

تحلیل احساسات یا نظرکاوی یکی از شاخههای کلیدی پردازش زبان طبیعی است که به استخراج حالات درونی، نظرات و نگرشهای موجود در متنهای دیجیتال میپردازد. این فناوری با استفاده از الگوریتمهای هوش مصنوعی، متون غیرساختاریافته را بررسی کرده و آنها را در دستههای مثبت، منفی یا خنثی طبقهبندی میکند تا درک عمیقتری از بازخورد مخاطبان حاصل شود.
با انفجار دادهها در فضای مجازی، تحلیل دستی حجم عظیم پیامها، ایمیلها و نظرات کاربران غیرممکن شده است. سیستمهای هوش مصنوعی با حذف سوگیریهای انسانی و افزایش سرعت پردازش، به سازمانها کمک میکنند تا نبض بازار را در دست بگیرند و بر اساس دادههای واقعی، تصمیمات استراتژیک اتخاذ کنند. در این مطلب از بخش آموزش هوش مصنوعی، قصد داریم به بررسی جامعتر مفاهیم و کاربردهای این فناوری جذاب بپردازیم.
تحلیل احساسات چیست؟
وقتی هر روز میلیونها نظر، پیام و توییت در اینترنت منتشر میشود، این سؤال مطرح میشود که ماشینها چگونه میتوانند این حجم عظیم از دادههای متنی را درک کنند؟ اینجاست که پردازش زبان طبیعی (NLP) وارد میدان میشود. NLP به سیستمهای هوشمند کمک میکند زبان انسان را بفهمند، ساختار آن را تحلیل کنند و حتی احساسات پنهان در پسِ کلمات را استخراج کنند. یکی از مهمترین کاربردهای این فناوری، تحلیل احساسات است؛ جایی که مدلهای زبانی با استفاده از یادگیری ماشین و یادگیری عمیق، لحن و نگرش کاربران را به دادههای قابل تحلیل تبدیل میکنند. در ادامه، دقیقتر بررسی میکنیم که این فرآیند چگونه کار میکند و چه مدلهایی پشت این فناوری قرار دارند.
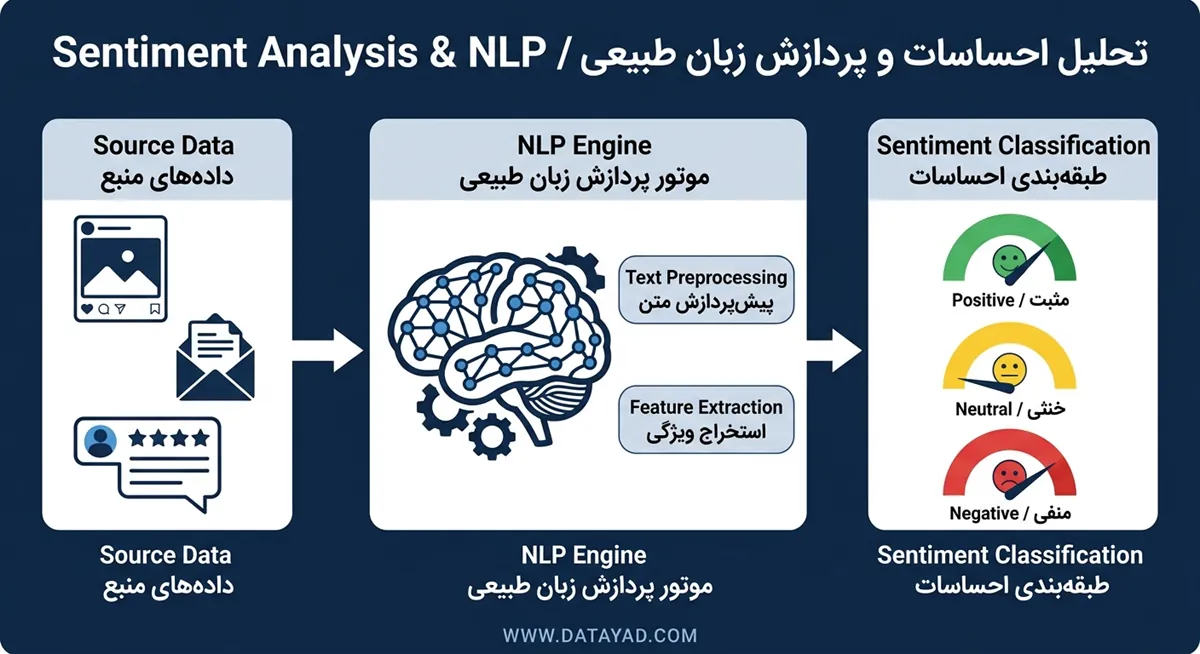
تحلیل احساسات با هوش مصنوعی چگونه کار میکند؟
فرآیند تحلیل احساسات بر پایه تبدیل دادههای زبانی و کیفی به متغیرهای عددی و کمی استوار است. هوش مصنوعی با استفاده از تکنیکهای محاسباتی، الگوهای تکرارشونده در متن را شناسایی کرده و آنها را به دستههای ساختاریافته تخصیص میدهند. این سیستمها به جای درک شهودی، بر وزن آماری و بافتار قرارگیری واژگان برای تعیین بار معنایی جملات تمرکز میکنند.
