

در دنیای هوش مصنوعی و پردازش زبان طبیعی (NLP)، مدلهای انکودر-دیکودر (Encoder-Decoder) انقلابی در نحوه تعامل ماشینها با توالیهای داده ایجاد کردهاند. این مدلها که به عنوان ساختار پایه در بسیاری از سیستمهای پیشرفته امروزی شناخته میشوند، برای وظایفی طراحی شدهاند که در آنها ورودی و خروجی هر دو به صورت توالی (Sequence) هستند و لزوماً طول یکسانی ندارند. از ترجمه ماشینی گرفته تا خلاصهسازی متن و پردازش گفتار، همگی مدیون این معماری قدرتمند هستند که در این مطلب از بخش آموزش هوش مصنوعی به بررسی آن میپردازیم.
مدل انکودر-دیکودر چیست؟
اگر تا به حال از ترجمه گوگل استفاده کردهاید، یا دیدهاید که یک مدل هوش مصنوعی متنی را خلاصه میکند یا به سوالی پاسخ میدهد، احتمالاً با خروجی یک مدل انکودر-دیکودر روبهرو شدهاید.
- اما این مدل دقیقاً چگونه کار میکند؟
- چطور یک جمله را میفهمد و آن را به جملهای دیگر تبدیل میکند؟
- و چرا این معماری نقطه عطفی در پردازش زبان طبیعی محسوب میشود؟
در ادامه بهصورت گامبهگام بررسی میکنیم که مدل Encoder–Decoder چیست، چگونه کار میکند و چرا پایه بسیاری از مدلهای مدرن امروزی است. مدل انکودر-دیکودر نوعی شبکه عصبی است که برای مدیریت وظایف توالی به توالی (Seq2Seq) استفاده میشود. ویژگی اصلی این مدل، توانایی آن در تبدیل یک توالی ورودی با طول مشخص به یک توالی خروجی با طولی متفاوت است.
این سیستم از دو بخش اصلی تشکیل شده است:
- انکودر (Encoder): توالی ورودی را پردازش کرده و آن را به یک نمایش ثابت به نام بردار بافت (Context Vector) تبدیل میکند.
- دیکودر (Decoder): از این بردار بافت استفاده میکند تا توالی خروجی را مرحله به مرحله تولید نماید.
این معماری بهویژه در مواردی که طول جملات مبدأ و مقصد با هم تفاوت دارند (مثل ترجمه انگلیسی به فارسی)، عملکرد بسیار درخشانی دارد.
معماری مدل انکودر-دیکودر
در یک ساختار انکودر-دیکودر، ما با دو شبکه عصبی مجزا روبرو هستیم که در عین استقلال، مکمل یکدیگرند. هر یک از این دو بخش وظیفه مشخصی را بر عهده دارند تا در نهایت یک خروجی معنادار تولید شود.
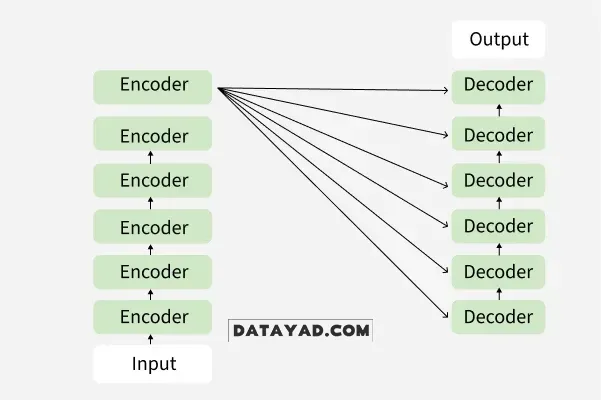
انکودر (Encoder)
وظیفه اصلی انکودر، “فهم” ورودی است. انکودر توالی ورودی را توکن به توکن پردازش کرده و اطلاعات موجود در آن را در یک فضای برداری فشرده میکند.
- پردازش توالی: انکودر معمولاً از شبکههای RNN یا LSTM استفاده میکند تا توکنهای ورودی را به صورت ترتیبی پردازش کند.
- بهروزرسانی وضعیتهای پنهان (Hidden States): با ورود هر کلمه جدید، وضعیت پنهان مدل بهروز میشود تا روابط بین کلمات قبلی و فعلی حفظ شود.
- تولید بردار بافت (Context Vector): خروجی نهایی انکودر، آخرین وضعیت پنهان (Hidden State) و وضعیت سلول (Cell State) است. این بردار در واقع “عصاره” یا خلاصهای از کل معنای جمله ورودی است.
