

یادگیری یک زبان جدید همیشه جذاب است؛ اما اگر تجربه استفاده از اپلیکیشنهایی مثل دولینگو را داشته باشید، میدانید که فقط حفظ کردن کلمات کافی نیست. مثلاً شاید بدانید “I am ready” به انگلیسی یعنی “من آماده هستم”، اما برای اینکه واقعاً یک زبان را بفهمید، باید ارتباط بین کلمات و موقعیت استفاده از آنها را درک کنید. در دنیای هوش مصنوعی و پردازش زبان طبیعی (NLP) هم دقیقاً همین چالش را داریم. مدلهای قدیمی مثل Bag-of-Words با هر کلمه طوری رفتار میکردند که انگار هیچ ربطی به کلمات دیگر ندارد. اما چطور میتوان به ماشین فهماند که «عشق» و «دوست داشتن» به هم نزدیک هستند؟ پاسخ این سوال در مفهومی به نام Word Embeddings نهفته است. در این مقاله، میخواهیم به زبان خیلی ساده سراغ مدل Word2Vec برویم و ببینیم چطور با کتابخانه Gensim میتوانیم به کامپیوترها بفهمانیم کلمات چه معنایی دارند. درک این مباحث بخش مهمی از آموزش مدل های زبانی بزرگ و پردازش زبان طبیعی هست.
تعبیه کلمات (Word Embeddings) چیست؟
ظهور زبان، نقطه عطفی در تکامل بشر بود. اگرچه همه موجودات به شکلی با هم ارتباط برقرار میکنند، اما ما انسانها تنها گونهای هستیم که در استفاده از زبان برای انتقال مفاهیم پیچیده و ذهنی استاد شدهایم. مثلاً وقتی من کلمه «موش» را به زبان میآورم، شما فوراً تصویر یک جونده کوچک و پشمالو را در ذهن تصور میکنید؛ اما سگ شما یا کامپیوترتان (در حالت پایه) هیچ درکی از ماهیت این موجود ندارند.
به همین خاطر، در هر پروژهای که با متن و زبان سر و کار دارد (NLP)، اولین و حیاتیترین قدم این است که راهی پیدا کنیم تا کلمات را به شکلی به کامپیوتر معرفی کنیم که «معنای» آنها را بفهمد.
روش قدیمی: مدل کیسه کلمات (Bag of Words) و One-Hot
ابتداییترین راه برای عددی کردن کلمات، استفاده از مدلی به نام کیسه کلمات (Bag of Words) و روش One-Hot Encoding است. با یه مثال و دو تا جمله ساده شروع میکنیم:
- «من فیلم جدید را دوست دارم»
- «من هوای عالی را دوست دارم»
در این روش، ما یک لیست از تمام کلمات منحصربهفردی که در این دو جمله هست میسازیم. لیست ما (Vocabulary) شامل این کلمات میشود: {من، فیلم، جدید، را، دوست، دارم، هوای، عالی}.
حالا برای نمایش هر کلمه، یک لیست عددی (بردار) میسازیم که طول آن برابر با تعداد کل کلمات ماست (اینجا ۸ کلمه داریم). در این لیست، همه اعداد صفر هستند و فقط جایگاهِ مخصوصِ آن کلمه، عدد یک میگیرد:
- من:
[1, 0, 0, 0, 0, 0, 0, 0] - فیلم:
[0, 1, 0, 0, 0, 0, 0, 0] - جدید:
[0, 0, 1, 0, 0, 0, 0, 0] - را:
[0, 0, 0, 1, 0, 0, 0, 0] - دوست:
[0, 0, 0, 0, 1, 0, 0, 0] - دارم:
[0, 0, 0, 0, 0, 1, 0, 0] - هوای:
[0, 0, 0, 0, 0, 0, 1, 0] - عالی:
[0, 0, 0, 0, 0, 0, 0, 1]
حالا اگر بخواهیم کل جمله اول را نمایش دهیم، خروجی به این صورت میشود: [1, 1, 1, 1, 1, 1, 0, 0] (یعنی کلمات من، فیلم، جدید، را، دوست و دارم در این جمله هستند).