تعریف قطبیت و تشخیص لحن
قطبیت (Polarity) هسته اصلی تحلیل احساسات است که جهتگیری کلی یک متن را در دستههای مثبت، منفی یا خنثی مشخص میکند. سیستمهای پیشرفته با اختصاص کدهای عددی به کلمات، مجموع امتیاز یک پاراگراف را محاسبه کرده و شدت احساس را در طیفهای دقیقتری نمایش میدهند. این امتیازدهی به تحلیلگران کمک میکند تا مرز بین یک نارضایتی ساده و یک بحران جدی در بازخوردها را به درستی تشخیص دهند.
تشخیص لحن، گامی فراتر از تعیین قطبیت ساده است و بر شناسایی اتمسفر حاکم بر نوشتار تمرکز دارد. در این مرحله، الگوریتمها تلاش میکنند حالات روانی نویسنده مانند خشم، شادی، تردید یا اطمینان را از میان کلمات استخراج کنند. شناسایی این لایههای زیرین برای درک مقصود واقعی کاربر در محیطهای تعاملی و پشتیبانی مشتریان ضروری است.
اهمیت استخراج بینش از دادههای متنی
در پردازش زبان طبیعی استخراج بینش از متون غیرساختاریافته امکان تحلیل عینی و بدون سوگیری حجم انبوهی از پیامها و نظرات را فراهم میکند. مدلهای هوش مصنوعی با حذف خطای انسانی در تفسیر سلیقهای، دادههای پراکنده را به شاخصهای عملکردی قابل اندازهگیری تبدیل میکنند. این رویکرد باعث میشود تصمیمات سازمانی به جای فرضیات ذهنی، بر اساس الگوهای واقعی استخراج شده از بطن جامعه آماری اتخاذ شود.
دادههای متنی حاوی سیگنالهای ارزشمندی از تغییرات بازار و نیازهای پنهان کاربران هستند که با روشهای سنتی قابل شناسایی نیستند. پردازش خودکار این دادهها سرعت پاسخگویی به تغییرات محیطی را به شکل چشمگیری افزایش میدهد. تبدیل کلمات به دانش عملیاتی، توانایی پیشبینی رفتار مخاطب و بهینهسازی تجربه کاربری را در مقیاس بزرگ ممکن میسازد.
انواع مدلهای تحلیل احساسات
انتخاب معماری مناسب برای تحلیل متن مستقیماً به اهداف تجاری و پیچیدگی دادههای ورودی بستگی دارد. مدلهای پیشرفته با عبور از لایههای سطحی کلمات، ساختارهای متفاوتی را برای استخراج الگوهای معنایی به کار میگیرند. هر یک از این مدلها بر جنبه خاصی از زبان تمرکز دارند تا دقت خروجی را در بافتارهای مختلف تضمین کنند.
