

سال ۲۰۱۸ برای مدلهای یادگیری ماشینِ مبتنی بر متن (یا بهطور دقیقتر، حوزهی پردازش زبان طبیعی یا NLP) یک نقطه عطف واقعی بود. در همین سال، مدل BERT معرفی شد؛ مدلی که نگاه ما به نمایش کلمات و جملات را بهطور بنیادین تغییر داد و نشان داد چگونه میتوان معنا و روابط پنهان میان واژهها را با دقتی بیسابقه مدلسازی کرد. این تحول تنها در حد مقالات آکادمیک باقی نماند، بلکه با معرفی مدلها و ابزارهای عملی، مسیر استفاده از NLP را برای طیف وسیعتری از علاقهمندان هموار کرد.
همزمان با این پیشرفتها، جامعهی NLP مدلها و چارچوبهایی ارائه داد که میتوان آنها را بهصورت آماده دانلود و در پروژههای واقعی استفاده کرد؛ اتفاقی که از آن با عنوان «لحظهی ImageNet در NLP» یاد میشود. درست همانطور که ImageNet جهشی اساسی در بینایی کامپیوتر ایجاد کرد، این موج جدید نیز باعث شد پردازش زبان طبیعی وارد مرحلهای کاملاً تازه شود.
BERT؛ نقطه عطفی در دنیای پردازش زبان
یکی از مهمترین رویدادهای حوزهی پردازش زبان طبیعی، انتشار مدل BERT بود؛ اتفاقی که از آن بهعنوان آغاز عصری جدید در NLP یاد میشود. BERT مدلی است که توانست در کیفیت انجام بسیاری از وظایف مبتنی بر زبان، رکوردهای متعددی را جابهجا کند. مدت کوتاهی پس از انتشار مقالهی علمی این مدل، تیم سازنده کدهای آن را بهصورت «متنباز» منتشر کرد و نسخههایی از مدل که از پیش روی حجم عظیمی از دادهها آموزش دیده بودند (Pre-trained)، برای دانلود در دسترس عموم قرار گرفتند.
در این بخش لینک دانلود مقاله BERT و لینک گیت هاب این مدل را برای شما قرار دادیم.
این موضوع یک پیشرفت بسیار مهم محسوب میشود؛ زیرا به هر کسی که در حال توسعهی مدلهای یادگیری ماشین برای پردازش زبان است، اجازه میدهد از این توان محاسباتی و دانشی عظیم بهعنوان یک ماژول آماده استفاده کند. نتیجهی این رویکرد، صرفهجویی قابلتوجه در زمان، انرژی، دانش تخصصی و منابع محاسباتی است؛ منابعی که پیش از این باید برای آموزش یک مدل NLP از صفر هزینه میشدند.
BERT بر پایهی مجموعهای از ایدههای هوشمندانه بنا شده است که در سالهای اخیر در جامعهی NLP شکل گرفتهاند؛ ایدههایی مانند:
- یادگیری متوالی نیمهنظارتی (Semi-supervised Sequential Learning)
- مدل ELMo
- روش ULMFiT
- مدل OpenAI Transformer
- و در نهایت، ساختار انقلابی Transformer
برای اینکه بتوانیم بهدرستی درک کنیم BERT دقیقاً چیست و چرا تا این حد تأثیرگذار بوده، لازم است ابتدا با این مفاهیم آشنا شویم. به همین دلیل، قبل از ورود به جزئیات درونی خودِ مدل، بهتر است از یک دید کاربردی شروع کنیم و ببینیم BERT چگونه در پروژههای واقعی مورد استفاده قرار میگیرد. آشنایی عملی با این مسیر، درک عمیقتری از نقش BERT در پردازش زبان طبیعی به ما میدهد.
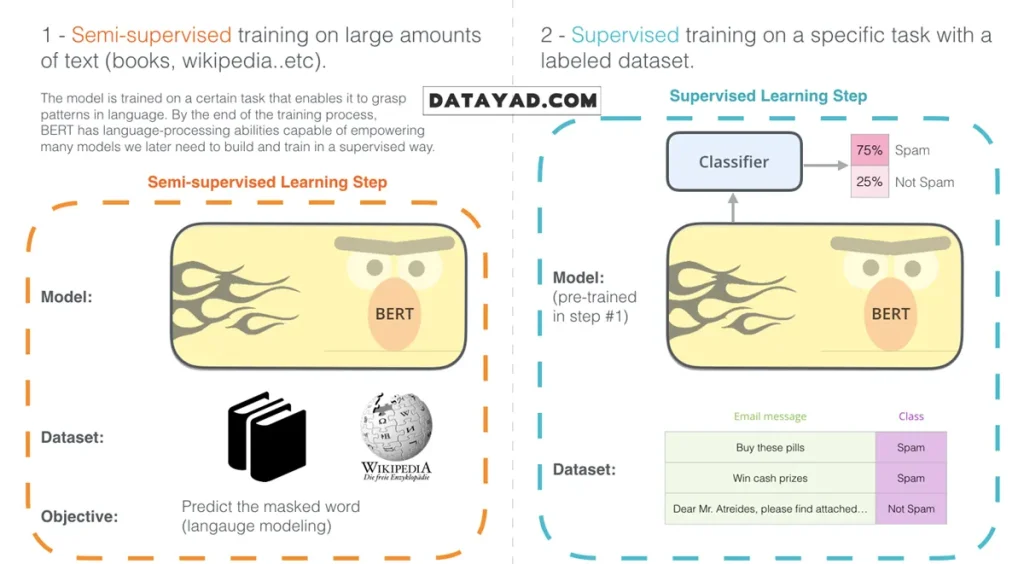
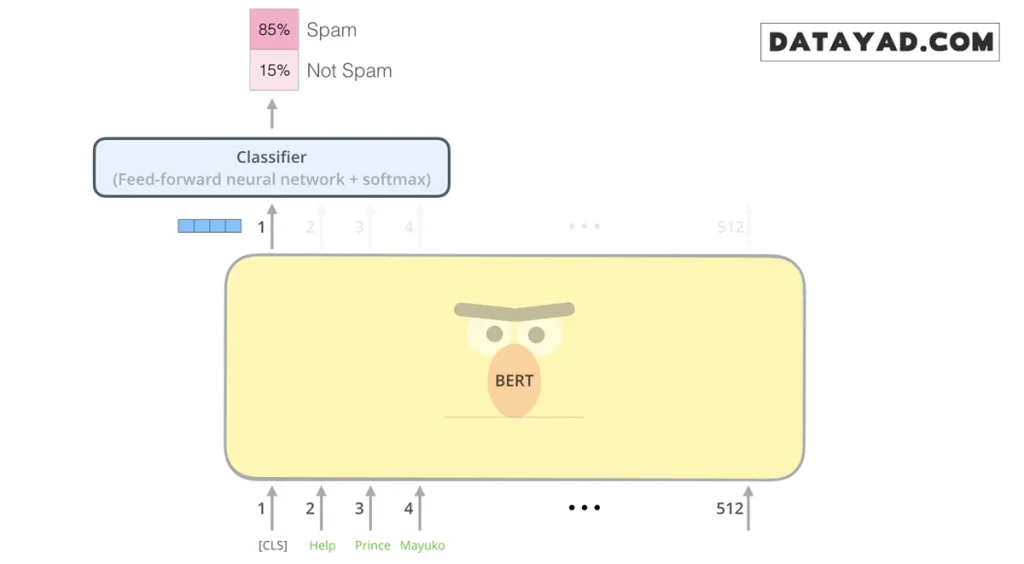
مثال: طبقهبندی جملات (Sentence Classification)
سادهترین و رایجترین روش استفاده از BERT، بهکارگیری آن برای طبقهبندی یک متن واحد است. برای مثال، فرض کنید میخواهید مدلی بسازید که تشخیص دهد یک ایمیل «اسپم» (Spam) است یا «معمولی» (Not Spam).
