

متادیتا یا فراداده در سادهترین تعریف به معنای «دادههایی درباره دادههای دیگر» است. این مفهوم نقش ستون فقرات را در سازماندهی اطلاعات ایفا میکند و به ما اجازه میدهد تا بدون نیاز به بررسی محتوای اصلی، ماهیت، مالکیت، زمان ایجاد و ویژگیهای فنی یک فایل یا مجموعه داده را درک کنیم. در واقع، متادیتا شناسنامهای دیجیتال است که به سیستمهای کامپیوتری و انسانها کمک میکند تا در انبوهی از دادههای غیرساختاریافته، مسیر خود را به درستی پیدا کنند.
اهمیت فراداده فراتر از یک برچسبگذاری ساده است؛ چرا که بدون آن، فرآیندهای حیاتی مانند جستجوی هوشمند در موتورهای جستجو، مدیریت آرشیوهای بزرگ و تحلیلهای پیشرفته در علم داده عملاً غیرممکن میشد. در دنیای مدرن که حجم دادهها به صورت انفجاری در حال رشد است، شناخت دقیق ساختار متادیتا به متخصصان علم داده و دانشجویان کمک میکند تا چرخهی حیات داده را بهتر مدیریت کرده و بهرهوری سیستمهای بازیابی اطلاعات را به حداکثر برسانند.
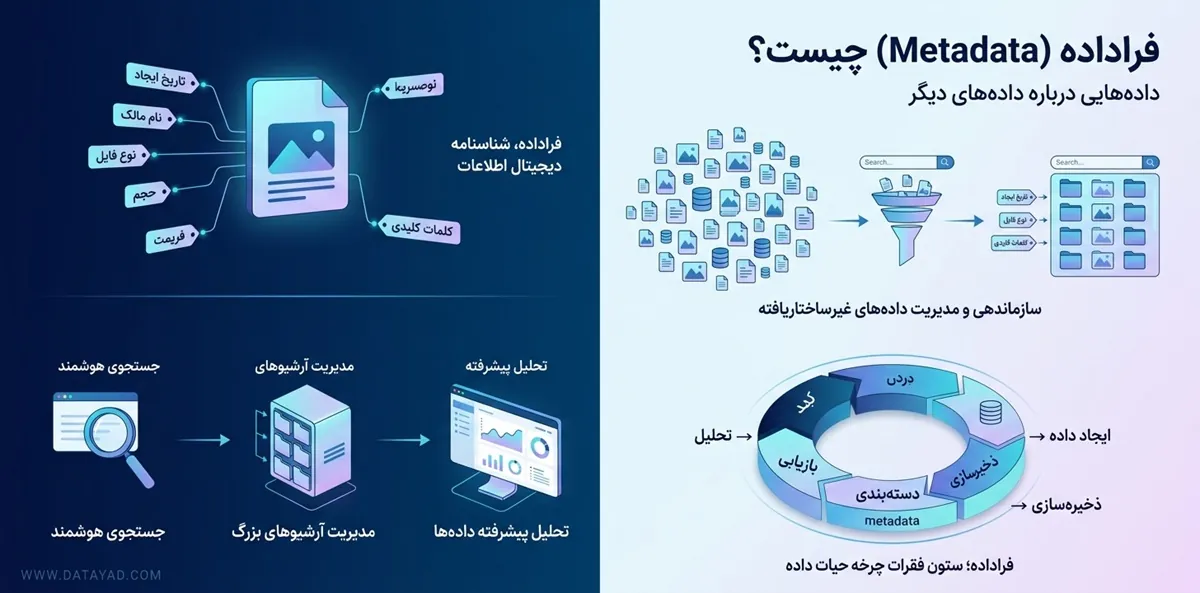
ماهیت و ساختار متادیتا
متادیتا شناسنامه ی دیجیتال هر فایل یا مجموعه داده ای است که لایه های پنهان اطلاعات را برای سیستم های پردازشی آشکار می کند. این ساختار به جای تمرکز بر محتوای اصلی، بر ویژگی های فنی و هویتی تمرکز دارد تا مدیریت داده ها در مقیاس بزرگ ممکن شود.
تعریف فنی و فلسفه وجودی
متادیتا در لایه ی زیرین ذخیره سازی قرار می گیرد تا فرآیند بازیابی اطلاعات را بهینه کند. هدف اصلی از وجود آن، کاهش هزینه های محاسباتی برای جستجو و دسته بندی است. وقتی حجم داده ها افزایش می یابد، بررسی تک تک فایل ها غیرممکن می شود و اینجاست که متادیتا به عنوان یک میان بر عمل می کند.