تحلیل احساسات دقیق (Fine-grained)
- تفکیک طیفی: این مدل به جای طبقهبندی ساده در سه دسته مثبت، منفی و خنثی، احساسات را در پنج سطح یا بیشتر (مانند بسیار مثبت تا بسیار منفی) بررسی میکند.
- امتیازدهی عددی: استفاده از مقیاسهای ۱ تا ۵ ستاره در نظرسنجیهای آنلاین، خروجی استاندارد این مدل برای سنجش شدت رضایت کاربران است.
- دقت در جزئیات: این رویکرد به تحلیلگران اجازه میدهد تا تغییرات کوچک در لحن مشتریان را شناسایی کرده و مرز بین رضایت معمولی و وفاداری کامل را تشخیص دهند.
تشخیص احساسات (Emotion Detection)
- شناسایی حالات روانی: این سیستمها فراتر از قطبیت عمل کرده و حالات خاصی نظیر خشم، شادی، ترس، ناامیدی و هیجان را در متن شناسایی میکنند.
- تحلیل ریشهای: مدلهای تشخیص احساس معمولاً از لغتنامههای پیچیده یا شبکههای عصبی برای درک محرکهای عاطفی نویسنده استفاده میکنند.
- کاربرد در پشتیبانی: شناسایی فوری مشتریان «مستاصل» یا «خشمگین» در صفهای انتظار، به سیستمهای هوشمند اجازه میدهد تا اولویت پاسخگویی را به موارد بحرانی اختصاص دهند.
تحلیل جنبهمحور (Aspect-based)
- تمرکز بر ویژگیها: این مدل به جای ارزیابی کل متن، احساسات را نسبت به اجزای خاص یک محصول (مانند باتری، قیمت یا طراحی) تفکیک میکند.
- استخراج بینش عملیاتی: برای مثال، در نقد یک رستوران، ممکن است نظر کاربر درباره «کیفیت غذا» مثبت و درباره «سرعت سرویسدهی» منفی باشد که این مدل هر دو را به صورت مجزا ثبت میکند.
- بهینهسازی محصول: دادههای استخراج شده از این روش مستقیماً توسط تیمهای تحقیق و توسعه برای رفع نواقص فنی در نسخههای بعدی استفاده میشود.
تحلیل چندزبانه و مبتنی بر قصد
- پردازش فرامرزی: مدلهای چندزبانه با در نظر گرفتن تفاوتهای فرهنگی و دستوری، امکان تحلیل همزمان متون به زبانهای مختلف را در بازارهای جهانی فراهم میکنند.
- کشف هدف (Intent): تحلیل مبتنی بر قصد به دنبال تشخیص مقصود نهایی کاربر از نگارش متن است؛ مانند تمایل به خرید، پرسش درباره قیمت یا اعلام شکایت.
- اتوماسیون بازاریابی: ترکیب این دو قابلیت به سازمانها کمک میکند تا سیگنالهای خرید را از میان انبوه پیامهای اجتماعی در سطح بینالمللی شناسایی و به تیم فروش هدایت کنند.
مقایسه رویکردهای پیادهسازی تحلیل احساسات
انتخاب استراتژی پیادهسازی مستقیماً بر کارایی سیستم در مواجهه با ابهامهای زبانی و حجم دادههای ورودی اثر میگذارد. مهندسان داده بر اساس توازن میان دقت محاسباتی، منابع سختافزاری و پیچیدگی بافتار متنی، یکی از متدولوژیهای اصلی را برای استخراج قطبیت انتخاب میکنند. هر یک از این روشها مسیر متفاوتی را برای تبدیل کلمات به بردارهای عددی و دانش عملیاتی طی میکنند.