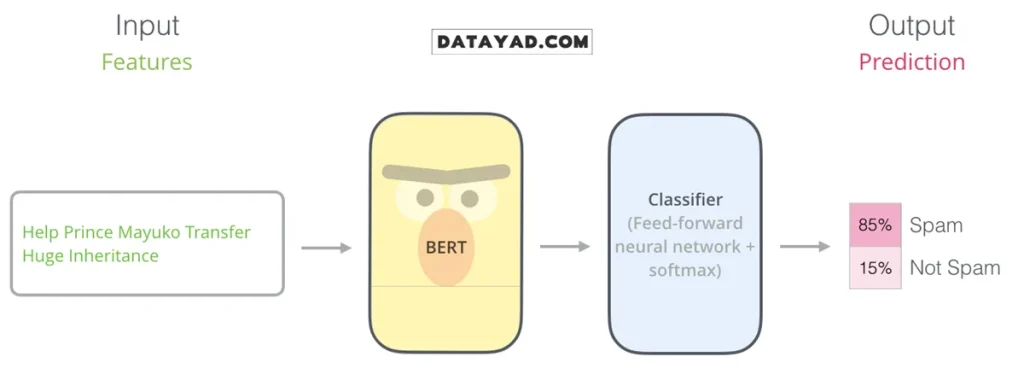
در چنین حالتی، ساختار مدل به این شکل است که BERT بهعنوان بخش اصلی درک زبان عمل میکند (که از قبل کاملا آموزش دیده و درک کاملی از زبان دارد) و در انتهای آن، یک لایهی سادهی طبقهبندی قرار میگیرد.
در فرآیند آموزش این مدل، تمرکز اصلی روی آموزش بخش «طبقهبندیکننده» (Classifier) است و در طول یادگیری، تغییرات بسیار محدودی در پارامترهای مدل اصلی BERT ایجاد میشود. به این شیوهی آموزش، تنظیم دقیق (Fine-Tuning) گفته میشود؛ رویکردی که ریشه در مفاهیم پیشرفتهای مانند یادگیری متوالی نیمهنظارتی و روش ULMFiT دارد.
درک بهتر فرآیند آموزش
اگر آشنایی عمیقی با مفاهیم یادگیری ماشین ندارید، لازم است بدانید که وقتی از «طبقهبندیکننده» صحبت میکنیم، در واقع وارد حوزهی یادگیری نظارتشده (Supervised Learning) شدهایم. این بدان معناست که برای آموزش مدل، به یک مجموعه دادهی برچسبدار نیاز داریم.
در مثال تشخیص اسپم، دادههای آموزشی شامل مجموعهای از پیامها هستند که برای هر کدام مشخص شده آیا اسپم است یا خیر. مدل با مشاهدهی این نمونهها، بهتدریج یاد میگیرد که الگوهای زبانی موجود در متن را به برچسبهای صحیح مرتبط کند.
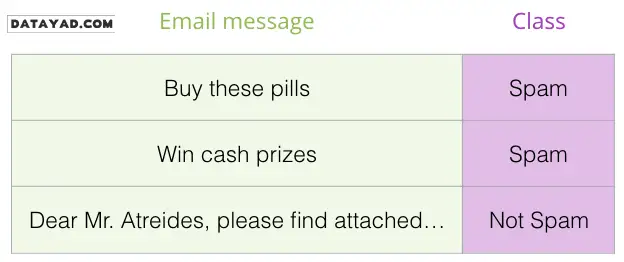
نمونههای دیگر از کاربرد طبقهبندی متن
علاوه بر تشخیص اسپم، از قابلیت طبقهبندی متن در BERT میتوان در کاربردهای متنوع دیگری نیز استفاده کرد، از جمله:
تحلیل احساسات (Sentiment Analysis):
ورودی: نظرات کاربران دربارهی یک فیلم یا محصول
خروجی: تشخیص مثبت یا منفی بودن نظر (مانند مجموعهدادهی SST)
راستیآزمایی مطالب (Fact-checking):
ورودی: یک جمله یا متن خبری
خروجی: تشخیص اینکه آیا متن شامل یک «ادعا» (Claim) است یا صرفاً یک خبر ساده
در مراحل پیشرفتهتر، مدل میتواند درستی یا نادرستی آن ادعا را نیز بررسی کند
اگر شما هم علاقهمند هستید که بدانید چطور میتوانید چنین پروژههایی را با دادههای واقعی اجرا کنید، از آموزش جامع LLM و NLP دیتایاد استفاده کنید تا مهارتهای لازم برای پیادهسازی این مدلها را به دست آورید.
