

در این مطلب از بخش آموزش هوش مصنوعی، به بررسی سیستمهای توصیهگر (Recommendation Systems) میپردازیم که به عنوان یکی از شاخههای حیاتی هوش مصنوعی، نقشی کلیدی در مدیریت حجم انبوه دادهها و شخصیسازی تجربهی کاربران ایفا میکنند. این سیستمها با استفاده از الگوریتمهای یادگیری ماشین، الگوهای رفتاری و ترجیحات فردی را شناسایی کرده و میان گزینههای بیپایان، مرتبطترین موارد را به کاربر پیشنهاد میدهند تا فرآیند تصمیمگیری تسهیل شود.
در دنیای مدرن، از پلتفرمهای تجارت الکترونیک گرفته تا سرویسهای پخش موسیقی و رسانههای اجتماعی، همگی بر پایهی این موتورهای هوشمند استوار هستند. هدف نهایی این سیستمها نه تنها افزایش نرخ تعامل و فروش، بلکه ایجاد ارزش افزوده از طریق کشف محتوای جدید و متناسب با علایق کاربر است که در حالت عادی ممکن بود هرگز توسط او یافت نشود.
سیستمهای توصیهگر چیست و چرا در دنیای دیجیتال اهمیت دارند؟
در دنیای امروز کاربران با حجم بسیار بزرگی از اطلاعات، محصولات و محتوا مواجه هستند. از فروشگاههای اینترنتی گرفته تا پلتفرمهای استریم فیلم و موسیقی، انتخاب بهترین گزینه از میان هزاران یا حتی میلیونها مورد کار سادهای نیست. در چنین شرایطی سیستمهای توصیهگر (Recommendation Systems) به عنوان یکی از مهمترین کاربردهای هوش مصنوعی وارد عمل میشوند. اگر در مورد مفاهیم و مبانی هوش مصنوعی سوالاتی در ذهن دارید مقاله هوش مصنوعی چیست؟ بهترین منبع مطالعاتی شماست.
سیستمهای توصیهگر با تحلیل رفتار کاربران، سابقه تعاملات و ویژگیهای محتوا تلاش میکنند مناسبترین گزینهها را به هر کاربر پیشنهاد دهند. برای مثال زمانی که در یک فروشگاه آنلاین بخش «محصولات پیشنهادی برای شما» را مشاهده میکنید یا در یک پلتفرم ویدیویی لیستی از فیلمهای پیشنهادی دریافت میکنید، در واقع یک سیستم توصیهگر در حال تصمیمگیری است.
هدف اصلی این سیستمها کاهش سردرگمی کاربر، افزایش سرعت تصمیمگیری و ارائه تجربهای شخصیسازیشده است. به همین دلیل امروزه تقریباً تمام پلتفرمهای بزرگ دیجیتال مانند آمازون، نتفلیکس، یوتیوب و اسپاتیفای از الگوریتمهای پیشرفته توصیهگر استفاده میکنند.
در ادامه این مقاله با ساختار فنی، الگوریتمها و معماریهای مختلف سیستمهای توصیهگر آشنا میشویم.