روش مبتنی بر قانون (Rule-based)
این رویکرد بر مجموعهای از لغتنامههای از پیش تعریف شده و قواعد نحوی دقیق استوار است. در این سیستم، کلمات بر اساس بار معنایی موجود در دیکشنریهای تخصصی امتیازدهی شده و مجموع این امتیازها جهتگیری نهایی متن را مشخص میکند. اگرچه این متدولوژی نیازی به مجموعهدادههای آموزشی حجیم ندارد، اما در تشخیص طنز، کنایه و ساختارهای پیچیده زبانی با محدودیتهای جدی روبرو است.
یادگیری ماشین (Machine Learning)
رویکرد یادگیری ماشین با استفاده از الگوریتمهای طبقهبندی نظیر SVM و Naive Bayes، الگوهای معنایی را از درون دادههای برچسبگذاری شده استخراج میکند. در این روش، ویژگیهای متنی از طریق تکنیکهایی مانند فراوانی کلمات به کدهای عددی تبدیل میشوند تا مدل بتواند مرزهای آماری میان احساسات مختلف را ترسیم کند. دقت این مدلها وابستگی مستقیمی به کیفیت برچسبگذاری اولیه و تنوع نمونههای آموزشی در دامنه موضوعی مورد نظر دارد.
یادگیری عمیق (Deep Learning)
شبکههای عصبی عمیق و معماریهای پیشرفته مبتنی بر ترنسفورمر، توانایی درک روابط ترتیبی و بافتار کلی جملات را فراهم میکنند. این مدلها به جای بررسی مجزای واژگان، لایههای پنهان معنایی و وابستگیهای طولانیمدت میان کلمات را پردازش کرده و بالاترین سطح دقت را در زبانهای طبیعی ارائه میدهند. با وجود قدرت تحلیل بالا، این رویکرد به زیرساختهای پردازشی قدرتمند و زمان طولانی برای آموزش مدلهای اولیه نیاز دارد.

روشهای ترکیبی (Hybrid)
معماریهای ترکیبی با هدف بهرهبرداری از سرعت روشهای لغتنامهای و دقت مدلهای یادگیری عمیق طراحی میشوند. در این سیستمها، ابتدا قوانین پایه برای فیلتر کردن موارد ساده و تکراری به کار میروند و سپس تحلیلهای پیچیده و حساس به لایههای عصبی واگذار میشود. این استراتژی باعث بهینهسازی مصرف منابع و افزایش پایداری سیستم در مواجهه با دادههای غیرساختاریافته و نویزی میشود.
| شاخص مقایسه | روش مبتنی بر قانون | یادگیری ماشین | یادگیری عمیق | روشهای ترکیبی |
|---|---|---|---|---|
