
دنیای هوش مصنوعی به سرعت در حال تغییر است. مدلهای زبانی بزرگ (LLM) امروزه تواناییهای شگفتانگیزی در تولید متن دارند، اما یک مشکل بزرگ دارند: آنها اغلب بر اساس دادههای آموزشی قدیمی خود پاسخ میدهند و ممکن است دچار توهم (Hallucination) شوند. تولید افزوده با بازیابی یا Retrieval-Augmented Generation (RAG)، که در این مطلب از بخش آموزش هوش مصنوعی به بررسی آن میپردازیم، راهکاری انقلابی برای حل این چالش است. RAG با ترکیب فرآیند جستجوی اطلاعات مرتبط و تولید پاسخ، هوش مصنوعی را بسیار دقیقتر و قابلاعتمادتر کرده است.
RAG چیست؟
Retrieval-Augmented Generation (RAG) روشی است که قابلیت پاسخگویی مدلهای هوش مصنوعی را با جستجو در منابع اطلاعاتی خارجی و ترکیب آن با تولید پاسخ، ارتقا میدهد. به جای اینکه مدل فقط بر اساس دادههای آموزشی قدیمی خود حدس بزند، ابتدا اطلاعات مفید را از منابع خارجی (مانند اسناد، پایگاههای داده یا دیتاسنترها) پیدا میکند و سپس از آن برای ارائه پاسخی دقیقتر بهره میبرد.
چرا RAG اهمیت دارد؟ (مزایای کلیدی):
- دسترسی به دادههای بهروز: اطلاعات جدید و لحظهای را بازیابی میکند و از پاسخهای غلط یا ساختگی میکاهد.
- عملکرد عالی در حوزههای تخصصی: برای دادههای حساس و تخصصی مانند متون پزشکی یا حقوقی بسیار ایدهآل است.
- عدم نیاز به آموزش مجدد: نیازی نیست مدل را هر بار که داده جدیدی اضافه میشود، دوباره آموزش (Retrain) دهید.
- شخصیسازی: میتواند از دادههای خاص هر کاربر برای ارائه پاسخهای مرتبطتر استفاده کند.
مثال کاربردی:
پلتفرمی را در نظر بگیرید که مجموعهای عظیم از مقالات برنامهنویسی دارد. اگر کاربر سوالی بپرسد، سیستم مبتنی بر RAG به جای ارائه یک پاسخ کلی و سطحی، اینگونه عمل میکند:
- مقالات مرتبط را از دیتابیس خود جستجو میکند.
- مفیدترین محتوا را انتخاب میکند.
- بر اساس آن اطلاعات دقیق، پاسخی سفارشی و کاربردی تولید میکند.