این مفهوم در علوم داده برای ردیابی منشا اطلاعات و حفظ یکپارچگی پایگاه های داده استفاده می شود. در واقع بدون وجود یک ساختار مشخص برای فراداده، سیستم های کامپیوتری توانایی درک تفاوت میان میلیون ها فایل مشابه را نخواهند داشت.
تمایز میان داده و فراداده
تفاوت اصلی این دو در محتوا و کاربرد آن ها نهفته است. داده محتوای خام مثل متن یک نامه یا پیکسل های یک تصویر است. فراداده اطلاعاتی نظیر حجم فایل، فرمت ذخیره سازی و زمان آخرین ویرایش را شامل می شود.
در یک فایل صوتی، فرکانس ها و سیگنال ها همان داده اصلی هستند. نام خواننده، نام آلبوم و نرخ بیت (Bitrate) همگی متادیتا محسوب می شوند. داده همان چیزی است که کاربر نهایی مصرف می کند، اما فراداده ابزاری برای سازماندهی آن توسط ماشین است.
اجزای تشکیلدهنده یک تگ متا
هر تگ متا از دو بخش اصلی یعنی نام ویژگی و مقدار آن تشکیل می شود. این ساختار جفت شده (Key-Value Pair) اجازه می دهد تا الگوریتم های موتورهای جستجو و پایگاه های داده به راحتی اطلاعات را استخراج کنند. اجزای رایج در یک تگ استاندارد شامل موارد زیر است:
-
- نام یا صفت (Name): مشخص می کند که فراداده مربوط به چه موضوعی است، مانند نویسنده یا تاریخ ثبت.
-
- مقدار (Value): محتوای واقعی مربوط به آن صفت را در بر می گیرد، مثل نام یک فرد یا یک عدد خاص.
-
- طرح واره (Schema): استانداردی که تعیین می کند داده ها با چه فرمتی و تحت چه قواعدی نوشته شوند تا در سیستم های مختلف قابل خواندن باشند.
انواع اصلی فراداده
دستهبندی فرادادهها بر اساس نوع کاربرد و نقشی که در مدیریت اطلاعات دارند انجام میشود. این تفکیک به سیستمهای هوشمند اجازه میدهد تا بدون درگیر شدن با محتوای اصلی، فرآیندهای بازیابی و نگهداری را به صورت تخصصی مدیریت کنند.
-
- فراداده توصیفی (Descriptive Metadata): این لایه برای شناسایی و جستجوی منابع به کار میرود. اطلاعاتی مانند عنوان، موضوع، کلمات کلیدی و نام پدیدآورنده در این گروه قرار میگیرند تا پیدا کردن یک فایل در میان انبوه دادهها سریعتر انجام شود.
-
- فراداده ساختاری (Structural Metadata): این بخش نحوه ارتباط اجزای مختلف یک موجودیت دیجیتال با یکدیگر را مشخص میکند. برای مثال، تعیین میکند که هر صفحه ی اسکن شده مربوط به کدام بخش از یک کتاب الکترونیکی است یا فایلهای صوتی یک پوشه با چه ترتیبی چیده شدهاند.
-
- فراداده مدیریتی (Administrative Metadata): این نوع بر مدیریت چرخه حیات و کنترل دسترسی تمرکز دارد. اطلاعاتی شامل تاریخ ایجاد، فرمت فنی فایل، محدودیتهای کپیرایت و دادههای مربوط به آرشیو در این دسته جای میگیرند.
-
- فراداده فنی (Technical Metadata): جزئیات دقیق سختافزاری و نرمافزاری را شامل میشود. در یک فایل ویدئویی، مواردی مثل نرخ فریم، کدک استفاده شده و ابعاد تصویر جزو فرادادههای فنی هستند که برای اجرای صحیح فایل ضرورت دارند.
-
- فراداده حقوقی (Rights Management Metadata): این بخش به حقوق مالکیت معنوی و لایسنسهای استفاده مربوط است. مشخص میکند که چه کسانی اجازه ی ویرایش، بازنشر یا مشاهده دادهها را دارند و محدودیتهای قانونی استفاده از منبع چیست.