| منطق اصلی | قواعد دستوری و لغتنامه | الگوریتمهای آماری | شبکههای عصبی مصنوعی | تلفیق قواعد و الگوریتم |
| نیاز به داده | بسیار کم | متوسط (برچسبدار) | بسیار زیاد | متغیر بر اساس معماری |
| دقت تحلیل | پایین | متوسط به بالا | بسیار بالا | بهینه و پایدار |
| پیچیدگی اجرا | ساده و سریع | متوسط | بسیار بالا | بالا |
مراحل فنی پردازش متون
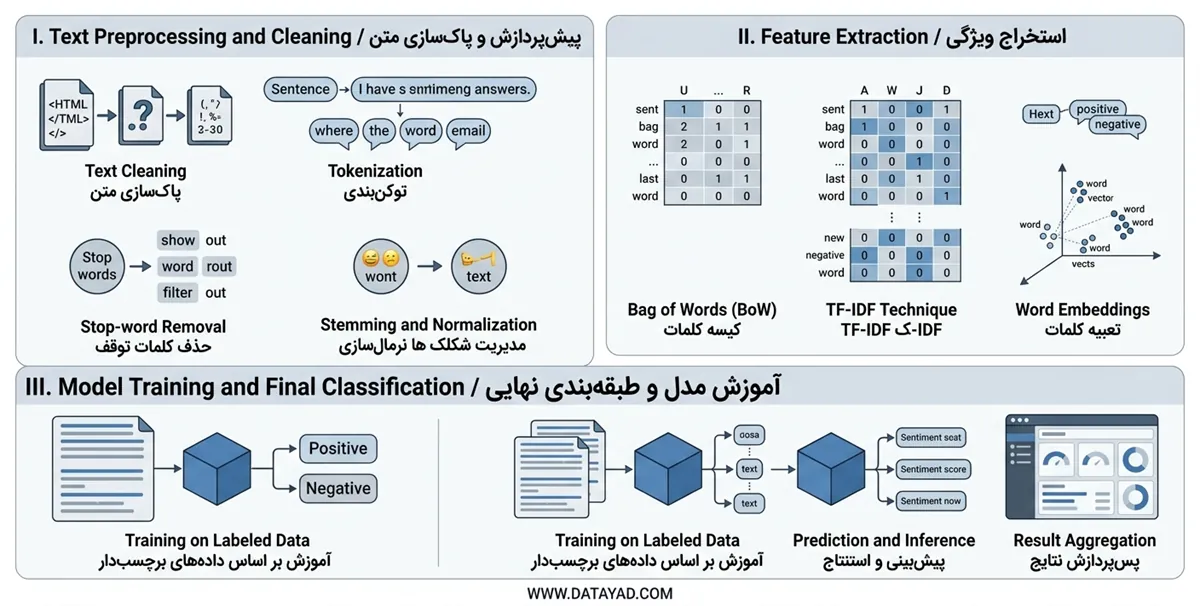
تبدیل متن خام به دانش عملیاتی نیازمند طی کردن یک پایپ لاین پردازشی دقیق است که دادههای غیرساختاریافته را برای الگوریتمهای ریاضی مهیا میکند. این نقشه راه فنی، از پاکسازی ابتدایی شروع شده و با استخراج الگوهای عددی، بستر لازم برای تصمیمگیری مدل را فراهم میسازد. دقت نهایی سیستم مستقیماً به کیفیت اجرای این مراحل و کاهش نویزهای زبانی بستگی دارد.
پیشپردازش و پاکسازی دادهها
- پاکسازی متن: حذف تگهای HTML، نویسههای خاص، اعداد و علائم نگارشی که بار معنایی در تحلیل احساسات ندارند و باعث ایجاد اختلال در محاسبات میشوند.
- توکنبندی (Tokenization): تجزیه جملات و پاراگرافها به واحدهای کوچکتر به نام توکن برای بررسی مجزای هر کلمه یا عبارت در ساختار زبانی.
- حذف کلمات توقف (Stop-words): فیلتر کردن واژگان پرتکرار و فاقد ارزش تحلیلی مانند «و»، «در» و «به» جهت تمرکز بر کلمات کلیدی حامل احساس.
- ریشهیابی و نرمالسازی: تبدیل کلمات به ریشه اصلی (Stemming) یا شکل لغتنامهای (Lemmatization) برای یکسانسازی کلمات همخانواده و کاهش ابعاد برداری.
- مدیریت شکلکها و اصطلاحات: تبدیل ایموجیها، اختصارات و کلمات عامیانه به معادلهای استاندارد متنی برای حفظ بار عاطفی موجود در زبان محاوره.
استخراج ویژگی (Feature Extraction)
- کیسه کلمات (Bag of Words): سادهترین روش برای تبدیل متن به بردارهای عددی بر اساس تکرار واژگان در یک سند بدون در نظر گرفتن ترتیب آنها.
- تکنیک TF-IDF: وزندهی هوشمند به کلمات به گونهای که واژگان منحصربهفرد و مهم وزن بیشتر و کلمات عمومی موجود در کل بدنه داده وزن کمتری دریافت کنند.