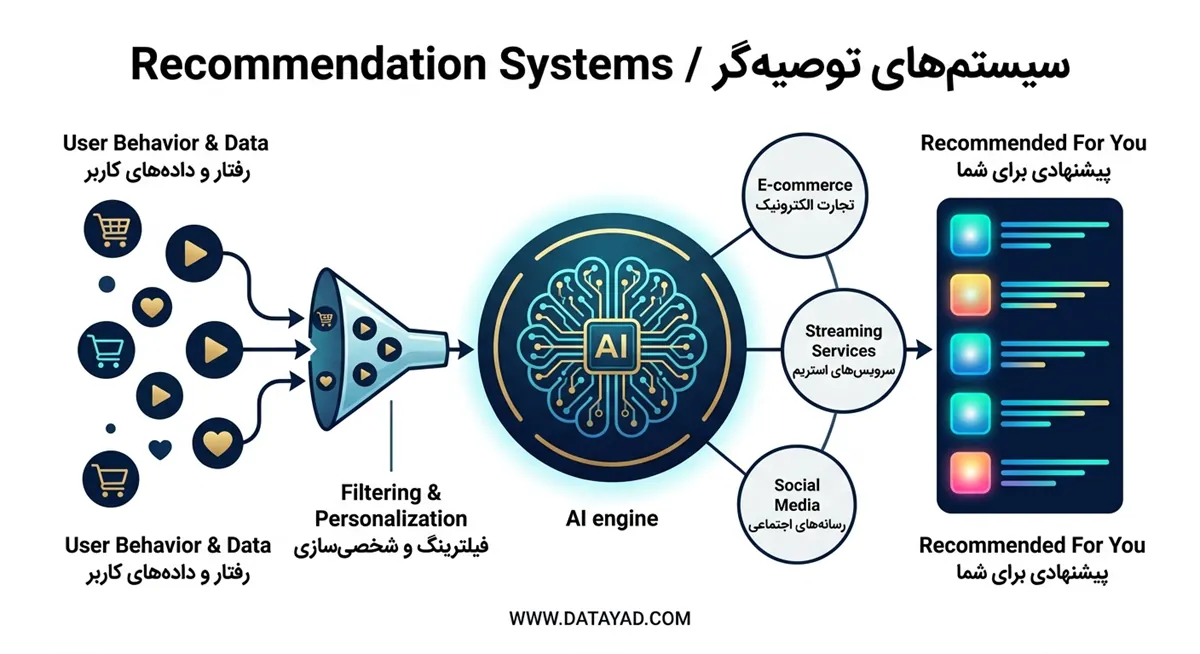
مبانی و اهداف سیستمهای توصیهگر
سیستمهای توصیهگر با تحلیل بردارهای ویژگی کاربران و اقلام، احتمال تعامل در آینده را بر اساس دادههای تاریخی تخمین میزنند. این الگوریتمها با فیلتر کردن حجم انبوه دادهها، فضای جستوجو را برای کاربر نهایی محدود کرده و بر شخصیسازی تجربه کاربری تمرکز میکنند. در ساختار فنی این سیستمها، ورودیهای دادهای به دو دسته صریح (مانند امتیازها) و ضمنی (مانند زمان توقف روی یک مطلب) تقسیم میشوند تا مدلسازی دقیقی از رفتار فرد صورت گیرد.
اهداف عملیاتی و فنی در طراحی و پیادهسازی این سیستمها شامل موارد زیر است:
- افزایش نرخ تبدیل (Conversion Rate): با ارائه پیشنهادهای دقیق، احتمال خرید یا تعامل کاربر با محتوا به شکل محسوسی افزایش مییابد.
- بهبود نرخ ماندگاری (Retention): درک صحیح سلیقه کاربر باعث میشود فرد پلتفرم را به عنوان یک ابزار کارآمد شناسایی کرده و برای دفعات بعدی به آن بازگردد.
- مدیریت سرریز اطلاعات: این سیستمها با حذف گزینههای نامرتبط در میان میلیونها انتخاب موجود، از سردرگمی کاربر و خستگی تصمیمگیری جلوگیری میکنند.
- کشف اقلام جدید (Discovery): کمک به کاربران برای پیدا کردن محصولات یا خدماتی که علیرغم تناسب با سلیقه آنها، به دلیل حجم بالای دادهها در حالت عادی دیده نمیشدند.
- شخصیسازی در مقیاس بالا: ایجاد یک تجربه منحصربهفرد برای هر کاربر به جای استفاده از لیستهای عمومی و پرفروش که برای همه یکسان است.
- افزایش میانگین ارزش سبد خرید: استفاده از استراتژیهای مکملفروشی (Cross-selling) از طریق پیشنهاد محصولات مرتبط با خرید فعلی کاربر.
- ایجاد عادت و وفاداری: سرویسدهی مداوم و ارائه محتوای مرتبط، باعث شکلگیری الگوهای استفاده منظم در کاربران و افزایش وابستگی مثبت به پلتفرم میشود.
بهرهگیری از این سیستمها در صنایع مختلفی از جمله تجارت الکترونیک، رسانه و بانکداری، نه تنها تجربه بصری کاربر را ارتقا میدهد، بلکه به عنوان یک ابزار پشتیبان تصمیمگیر، فرآیند رسیدن به هدف را برای کاربر سرعت میبخشد. دقت این سیستمها معمولا با معیارهایی نظیر RMSE در ارزیابیهای آفلاین و نرخ کلیک در تستهای آنلاین سنجیده میشود.