بررسی نمونههای کاربردی
درک عملکرد فراداده در سیستمهای عملیاتی مستلزم مشاهده نحوه پیادهسازی آن در محیطهای مختلف نرمافزاری و سختافزاری است. این دادههای ثانویه در فرآیندهای اتوماسیون و فیلترینگ هوشمند، جایگزین بررسی دستی محتوای حجیم میشوند. با تحلیل لایههای فنی در حوزههای گوناگون، تفاوت در نحوه ذخیرهسازی و بازیابی اطلاعات مشخص میشود.
| حوزه کاربرد | نمونههای فراداده | هدف عملیاتی |
|---|---|---|
| رسانههای دیجیتال (تصویر و ویدیو) | مدل دوربین، سرعت شاتر، مختصات جغرافیایی (GPS)، نرخ فریم | دستهبندی خودکار بر اساس لوکیشن و بهینهسازی ویرایش فنی |
| تجارت الکترونیک (فروشگاه آنلاین) | شناسه کالا (SKU)، وزن محصول، دستهبندی سطحبندی شده، برند | مدیریت دقیق موجودی انبار و فیلترینگ نتایج جستجو برای کاربر |
| مدیریت اسناد و کتابخانهها | شابک (ISBN)، کدهای ردهبندی دیوئی، زبان سند، وضعیت امانت | تسهیل در بازیابی منابع و سازماندهی فیزیکی و دیجیتالی کتابها |
| مهندسی داده و پایگاه داده | طرحواره (Schema)، نوع متغیر (String/Int)، زمان آخرین بهروزرسانی | حفظ یکپارچگی پایگاه داده و افزایش سرعت اجرای کوئریهای پیچیده |
| ارتباطات (ایمیل و پیامرسان) | آدرس IP فرستنده، مسیرهای سرور، برچسبهای امنیتی | شناسایی خودکار هرزنامهها و ردیابی مسیر انتقال پیام |
استفاده از این استانداردها در هر صنعت باعث میشود تا سیستمهای نرمافزاری بدون نیاز به پردازش مستقیم محتوا، ماهیت فایل را تشخیص دهند. این رویکرد ساختاریافته، خطای انسانی را در مدیریت داراییهای دیجیتال به شدت کاهش میدهد و دقت در استخراج اطلاعات را بالا میبرد.
نقش متادیتا در فناوریهای مدرن
پیادهسازی سیستمهای خودکار بدون متادیتا باعث غرق شدن ماشینها در انبوهی از اطلاعات بیمعنی میشود. فرادادهها لایهای از معنا را به دادههای خام اضافه میکنند تا نرمافزارها بتوانند بدون مداخله انسان، محتوا را درک و دستهبندی کنند. این فرآیند سرعت پردازش را در معماریهای نرمافزاری پیچیده و مقیاسپذیر افزایش میدهد.
بهینهسازی برای موتورهای جستجو
الگوریتمهای رتبهبندی برای تحلیل ماهیت صفحات وب از تگهای متا کمک میگیرند. استفاده از دادههای ساختاریافته به موتورهای جستجو اجازه میدهد تا نتایج را در قالبهای غنی به کاربران نمایش دهند. این متادیتاها هستند که مشخص میکنند یک صفحه وب مربوط به دستور پخت غذا است یا یک مقاله علمی تخصصی.
مدیریت کلانداده و هوش مصنوعی
در زیرساختهای کلانداده، متادیتا وظیفه ردیابی منشأ و بررسی کیفیت دادهها را بر عهده دارد. در هوش مصنوعی ، مدلهای یادگیری ماشین برای آموزش دقیق، نیاز دارند بدانند هر ورودی در چه زمانی و تحت چه شرایطی جمعآوری شده است. فرادادهها به مهندسان داده کمک میکنند تا الگوهای معنادار را از نویزهای آماری تفکیک کنند.
سازماندهی کتابخانههای دیجیتال
آرشیوهای دیجیتال برای مدیریت میلیونها سند از استانداردهای فرادادهای مشترک استفاده میکنند. این سیستمها امکان جستجوی دقیق در نسخههای خطی، نقشهها و فایلهای چندرسانهای را برای پژوهشگران فراهم میکنند. بدون وجود این شناسنامههای دیجیتال، بازیابی یک فایل خاص در مخازن اطلاعاتی عظیم غیرممکن است.
ملاحظات امنیتی و حریم خصوصی
فرادادهها برخلاف ظاهر بیخطرشان، جزییات پنهانی را افشا میکنند که میتواند امنیت سایبری و حریم خصوصی کاربران را به خطر بیندازد. این دادههای ثانویه اغلب بدون نظارت دقیق در لایههای زیرین فایلها باقی میمانند و مسیر نشت اطلاعات حساس را هموار میکنند. استخراج الگوهای رفتاری و موقعیتهای مکانی دقیق از طریق تحلیل همین شناسنامههای دیجیتال انجام میشود.