دیکودر (Decoder)
دیکودر وظیفه دارد “عصاره” تولید شده توسط انکودر را بازخوانی کرده و آن را به زبان مقصد یا فرمت خروجی ترجمه کند.
- پیشبینی گامبهگام: دیکودر با استفاده از بردار بافت و آخرین کلمه تولید شده، کلمه بعدی را پیشبینی میکند.
- تولید تا توکن پایان: این فرآیند به صورت بازگشتی ادامه مییابد تا زمانی که مدل به توکن پایان (مثلاً _end) برسد.
- مقداردهی اولیه: دیکودر وضعیتهای اولیه خود را مستقیماً از وضعیتهای نهایی انکودر دریافت میکند؛ این یعنی شروع کار دیکودر با آگاهی کامل از معنای جمله ورودی است.
نحوه کارکرد گامبهگام مدل انکودر-دیکودر
درک فرآیند درونی این مدل به ما کمک میکند تا بفهمیم چگونه یک جمله از یک زبان به زبان دیگر ترجمه میشود. بیایید این فرآیند را مرحله به مرحله بررسی کنیم:
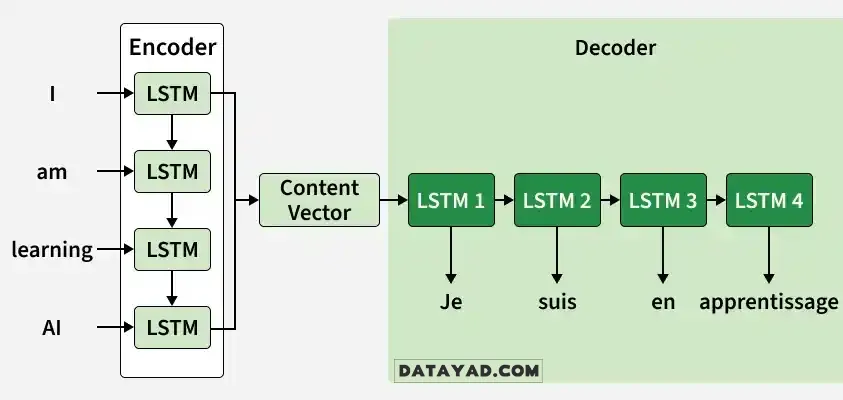
گام ۱: توکنبندی ورودی
ابتدا جمله ورودی (مثلاً: “I am learning AI”) به واحدهای کوچکتری به نام توکن شکسته میشود. نتیجه به صورت یک لیست خواهد بود: [“I”, “am”, “learning”, “AI”]. سپس هر توکن به یک بردار عددی تبدیل میشود که ماشین قادر به درک آن باشد؛ به این فرآیند Embedding یا جاسازی کلمات میگویند.
گام ۲: فرآیند کدگذاری (Encoding)
انکودر (که معمولاً یک شبکه LSTM است) این بردارها را به صورت متوالی پردازش میکند. در هر گام:
- مدل وضعیت پنهان (Hidden State) خود را بر اساس کلمه فعلی و بافت کلمات قبلی بهروز میکند.
- این کار باعث میشود مدل روابط بین کلمات و ترتیب آنها را درک کند.
- پس از اتمام جمله، انکودر یک بردار بافت (Context Vector) تولید میکند که شامل آخرین وضعیتهای پنهان و سلول (Hidden & Cell States) است. این بردار، چکیده تمام معنای جمله ورودی است.
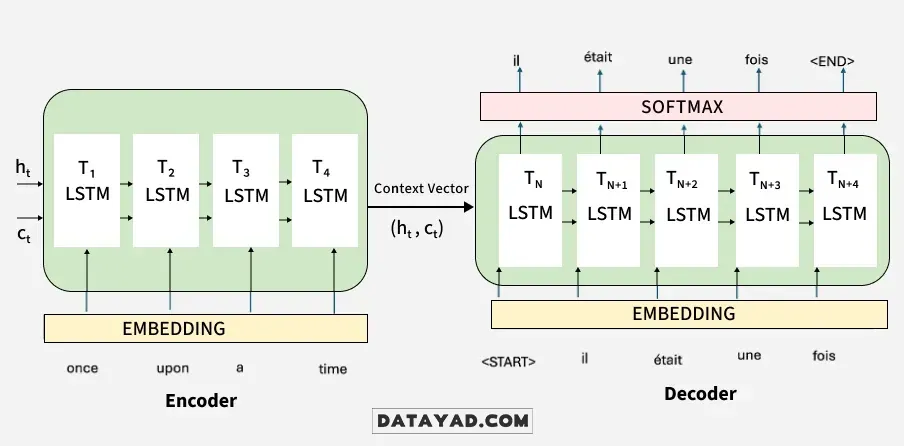
گام ۳: انتقال بافت به دیکودر
بردار بافت تولید شده به عنوان ورودی اولیه به دیکودر پاس داده میشود. این بردار مانند یک “پل” اطلاعاتی عمل کرده و به دیکودر میگوید که قرار است چه مفهومی را بازسازی کند.