مشکل اصلی اینجاست!
اگر به این لیستهای عددی دقت کنید، متوجه یک ایراد بزرگ میشوید: این روش اصلاً نمیتواند شباهت بین کلمات را نشان دهد. در این مدل، کلمات به صورت موجودات کاملاً مستقل و جدا از هم در یک فضای ریاضی قرار میگیرند.
هیچ راهی وجود ندارد که بفهمیم کلمه «فیلم» و «سریال» (اگر در متن بود) چقدر به هم نزدیک هستند. از نظر این مدل، شباهت کلمه «فیلم» با «سینما»، دقیقاً برابر با شباهت کلمه «فیلم» با «هوا» است! یعنی صفر. چون هر کلمه فقط یک جایگاه مستقل دارد و هیچ پیوند معنایی بین آنها برقرار نیست.
ورود به دنیای تعبیه کلمات (Word Embeddings)
اینجاست که مفهوم تعبیه کلمات یا همان Word Embeddings وارد میشود تا بازی را عوض کند. تعبیه کلمات در واقع یک روش نمایش عددی است که در آن، بافت (Context) و شباهت کلمات کاملاً حفظ میشود. در این فضای جدید، کلمات به جای یک عدد با برداری از اعداد تعریف میشوند. کلماتی که معنای مشابهی دارند، بردارهای عددی مشابهی هم خواهند داشت و در نزدیکی هم قرار میگیرند.
یکی از موفقترین و محبوبترین تکنیکها برای رسیدن به این هدف، مدل Word2Vec است. ما در ادامه میخواهیم بررسی کنیم که این مدل چطور کار میکند و چطور میتوانیم با استفاده از کتابخانه قدرتمند Gensim، آن را در پروژههایمان به کار بگیریم.

مدل Word2Vec؛ جادوی گوگل در درک معنای کلمات
مدل Word2Vec در سال ۲۰۱۳ توسط تیمی از محققان گوگل به رهبری توماس میکولوف (Tomas Mikolov) معرفی شد و انقلابی در پردازش زبان طبیعی ایجاد کرد. برخلاف روشهای قدیمی، Word2Vec برای هر کلمه یک بردار (Vector) میسازد.
نکته طلایی اینجاست: کلماتی که در متن ها و موضوعات مشابه استفاده میشوند یا با هم رابطه معنایی دارند، در این فضای ریاضی به هم نزدیک میشوند. به زبان سادهتر، کلمات مشابه، بردارهای مشابهی خواهند داشت!
مثال کلاسیک: پادشاه، ملکه، مرد و زن
برای اینکه بفهمید این بردارهای عددی چطور معنا را در خود جای میدهند، بیایید یک دنیای فرضی را تصور کنیم. فرض کنید برای هر کلمه، چند معیار (ویژگی) داریم و به هر کلمه در آن معیار امتیازی بین ۰ تا ۱ میدهیم:
| کلمه | سلطنتی بودن | مردانگی | زنانگی | سن (بزرگسال) |
| پادشاه (King) | ۰.۹۹ | ۰.۹۵ | ۰.۰۵ | ۰.۷ |
| ملکه (Queen) | ۰.۹۹ | ۰.۰۵ | ۰.۹۵ | ۰.۷ |
| مرد (Man) | ۰.۰۱ | ۰.۹۹ | ۰.۰۱ | ۰.۶ |
| زن (Woman) | ۰.۰۱ | ۰.۰۱ | ۰.۹۹ | ۰.۶ |
| شاهزاده (Prince) | ۰.۹۵ | ۰.۹۰ | ۰.۰۵ | ۰.۲ |
همانطور که در جدول بالا میبینید:
- کلمات «پادشاه»، «ملکه» و «شاهزاده» در ویژگی سلطنتی بودن امتیاز بالایی دارند.