- نتیجه این فرآیند، پاسخهایی است که کاملاً با محتوای پلتفرم همراستا بوده و برای کاربر واقعاً راهگشا است.
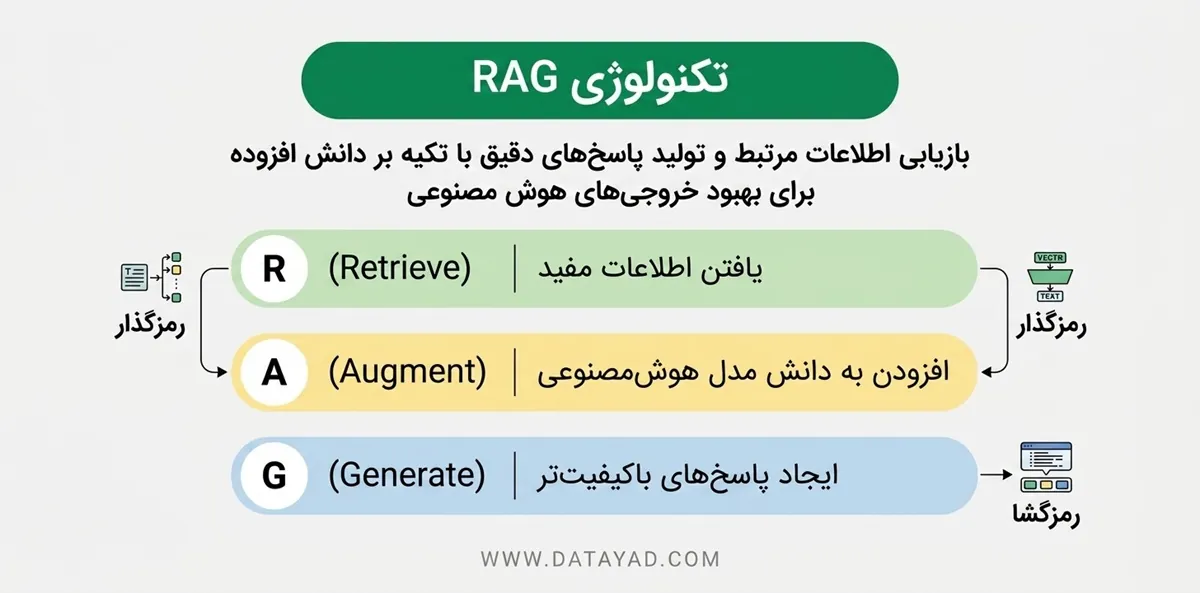
اجزای RAG
اجزای اصلی RAG شامل موارد زیر هستند:
- منبع دانش خارجی: محلی برای ذخیرهسازی اطلاعات عمومی یا تخصصی مانند اسناد، APIها یا پایگاههای داده.
- تکهتکهسازی و پیشپردازش متن (Text Chunking and Preprocessing): متون بزرگ را به بخشهای کوچکتر و قابل مدیریت تبدیل میکند و دادهها را برای یکپارچگی بیشتر پاکسازی میکند.
- مدل امبدینگ (Embedding Model): متن را به بردارهای عددی تبدیل میکند که معنای آن را بهصورت مفهومی نشان میدهند.
- پایگاه داده برداری (Vector Database): امبدینگها را ذخیره کرده و امکان جستجوی شباهت را برای بازیابی سریع اطلاعات فراهم میکند.
- رمزگذار پرسوجو (Query Encoder): پرسش کاربر را به یک بردار تبدیل میکند تا بتوان آن را با امبدینگهای ذخیرهشده مقایسه کرد.
- بازیاب (Retriever): مرتبطترین بخشها را براساس شباهت با پرسش کاربر پیدا کرده و بازمیگرداند.
- لایه تقویت پرامپت: بخشهای بازیابیشده را با پرسش کاربر ترکیب میکند تا زمینه لازم را به مدل زبانی ارائه دهد.
- مدل زبانی: با استفاده از پرسش کاربر و دانش بازیابیشده، پاسخی دقیق و مبتنی بر داده تولید میکند.
- بروزرسان: بهطور دورهای دادهها و امبدینگها را تازهسازی میکند تا پایگاه دانش همیشه بهروز بماند.
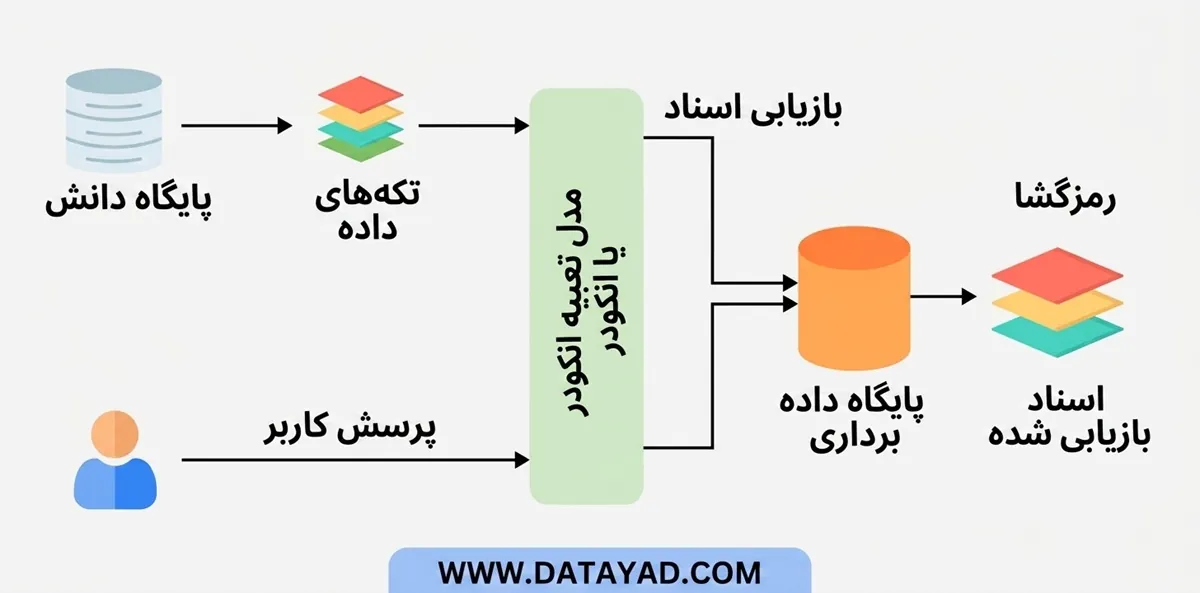
نحوه عملکرد RAG
سیستم RAG برای پاسخگویی، به جای تکیه صرف بر دادههای آموزشی ایستا، فرآیندی پویا را دنبال میکند. در این سیستم، ابتدا اطلاعات مرتبط از منابع خارجی بر اساس پرسوجوی کاربر استخراج شده و سپس پردازش نهایی انجام میشود.
مراحل عملیاتی در RAG:
- ایجاد دادههای خارجی (Creating External Data): ابتدا دادههای خام از منابع مختلف (مانند APIها، پایگاههای داده یا اسناد متنی) جمعآوری میشوند. این دادهها «تکهتکهسازی» (Chunking) شده، به بردار تبدیل میشوند و در نهایت در یک «پایگاه داده برداری» (Vector Database) ذخیره میگردند تا یک کتابخانه دانش منسجم تشکیل شود.