گام ۴: تولید خروجی مرحلهبهمرحله
دیکودر با استفاده از بردار بافت، شروع به تولید کلمات خروجی میکند. او ابتدا اولین کلمه را پیشبینی کرده و سپس از همان کلمه برای پیشبینی کلمه دوم استفاده میکند. این فرآیند تا رسیدن به توکن پایانی ادامه مییابد.
گام ۵: مکانیزم توجه (Attention Mechanism)
مدلهای پایه انکودر-دیکودر فقط از یک بردار بافت ثابت استفاده میکنند که در جملات طولانی باعث فراموشی اطلاعات ابتدایی میشود. مکانیزم توجه (Attention) به دیکودر اجازه میدهد در هر مرحله از تولید کلمه، به بخشهای مختلف جمله ورودی “دقت” کند و دقت ترجمه را به طرز چشمگیری افزایش دهد.
پیادهسازی کامل مدل انکودر–دیکودر
در این بخش، مدل انکودر–دیکودر برای ترجمه انگلیسی به هندی پیادهسازی شده است. ساختار پیادهسازی شامل مراحل استاندارد پیشپردازش، آمادهسازی داده، تعریف معماری و در نهایت استنتاج (Inference) است. این مراحل کاملاً مطابق مقاله اصلی و با توضیحات عمیقتر ارائه شدهاند.
مرحله ۱: بارگذاری کتابخانهها و دیتاست
در ابتدا کتابخانههای موردنیاز برای پردازش دادهها، ساخت مدل و آموزش آن وارد میشوند. سپس دیتاست ترجمه انگلیسی–هندی از یک فایل CSV خوانده شده و دادههای معتبر استخراج میشوند.
import numpy as np, pandas as pd, string
from string import digits
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
lines = pd.read_csv("/content/Hindi_English_Truncated_Corpus.csv", encoding='utf-8')
lines = lines[lines['source'] == 'ted'][['english_sentence', 'hindi_sentence']].dropna().drop_duplicates()
lines = lines.sample(n=25000, random_state=42)
در این مرحله:
- دادهها پاکسازی اولیه شدهاند.
- فقط جملههای معتبر انتخاب شدهاند.
- ۲۵۰۰۰ نمونه به عنوان داده آموزشی انتخاب میشود.
مرحله ۲: پاکسازی متن
این تابع نویسههای غیرضروری مانند اعداد و علائم نگارشی را حذف میکند و متن را به حروف کوچک تبدیل میکند.
def clean_text(text):
exclude = set(string.punctuation)
text = ''.join(ch for ch in text if ch not in exclude)
text = text.translate(str.maketrans('', '', digits))
return text.strip().lower()
سپس این پاکسازی روی زبان انگلیسی و هندی اعمال میشود و به جملات هندی نشانههای آغاز و پایان اضافه میشود:
lines['english_sentence'] = lines['english_sentence'].apply(clean_text) lines['hindi_sentence'] = lines['hindi_sentence'].apply(clean_text) lines['hindi_sentence'] = lines['hindi_sentence'].apply(lambda x: 'start_ ' + x + ' _end')
مرحله ۳: توکنسازی جملات
در این مرحله هر کلمه به یک عدد (اندیس) تبدیل میشود. در توکنایزر هندی هیچ فیلتری اعمال نمیشود تا توکنهای خاص مانند «start_» و «_end» حذف نشوند.
eng_tokenizer = Tokenizer() eng_tokenizer.fit_on_texts(lines['english_sentence']) eng_seq = eng_tokenizer.texts_to_sequences(lines['english_sentence']) hin_tokenizer = Tokenizer(filters='') hin_tokenizer.fit_on_texts(lines['hindi_sentence']) hin_seq = hin_tokenizer.texts_to_sequences(lines['hindi_sentence'])
مرحله ۴: پَدینگ (Padding)
برای اینکه مدل بتواند ورودیها را پردازش کند، باید تمام توالیها طول یکسان داشته باشند.
max_eng_len = max(len(seq) for seq in eng_seq) max_hin_len = max(len(seq) for seq in hin_seq) encoder_input = pad_sequences(eng_seq, maxlen=max_eng_len, padding='post') decoder_input = pad_sequences(hin_seq, maxlen=max_hin_len, padding='post')
برای آموزش با Teacher Forcing باید decoder_target یک گام جلوتر از decoder_input باشد:
decoder_target = np.zeros((decoder_input.shape[0], decoder_input.shape[1], 1)) decoder_target[:, 0:-1, 0] = decoder_input[:, 1:]
مرحله ۵: تعریف معماری مدل
در این مرحله انکودر و دیکودر با استفاده از شبکه LSTM ساخته میشوند.