فیلترینگ مشارکتی و شباهتسنجی کاربران
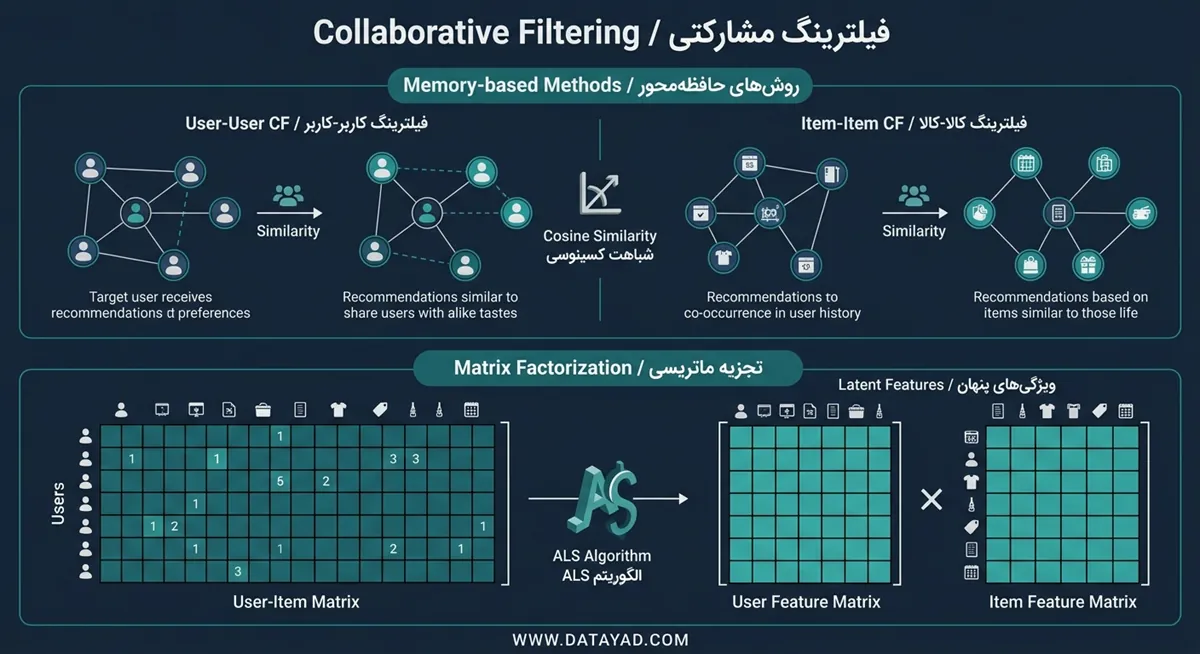
در سیستمهای توصیهگر فیلترینگ مشارکتی (Collaborative Filtering) بر پایه این فرض عمل میکند که کاربرانی با سوابق رفتاری مشابه، در آینده نیز انتخابهای نزدیکی خواهند داشت. این روش بدون نیاز به تحلیل ویژگیهای ذاتی کالا، صرفاً با تکیه بر تعاملات ثبت شده، الگوهای پنهان در میان توده کاربران را شناسایی میکند.
مکانیسم اصلی در اینجا بر یافتن شباهت میان بردارها استوار است. سیستم با تحلیل ماتریس تعاملات، کاربرانی را که به اقلام مشترکی امتیاز داده یا واکنش نشان دادهاند، در گروههای همسلیقه دستهبندی میکند.
روشهای حافظهمحور و همسایگی
در روشهای حافظهمحور، سیستم از کل پایگاه داده تعاملات برای یافتن شباهت میان کاربران یا کالاها استفاده میکند. الگوریتم (k-NN) یکی از ابزارهای اصلی در این حوزه است که با محاسبه فواصل آماری، نزدیکترین خوشههای رفتاری را شناسایی میکند.
-
- فیلترینگ کاربر-کاربر (User-User CF): پیشنهاد کالا به کاربر هدف بر اساس سلیقه افرادی که سوابق تعاملی مشابهی با او داشتهاند.
-
- فیلترینگ کالا-کالا (Item-Item CF): تمرکز بر یافتن کالاهای مشابه بر اساس همپوشانی در امتیازدهی کاربران، که معمولاً پایداری بیشتری نسبت به مدلهای کاربر-محور دارد.
محاسبه این شباهتها معمولاً از طریق معیارهایی نظیر ضریب همبستگی پیرسون یا شباهت کسینوسی انجام میشود. این رویکرد به دلیل سادگی در پیادهسازی و شهودی بودن نتایج، برای سیستمهایی با تعداد کاربر محدود بسیار موثر است.