معماری مدل BERT: نگاهی به ساختار درونی
در مقالهی اصلی BERT، دو نسخهی متفاوت از این مدل معرفی شده است که هر کدام با هدف مشخصی طراحی شدهاند:
- BERT Base: این نسخه از نظر اندازه و پیچیدگی، قابل مقایسه با مدل OpenAI Transformer است. هدف اصلی از ارائهی BERT Base، فراهمکردن امکان مقایسهی منصفانه و دقیق عملکرد BERT با سایر مدلهای همردهی آن بود.
- BERT Large: نسخهای بسیار بزرگتر و قدرتمندتر که توانست در بسیاری از وظایف پردازش زبان طبیعی، نتایج خیرهکنندهای در حد بهترین مدلهای زمان خود به ثبت برساند.
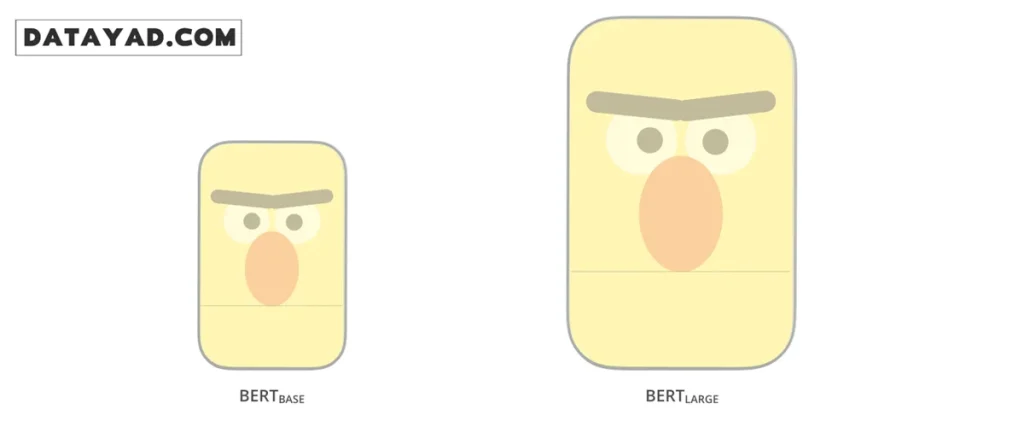
بهطور خلاصه، BERT را میتوان مجموعهای از انکودرهای ترنسفورمر (Transformer Encoders) دانست که بهصورت لایهلایه روی هم قرار گرفتهاند. اگر با ساختار ترنسفورمر آشنایی ندارید، درک مفاهیم پایهی آن اهمیت زیادی دارد؛ چرا که ترنسفورمرها سنگبنای اصلی BERT و تقریباً تمام مدلهای پیشرفتهای هستند که پس از آن معرفی شدهاند.
مقایسه مشخصات فنی نسخههای BERT
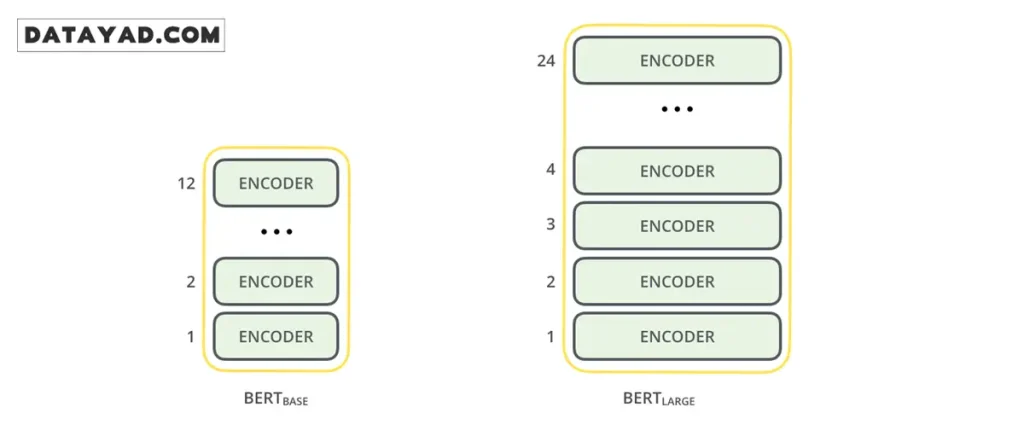
هر دو نسخهی BERT از تعداد زیادی لایهی انکودر تشکیل شدهاند؛ لایههایی که در مقالهی اصلی با عنوان Transformer Blocks شناخته میشوند. در جدول زیر، میتوانید تفاوتهای کلیدی این دو نسخه را در مقایسه با ترنسفورمر اولیه مشاهده کنید.
| مشخصات فنی | ترنسفورمر اولیه | BERT Base | BERT Large |
| تعداد لایهها (Encoder Layers) | ۶ لایه | ۱۲ لایه | ۲۴ لایه |
| واحدهای پنهان (Hidden Units) | ۵۱۲ واحد | ۷۶۸ واحد | ۱۰۲۴ واحد |
| هدهای توجه (Attention Heads) | ۸ هد | ۱۲ هد | ۱۶ هد |
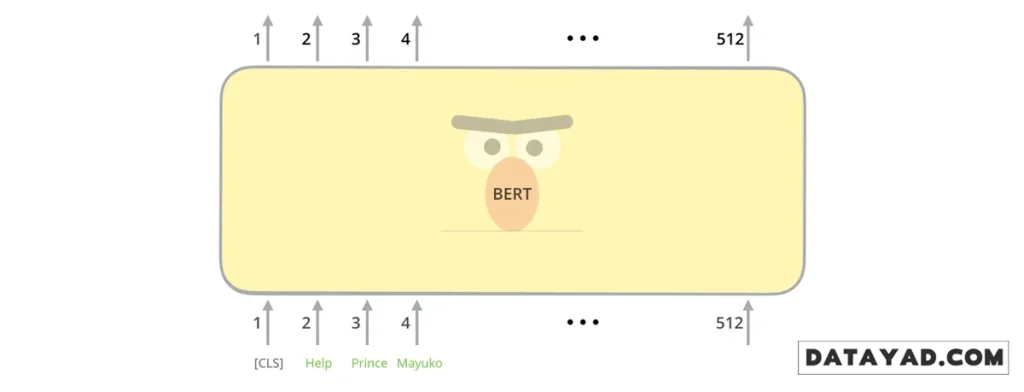
ورودیهای مدل BERT: دادهها چگونه وارد میشوند؟
اولین نکتهای که در ورودیهای BERT جلب توجه میکند، وجود یک توکن ویژه به نام [CLS] در ابتدای هر توالی متنی است. واژهی CLS مخفف Classification (طبقهبندی) است. شاید در نگاه اول حضور این توکن غیرمعمول به نظر برسد، اما در ادامه خواهیم دید که نقش آن در انجام وظایف طبقهبندی متنی تا چه اندازه حیاتی است.
