیشپردازش شامل موارد زیر است:
- مدیریت مقادیر گمشده: پر کردن یا درونیابی (interpolate) مشاهداتِ از دسترفته برای حفظ پیوستگی دادهها.
- رسیدگی به دادههای پرت: شناسایی و اصلاح مقادیر خیلی بزرگ/خیلی کوچک که میتوانند تحلیل را منحرف کنند.
- ایستایی و تبدیلها: استفاده از روشهایی مثل تفاضلگیری، حذف روند یا حذف فصلیبودن برای ثابتتر کردن میانگین و واریانس در طول زمان.
- مقیاسبندی و نرمالسازی: استانداردسازی داده برای بهتر شدن عملکرد مدل.
- پایدارسازی واریانس: اعمال تبدیلها برای کاهش نوسانپذیری و بهتر شدن قابلیت پیشبینی.
تکنیکهای پیشپردازش سری زمانی
- ایستایی: ثابت نگه داشتن میانگین و واریانس در طول زمان.
- تفاضلگیری: حذف روند با کم کردن مقدارهای قبلی از مقدارهای فعلی.
- میانگین متحرک: هموارسازی داده با میانگینگیری روی یک پنجره ثابت.
- میانگین متحرک نمایی: میانگینگیری وزندار که به دادههای جدیدتر اهمیت بیشتری میدهد.
- جایگزینی مقدار گمشده: پر کردن شکافها با درونیابی یا روشهای آماری.
- تشخیص و حذف دادههای پرت: شناسایی و اصلاح مقادیر بسیار دورافتاده.
- مقیاسبندی: تنظیم بازه مقادیر برای قابلمقایسه شدن.
- نرمالسازی: استاندارد کردن دادهها روی یک مقیاس مشترک.
تحلیل و تجزیه سری زمانی
تحلیل و تجزیه (Decomposition) سری زمانی برای مطالعه دادههای ترتیبی در طول زمان استفاده میشود تا الگوها را بهتر بفهمیم و سری را به اجزای اصلی آن بشکنیم؛ یعنی:
- روند
- فصلیبودن
- باقیماندهها/پسماند
این کار باعث میشود ساختار سری زمانی شفافتر شود و تحلیل و مدلسازی آن راحتتر انجام شود.
تکنیکهای رایج (Common Techniques)
- تحلیل خودهمبستگی (Autocorrelation Analysis)
همبستگی بین یک سری و مقادیر با تأخیر (lagged values) آن را اندازهگیری میکند تا الگوها مشخص شوند.
- خودهمبستگی جزئی (Partial Autocorrelation – PACF)
همبستگی مستقیم سری با مقادیر با تأخیر را پیدا میکند، در حالی که اثر تأخیرهای میانی را کنترل میکند.
- تحلیل روند (Trend Analysis)
جهت یا حرکت بلندمدت سری را مشخص میکند (میتواند خطی، نمایی یا غیرخطی باشد).
- تحلیل فصلیبودن (Seasonality Analysis)
الگوهای دورهای را در بازههای ثابت مثل روزانه، هفتگی یا سالانه تشخیص میدهد.
- تجزیه (Decomposition)
سری را به مؤلفههای روند، فصلی و پسماند جدا میکند تا تحلیل آسانتر شود.
- STL (Seasonal-Trend decomposition using Loess)
سری را به مؤلفههای فصلی، روند و پسماند برای مدلسازی تجزیه میکند (روش STL بر پایه Loess است).
- همبستگی غلتان (Rolling Correlation)
همبستگی بین سریها را روی یک پنجره متحرک (moving window) محاسبه میکند تا تغییر روابط در طول زمان مشخص شود.