تجزیه ماتریسی و ویژگیهای پنهان
تجزیه ماتریسی (Matrix Factorization) با تبدیل ماتریس بزرگ و پراکنده تعاملات به دو ماتریس کوچکتر و متراکم، چالش پراکندگی دادهها را مدیریت میکند. این ماتریسها شامل بردارهای ویژگیهای پنهان (Latent Features) هستند که ابعاد غیرمستقیم علایق کاربر و ماهیت کالا را نمایش میدهند.
در این فرآیند، ویژگیهایی که به طور صریح در متادیتای کالا وجود ندارند، توسط الگوریتمهایی نظیر کمترین مربعات متناوب (ALS) استخراج میشوند. به عنوان مثال، سیستم ممکن است تمایل کاربر به نوع خاصی از روایت داستانی را شناسایی کند، بدون اینکه آن ویژگی در مشخصات فنی کالا درج شده باشد.
حاصلضرب نقطهای بردارهای کاربر و کالا در فضای ویژگیهای پنهان، احتمال تعامل بعدی را تخمین میزند. این مدلسازی ریاضیاتی اجازه میدهد تا سیستم حتی برای جفتهای کاربر-کالایی که هیچ تاریخچه مستقیمی ندارند، پیشبینیهای دقیقی ارائه دهد.
فیلترینگ محتوامحور و تحلیل ویژگیها
در سیستمهای توصیهگر فیلترینگ محتوامحور بر تحلیل ویژگیهای ذاتی کالا یا محتوا متمرکز است و برخلاف روشهای مشارکتی، وابستگی مستقیمی به رفتار توده کاربران ندارد. این رویکرد با ایجاد یک بردار ویژگی برای هر آیتم و تطبیق آن با پروفایل ترجیحات کاربر، موارد مشابه با علایق قبلی را پیشنهاد میدهد. در این مکانیسم، شباهت بین آیتمها بر اساس صفات فیزیکی یا محتوایی آنها محاسبه میشود.
پروفایلسازی اقلام و کلمات کلیدی
در این مرحله، هر موجودیت در سیستم به یک فرمت ساختاریافته تبدیل میشود که ویژگیهای متمایزکننده آن را در بر میگیرد. برای مثال در یک سیستم توصیهگر کتاب، ژانر، نویسنده و کلمات کلیدی موجود در خلاصه داستان، اجزای اصلی پروفایل آیتم را تشکیل میدهند. استفاده از نمایش فضای برداری (Vector Space Representation) به سیستم اجازه میدهد تا هر کتاب را به صورت نقطهای در یک فضای چندبعدی مدلسازی کند.
الگوریتم TF-IDF یکی از ابزارهای متداول برای شناسایی و وزندهی به کلمات کلیدی پراهمیت در توضیحات متنی است. این شاخص کلماتی که بار معنایی بیشتری برای یک مطلب خاص دارند را شناسایی کرده و اثر کلمات عمومی و تکراری را کاهش میدهد. با این روش، وزن هر ویژگی در بردار نهایی مشخص شده و امکان محاسبه دقیق شباهت با استفاده از معیارهایی مانند شباهت کسینوسی فراهم میشود.
استخاج ویژگی با تحلیل متن و نظرکاوی
بسیاری از ویژگیهای کلیدی اقلام در لایههای پنهان دادههای غیرساختاریافته مانند نظرات کاربران یا نقدهای تخصصی قرار دارند. سیستمهای پیشرفته با بهرهگیری از پردازش زبان طبیعی (NLP)، مفاهیم کلیدی را از میان هزاران سطر متن استخراج میکنند تا پروفایل آیتم را غنیتر سازند. روشهایی مانند تخصیص دیریکله پنهان (LDA) برای موضوعبندی خودکار متن و شناسایی تمایلات پنهان در این بخش کاربرد گستردهای دارند.
- تحلیل احساسات: استخراج امتیازهای کیفی برای ویژگیهای خاص محصول از میان متن نظرات.
- شناسایی موجودیتهای نامدار: استخراج خودکار اسامی برندها، اشخاص یا مکانهای مرتبط با محتوا.
- تحلیل بافتار: درک ارتباط معنایی کلمات فراتر از تکرار ساده آنها برای بهبود دقت دستهبندی.