- کلمات «پادشاه» و «شاهزاده» از نظر مردانگی به هم نزدیکاند، اما در معیار سن با هم تفاوت دارند.
ریاضیاتِ معنایی: پادشاه منهای مرد، مساوی است با ملکه!
یکی از شگفتانگیزترین ویژگیهای Word2Vec این است که میتوانید روی کلمات عملیات ریاضی انجام دهید! اگر بردار عددی کلمه «مرد» را از «پادشاه» کم کنید و بردار «زن» را به آن اضافه کنید، نتیجه به دست آمده در فضای برداری، بسیار به کلمه «ملکه» نزدیک خواهد بود:
King – Man + Woman ≈ Queen
این مدل حتی میتواند روابطی مثل «کشور-پایتخت» را هم به درستی تشخیص دهد (مثلاً پاریس برای فرانسه، مثل تهران است برای ایران).
نکته مهم: در دنیای واقعی، ما این ویژگیها (مثل سلطنتی بودن یا جنسیت) را دستی به مدل نمیدهیم. Word2Vec خودش با خواندن حجم عظیمی از متنها، این الگوهای پنهان را کشف میکند. خروجی این مدل میتواند به عنوان ورودی برای کارهای پیچیدهتری مثل دستهبندی متن استفاده شود.
معماری مدل Word2Vec؛ پشت صحنه این مدل هوشمند!
شاید تصور کنید Word2Vec یک سیستم بسیار پیچیده و چندلایه است، اما در واقعیت، این مدل یک شبکه عصبی ساده (Shallow Neural Network) با دو لایه است که به شکلی هوشمندانه آموزش میبیند.
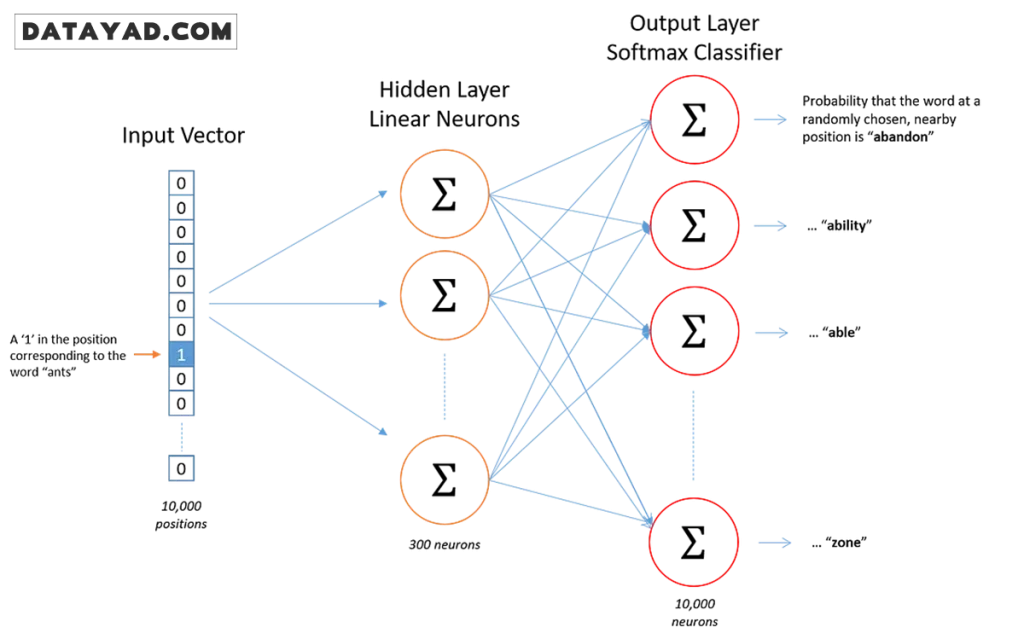
ساختار شبکه عصبی مدل Word2Vec
- لایه ورودی: تمام کلمات متن ما به صورت همان روش One-Hot (که قبلاً توضیح دادیم) وارد شبکه میشوند.