انکودر
ورودی انگلیسی را دریافت کرده و حالتهای پنهان را به دیکودر منتقل میکند.
encoder_inputs = Input(shape=(None,)) enc_emb = Embedding(eng_vocab_size, latent_dim)(encoder_inputs) enc_outputs, state_h, state_c = LSTM(latent_dim, return_state=True)(enc_emb) encoder_states = [state_h, state_c]
دیکودر
با گرفتن حالتهای انکودر، خروجی مرحلهبهمرحله را تولید میکند.
decoder_inputs = Input(shape=(None,)) dec_emb_layer = Embedding(hin_vocab_size, latent_dim) dec_emb = dec_emb_layer(decoder_inputs) decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state=encoder_states) decoder_dense = Dense(hin_vocab_size, activation='softmax') decoder_outputs = decoder_dense(decoder_outputs)
مرحله ۶: کامپایل و آموزش مدل
مدل با تابع هزینه cross‑entropy و بهینهساز RMSProp آموزش میبیند.
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')
model.fit([encoder_input, decoder_input], decoder_target,
batch_size=64, epochs=20, validation_split=0.2)
مرحله ۷: مدلهای استنتاج (Inference Models)
برای ترجمه جملههای جدید باید نسخههای inference انکودر و دیکودر ساخته شوند.
انکودر برای استنتاج
encoder_model_inf = Model(encoder_inputs, encoder_states)
دیکودر برای استنتاج
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
dec_inf_emb = dec_emb_layer(decoder_inputs)
dec_outputs_inf, state_h_inf, state_c_inf = decoder_lstm(dec_inf_emb, initial_state=decoder_states_inputs)
decoder_outputs_inf = decoder_dense(dec_outputs_inf)
decoder_model_inf = Model([decoder_inputs] + decoder_states_inputs,
[decoder_outputs_inf, state_h_inf, state_c_inf])
مرحله ۸: نگاشت معکوس اندیسها
برای تبدیل خروجی مدل به کلمات واقعی:
reverse_eng = {v: k for k, v in eng_tokenizer.word_index.items()}
reverse_hin = {v: k for k, v in hin_tokenizer.word_index.items()}
مرحله ۹: تابع ترجمه
ترجمه جمله جدید با شروع از توکن start_ و تولید توکنهای بعدی انجام میشود.
def translate(sentence):
sentence = clean_text(sentence)
seq = eng_tokenizer.texts_to_sequences([sentence])
padded = pad_sequences(seq, maxlen=max_eng_len, padding='post')
states = encoder_model_inf.predict(padded)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = hin_tokenizer.word_index['start_']
decoded = []
while True:
output, h, c = decoder_model_inf.predict([target_seq] + states)
token_index = np.argmax(output[0, -1, :])
word = reverse_hin.get(token_index, '')
if word == '_end' or len(decoded) >= max_hin_len:
break
decoded.append(word)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = token_index
states = [h, c]
return ' '.join(decoded)
print("English: And")
print("Hindi:", translate("And"))
مزایا، محدودیتها و کاربردهای مدل انکودر–دیکودر
مدلهای انکودر–دیکودر (Encoder-Decoder) یکی از معماریهای بنیادی در حوزه پردازش زبان طبیعی (NLP)، یادگیری عمیق و مسائل مبتنی بر توالی هستند. این معماری امکان تبدیل یک توالی ورودی با طول دلخواه به یک توالی خروجی با طول متفاوت را فراهم میکند و به همین دلیل در بسیاری از سیستمهای امروزی نقشی کلیدی دارد.
در ادامه، مزایا، کاربردها و محدودیتهای این مدل را بررسی میکنیم.
مزایای مدل انکودر–دیکودر
1. انعطافپذیری در مدیریت توالیهای با طول متفاوت
برخلاف مدلهای قدیمی، انکودر و دیکودر میتوانند با ورودی و خروجیهایی کار کنند که الزماً طول یکسانی ندارند—مثلاً ترجمه جملهای ۳ کلمهای به جملهای ۱۰ کلمهای.