- تعبیه کلمات (Word Embeddings): نمایش کلمات در قالب بردارهای متراکم که روابط معنایی و شباهتهای بافتاری میان واژگان را در یک فضای چندبعدی حفظ میکنند.
آموزش مدل و طبقهبندی نهایی
- آموزش بر اساس دادههای برچسبدار: تغذیه مدل با مجموعهدادههای آموزشی که قبلاً توسط انسان برچسبگذاری شدهاند تا الگوهای تمایز بین قطبیتهای مختلف شناسایی شود.
- پیشبینی و استنتاج: اعمال الگوهای آماری یاد گرفته شده بر روی دادههای جدید و غیرتکراری برای اختصاص برچسب احساسی یا امتیاز عددی.
- پسپردازش نتایج: تجمیع امتیازات استخراج شده از بخشهای مختلف متن برای ارائه تحلیل نهایی در سطح کل سند یا جنبههای خاص موضوعی.
چالشهای تحلیل احساسات با هوش مصنوعی
اجرای دقیق مراحل فنی پردازش متن، لزوماً به معنای درک کامل پیام توسط ماشین نیست. پیچیدگیهای ذاتی زبان طبیعی باعث میشود که حتی پیشرفتهترین مدلهای یادگیری عمیق نیز در مواجهه با لایههای پنهان معنا دچار خطا شوند. این موانع زمانی پدیدار میشوند که فاصله میان معنای تحتاللفظی و قصد واقعی نویسنده افزایش یابد.
درک کنایه و طنز در نوشتار
تشخیص کنایه و طنز، یکی از دشوارترین مراحل برای الگوریتمهای مبتنی بر کلمات کلیدی محسوب میشود. در این ساختارها، نویسنده از واژگان مثبت برای انتقال پیامی کاملاً منفی استفاده میکند که منجر به گمراهی مدلهای ساده میشود. به عنوان مثال، عبارت «چه عالی، باز هم سیستم کرش کرد!» حاوی کلمه مثبت «عالی» است، اما بار معنایی آن در این بافتار کاملاً اعتراضی است. سیستمهای هوشمند بدون درک لحن و دانش عمومی، این قبیل جملات را به اشتباه در دسته بازخوردهای مثبت طبقهبندی میکنند.
مدیریت جملات نقیض و مبهم
جملات نقیض توازن قطبیت را در کل ساختار عبارت تغییر میدهند و شناسایی دقیق محدوده اثرگذاری آنها برای هوش مصنوعی چالشبرانگیز است. کلماتی مانند «نباید»، «هرگز» یا «به هیچ وجه» میتوانند بار معنایی کلمات مجاور خود را کاملاً معکوس کنند. علاوه بر این، وجود ابهام در جملاتی که چندین تفسیر متفاوت دارند، مدل را در انتخاب برچسب نهایی دچار تردید میکند. عدم مدیریت صحیح این ساختارهای دستوری، منجر به استخراج نتایج متناقض و کاهش دقت عملیاتی سیستم میشود.
وابستگی به بافتار و دامنه موضوعی
قطبیت واژگان ثابت نیست و به شدت به دامنه موضوعی و بافتار خاص متن بستگی دارد. کلمهای مانند «غیرقابل پیشبینی» در نقد یک رمان هیجانانگیز امتیازی مثبت تلقی میشود، اما در بررسی عملکرد ترمز یک خودرو، نشاندهنده نقص فنی و بار منفی است. اکثر مدلهای زبانی در انتقال دانش از یک حوزه تخصصی به حوزه دیگر دچار افت کارایی میشوند. به همین دلیل، موفقیت در تحلیل احساسات مستلزم بومیسازی مدل بر اساس فرهنگ لغت تخصصی و ویژگیهای منحصر به فرد هر صنعت است.