- افشای موقعیت جغرافیایی: بسیاری از دوربینها و تلفنهای هوشمند، مختصات دقیق GPS را در تگهای Exif تصاویر ذخیره میکنند که منجر به شناسایی محل سکونت یا کار کاربر میشود.
- نشت اطلاعات سازمانی: اسناد متنی و فایلهای ارائه حاوی نام کاربری، مسیرهای ذخیرهسازی در سرور داخلی و نسخه نرمافزارهای مورد استفاده هستند که خوراک اولیه برای حملات هدفمند محسوب میشوند.
- ردیابی ارتباطات: فرادادههای موجود در هدر ایمیلها، مسیر دقیق عبور پیام از سرورهای مختلف و آدرسهای آیپی فرستنده را برای تحلیلگران آشکار میکند.
- بازیابی تاریخچه تغییرات: برخی فرمتهای فایلی، نسخههای قبلی و کامنتهای حذف شده را در بخش متادیتا نگه میدارند که ممکن است حاوی دادههای محرمانه یا حذفیات حساس باشد.
- تشخیص هویت مجدد: ترکیب چندین مجموعه از فرادادههای به ظاهر ناشناس در پروژههای کلانداده، میتواند به شناسایی هویت واقعی افراد در بانکهای اطلاعاتی منجر شود.
پاکسازی فراداده یا Metadata Scrubbing پیش از انتشار عمومی فایلها، راهکاری فنی برای مقابله با این تهدیدات است. ابزارهای امنیتی با حذف تگهای غیرضروری، ریسک مهندسی معکوس و دسترسی به سرنخهای فنی را به حداقل میرسانند. مدیریت صحیح این دادههای پنهان، بخشی جداییناپذیر از استراتژیهای حفاظت از داده در زیرساختهای دیجیتال است.
ابزارهای مدیریت و استخراج
مدیریت فراداده مستلزم استفاده از ابزارهایی است که لایههای پنهان فایل را بدون تغییر در محتوای اصلی بازخوانی میکنند. این ابزارها با دسترسی مستقیم به بخش هدر (Header)، امکان مشاهده و تغییر مشخصات فنی و توصیفی را فراهم میسازند. استفاده از این راهکارها برای سازماندهی انبوه دادهها و خودکارسازی فرآیندهای دستهبندی در پروژههای بزرگ صنعتی ضرورت دارد.
نرمافزارهای ویرایش متادیتا
نرمافزارهای ویرایشگر به دو گروه ابزارهای خط فرمان (CLI) و رابطهای گرافیکی (GUI) تقسیم میشوند. ابزارهای تحت کنسول به دلیل سرعت بسیار بالا در پردازش دستهای، مورد توجه مهندسان داده هستند. این برنامهها میتوانند تگهای متنی را در هزاران فایل به صورت همزمان و با دقت میلیثانیهای اصلاح یا جایگزین کنند.
ویرایشگرهای گرافیکی برای مدیریت فایلهای چندرسانهای و اسناد اداری کاربرد بیشتری دارند. این ابزارها محیطی بصری برای تغییر تگهای صوتی، مشخصات تصاویر و جزئیات اسناد متنی فراهم میکنند. تمرکز اصلی این نرمافزارها بر حفظ یکپارچگی ساختار فایل در حین تغییر اطلاعات شناسنامهای است.
پاکسازی خودکار اطلاعات حساس
فرآیند پاکسازی یا اسکرابینگ (Scrubbing) به معنای حذف هوشمند فیلدهایی است که امنیت یا حریم خصوصی را به مخاطره میاندازند. ابزارهای خودکار با اسکن دقیق بلوکهای داده، اطلاعاتی نظیر موقعیت مکانی دقیق، نام کاربری سیستم و مشخصات فنی سرورها را شناسایی و حذف میکنند. این اقدام معمولا در آخرین مرحله پیش از انتشار عمومی فایلها در بستر وب انجام میشود.
الگوریتمهای پاکسازی بر اساس استانداردهای حفاظتی تعریف میشوند تا از باقی ماندن هرگونه ردپای دیجیتال در منشأ تولید داده جلوگیری کنند. این ابزارها علاوه بر حذف کامل، توانایی جایگزینی اطلاعات حساس با مقادیر تصادفی را نیز دارند. پیادهسازی این فرآیند در سازمانها مانع از نشت اطلاعات زیرساختی از طریق فایلهای خروجی میشود.




