- بازیابی اطلاعات مرتبط (Retrieving Relevant Information): هنگامی که کاربر پرسشی را مطرح میکند، آن پرسش به بردار تبدیل میشود. سپس سیستم با جستجوی شباهت در پایگاه داده برداری، مرتبطترین قطعات اطلاعاتی را پیدا کرده و استخراج میکند تا دقت پاسخ افزایش یابد.
- تقویت پرامپت (Augmenting the LLM Prompt): در این مرحله، محتوای بازیابی شده مستقیماً به پرسش اصلی کاربر اضافه میشود. این کار باعث میشود مدل زبانی (LLM) به زمینهی (Context) غنیتری دسترسی داشته باشد و بتواند پاسخی دقیقتر تولید کند.
- تولید پاسخ (Answer Generation): مدل زبانی با ترکیب پرسش کاربر و دانش بازیابیشده، پاسخی تولید میکند که هم از نظر محتوایی دقیق است و هم با واقعیتهای موجود در پایگاه دانش همخوانی دارد.
- بروزرسانی دادهها (Keeping Data Updated): از آنجایی که اطلاعات همواره در حال تغییر هستند، سیستم بهصورت دورهای یا در لحظه (Real-time)، دادهها و بردارهای ذخیرهشده را تازهسازی میکند تا خروجیهای سیستم همیشه بر اساس آخرین اطلاعات موجود باشد.
RAG چه مشکلاتی را حل میکند؟
- توهم (Hallucinations): مدلهای مولد سنتی ممکن است اطلاعات نادرست تولید کنند. RAG این ریسک را با بازیابی دادههای تأییدشده و خارجی کاهش میدهد و پاسخها را بر دانش واقعی و مستند استوار میکند.
- اطلاعات قدیمی (Outdated Information): مدلهای ایستا به دادههای آموزشی وابسته هستند که ممکن است بهمرور زمان قدیمی شوند. RAG بهصورت پویا جدیدترین اطلاعات را بازیابی میکند و از این طریق ارتباط و دقت پاسخها را در زمان واقعی تضمین میکند.
- ارتباط زمینهای (Contextual Relevance): مدلهای مولد اغلب در حفظ زمینه در مکالمات پیچیده یا چندمرحلهای دچار مشکل میشوند. RAG با بازیابی اسناد مرتبط، زمینه را غنیتر میکند و انسجام و ارتباط پاسخها را بهبود میبخشد.