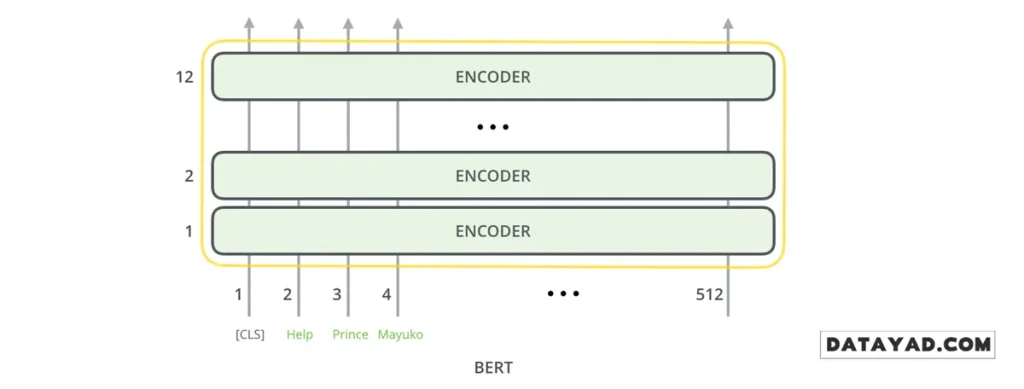
BERT، دقیقاً مانند بخش انکودر در ترنسفورمر کلاسیک، دنبالهای از کلمات (یا بهطور دقیقتر، توکنها) را بهعنوان ورودی دریافت میکند. این توکنها در طول لایههای مختلف مدل بهتدریج پردازش میشوند. در هر لایه، دو عملیات اصلی روی دادهها انجام میگیرد:
- مکانیزم توجه به خود (Self-Attention): مدل روابط و وابستگیهای بین کلمات را بررسی میکند.
- شبکهی Feed-forward: نمایشهای بهدستآمده پردازش شده و به لایهی بعدی منتقل میشوند.
از نظر معماری، BERT تا این مرحله تفاوتی اساسی با ترنسفورمر استاندارد ندارد؛ البته بهجز اندازهی لایهها و تنظیمات فنی که پیشتر به آنها اشاره شد. تفاوت اصلی، و نقطهای که نبوغ BERT در آن آشکار میشود، در نحوهی استفاده از خروجیهای مدل نهفته است.
خروجیهای مدل BERT: از بردارها تا تصمیمگیری نهایی
در معماری BERT، برای هر جایگاه (Position) در خروجی مدل، یک بردار عددی با اندازهی ثابت تولید میشود. در نسخهی BERT Base، طول این بردار برابر با 768 است. با این حال، برای انجام وظایفی مانند طبقهبندی متن، نیازی به استفاده از تمام این بردارها نداریم.
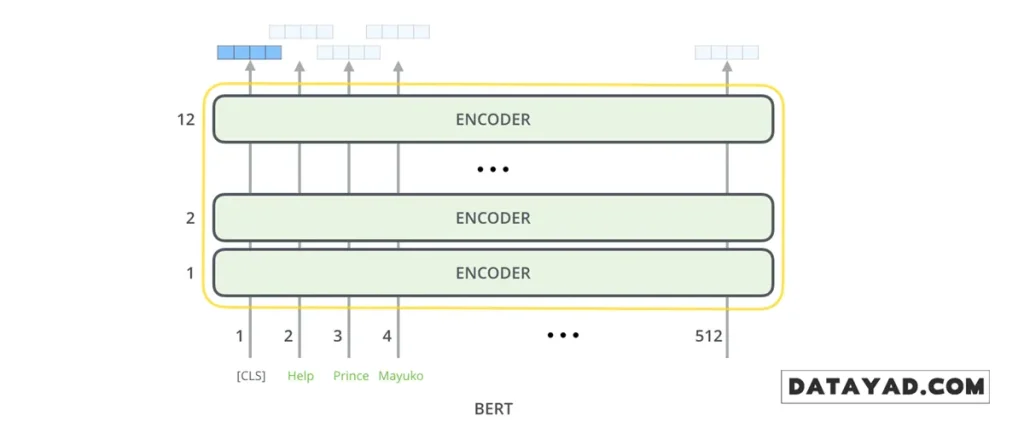
تمرکز بر خروجی توکن [CLS]
در مثال طبقهبندی جملات که پیشتر بررسی شد، تمرکز ما تنها روی خروجی اولین جایگاه در توالی است؛ یعنی همان موقعیتی که توکن ویژهی [CLS] در ورودی قرار داده شده بود.
بردار 768بعدیای که در این جایگاه تولید میشود، در عمل نمایندهای فشرده از کل محتوای جمله است؛ برداری که میتوان آن را «چکیدهی معنایی» متن ورودی در نظر گرفت. این بردار سپس بهعنوان ورودی به یک لایهی طبقهبندیکننده (Classifier) داده میشود.
ساخت لایهی طبقهبندی (Classifier)
یکی از نکات قابلتوجه دربارهی BERT این است که برای دستیابی به عملکرد بالا، نیازی به طراحی لایههای خروجی پیچیده وجود ندارد. در مقالهی اصلی نشان داده شده است که حتی استفاده از یک شبکهی عصبی تکلایهای بهعنوان طبقهبندیکننده نیز میتواند نتایج بسیار خوبی ارائه دهد.