- لایه مخفی (Hidden Layer): تعداد نرونهای این لایه، طول بردار کلمه ما را مشخص میکند. مثلاً اگر بخواهیم هر کلمه به یک بردار ۳۰۰ تایی تبدیل شود، در این لایه ۳۰۰ نرون قرار میدهیم.
- لایه خروجی: این لایه احتمال حضور کلمات دیگر را پیشبینی میکند.
نکته کلیدی: وقتی آموزشِ مدل تمام میشود، ما با لایه خروجی کاری نداریم! چیزی که برای ما ارزش طلا را دارد، وزنهای لایه مخفی است. این وزنها همان «تعبیه کلمات» یا بردار عددی هستند که ویژگیهای معنایی کلمه را در خود جای دادهاند.
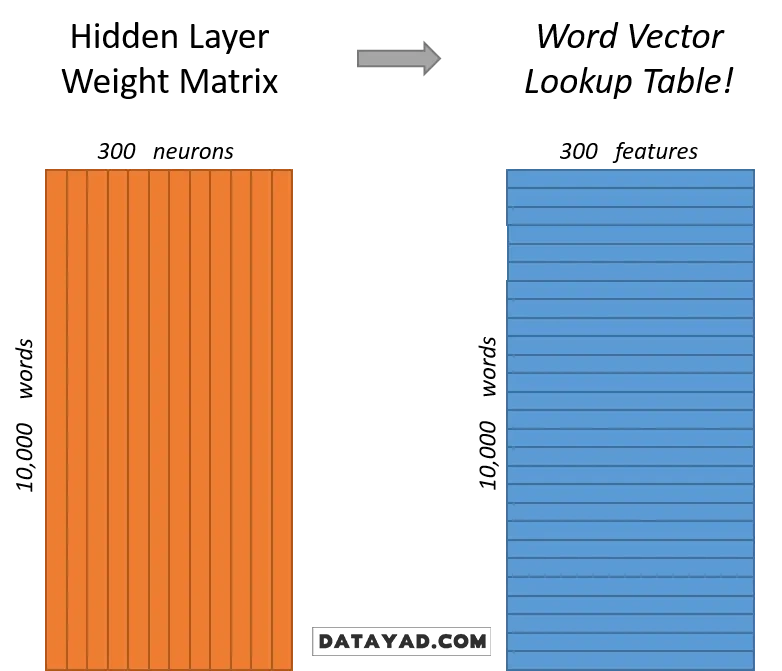
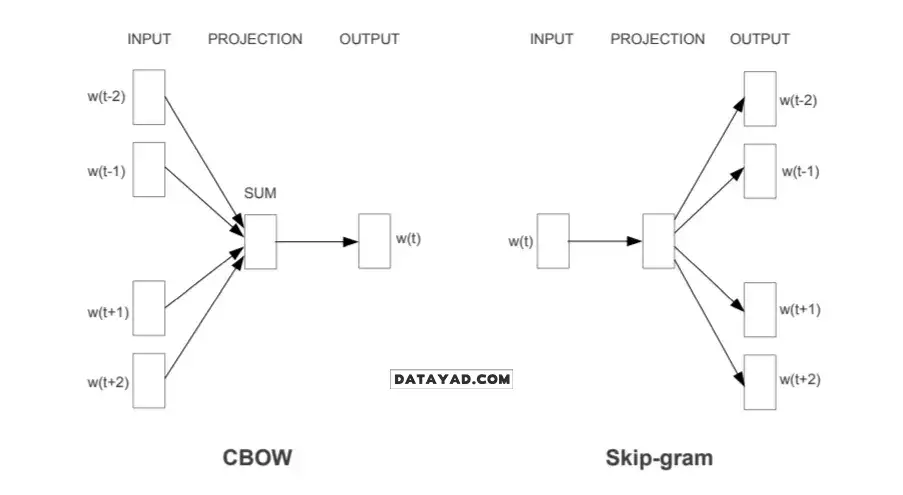
دو استراتژی اصلی: CBOW در مقابل Skip-gram
برای ساخت این بردارهای عددی، دو روش یا معماری اصلی وجود دارد که هر کدام از زاویه متفاوتی به متن نگاه میکنند:
۱. روش CBOW (Continuous Bag-Of-Words)
در روش CBOW، هدف این است که مدل، کلمه هدف را بر اساس کلمات اطرافش (Context) پیشبینی کند. فرض کنید این جمله را داریم: «امروز هوا بسیار عالی است». در این روش، کلمات «امروز»، «هوا»، «بسیار» و «است» به عنوان ورودی داده میشوند و مدل باید حدس بزند که کلمه جای خالی، «عالی» است.