استفاده از نظرکاوی به سیستم اجازه میدهد تا فراتر از متادیتاهای رسمی (مانند رنگ یا قیمت)، به ابعاد کیفی مورد توجه کاربران دست یابد. این دادههای استخراجشده به عنوان بردارهای ویژگی مکمل در کنار مشخصات فنی قرار میگیرند. در نهایت، سیستم با ترکیب این ویژگیهای تحلیلشده، مدلی دقیق از علایق کاربر ساخته و اقلامی را که بیشترین همپوشانی معنایی با سوابق او دارند، در اولویت نمایش قرار میدهد.

مقایسه رویکردهای اصلی سیستمهای توصیهگر
انتخاب معماری بهینه در سیستمهای توصیهگر بر اساس توازن میان دقت پیشبینی، تنوع خروجی و محدودیتهای دادهای صورت میگیرد. هر رویکرد با تمرکز بر بخشی از فضای ویژگیها، سناریوهای عملیاتی متفاوتی را پوشش میدهد. جدول زیر تفاوتهای ساختاری و عملیاتی متدولوژیهای رایج را در محیطهای تولیدی نشان میدهد.
| عنوان رویکرد | مبنای اصلی پیشنهاد | مزیت استراتژیک | چالش فنی عمده |
|---|---|---|---|
| فیلترینگ مشارکتی | الگوهای رفتاری و شباهت کاربران | عدم نیاز به دانش تخصصی درباره ویژگیهای کالا | شروع سرد برای کاربران و کالاهای جدید |
| فیلترینگ محتوامحور | ویژگیهای ذاتی و صفات کالاها | کارایی بالا برای کالاهای جدید و بدون تاریخچه تعامل | محدودیت در ایجاد تنوع و غافلگیری کاربر |
| سیستمهای ترکیبی | ادغام مدلهای رفتاری و محتوایی | کاهش اثر چالش شروع سرد و افزایش پایداری مدل | پیچیدگی بالا در پیادهسازی و هزینه محاسباتی |
| حساس به بافتار | شرایط محیطی (زمان، مکان، دستگاه) | شخصیسازی لحظهای بر اساس موقعیت کاربر | نیاز به جمعآوری و پردازش حجم عظیمی از دادههای ضمنی |
مدلهای پیشرفته با ترکیب این استراتژیها سعی در پوشش نقاط کور یکدیگر دارند. استفاده از معماریهای چندلایه اجازه میدهد تا محدودیتهای مربوط به پراکندگی دادهها در روشهای مشارکتی، توسط اطلاعات غنی روشهای محتوامحور جبران شود.
مدلهای هیبریدی و استراتژیهای ترکیبی
مدلهای هیبریدی سیستمهای توصیهگر با ترکیب خروجی چندین مدل، دقت پیشبینی را در سناریوهای عملیاتی افزایش میدهند. این رویکردها اجازه میدهند نقاط ضعف یک روش توسط قوتهای روش دیگر پوشش داده شود. معماریهای ترکیبی معمولاً بر اساس نحوه ادغام نتایج به دستههای مختلفی تقسیم میشوند.
هدف اصلی در این استراتژیها، رسیدن به پایداری بیشتر در توصیهها است. مدلهای تکی اغلب در مواجهه با شرایط خاص دچار خطا میشوند. ترکیب منطقهای مختلف باعث میشود خروجی نهایی بهینه و به واقعیت نزدیکتر باشد.
ترکیب وزنی و سوئیچینگ
در روش وزنی، امتیاز نهایی هر کالا حاصل جمع جبری امتیازات تخصیص یافته توسط الگوریتمهای مختلف است. سیستم به هر مدل وزنی اختصاص میدهد که نشاندهنده میزان اعتماد به پیشبینیهای آن است. این وزنها میتوانند به صورت دستی تنظیم شده یا از طریق یادگیری ماشین بهینهسازی شوند.
استراتژی سوئیچینگ بر اساس وضعیت کاربر یا کالا، یکی از مدلها را برای تولید خروجی انتخاب میکند. اگر سیستم با کاربری جدید روبرو شود، از مدل محتوامحور استفاده کرده و با افزایش تعاملات، به سراغ فیلترینگ مشارکتی میرود. این مکانیسم از اتلاف منابع محاسباتی در سناریوهای ساده جلوگیری میکند.
تکنیک دیگری به نام ترکیب آمیخته (Mixed) نیز وجود دارد. در این حالت، توصیههای حاصل از مدلهای متفاوت به صورت همزمان در لیست نهایی نمایش داده میشوند. این کار باعث افزایش تنوع اقلام پیشنهادی و بهبود تجربه کاربری میشود.