ابزارها و کتابخانههای محبوب تحلیل احساسات
غلبه بر چالشهای فنی و زبانی مطرح شده نیازمند انتخاب زیرساختهای نرمافزاری متناسب با حجم و نوع دادههای متنی است. ابزارهای مدرن با خودکارسازی فرآیندهای پیچیده آماری، فاصله میان متون خام و بینشهای عملیاتی را کاهش میدهند. این ابزارها در سه سطح کتابخانههای برنامهنویسی، مدلهای هوش مصنوعی پیشرفته و سرویسهای آماده ابری دستهبندی میشوند.
کتابخانههای پایتونی NLTK و TextBlob
- NLTK: این کتابخانه به عنوان یک پلتفرم جامع در پردازش زبان طبیعی، مجموعهای غنی از لغتنامههای برچسبگذاری شده و ابزارهای متنوع برای توکنبندی و ریشهیابی را ارائه میدهد.
- TextBlob: این ابزار با سادهسازی توابع پیچیده NLTK، امکان استخراج قطبیت (Polarity) و ذهنیت (Subjectivity) را تنها با چند خط کد فراهم میکند و برای نمونهسازیهای سریع ایدهآل است.
- VADER: یک ابزار اختصاصی مبتنی بر قانون است که قدرت بالایی در تحلیل متون کوتاه شبکههای اجتماعی و تشخیص شدت احساسات بر اساس اصطلاحات و علائم نگارشی دارد.
- SpaCy: این کتابخانه با تمرکز بر عملکرد صنعتی، فرآیند تحلیل احساسات را با استفاده از مدلهای آماری بهینه و سرعت پردازش بسیار بالا در پروژههای بزرگ تسهیل میکند.
مدلهای تحلیل احساسات با هوش مصنوعی مانند BERT
- درک دوطرفه بافتار: مدلهایی مانند BERT برخلاف روشهای سنتی، کلمات را به صورت همزمان با توجه به کلمات قبل و بعد از آنها بررسی کرده و معنای دقیق واژه را در بافتار جمله شناسایی میکنند.
- یادگیری انتقالی: این مدلها ابتدا بر روی مخازن عظیم داده آموزش دیدهاند و میتوان با صرف زمان و دادههای کمتر، آنها را برای دامنههای موضوعی خاص یا زبانهای مختلف بومیسازی کرد.
- بهینهسازی دقت: استفاده از مدلهای مشتق شده نظیر RoBERTa و DistilBERT باعث افزایش دقت در تشخیص پیچیدگیهای زبانی مانند کنایه و روابط معنایی پنهان در جملات طولانی میشود.
- تحلیل چندزبانه: نسخههای چندزبانه این مدلها توانایی پردازش متون در دامنههای وسیعی از زبانها را دارند که برای تحلیل دیدگاههای کاربران در سطح جهانی بسیار کاربردی است.
سرویسهای ابری گوگل و آمازون
- Google Cloud Natural Language: این سرویس با بهرهگیری از مدلهای قدرتمند گوگل، امکان استخراج احساسات را در سطح کل سند یا به تفکیک نهادهای موجود در متن فراهم میکند.
- Amazon Comprehend: یک سرویس کاملاً مدیریت شده که از یادگیری ماشین برای یافتن بینشها و روابط در متن استفاده کرده و نیاز به مدیریت زیرساختهای سختافزاری را حذف میکند.
- مقیاسپذیری عملیاتی: این پلتفرمهای ابری قادر به پردازش میلیونها رکورد در ساعت هستند و برای سازمانهایی که با جریانهای مداوم و حجیم دادههای مشتریان روبرو هستند، گزینهای پایدار محسوب میشوند.
- یکپارچگی با اکوسیستمهای تحلیل داده: خروجی این سرویسها به راحتی با ابزارهای بصریسازی داده و پایگاههای داده ابری ادغام میشود تا فرآیند تصمیمگیری بر اساس احساسات کاربران تسریع یابد.