بصریسازی سری زمانی (Time Series Visualization)
بصریسازی کمک میکند دادههای وابسته به زمان را بررسی کنیم، تفسیر کنیم و بینشها را بهخوبی منتقل کنیم. «تکنیکهای رایج بصریسازی» اینها هستند:
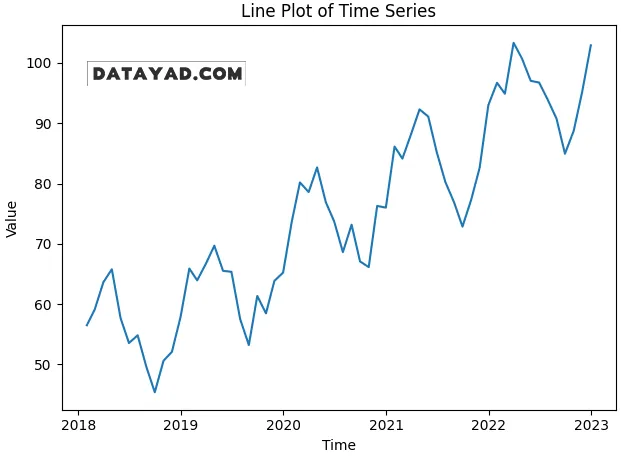
1) نمودارهای خطی (Line Plots)
نمودار خطی نشان میدهد یک متغیر در طول زمان چطور تغییر میکند و کمک میکند روندها (trends)، پرشها (jumps) و نوسانات (fluctuations) را راحتتر ببینید.
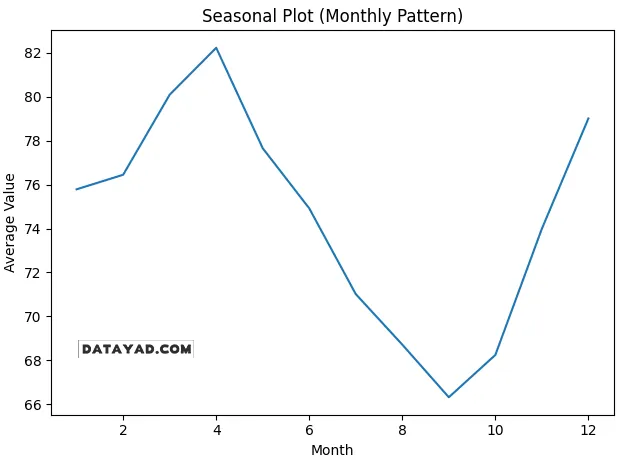
2) نمودارهای فصلی (Seasonal Plots)
نمودارهای فصلی، الگوهای تکرارشونده در طول ماهها، هفتهها یا فصلها را نمایش میدهند تا رفتار دورهای (periodic behavior) برجسته شود.
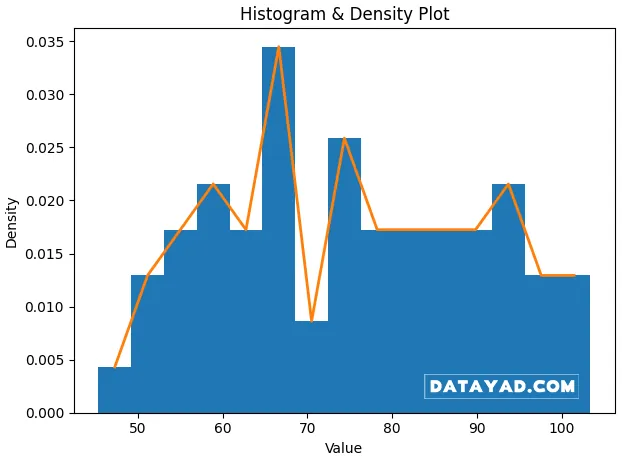
3) هیستوگرام و نمودار چگالی (Histograms and Density Plots)
این نمودارها توزیع مقادیر در یک سری زمانی را نشان میدهند و فهمیدن بازههای رایج و پراکندگی (spread) را آسان میکنند.