- در مسائل دودستهای (مانند اسپم یا غیر اسپم)، خروجی مدل به یک نورون ختم میشود.
در مسائل چنددستهای (برای مثال دستهبندی ایمیلها به «اسپم»، «اجتماعی»، «تبلیغاتی» و «معمولی»)، کافی است تعداد نورونهای خروجی متناسب با تعداد کلاسها تنظیم شود. در این حالت، معمولاً از تابع Softmax برای محاسبهی احتمال تعلق متن به هر دسته استفاده میشود.
در نهایت، میتوان گفت که BERT بخش پیچیده و پرهزینهی مسئله، یعنی «درک زبان»، را انجام میدهد و تنها کاری که باقی میماند، افزودن یک لایهی ساده برای تصمیمگیری نهایی است.
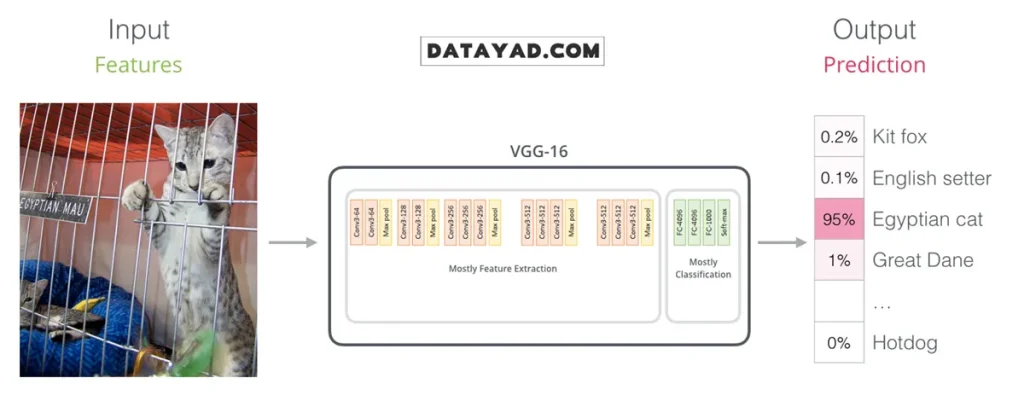
شباهت BERT با شبکههای عصبی پیچشی (CNN)
اگر پیشزمینهای در حوزه بینایی کامپیوتر (Computer Vision) داشته باشید، نحوهی تبدیل ورودی به یک نمایش برداری در BERT میتواند برایتان آشنا به نظر برسد. این فرآیند از نظر مفهومی شباهت زیادی به ساختارهایی دارد که در شبکههای عصبی پیچشی مانند VGGNet مشاهده میشود.
در شبکههای CNN، بخش کانولوشنی وظیفه استخراج ویژگیهای سطح پایین و بالا از تصویر را بر عهده دارد و در نهایت، این ویژگیها بهصورت یک بردار به لایههای کاملاً متصل (Fully Connected) برای انجام وظیفههایی مانند طبقهبندی منتقل میشوند.
در BERT نیز نقش مشابهی ایفا میشود؛ با این تفاوت که بهجای تصویر، ورودی متنی است. لایههای ترنسفورمر، الگوهای معنایی و وابستگیهای زبانی را از متن استخراج کرده و خروجی نهایی آنها بهصورت یک بردار فشرده، به لایهی تصمیمگیر (مانند لایهی طبقهبندی) منتقل میشود. این شباهت، نه در معماری دقیق، بلکه در منطق میان این دو مدل دیده میشود. برای آشنایی عمیقتر با این دیدگاههای پایهای در حوزه مدلهای یادگیری ماشین، آموزش رایگان یادگیری عمیق میتوانند چارچوب مفهومی مناسبی ارائه دهند.
عصری نو در بازنمایی کلمات (Embedding)
پیشرفتهای اخیر در پردازش زبان طبیعی، تغییرات اساسی در نحوهی نمایش کلمات ایجاد کردهاند. تا سالها، جایگذاری کلمات یا Word Embeddingها نقش کلیدی در موفقیت مدلهای NLP داشتند. روشهایی مانند Word2Vec و GloVe امکان نمایش کلمات بهصورت بردارهای عددی را فراهم کردند؛ بردارهایی که روابط معنایی و گرامری بین کلمات را در خود حفظ میکردند.
برای مثال، این مدلها قادر بودند روابط معنایی مانند نسبت «پایتخت به کشور» یا روابط گرامری مانند تبدیل زمان افعال را در فضای برداری بازنمایی کنند. به همین دلیل، استفاده از embeddingهای از پیشآموزشدیده به یک استاندارد در پروژههای NLP تبدیل شد و بسیاری از مدلها بهجای یادگیری این بردارها از ابتدا، از نسخههای آماده استفاده میکردند.
با این حال، این بردارها یک ویژگی مهم داشتند: ایستا بودن. هر کلمه، صرفنظر از context یا زمینه متن، همیشه به یک بردار ثابت نگاشت میشد. BERT دقیقاً در همین نقطه مسیر را تغییر داد و مفهوم embeddingهای وابسته به بافت (Contextual Embeddings) را بهصورت عملی و گسترده وارد جریان اصلی NLP کرد؛ تغییری که تأثیر آن، فراتر از یک بهبود عددی، در شیوهی درک زبان توسط مدلها قابل مشاهده است.