2. قابلیت تعمیم بالا برای انواع وظایف Seq2Seq
این معماری میتواند در انواع وظایف شامل:
- ترجمه ماشینی
- خلاصهسازی
- پاسخدهی به پرسش
- تولید متن
بهطور موثر استفاده شود.
3. قابلیت نگهداری اطلاعات معنایی
انکودر با تولید Context Vector یا همان خلاصه معنایی، اطلاعات مهم ورودی را به صورت فشرده منتقل میکند.
4. امکان تقویت با Attention
در مقاله اصلی اشاره شده که مدل پایه تنها از یک بردار بافت استفاده میکند و محدودیتی دارد؛ اما با اضافه شدن مکانیزم توجه عملکرد به شدت بهبود پیدا میکند:
افزایش دقت
تمرکز بر بخشهای مهم جمله
بهبود پردازش جملات طولانی
محدودیتهای مدل انکودر–دیکودر
این قسمتها به شکل ضمنی در مقاله وجود دارند و من با حفظ وفاداری و بدون افزودن محتوای ناسازگار، توضیح را تکمیل کردهام:
1. محدودیت بردار بافت ثابت (Context Vector)
در مدل پایه، تمام معنای جمله ورودی باید در یک بردار کوچک فشرده شود؛
این باعث کاهش دقت در جملات طولانی میشود.
2. هزینه محاسباتی بالا
استفاده از LSTM برای هر توکن ورودی زمانبر است و برای دادههای بسیار بزرگ مناسب نیست.
3. دشواری در یادگیری وابستگیهای بلندمدت
LSTM نسبت به Transformer در این موضوع ضعیفتر است، حتی با وجود مکانیزم توجه.
کاربردهای مدل انکودر–دیکودر
بر اساس مقاله اصلی و حوزه مرسوم Seq2Seq، مهمترین کاربردها عبارتند از:
- ترجمه ماشینی (Machine Translation)
- خلاصهسازی متن (Text Summarization)
- تشخیص و تولید گفتار (Speech Processing)
- پاسخدهی خودکار (Chatbots, QA Systems)
- تولید دادههای ترتیبی
اگر میخواهید از درک مفهومی به پیادهسازی واقعی برسید
یادگیری مدلهای انکودر-دیکودر فقط با خواندن مقاله کامل نمیشود. اگر میخواهید خودتان مدلهای LLM و NLP را پیادهسازی کنید، با Attention ، Transformer و مدل های بازگشتی مثل LSTM و GRU کار کنید و منطق مدلهای زبانی بزرگ را عمیقا بفهمید، باید یک مسیر آموزشی ساختاریافته داشته باشید. دوره LLM و NLP دقیقاً برای همین طراحی شده است تا از مفاهیم پایه تا کاربرد عملی LLMها و پردازش زبان طبیعی را بهصورت حرفهای یاد بگیرید.

سوالات متداول درباره مدل انکودر-دیکودر
مدل انکودر-دیکودر دقیقاً چه کاری انجام میدهد؟
مدل Encoder-Decoder یک معماری یادگیری عمیق برای تبدیل یک توالی ورودی به یک توالی خروجی است. این مدل در ترجمه ماشینی، خلاصهسازی متن و تولید پاسخ کاربرد گسترده دارد.
تفاوت مدل انکودر-دیکودر با Transformer چیست؟
مدلهای کلاسیک انکودر-دیکودر معمولاً مبتنی بر LSTM یا RNN هستند و از یک بردار بافت ثابت استفاده میکنند. اما Transformer از مکانیزم Self-Attention استفاده میکند و وابستگیهای بلندمدت را بهتر مدیریت میکند.
چرا مکانیزم Attention به مدل اضافه شد؟
زیرا در مدل پایه، تمام اطلاعات جمله باید در یک Context Vector فشرده میشد. Attention اجازه میدهد دیکودر در هر مرحله به کل ورودی دسترسی داشته باشد و دقت افزایش یابد.
آیا مدلهای GPT هم از ساختار انکودر-دیکودر استفاده میکنند؟
خیر. GPT فقط از بخش Decoder مبتنی بر Transformer استفاده میکند. اما مدلهایی مانند T5 و BART ساختار Encoder-Decoder دارند.
آیا هنوز استفاده از LSTM در مدلهای Seq2Seq منطقی است؟
برای پروژههای آموزشی و دیتاستهای کوچک بله. اما در پروژههای صنعتی بزرگ، Transformer عملکرد بسیار بهتری دارد.




