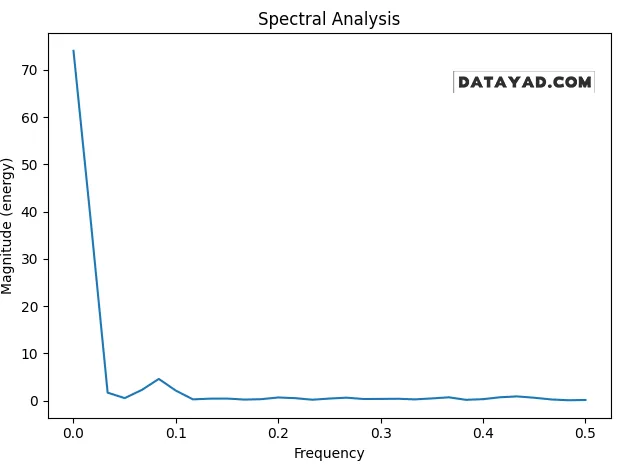
4) تحلیل طیفی (Spectral Analysis)
تحلیل طیفی، چرخههای فرکانسی غالب در داده را پیدا میکند و برای تشخیص الگوهای تکرارشونده بلندمدت مفید است.
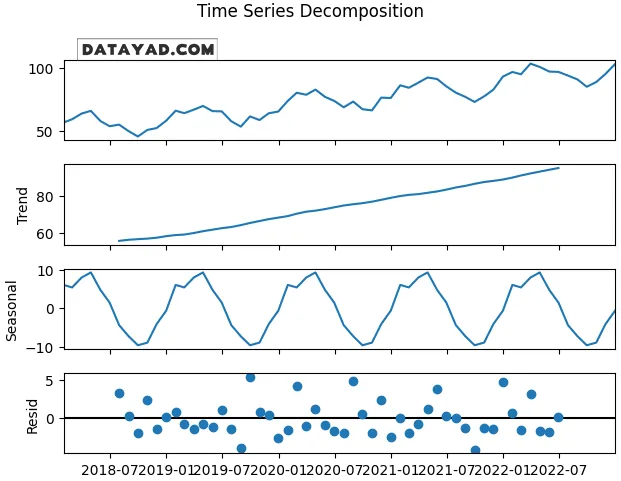
5) نمودارهای تجزیه (Decomposition Plots)
نمودارهای تجزیه، سری را به بخشهای روند (trend)، فصلی (seasonal) و باقیمانده/پسماند (residual) تقسیم میکنند تا ساختار زیرین داده واضحتر شود.
الگوریتمهای پیشبینی سری زمانی
مدلهای یادگیری ماشین
- Random Forest: مدل ensemble برای پیشبینی سری زمانی مبتنی بر رگرسیون.
- Gradient Boosting (GBM): درختهای boosting شده برای ثبت الگوهای پیچیده.
- Generalized Additive Models (GAM): ترکیب روندهای خطی و غیرخطی در سری.
مدلهای یادگیری عمیق
- RNN: شبکههای بازگشتی برای وابستگیهای ترتیبی.
- LSTM: شبکههای Long Short-Term Memory برای مدیریت وابستگیهای بلندمدت.
- GRU: واحدهای Gated Recurrent، جایگزینی سادهتر برای LSTM.
- Sequence-to-Sequence: معماری encoder-decoder برای سریهای زمانی پیچیده.
- CNN-based Models: ثبت الگوهای زمانی محلی با استفاده از لایههای کانولوشن.
مدلهای احتمالاتی و بیزی
- Gaussian Processes: مدلسازی احتمالاتی همراه با برآورد عدمقطعیت.
- State Space Models: نمایش سری بهصورت حالتهای نهفته که در طول زمان تکامل پیدا میکنند.
- Dynamic Linear Models (DLM): مدلهای خطیِ زمانمتغیر برای پیشبینی.
- Hidden Markov Models (HMM): مدلسازی سری با حالتهای پنهان زیرین.