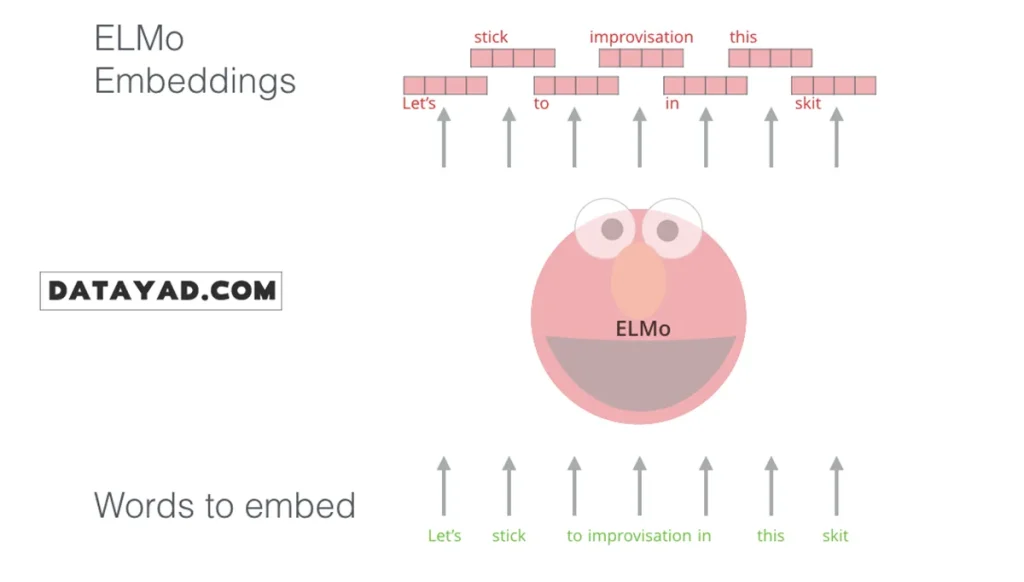
مدل ELMo: وابستگی به متن در نمایش کلمات
در مدلهای قدیمی embedding مانند GloVe، هر کلمه یک بردار ثابت داشت. به عنوان مثال، کلمهی “stick” (به معنای چوب یا چسباندن) همیشه با همان بردار نمایش داده میشد، صرفنظر از جملهای که در آن به کار رفته بود.
در سالهای ۲۰۱۷ و ۲۰۱۸، محققان حوزه NLP، از جمله نویسندگان ELMo، ایدهای مطرح کردند: معنای یک کلمه کاملاً به متن اطراف آن وابسته است. بنابراین بهتر است برداری برای هر کلمه تولید شود که به جمله یا متن اطراف آن وابسته باشد.
ELMo این مفهوم را عملی کرد و با معرفی Contextualized Word Embeddings توانست وابستگی معنایی کلمات به بافت را در مدلهای پردازش زبان طبیعی لحاظ کند.
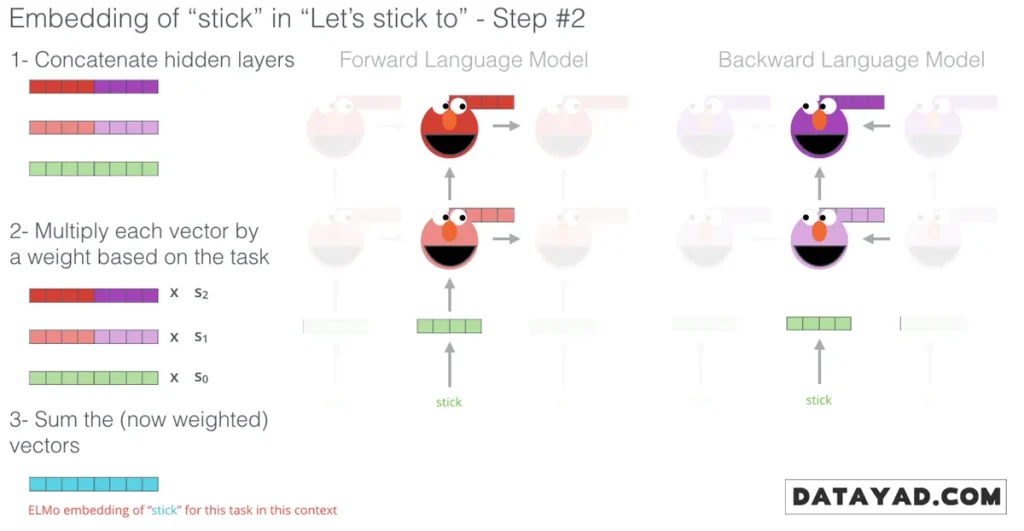
ساختار و عملکرد ELMo
در ELMo، به جای اختصاص یک بردار ثابت به هر کلمه، کل جمله در نظر گرفته میشود و برداری اختصاصی برای هر کلمه تولید میشود. برای این کار، مدل از LSTM دوطرفه (Bi-directional LSTM) استفاده میکند که برای پردازش دادههای متوالی طراحی شده است.
ELMo یک گام مهم در مسیر پیشآموزش (Pre-training) بود: مدل میتواند روی حجم عظیمی از دادههای متنی آموزش ببیند و سپس به عنوان یک ماژول آماده در مدلهای دیگر استفاده شود.
نکات کلیدی فنی ELMo
- پردازش دوطرفه: مدل کلمات را هم از چپ به راست و هم از راست به چپ پردازش میکند تا وابستگیهای معنایی کاملتر درک شود.
- ترکیب لایهها: بردار نهایی هر کلمه از ترکیب لایههای داخلی شبکه عصبی (Hidden States) ساخته میشود، بهطوری که عصاره معنای کلمه در جمله حفظ شود.
- مدلسازی زبان: ELMo با پیشبینی کلمه بعدی در یک دنباله، روی دادههای بدون برچسب یاد میگیرد و نیازی به مجموعه دادههای دستی ندارد.
ULM-FiT؛ تثبیت مفهوم یادگیری انتقالی در NLP
مدل ULM-FiT روشهایی معرفی کرد که امکان استفاده بهینه از دانش بهدست آمده در مرحله پیشآموزش (Pre-training) را فراهم میکند. این مدل فراتر از بردارهای کلمات عمل میکند و فرآیندی ارائه میدهد که طی آن یک مدل زبان (Language Model) میتواند برای وظایف مختلف به صورت دقیق تنظیم دقیق (Fine-tuning) شود.
با ظهور ULM-FiT، حوزه پردازش زبان طبیعی (NLP) توانست به همان سطح از انتقال یادگیری (Transfer Learning) دست یابد که پیشتر در بینایی کامپیوتر تجربه شده بود.
ترنسفورمر؛ عبور از محدودیتهای LSTM
با معرفی مدل ترنسفورمر (Transformer)، توانایی مدلها در انجام وظایف پیچیده NLP به شکل قابل توجهی افزایش یافت. نتایج درخشان این مدل در ترجمه ماشینی نشان داد که ترنسفورمرها میتوانند جایگزین LSTM شوند، به ویژه در درک وابستگیهای طولانیمدت (Long-term dependencies)، یعنی توانایی ارتباطدهی بین کلماتی که فاصله زیادی از هم دارند.