ویژگی: این روش سرعت بالایی دارد و برای کلماتی که تکرار آنها در متن زیاد است، بسیار خوب عمل میکند.
۲. روش Skip-gram
این روش دقیقاً برعکس CBOW عمل میکند. اینجا ما یک کلمه را به مدل میدهیم و از او میخواهیم پیشبینی کند چه کلماتی احتمالاً در اطراف آن قرار دارند. دوباره همان مثال را در نظر بگیرید: ما کلمه «عالی» را به مدل میدهیم و انتظار داریم مدل کلمات «امروز»، «هوا» و «بسیار» را پیشبینی کند.
ویژگی: Skip-gram در مجموعه دادههای کوچکتر بسیار قوی عمل میکند و حتی میتواند کلمات کمیاب (که کمتر در متن تکرار شدهاند) را هم به خوبی مدلسازی کند.
آموزش مدل Word2Vec شخصیسازی شده با کتابخانه Gensim
حالا که با تئوری کار آشنا شدیم، وقت آن است که دستبهکد شویم. برای پیادهسازی این مدل در پایتون، بهترین انتخاب کتابخانه Gensim است. شعار این کتابخانه ساده است: «تولید بردارهای معنایی به کارآمدترین شکل ممکن برای کامپیوتر و بیدردسرترین حالت برای انسان».
در این پروژه، از مجموعه داده (Dataset) توییتهای مربوط به کرونا استفاده میکنیم. انتخاب این دیتاست به این دلیل است که برخلاف مجموعههای عظیمی مثل IMDB، اندازه متوسطی دارد و به پروژههای واقعی که ممکن است شما در بازار کار با آنها روبرو شوید، شبیهتر است.
آمادهسازی ورودی برای مدل
قبل از هر چیز، باید کلاس Word2Vec را از gensim.models وارد کنید. نکته مهم اینجاست که مدل Word2Vec نمیتواند یک متن خام را به عنوان ورودی بپذیرد. ورودی مدل باید به صورت لیستی از جملات باشد که هر جمله خودش به لیستی از کلمات (توکنها) تقسیم شده است.
معمولاً برای این کار از تابع split روی هر خط از متن استفاده میکنیم تا کلمات از هم جدا شوند.
from gensim.models import Word2Vec sentences = [line.split() for line in texts]
تنظیم پارامترهای طلایی مدل Word2Vec
وقتی میخواهید مدل را تعریف کنید، چند پارامتر کلیدی وجود دارد که کیفیت نهایی بردارهای شما را تعیین میکنند. بیایید ببینیم هر کدام چه معنایی دارند:
- Size (اندازه بردار): این پارامتر مشخص میکند که هر کلمه به یک بردار با چه طولی تبدیل شود. مثلاً اگر عدد ۱۰۰ را انتخاب کنید، هر کلمه با ۱۰۰ عدد ویژگی توصیف میشود. هر چه این عدد بزرگتر باشد، مدل میتواند جزئیات بیشتری را یاد بگیرد (البته به دیتای بیشتری هم نیاز خواهد داشت).
- Window (پنجره): این عدد مشخص میکند که مدل برای یادگیری هر کلمه، تا چه فاصلهای از کلماتِ قبل و بعد آن را بررسی کند. به نوعی، این همان «بافت» یا Context کلمه است.