یک متخصص علم داده باید بداند چه زمانی از مدلهای کلاسیک مثل ARIMA و چه زمانی از قدرت شبکههای عصبی پیچیده برای پیشبینی دقیقتر استفاده کند.
پیادهسازی گامبهگام
در این کد، یک گردشکار کامل «از ابتدا تا انتها» برای پیشبینی سری زمانی انجام میشود.
گام 1: نصب پکیجهای موردنیاز
- نصب کتابخانههایی که برای جستوجوی ARIMA، تجزیه (decomposition)، رسم نمودار و ارزیابی لازماند.
pmdarimaتابعauto_arimaرا ارائه میدهد تا مرتبههای ARIMA/SARIMA را بهصورت خودکار انتخاب کند.
!pip install --quiet pmdarima statsmodels matplotlib pandas numpy scikit-learn
گام 2: وارد کردن کتابخانهها
اینجا numpy، pandas، matplotlib، seaborn، statsmodels و scikit-learn را import میکنیم.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from statsmodels.tsa.seasonal import seasonal_decompose from statsmodels.tsa.stattools import adfuller from sklearn.metrics import mean_absolute_error, mean_squared_error import pmdarima as pm
گام 3: تولید یک سری زمانی ماهانه مصنوعی
- یک ایندکس تاریخ ماهانه برای
periodsنقطه زمانی بسازید. - یک مؤلفه روند خطی (linear trend) و یک مؤلفه فصلی سالانه (yearly seasonal component) بسازید.
- برای واقعیتر شدن سری، نویز گاوسی (Gaussian noise) اضافه کنید.
periods = 120
time_index = pd.date_range("2015-01-01", periods=periods, freq="M")
trend = np.linspace(50, 120, periods)
season = 10 * np.sin(2 * np.pi * time_index.month / 12)
noise = np.random.normal(0, 5, periods)
ts = trend + season + noise
گام 4: ساخت DataFrame
- سری تولیدشده را داخل یک DataFrame پانداس با اندیس Date قرار دهید.
- تنظیم Date بهعنوان index برای رسم نمودار، resampling و عملیات زمانمحور مهم است.
data = pd.DataFrame({"Date": time_index, "Value": ts})
data.set_index("Date", inplace=True)
data.head()
گام 5: نمایش سری زمانی خام
- سری مشاهدهشده را رسم کنید تا روند و فصلیبودن بررسی شود.
- یک بررسی سریع بصری کمک میکند درباره پیشپردازش و انتخاب مدل تصمیم بگیرید.
plt.figure(figsize=(12,5))
plt.plot(data.Value)
plt.title("Time Series Plot")
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
plt.show()
گام 6: مدیریت مقادیر گمشده
- اگر مقدار گمشده وجود داشته باشد، درونیابی (interpolate) آنها پیوستگی را برای الگوریتمهای سری زمانی حفظ میکند.
- این مرحله برای اغلب سریهای پیوسته و داده مصنوعی ساده، امن است.
data.Value = data.Value.interpolate()
گام 7: تشخیص و پاکسازی داده پرت با روش z-score
- z-score را محاسبه کنید تا مقادیر شدید (extreme) نسبت به میانگین/انحراف معیار شناسایی شوند.
- مقادیری که z-score آنها > 3 است را با میانه (median) سری جایگزین کنید.