- دانش تخصصی حوزهای (Domain Specific Knowledge): مدلهای عمومی ممکن است در حوزههای تخصصی دانش کافی نداشته باشند. RAG با یکپارچهسازی دانش خارجیِ تخصصی، پاسخهایی دقیقتر و متناسب با حوزه ارائه میدهد.
- هزینه و کارایی (Cost and Efficiency): فاینتیون (Fine-tuning) مدلهای بزرگ برای وظایف خاص هزینهبر است. RAG با بازیابی پویا و استفاده از دادههای مرتبط، نیاز به آموزش مجدد را حذف کرده و هزینهها و بار محاسباتی را کاهش میدهد.
- مقیاسپذیری در حوزههای مختلف (Scalability Across Domains): RAG در صنایع متنوع از سلامت تا امور مالی قابل استفاده است، بدون اینکه نیاز به آموزش مجدد گسترده داشته باشد؛ بنابراین راهکاری بسیار مقیاسپذیر محسوب میشود.
چالشهای RAG
- پیچیدگی (Complexity): ترکیب فرآیند بازیابی (Retrieval) و تولید (Generation) باعث افزایش پیچیدگی مدل میشود و نیازمند تنظیم دقیق (Tuning) و بهینهسازی است تا اطمینان حاصل شود هر دو مؤلفه بهصورت یکپارچه و هماهنگ با یکدیگر عمل میکنند.
- تأخیر (Latency): مرحله بازیابی میتواند باعث ایجاد تأخیر شود و همین موضوع، استقرار مدلهای RAG را در کاربردهای بلادرنگ (Real-time Applications) چالشبرانگیز میکند.
- کیفیت بازیابی (Quality of Retrieval): عملکرد کلی سیستم بهشدت به کیفیت اسناد بازیابیشده وابسته است. اگر فرآیند بازیابی ضعیف باشد، مرحله تولید نیز بهینه نخواهد بود و در نتیجه اثربخشی مدل کاهش مییابد.
- سوگیری و عدالت (Bias and Fairness): RAG میتواند سوگیریهای موجود در دادههای آموزشی یا اسناد بازیابیشده را به ارث ببرد؛ بنابراین نیازمند نظارت و تلاش مداوم برای تضمین عدالت و کاهش سوگیریها است.
کاربردهای RAG
تکنولوژی تولید افزوده با بازیابی یا همان RAG، به دلیل انعطافپذیری و دقت بالایی که دارد، در صنایع و ابزارهای مختلفی کاربرد پیدا کرده است. این تکنولوژی فراتر از یک جستجوی ساده عمل کرده و اطلاعات را به صورت هوشمندانه استخراج و پردازش میکند. در ادامه به بررسی مهمترین کاربردهای آن میپردازیم:
سیستمهای پرسش و پاسخ (Question-Answering Systems):
این یکی از اصلیترین کاربردهای RAG است. چتباتهای هوش مصنوعی و دستیارهای مجازی با استفاده از RAG میتوانند به جای تکیه بر حافظه محدود خود، از پایگاههای دانش (Knowledge Base) یا اسناد داخلی سازمانها اطلاعات دقیق استخراج کنند. این کار باعث میشود پاسخهایی که به کاربر ارائه میشود، کاملاً مستند، دقیق و متناسب با زمینه (Context) سوال باشد.
تولید محتوا و خلاصهسازی (Content Creation and Summarization):
RAG توانایی این را دارد که اطلاعات را از چندین منبع مختلف و پراکنده جمعآوری کند. سپس با تحلیل این دادهها، مقالات، گزارشها و خلاصههایی دقیق، ساده و منسجم تولید کند که همگی بر اساس واقعیتهای استخراجشده هستند.
عوامل مکالمهای و چتباتها (Conversational Agents and Chatbots):
استفاده از RAG در چتباتها باعث میشود پاسخها «زمینهمند» (Grounded) شوند. یعنی پاسخها بر اساس دادههای قابل اعتماد بنا میشوند که این امر تعاملات را برای کاربران بسیار آموزندهتر، شخصیسازیشدهتر و قابلاعتمادتر میکند.