رویکردهای متاسطح و آبشاری
رویکرد آبشاری با اولویتبندی مدلها کار میکند. در این حالت، مدل اول مجموعهای از کاندیداها را انتخاب کرده و مدل دوم وظیفه رتبهبندی دقیقتر یا رفع تساوی در امتیازات را بر عهده میگیرد. این فرآیند باعث میشود فیلترهای سختگیرانه در مراحل نهایی اعمال شوند.
در مدلهای متاسطح، خروجی یک الگوریتم به عنوان ورودی برای الگوریتم بعدی استفاده میشود. برای مثال، یک مدل استخراج ویژگیهای متنی، پروفایلی میسازد که مستقیماً در یک مدل فیلترینگ مشارکتی به کار میرود. این زنجیره اطلاعاتی باعث درک عمیقتر رفتارهای پیچیده کاربر میشود.
استفاده از رویکرد تقویت ویژگی (Feature Augmentation) نیز در این بخش مرسوم است. در این روش، خروجی یک مدل به عنوان یک ویژگی جدید به مدل دیگر اضافه میشود. این کار باعث میشود مدل دوم با دانش بیشتری نسبت به ترجیحات کاربر تصمیمگیری کند.
معماریهای مبتنی بر یادگیری عمیق
یادگیری عمیق با استفاده از شبکههای عصبی چندلایه، محدودیتهای مدلهای خطی در شناسایی الگوهای پیچیده میان کاربر و کالا را برطرف میکند. این معماریها به جای تکیه بر ضرب داخلی ساده در تجزیه ماتریسی، از توابع فعالسازی غیرخطی برای یادگیری ویژگیهای انتزاعی استفاده میکنند. این رویکرد باعث میشود سیستم توصیهگر بتواند روابط پنهانی موجود در دادههای حجیم را با دقت بالاتری استخراج کند.

فیلترینگ مشارکتی عصبی و مدلهای دولایه
مدل فیلترینگ مشارکتی عصبی (NCF) در سیستمهای توصیهگر با جایگزینی ضرب داخلی بردارها با یک شبکه عصبی پیشخور، تعاملات کاربر و کالا را مدلسازی میکند. در این ساختار، بردارهای تعبیه (Embedding) کاربر و کالا به لایههای پرسپترون چندلایه تزریق میشوند تا احتمال تعامل پیشبینی شود. این روش انعطافپذیری بالایی در یادگیری توابع پیچیده از دادههای تعاملی دارد.
معماریهای دولایه یا Two-Tower نیز با جداسازی بخش پردازش ویژگیهای کاربر از ویژگیهای کالا، امکان جستجوی سریع در فضاهای برداری بزرگ را فراهم میکنند. یک برج مسئول تولید بردار ویژگی کاربر و برج دیگر مسئول تولید بردار ویژگی کالا است. خروجی این دو برج در یک فضای مشترک مقایسه میشود که برای مرحله بازیابی نامزدها در مقیاس میلیونی بسیار کارآمد است.
شبکههای عصبی بازگشتی و تحلیل توالی
سیستمهای توصیهگر مبتنی بر توالی از شبکههای عصبی بازگشتی مانند لایههای LSTM و GRU برای درک ترتیب زمانی رفتار کاربران استفاده میکنند. این مدلها به جای نگاه ایستا به تاریخچه کاربر، وابستگیهای زمانی میان کلیکها و بازدیدها را در یک جلسه کاربری تحلیل میکنند. این قابلیت برای پیشبینی اقدام بعدی کاربر بر اساس رفتارهای لحظهای او کاربرد فراوانی دارد.
استفاده از مدلهای مبتنی بر مکانیزم توجه و ترنسفورمرها تحول بزرگی در تحلیل توالیها ایجاد کرده است. این مدلها برخلاف شبکههای بازگشتی سنتی، محدودیت پردازش ترتیبی را ندارند و میتوانند الگوهای بلندمدت را در تاریخچه کاربر با سرعت بیشتری شناسایی کنند. این معماری در پلتفرمهای اشتراک ویدیو و موسیقی که سلیقه کاربر در طول زمان تغییر میکند، نتایج دقیقتری ارائه میدهد.