z = np.abs((data.Value - data.Value.mean()) / data.Value.std()) data["Value_clean"] = np.where(z > 3, data.Value.median(), data.Value)
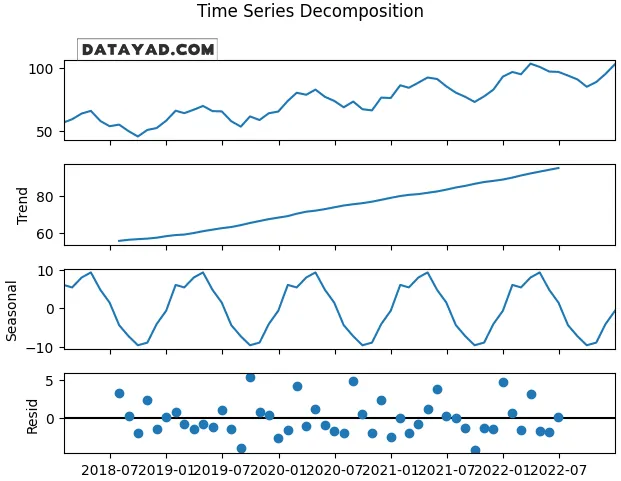
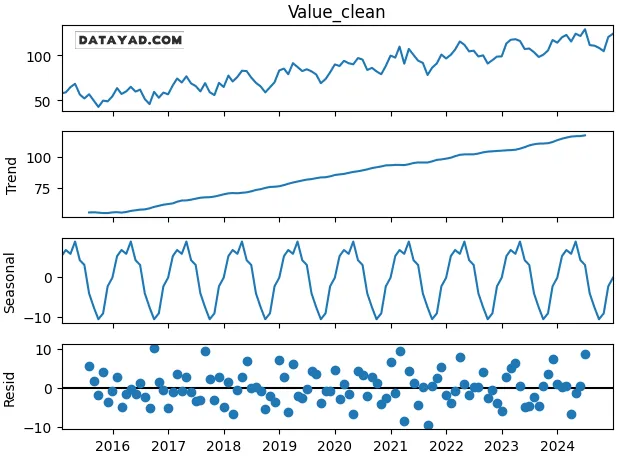
گام 8: تجزیه سری زمانی
- از
seasonal_decompose(مدل additive وperiod=12برای فصلیبودن ماهانه) استفاده کنید. - مؤلفه روند، مؤلفه فصلی و باقیمانده (residual) را برای تصمیمگیری مدلسازی بصریسازی کنید.
- تجزیه کمک میکند بین مدلهای additive و multiplicative تصمیم بگیرید.
decomp = seasonal_decompose(data.Value_clean.dropna(), model="additive", period=12) decomp.plot() plt.show()
گام 9: آموزش SARIMA خودکار (Train automatic SARIMA)
- از
pmdarima.auto_arimaبرای جستوجوی خودکار بهترین پارامترهای ARIMA فصلی استفاده کنید. seasonal=Trueوm=12یعنی فصلیبودن ماهانه تنظیم شده است.
model = pm.auto_arima(
train,
seasonal=True,
m=12,
trace=True,
error_action="ignore",
suppress_warnings=True
)
model.summary()
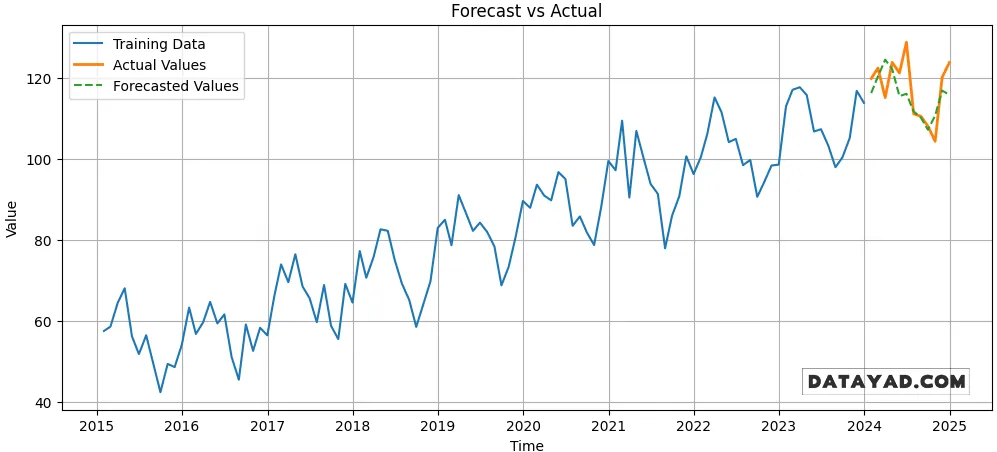
گام 10: پیشبینی روی مجموعه تست و رسم نتایج
- ۱۲ دوره بعدی را پیشبینی کنید و پیشبینیها را با اندیس تست همتراز (align) کنید.