اما چالش این بود که ساختار ترنسفورمر، شامل انکودر و دکودر، برای ترجمه طراحی شده بود. چگونه میتوان از آن در وظایف دیگر مانند طبقهبندی جملات یا پاسخ به سوالات استفاده کرد؟
ترنسفورمر OpenAI؛ استفاده از دیکودر برای مدلسازی زبان
محققان OpenAI متوجه شدند که برای پیادهسازی یادگیری انتقالی، لزوماً به کل ساختار ترنسفورمر نیاز نداریم. آنها فقط از بخش دیکودر (Decoder) استفاده کردند.
دیکودر انتخاب هوشمندانهای بود؛ زیرا این بخش ذاتاً برای پیشبینی کلمه بعدی طراحی شده است. دیکودر کلمات آینده را «ماسک» (Mask) میکند تا مدل نتواند به کلمات بعدی نگاه کند و مجبور شود آنها را حدس بزند. این ویژگی برای تولید متن و ترجمه کلمه به کلمه بسیار حیاتی است.
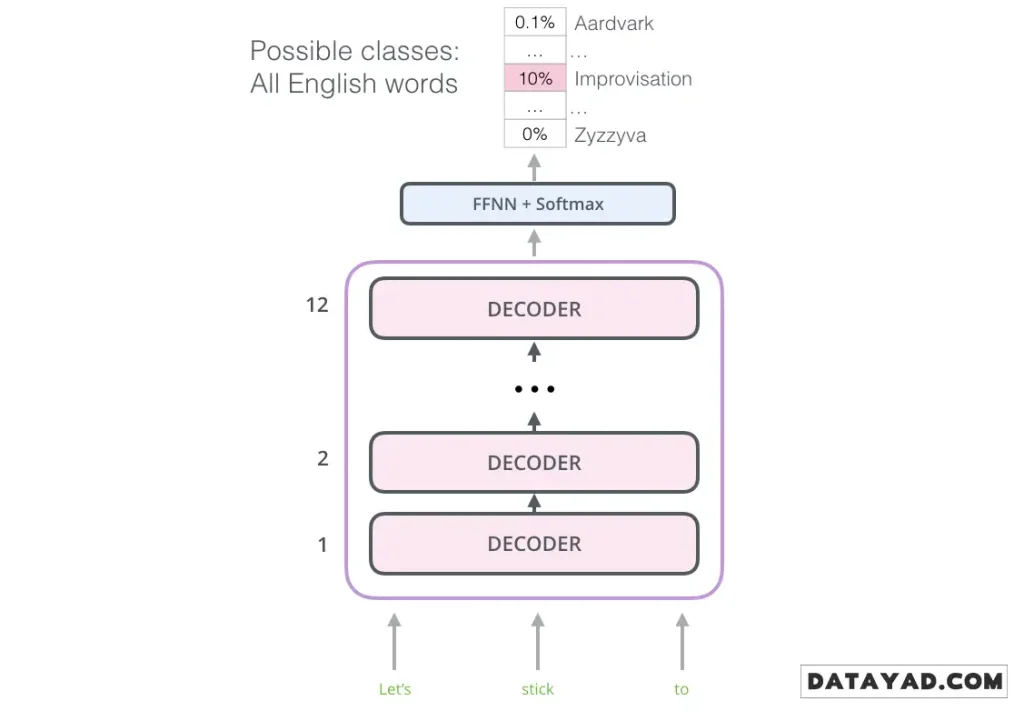
مشخصات این مدل:
- ۱۲ لایه دکودر: این لایهها روی هم چیده شدهاند.
- حذف لایه میانی: چون انکودری در کار نیست، لایه «توجه انکودر-دکودر» حذف شده است.
- یادگیری از کتابها: این مدل با متن ۷۰۰۰ کتاب آموزش دید! کتابها منابع فوقالعادهای هستند، زیرا برخلاف توییتر یا مقالات کوتاه، به مدل اجازه میدهند روابط معنایی را در متنهای طولانی یاد بگیرد.
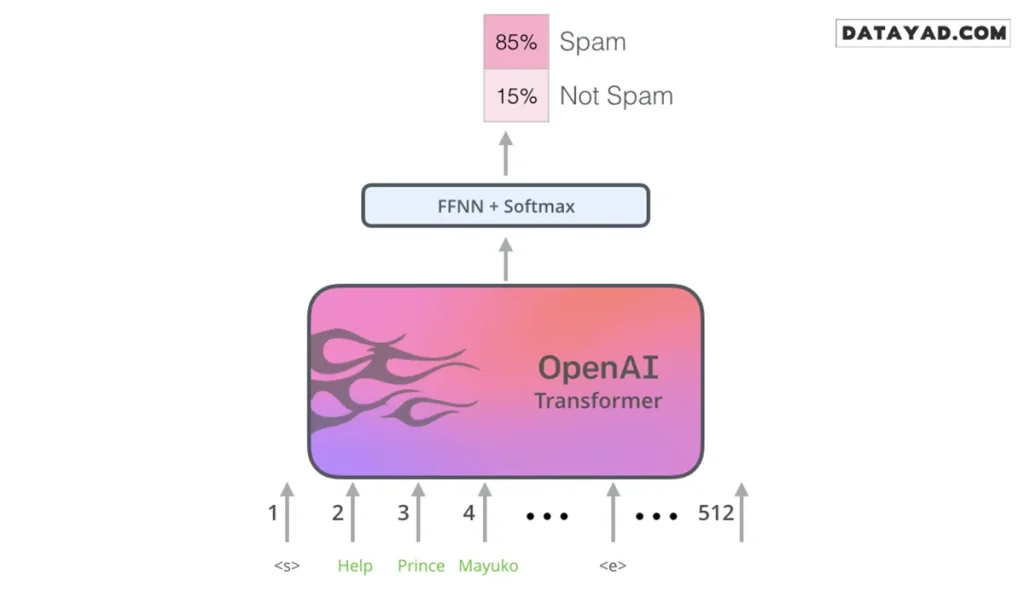
انتقال یادگیری به وظایف پاییندستی
بعد از اینکه ترنسفورمر OpenAI روی این حجم عظیم از دادهها آموزش دید، میتوان از آن برای وظایفی مثل «تشخیص اسپم» استفاده کرد. کافی است ورودیهای مدل را بر اساس نوع تسک (مثل طبقهبندی، شباهت جملات یا سوال و جواب) تغییر دهیم.