- Min_count: با این پارامتر به مدل میگویید: «کلماتی که کمتر از $n$ بار تکرار شدهاند را نادیده بگیر». این کار باعث میشود کلمات نادری که ممکن است غلط املایی باشند یا ارزش معنایی کمی دارند، از محاسبات حذف شوند.
- Workers: این پارامتر برای افزایش سرعت است! در اینجا مشخص میکنید که مدل از چند هسته پردازنده (CPU) به صورت همزمان برای آموزش استفاده کند. هر چه تعداد هستهها بالاتر باشد، سرعت آموزش بیشتر میشود.
- Iter (تعداد تکرار): مشخص میکند که مدل چند بار باید کل متنهای شما را بخواند و وزنهای خود را آپدیت کند تا به بهترین نتیجه برسد.
w2v =Word2Vec(sentences, size=100, window=5, workers=4, iter=10, min_count=5) print(sentences[20:25]) [['with', 'nations', 'inficted', 'with', 'covid', 'the', 'world', 'must', 'not', 'play', 'fair', 'with', 'china', 'goverments', 'must', 'demand', 'china', 'adopts', 'new', 'guilde', 'lines', 'on', 'food', 'safty', 'the', 'chinese', 'goverment', 'is', 'guilty', 'of', 'being', 'irosponcible', 'with', 'life', 'on']]
تحلیل و استفاده از مدل Word2Vec آموزشدیده
بعد از اینکه مدل خود را با استفاده از کتابخانه Gensim آموزش دادیم، نوبت به استخراج اطلاعات ارزشمند میرسد. در ادامه، کاربردیترین متدهایی را که یک متخصص دیتا ساینس برای تحلیل متن به آنها نیاز دارد، بررسی میکنیم.
۱. استخراج لیست کلمات (Vocabulary)
اولین قدم این است که ببینیم مدل ما چه کلماتی را یاد گرفته است. استخراج لغتنامه (Vocabulary) به ما کمک میکند تا بدانیم ورودیهای معتبر برای مدل ما چه کلماتی هستند.
words = list(w2v.wv.vocab) print(words)
۲. مشاهده بردار عددی کلمات
شاید کنجکاو باشید بدانید بردار یک کلمه واقعاً چه شکلی است. وقتی بردار کلمهای مثل computer را استخراج میکنید، با صفی از اعداد اعشاری روبرو میشوید. اگرچه این اعداد برای ما بیمعنی به نظر میرسند، اما برای هوش مصنوعی، این اعداد دقیقاً همان «معنای» کلمه هستند که در لایههای مدل به دست آمدهاند. این بردارها در واقع بلوکهای سازنده لایه Embedding در شبکههای عصبی پیچیدهتر هستند.
print( w2v.wv['computer'] ) [ 1.57469660e-01 1.40157074e-01 -3.25907797e-01 -6.61702231e-02 3.14891905e-01 6.28795177e-02 -4.47840840e-02 4.59685735e-02 2.28131562e-02 2.39715233e-01 2.16640569e-02 7.56994933e-02 7.25479275e-02 -2.12595508e-01 -3.17018256e-02 1.75617978e-01 1.16614237e-01 1.87761128e-01 -5.23434877e-02 1.26436412e-01 1.70193449e-01 -1.07564844e-01 7.81135038e-02 2.12555289e-01 -5.70309162e-02 9.05565321e-02 -1.88474759e-01 9.64211822e-02 3.91710252e-02 -1.95013254e-03 -3.80934596e-01 2.09646896e-01 -9.98702249e-04 9.41597596e-02 -1.42464504e-01 -1.65631194e-02 -7.55091384e-02 8.67938846e-02 1.08608618e-01 4.55869362e-02 4.33201902e-02 1.76215306e-01 -5.83453756e-03 -2.22821414e-01 1.07587561e-01 -2.81930178e-01 9.92109030e-02 5.60606346e-02 -1.21222138e-01 -2.12018788e-01 