- داده train، مقادیر واقعی test و مقادیر پیشبینیشده را برای مقایسه بصری رسم کنید.
forecast = model.predict(n_periods=12)
forecast = pd.Series(forecast, index=test.index)
plt.figure(figsize=(12,5))
plt.plot(train, label='Training Data')
plt.plot(test, label='Actual Values', linewidth=2)
plt.plot(forecast, label='Forecasted Values', linestyle="--")
plt.title("Forecast vs Actual")
plt.xlabel("Time")
plt.ylabel("Value")
plt.legend()
plt.grid(True)
plt.show()
کاربردهای سری زمانی
پیشبینی سری زمانی در صنایع مختلف برای پیشبینی مقادیر آینده و پشتیبانی از تصمیمگیری بهطور گسترده استفاده میشود:
- مدلسازی آبوهوا و اقلیم: پیشبینی دما، بارش و رخدادهای شدید.
- مالی و پیشبینی سهام: پیشبینی قیمت سهام، بازدهها و روندهای بازار.
- پیشبینی تقاضا: تخمین تقاضای محصول یا خدمت برای بهینهسازی موجودی.
- فروش خردهفروشی: پیشبینی الگوهای فروش و روندهای فصلی.
- پیشبینی ترافیک: تخمین جریان ترافیک برای برنامهریزی شهری و بهینهسازی مسیر.
محدودیتهای سری زمانی
پیشبینی سری زمانی تکنیک مفیدی است، اما چند محدودیت و چالش دارد:
- مقادیر گمشده: شکافهای داده دقت و قابلیت اعتماد مدل را کم میکنند.
- داده محدود: سابقه تاریخی کوتاه مانع پیشبینی دقیق میشود.
- ناایستایی (Non-Stationarity): تغییر میانگین یا واریانس در طول زمان روی پایداری مدل اثر میگذارد.
- رانش فصلی (Seasonal Drift): الگوهای فصلی ممکن است در طول سالها جابهجا شوند و پیشبینی را سخت کنند.
- رانش مفهوم (Concept Drift): الگوهای زیربنایی در طول زمان تغییر میکنند و ارتباط مدل را کمتر میکنند.
- بیشبرازش در مدلهای ML/DL: مدلهای پیچیده ممکن است به جای الگوی واقعی، نویز را یاد بگیرند و تعمیمپذیری بد شود.
چگونه تحلیل سری زمانی را به صورت حرفهای و در سطح بازار کار یاد بگیریم؟
تحلیل و پیشبینی سری زمانی، قلهای است که برای فتح آن باید پایه و اساسی مستحکم داشته باشید. اگر میخواهید از صفر مطلق شروع کنید و به یک متخصص تمامعیار تبدیل شوید، باید مسیری را طی کنید که تمام ابعاد این تخصص را پوشش دهد.
در دوره علم داده، ما این مسیر را برای شما ترسیم کردهایم. شما در این دوره فقط کدنویسی یاد نمیگیرید؛ بلکه یک سفر کامل را تجربه میکنید:
- پایتون و ریاضیات پایه: تسلط بر ابزارها و منطق مورد نیاز.
- تحلیل و بصریسازی داده: یادگیری نحوه استخراج بینش از دادههای خام.
- یادگیری ماشین (Machine Learning): پیادهسازی الگوریتمهای پیشرفته پیشبینی.
- یادگیری عمیق (Deep Learning): کار با شبکههای عصبی برای حل پیچیدهترین مسائل زمانی.




