برای متخصص شدن در NLP و LLM از کجا شروع کنیم؟
اگر به تحلیل احساسات با هوش مصنوعی، مدلهای ترنسفورمر و معماریهایی مانند BERT و GPT علاقهمند شدهاید، وقت آن رسیده که فراتر از مطالعه تئوری حرکت کنید. بازار کار هوش مصنوعی امروز به متخصصانی نیاز دارد که بتوانند مدلهای زبانی بزرگ (LLM) را آموزش دهند، فاینتیون کنند و در پروژههای واقعی پیادهسازی کنند.
برای تبدیل شدن به یک متخصص حرفهای در حوزه پردازش زبان طبیعی باید این مهارتها را یاد بگیرید:
- مبانی کامل NLP و پیشپردازش متن
- پیادهسازی الگوریتمهای یادگیری ماشین برای متن
- کار با شبکههای عصبی و معماریهای ترنسفورمر
- فاینتیون کردن مدلهایی مانند BERT و ParsBERT
- کار عملی با مدلهای زبانی بزرگ (LLM) مانند GPT
- ساخت پروژههای واقعی تحلیل احساسات و چتبات
اگر میخواهید این مهارتها را بهصورت پروژهمحور و کاربردی یاد بگیرید و وارد بازار کار هوش مصنوعی شوید، پیشنهاد میکنیم از دوره جامع آموزش پردازش زبان طبیعی و مدلهای زبانی بزرگ شروع کنید. در این دوره، از مفاهیم پایه تا پیادهسازی مدلهای پیشرفته را قدمبهقدم یاد میگیرید و آماده اجرای پروژههای صنعتی میشوید. همین حالا مسیر حرفهای خود در NLP و LLM را شروع کنید و به جمع متخصصان هوش مصنوعی بپیوندید.

سوالات متداول
بهرهگیری از ابزارهای ابری و کتابخانههای تخصصی، اگرچه فرآیند پردازش را تسهیل میکند، اما پیادهسازی نهایی مستلزم درک دقیق ظرافتهای معنایی و چالشهای بومیسازی است. پاسخ به پرسشهای زیر به شفافسازی مسیر انتخاب رویکرد مناسب در پروژههای تحلیل متن کمک میکند.
تفاوت تحلیل احساسات با تحلیل معنایی چیست؟
تحلیل احساسات صرفاً بر شناسایی بار عاطفی، نظرات و قطبیت متن (مثبت، منفی یا خنثی) تمرکز دارد. در مقابل، تحلیل معنایی به دنبال درک معنای منطقی کلمات، شناسایی روابط میان اجزای جمله و درک مفاهیم انتزاعی در یک بافتار مشخص است.
آیا هوش مصنوعی میتواند لحن طعنهآمیز را تشخیص دهد؟
مدلهای پیشرفته یادگیری عمیق مانند ترنسفورمرها با تحلیل روابط دوطرفه بین کلمات، تا حد زیادی قادر به تشخیص کنایه هستند. با این حال، به دلیل تضاد میان معنای تحتاللفظی و قصد واقعی نویسنده، تشخیص طنز همچنان یکی از پیچیدهترین چالشهای پردازش زبان طبیعی محسوب میشود.
بهترین الگوریتم برای تحلیل احساسات در زبان فارسی کدام است؟
مدلهای مبتنی بر معماری BERT، به ویژه نسخههای بومیسازی شده مانند ParsBERT، در حال حاضر بالاترین دقت را در پردازش زبان فارسی دارند. این مدلها به دلیل آموزش بر روی مخازن عظیم دادههای فارسی، تفاوتهای ساختاری و ویژگیهای صرفی این زبان را بهتر درک میکنند.
چگونه میتوان دقت مدلهای تحلیل احساسات را افزایش داد؟
بهبود کیفیت پیشپردازش دادهها، استفاده از مجموعهدادههای برچسبگذاری شده در دامنه موضوعی خاص و بهکارگیری روشهای ترکیبی (Hybrid) که قواعد لغوی را با مدلهای آماری ادغام میکنند، از موثرترین راهکارها برای ارتقای دقت خروجی سیستم است.




