4.72052723e-01 -3.12591828e-02 -5.42412922e-02 -7.44261965e-02 3.52113754e-01 -1.90538943e-01 -7.09711239e-02 1.26500160e-01 -8.27063695e-02 -2.49383450e-01 3.60160917e-01 -4.97583784e-02 1.39887974e-01 6.15979731e-02 -2.80842483e-01 -2.78978139e-01 1.32049369e-02 1.59579322e-01 -9.90456715e-02 -1.41615823e-01 2.03401580e-01 3.06724429e-01 8.00921768e-02 1.03146449e-01 -1.84937827e-02 -1.72093600e-01 -5.00345118e-02 -2.73426086e-01 -1.09151237e-01 -2.43122593e-01 4.89120372e-02 -2.03040734e-04 2.16287613e-01 -3.27757820e-02 2.49404564e-01 -1.49146728e-02 2.37480059e-01 -3.74893248e-02 2.34831229e-01 -2.00750634e-01 -4.97181853e-03 1.14014670e-02 1.63772311e-02 -1.84596679e-03 3.10765058e-01 3.27039659e-02 -7.81936795e-02 -1.61034450e-01 3.56368750e-01 4.25313175e-01]
۳. محاسبه شباهت کلمات (Similarity)
یکی از قدرتمندترین ویژگیهای Gensim، محاسبه شباهت بین دو کلمه است. مدل با استفاده از فرمولهای ریاضی (مثل تشابه کسینوسی)، فاصله بین بردارهای دو کلمه را میسنجد. به عنوان مثال، در یک مدل آموزشدیده روی اخبار، شباهت بین کلمات vladimir و putin بسیار بالا خواهد بود، در حالی که شباهت vladimir با modi (نخستوزیر هند) به مراتب کمتر است. این نشان میدهد که مدل، بافتار سیاسی را به خوبی درک کرده است.
w2v.wv.similarity('vladimir', 'putin')
0.81842446
w2v.wv.similarity('vladimir', 'modi')
0.6622772
۴. یافتن مشابهترین کلمات (Most Similar)
این متد قدرت واقعی Word2Vec در درک «بافتار» را نشان میدهد.
اگر کلمه covid را به مدل بدهید، خروجیهایی مثل coronavirus ، virus و disease دریافت میکنید.
اگر کلمه india را جستجو کنید، لیستی از نام سایر کشورها را به شما برمیگرداند.
جالبتر اینکه اگر یک فعل مثل pay را بدهید، مدل نه تنها همخانوادههای آن مثل paid و paying را پیدا میکند، بلکه کلمات مرتبطی مثل bills (قبوض) را هم پیشنهاد میدهد.
print(w2v.wv.most_similar('pay'))
[('paying', 0.7022949457168579), ('paid', 0.686174213886261), ('wages', 0.6507245898246765)]
print(w2v.wv.most_similar('covid'))
[('coronavirus', 0.6034492254257202), ('virus', 0.5288746953010559), ('corona', 0.5067222118377686)]
print(w2v.wv.most_similar('india'))
[('nigeria', 0.7527592182159424), ('pakistan', 0.7506697177886963), ('kenya', 0.6827074885368347)]
بصریسازی تعبیه کلمات؛ چطور بردارهای ۱۰۰ بعدی را ببینیم؟
بردارهای مدل Word2Vec معمولاً ۱۰۰ یا ۳۰۰ بُعد دارند. از آنجایی که ذهن ما انسانها فراتر از ۳ بعد را نمیتواند تصور کند، دیدن این همه عدد در کنار هم و درک رابطه آنها غیرممکن است. اما چاره چیست؟
برای این کار از تکنیکی به نام کاهش ابعاد (Dimensionality Reduction) استفاده میکنیم. یکی از معروفترینِ این روشها، الگوریتم PCA است. این الگوریتم بردارهای ۳۰۰ بعدی ما را به گونهای فشرده میکند که بتوانیم آنها را روی یک نمودار دوبعدی (مثل یک نقشه) نمایش دهیم.