مدلهای عریض و عمیق در رتبهبندی
معماری عریض و عمیق با ترکیب دو ساختار متفاوت، توازن میان «حفظ الگوها» و «تعمیمدهی» را برقرار میکند. بخش عریض شامل یک مدل خطی ساده است که تعاملات ویژگیهای مشخص و پرتکرار را یاد میگیرد. این بخش به سیستم کمک میکند تا روابطی که مستقیماً در دادهها وجود دارد را به خاطر بسپارد و توصیههای دقیقی برای موارد مشابه گذشته داشته باشد.
بخش عمیق این معماری از شبکههای عصبی متراکم برای شناسایی ویژگیهای پنهان و الگوهایی که قبلاً مشاهده نشدهاند، استفاده میکند. این بخش قدرت تعمیمدهی سیستم را افزایش میدهد و مانع از محدود شدن توصیهها به موارد تکراری میشود. ترکیب این دو بخش در مرحله رتبهبندی نهایی، منجر به ایجاد لیستی از پیشنهادات میشود که هم با سلیقه قبلی کاربر مطابقت دارد و هم گزینههای جدید و مرتبطی را معرفی میکند.
چالشهای فنی و محدودیتهای پیادهسازی
استقرار عملیاتی سیستمهای توصیهگر در مقیاس وسیع با پیچیدگیهای زیرساختی روبرو است که فراتر از انتخاب یک الگوریتم ساده پیش میرود. توازن بین سرعت پاسخدهی آنی و دقت محاسباتی، اصلیترین مانع در مسیر بهینهسازی این ابزارها در پلتفرمهای پرسرعت است.
| نوع چالش فنی | توصیف و ریشه چالش | تاثیر بر سیستم |
|---|---|---|
| خطای طبقهبندی سلیقه (Taxonomy Error) | بروز ناهماهنگی معنایی در درک ویژگیهای کالا؛ برای مثال پیشنهاد یک کالای صنعتی قرمز به کاربری که به لوازم آرایشی قرمز علاقه دارد. | کاهش رضایت کاربر به دلیل عدم تناسب بافتار و دستهبندی موضوعی. |
| رانش مفهوم زمانی (Temporal Concept Drift) | تاخیر در بهروزرسانی مدل نسبت به تغییر سلیقه یا نیاز لحظهای کاربر، مانند پیشنهاد محصولی که کاربر قبلاً خریداری کرده است. | ایجاد تکرار خستهکننده و کاهش نرخ تبدیل در سناریوهای فروشگاهی. |
| انتساب نادرست علیت (Causality Misattribution) | تمرکز بیش از حد الگوریتم بر همبستگیهای کاذب؛ مثلاً تصور اینکه کاربر به دلیل کشور سازنده کالا را خریده، در حالی که علت اصلی قیمت بوده است. | ایجاد سوگیری در توصیهها و محدود شدن دایره انتخابهای کاربر. |
| تاخیر در پاسخدهی (Inference Latency) | زمانبر بودن محاسبات در مدلهای پیچیده یادگیری عمیق هنگام رتبهبندی هزاران کالا در کسری از ثانیه. | افت تجربه کاربری و ریزش مخاطب به دلیل کندی بارگذاری لیست پیشنهادات. |
| پایداری و بازتولیدپذیری (Reproducibility) | دشواری در تکرار نتایج دقیق مدلهای عصبی در محیطهای مختلف به دلیل ماهیت تصادفی آموزش و تغییرات دادههای ورودی. | ایجاد چالش در خطایابی و پایش کیفیت خروجی در محیط عملیاتی. |
مدیریت این محدودیتها نیازمند بازنگری در معماری داده و استفاده از سختافزارهای تخصصی برای پردازشهای موازی است. مهندسان داده برای غلبه بر این موانع، معمولاً از ترکیب مدلهای سریع برای مرحله بازیابی و مدلهای دقیق برای مرحله رتبهبندی نهایی استفاده میکنند.
حوزههای کاربرد و بهرهبرداری تجاری
پیادهسازی سیستمهای توصیهگر در پلتفرمهای بزرگ تجاری، نرخ تبدیل را به طور میانگین بیش از ۲۲ درصد ارتقا میدهد. این فناوری با کاهش اصطکاک در مسیر خرید و ارائه گزینههای مرتبط، تجربه کاربری را از حالت جستوجوی غیرفعال به کشف هوشمند تغییر میدهد. در ادامه، حوزههای کلیدی بهرهبرداری از این سیستمها در صنایع مختلف بررسی شده است:
- خردهفروشی و تجارت الکترونیک: پلتفرمهای فروشگاهی از الگوریتمها برای پیادهسازی استراتژیهای فروش مکمل و بیشفروشی در سبد خرید استفاده میکنند. نمایش بخشهایی مانند «خرید محصولات مرتبط» یا «تکمیل استایل» باعث افزایش میانگین ارزش سفارشها و کشف کالاهایی میشود که کاربر به تنهایی قادر به یافتن آنها نبود.