بازیابی اطلاعات (Information Retrieval):
RAG فراتر از موتورهای جستجوی سنتی عمل میکند. این سیستم نه تنها اسناد مرتبط را بازیابی میکند، بلکه با تولید خلاصههای معنایی (Meaningful Summaries) از محتوای آن اسناد، به کاربر کمک میکند تا در سریعترین زمان ممکن به هسته اصلی اطلاعات دسترسی پیدا کند.
ابزارها و منابع آموزشی (Educational Tools and Resources):
در حوزهی آموزش، RAG میتواند نقش یک معلم خصوصی هوشمند را بازی کند. این سیستم قادر است برای دانشآموزان و دانشجویان، توضیحات، نمودارها یا منابع چندرسانهای مرتبط با پرسشهای درسی آنها را ارائه دهد و فرآیند یادگیری را شخصیسازی کند.
یادگیری RAG در کنار LLM و NLP
اگر به دنیای مدلهای زبانی علاقه دارید، یادگیری مفاهیمی مثل RAG تنها بخشی از مسیر ساخت سیستمهای هوش مصنوعی پیشرفته است. برای طراحی و پیادهسازی ابزارهای واقعی مبتنی بر هوش مصنوعی، لازم است با مفاهیمی مانند مدلهای زبانی بزرگ (LLM)، پردازش زبان طبیعی (NLP)، Embeddingها، Vector Database، طراحی سیستمهای RAG و ساخت چتباتهای هوشمند آشنا باشید.
اگر میخواهید این مهارتها را بهصورت عملی یاد بگیرید و بتوانید سیستمهای واقعی مبتنی بر مدلهای زبانی بسازید، در دوره LLM و NLP علاوه بر مفاهیم پایه، تمام مباحث موردنیاز برای کار با مدلهای زبانی و پردازش زبان طبیعی از جمله پیادهسازی کامل سیستمهای RAG نیز آموزش داده میشود. در این دوره یاد میگیرید چگونه از LLMها در پروژههای واقعی استفاده کنید، دادهها را به شکل برداری پردازش کنید، پایگاه دادههای برداری بسازید و سیستمهای هوشمند مبتنی بر RAG طراحی کنید. برای مشاهده جزئیات و سرفصلها میتوانید صفحه دوره LLM و NLP را ببینید

سوالات متداول درباره RAG
RAG در هوش مصنوعی چیست؟
RAG یا Retrieval-Augmented Generation روشی برای بهبود عملکرد مدلهای زبانی است که در آن مدل قبل از تولید پاسخ، اطلاعات مرتبط را از منابع خارجی مانند پایگاههای داده، اسناد یا APIها بازیابی میکند و سپس با استفاده از آنها پاسخ دقیقتری تولید میکند.
تفاوت RAG با Fine-tuning چیست؟
در Fine-tuning مدل زبانی با دادههای جدید دوباره آموزش داده میشود، اما در RAG نیازی به آموزش مجدد مدل نیست. در عوض، اطلاعات از یک پایگاه دانش خارجی بازیابی شده و به عنوان context به مدل داده میشود.
آیا RAG میتواند مشکل Hallucination را حل کند؟
RAG میتواند احتمال توهم یا Hallucination در مدلهای زبانی را کاهش دهد، زیرا پاسخها بر اساس اطلاعات واقعی بازیابیشده از منابع معتبر تولید میشوند.
برای پیادهسازی RAG به چه ابزارهایی نیاز است؟
معمولاً برای ساخت سیستم RAG از ابزارهایی مانند مدلهای Embedding، پایگاه داده برداری (Vector Database)، سیستمهای Retrieval و یک مدل زبانی بزرگ (LLM) استفاده میشود.
آیا RAG فقط برای چتباتها استفاده میشود؟
خیر. علاوه بر چتباتها، RAG در سیستمهای پرسش و پاسخ، موتورهای جستجوی هوشمند، تولید محتوا، خلاصهسازی اسناد و سیستمهای آموزشی نیز کاربرد دارد.




