تحلیل نمودار: قدرت خوشهبندی کلمات
وقتی بردارهای مدل را روی نمودار رسم میکنیم، اتفاق شگفتانگیزی میافتد: کلماتی که معنای مشابه دارند، به صورت خودکار در کنار هم «خوشه» (Cluster) تشکیل میدهند.
- خوشه اول (بیماری): کلماتی مثل coronavirus ، covid و virus در یک گوشه نمودار کاملاً به هم چسبیدهاند.
- خوشه دوم (اقتصادی): کلمات مرتبط با پرداخت مثل paying ، paid ، bills (قبوض) و wages (دستمزدها) یک گروه مستقل تشکیل دادهاند.
- خوشه سوم (کشورها): نام کشورها مثل kenya ، pakistan و saudiarabia در نقطهای دیگر از نمودار یک تجمع متراکم ایجاد کردهاند.
در واقع، فواصل روی این نمودار بیمعنی نیستند؛ هرچه دو نقطه به هم نزدیکتر باشند، یعنی مدل ما درک کرده است که آن دو کلمه در دنیای واقعی با هم ارتباط نزدیکتری دارند.
display_pca_scatterplot(w2v,['coronavirus', 'covid', 'virus', 'corona','disease', 'saudiarabia', 'doctor', 'hospital', 'pakistan', 'kenya', 'pay', 'paying', 'paid', 'wages', 'raise', 'bills', 'rent', 'charge'] )

جمعبندی و نتیجهگیری
ما از روشهای سادهای مثل Bag-of-Words شروع کردیم و دیدیم که چرا این مدلهای ابتدایی در درک ظرافتهای زبان انسانی ناتوان هستند. سپس با جادوی تعبیه کلمات (Word Embeddings) آشنا شدیم که به ماشین اجازه میدهد کلمات را نه به عنوان کدهای مستقل، بلکه به عنوان نقاطی در یک فضای معنایی ببیند.
نکات کلیدی که در این مقاله آموختیم:
- برتری Word Embeddings: این روش برخلاف مدلهای قدیمی، روابط معنایی (Semantics) و نحوی (Syntax) بین کلمات را به خوبی درک و حفظ میکند.
- جوهرۀ Word2Vec: این مدل برای هر کلمه یک بردار میسازد؛ به طوری که کلمات مشابه، بردارهای مشابه و نزدیکی در فضای ریاضی خواهند داشت.
- CBOW: کلمه هدف را از روی کلمات اطراف پیشبینی میکند (سریع و مناسب برای کلمات پرتکرار).
- Skip-gram: کلمات اطراف را از روی یک کلمه ورودی پیشبینی میکند (دقیق و عالی برای دیتاستهای کوچک و کلمات کمیاب).
- کتابخانه Gensim: این ابزار قدرتمند پایتون، پیادهسازی، آموزش و تحلیل مدلهای Word2Vec را برای ما بسیار ساده و بهینه کرده است.
- قابلیتهای پیشرفته: با استفاده از متدهای Gensim، ما توانستیم کلمات مشابه را پیدا کنیم، شباهتها را بسنجیم و حتی روابط منطقی و تناسبها (Analogies) را حل کنیم.
قدم بعدی شما چیست؟
دنیای پردازش زبان طبیعی بسیار گستردهتر از یک مدل واحد است. شما میتوانید از مدلهای آماده (Pre-trained) که روی میلیاردها کلمه (مثل اخبار گوگل) آموزش دیدهاند استفاده کنید یا مدل اختصاصی خودتان را برای پروژههای خاص بسازید.
فراموش نکنید که یادگیری هوش مصنوعی یک مسیر مستمر است. ما در دیتایاد در کنار شما هستیم تا این مسیر را با آموزشهای پروژهمحور و کاربردی، کوتاهتر و جذابتر کنیم. اگر به دنبال تسلط کامل بر مباحث علم داده و هوش مصنوعی هستید، پیشنهاد میکنیم حتماً دوره جامع هوش مصنوعی دیتایاد را بررسی کنید.
منبع: Medium



