- رسانه و سرویسهای استریم: در این حوزه، بهینهسازی بر اساس زمان توقف و تحلیل توالی رفتارها انجام میگیرد. موتورهای توصیه با شناسایی الگوهای مصرف محتوا، فیدهای اختصاصی ایجاد میکنند که منجر به افزایش نرخ ماندگاری و وفاداری کاربران در پلتفرمهای ویدیویی و موسیقی میشود.
- بانکداری و خدمات مالی: موسسات مالی با تحلیل دقیق تراکنشها و تاریخچه اعتباری، محصولات اختصاصی نظیر طرحهای بیمه یا فرصتهای سرمایهگذاری را به مشتریان پیشنهاد میدهند. این رویکرد به جای بازاریابی انبوه، بر نیازهای لحظهای و توان مالی هر فرد تمرکز دارد.
- آموزش و پژوهشهای علمی: سیستمهای کشف محتوای آکادمیک با تحلیل شبکههای استنادی، مقالات و منابع جدید را به پژوهشگران معرفی میکنند. این ابزارها با کاهش زمان جستوجوی دستی، بازدهی تحلیلگران را در دستیابی به دادههای مورد نیاز بهبود میبخشند.
- صنعت تبلیغات و مارکتینگ: هدفمندی تبلیغات بر اساس علایق و رفتارهای ضمنی کاربران، بازگشت سرمایه کمپینها را تضمین میکند. مدلهای توصیهگر با نمایش تبلیغات مرتبط در زمان مناسب، نرخ کلیک را افزایش داده و از هدررفت بودجههای بازاریابی در مقیاس وسیع جلوگیری میکنند.
- تلویزیونهای هوشمند و رسانههای متصل: با گسترش محتواهای پراکنده در بسترهای مختلف، سیستمهای توصیهگر به عنوان یک پورتال مرکزی عمل میکنند. این سیستمها با یکپارچهسازی منابع مختلف، فرآیند یافتن محتوا را برای بیننده ساده کرده و از سردرگمی کاربر در میان هزاران شبکه جلوگیری میکنند.
برای ساخت سیستمهای توصیهگر چه مهارتهایی باید یاد بگیریم؟
پیادهسازی سیستمهای توصیهگر تنها به دانستن یک الگوریتم محدود نمیشود. در عمل، توسعه این سیستمها نیازمند ترکیبی از مهارتهای علم داده، یادگیری ماشین و مهندسی داده است. متخصصان این حوزه باید بتوانند دادههای رفتاری کاربران را تحلیل کرده، مدلهای پیشبینی بسازند و آنها را در مقیاس بزرگ پیادهسازی کنند.
مهمترین مهارتهایی که برای ساخت سیستمهای توصیهگر باید یاد بگیرید عبارتاند از:
- تحلیل داده و آمار
- برنامهنویسی با Python
- یادگیری ماشین و مدلهای پیشبینی
- کار با دادههای بزرگ و مهندسی داده
- یادگیری عمیق و مدلهای مدرن توصیهگر
- ارزیابی و بهینهسازی مدلها در محیط واقعی
اگر میخواهید چنین سیستمهایی را در پروژههای واقعی پیادهسازی کنید، یادگیری ساختارمند علم داده و یادگیری ماشین ضروری است.
در دوره آموزش جامع علم داده و یادگیری ماشین در دیتایاد، تمام مهارتهای مورد نیاز برای ورود به حوزه Data Science از پایه تا سطح پیشرفته آموزش داده میشود؛ از تحلیل داده و ساخت مدلهای یادگیری ماشین گرفته تا کار روی پروژههای واقعی.
اگر قصد دارید وارد مسیر حرفهای علم داده شوید و سیستمهایی مانند موتورهای پیشنهاددهنده را خودتان طراحی کنید، این دوره میتواند نقطه شروع قدرتمندی برای شما باشد.




