BERT؛ بازگشت به انکودرها و جادوی دوطرفه بودن
مدل OpenAI Transformer نشان داد که میتوان از مدلهای پیشآموزش دیده برای وظایف مختلف استفاده کرد، اما یک ویژگی مهم ELMo یعنی دوطرفه بودن (Bi-directionality) در آن وجود نداشت.
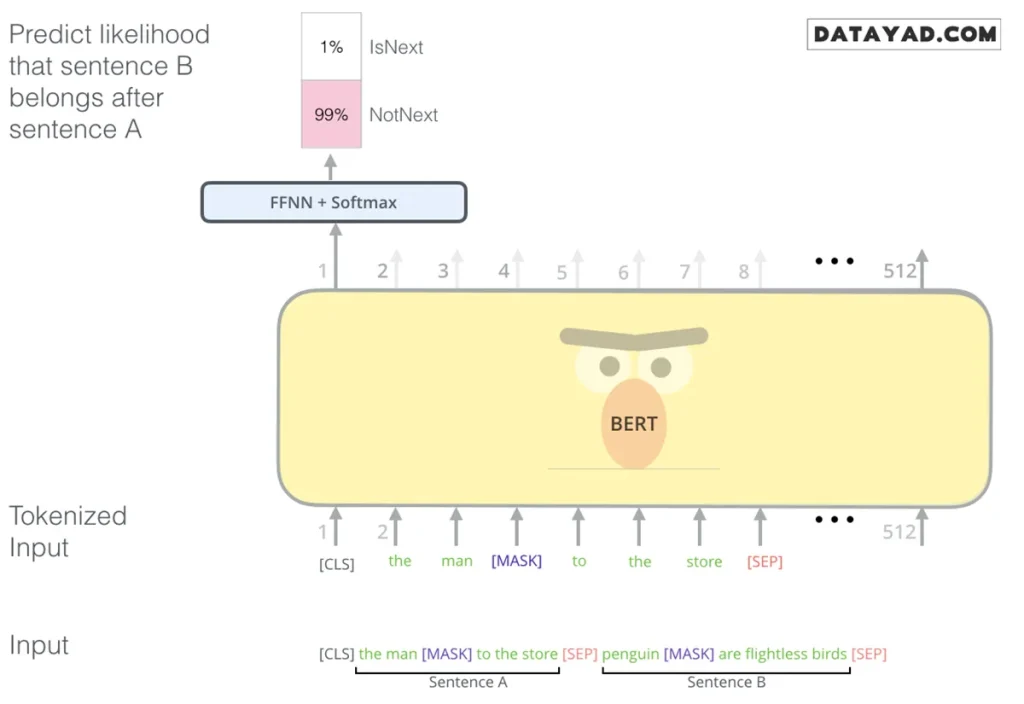
BERT این مشکل را با استفاده از مدل زبان ماسکشده (Masked Language Model) حل کرد:
- حدود ۱۵٪ از کلمات ورودی با توکن [MASK] جایگزین میشوند.
- مدل باید حدس بزند کلمه اصلی زیر ماسک چه بوده است.
- برای جلوگیری از ابهام در مرحله تنظیم دقیق (Fine-tuning)، برخی کلمات با کلمات تصادفی جایگزین میشوند یا بدون تغییر باقی میمانند.
همچنین BERT یک آموزش اضافی به نام Next Sentence Prediction دارد تا مدل بتواند رابطه بین دو جمله را درک کند، که برای پاسخ به سوالات یا تشخیص شباهت جملات ضروری است.
استفاده از BERT به عنوان استخراجکننده ویژگی (Feature Extraction)
تنظیم دقیق (Fine-tuning) تنها راه استفاده از BERT نیست. شما میتوانید مانند ELMo، از BERT برای تولید بردارهای متنی غنی استفاده کنید و سپس این بردارها را به مدلهای فعلی خودتان بدهید. تحقیقات نشان داده که استفاده از خروجی لایههای آخر BERT برای کارهایی مثل «تشخیص موجودات نامدار» (NER)، نتایجی بسیار نزدیک به روش تنظیم دقیق کامل دارد.
چطور با BERT کار را شروع کنیم؟
اگر مشتاق هستید که همین حالا دست به کد شوید، بهترین راه استفاده از نوتبوکهای آماده در Google Colab است که از TPU برای پردازش سریع استفاده میکنند. کد اصلی BERT در مخزن گیتهاب آن شامل بخشهای زیر است:
- modeling.py: قلب تپنده مدل که ساختار انکودر ترنسفورمر در آن تعریف شده است.
- tokenization.py: بخشی که کلمات شما را به قطعات ریزتری به نام WordPieces تبدیل میکند تا BERT بتواند آنها را پردازش کند.
- مدلهای پیشآموزش دیده: نسخههای مختلفی از BERT (پایه، بزرگ، چندزبانه و چینی) برای دانلود در دسترس هستند که روی ۱۰۲ زبان مختلف (از جمله ویکیپدیا) آموزش دیدهاند.
- پیادهسازیهای معروفی مثل کتابخانه Hugging Face در پایتون نیز اجازه میدهند تا به راحتی از این قدرت بیپایان در پروژههای خود استفاده کنید.
اگر میخواهید به صورت گامبهگام و پروژهمحور، کار با این کتابخانهها و مدل ها را یاد بگیرید، دوره جامع آموزش پردازش زبان طبیعی دیتایاد بهترین نقطه برای شروع حرفهای شماست. ضمنا برای رسیدن به تخصص های بیشتر در هوش مصنوعی از دیگر آموزشهای هوش مصنوعی دیتایاد استفاده کنید.
منبع: jalammar.github



















