

توزیع آماری دادهها (Statistical Data Distribution) تابعی است که مقادیر ممکن برای یک متغیر و میزان تکرار (فرکانس) وقوع آنها را نشان میدهد. این مفهوم، توصیفی ریاضی از رفتار دادهها ارائه کرده و به ما کمک میکند تا درک کنیم بیشتر نقاط داده در کجا متمرکز شدهاند و چگونه در بازههای مختلف پراکندگی دارند.
توزیعها بسته به نوع دادهها به شکلهای متفاوتی محاسبه و نمایش داده میشوند. برای مثال، در دادههای پیوسته از تابع چگالی احتمال (PDF) و در دادههای گسسته از تابع جرم احتمال (PMF) استفاده میشود.
چند تابع کلیدی که برای توصیف و تحلیل توزیع دادهها به کار میروند عبارتاند از:
- تابع احتمال (Probability Function): این تابع برای تخصیص احتمال به نتایج مختلف و ممکن در یک مجموعه داده استفاده میشود.
- تابع چگالی احتمال (Probability Density Function یا PDF): این تابع ویژه متغیرهای پیوسته است. از آنجا که در دادههای پیوسته محاسبه احتمال برای یک مقدار دقیق و نقطهای منطقی نیست، تابع PDF احتمال قرار گرفتن یک متغیر در یک بازه مشخص را نشان میدهد.
- تابع توزیع تجمعی (Cumulative Distribution Function یا CDF): این تابع نشاندهنده احتمال این است که یک متغیر، مقداری کمتر یا مساوی با یک عدد مشخص به خود بگیرد و برای درک روند کلی دادهها بسیار کاربردی است.
همچنین، میتوان توزیعهای آماری را بر اساس ویژگیهایشان به دو دسته کلی پیوسته و گسسته طبقهبندی کرد (مانند توزیع نرمال، دوجملهای، پواسون و غیره). درک عمیق این توابع و مفاهیم پایه آماری، خشت اول در تحلیل دادهها و ساخت مدلهای دقیق یادگیری ماشین است. برای یادگیری اصولی این مفاهیم و تسلط بر پیادهسازی عملی آنها برای تحلیل مجموعهدادههای واقعی، استفاده از آموزش یادگیری ماشین و علم داده، مسیر کامل و استانداردی را پیش روی شما قرار میدهد.
توزیع آماری دادهها چیست و چرا اهمیت دارد؟
در تحلیل دادهها، یکی از اولین سوالها این است که دادهها چگونه در یک مجموعه پخش شدهاند. آیا بیشتر دادهها نزدیک یک مقدار خاص قرار دارند؟ آیا دادهها پراکندگی زیادی دارند؟
توزیع آماری دادهها ابزاری است که به ما کمک میکند شکل کلی دادهها را درک کنیم. با استفاده از توزیعها میتوان فهمید دادهها در چه بازههایی متمرکز هستند، چه مقدار پراکندگی دارند و احتمال وقوع مقادیر مختلف چقدر است. در بسیاری از روشهای آماری و الگوریتمهای یادگیری ماشین، شناخت توزیع دادهها اولین قدم برای تحلیل درست دادهها محسوب میشود.
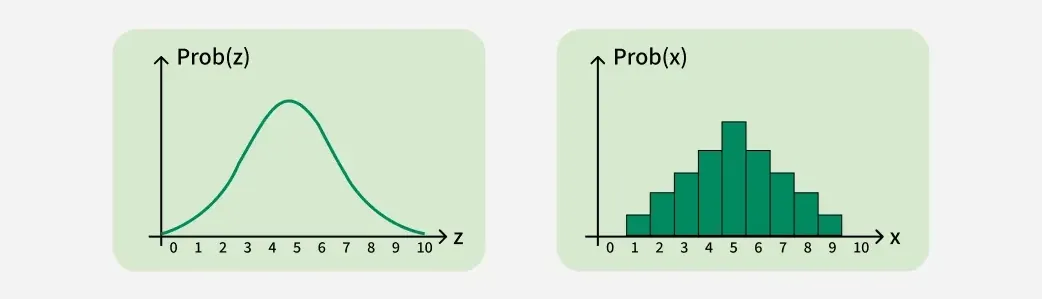
انواع توزیع آماری دادهها
توزیع آماری دادهها را میتوان به دو دسته اصلی تقسیم کرد:
توزیعهای گسسته (Discrete Distributions)
- توزیع گسسته زمانی استفاده میشود که دادهها فقط بتوانند مقادیر جداگانه و مشخصی بگیرند.
- این مقادیر قابل شمارش هستند مانند 1، 2، 3 و به همین ترتیب ادامه دارند. در این نوع دادهها مقادیر بینابینی مانند 1.5 یا 2.7 وجود ندارند.
- برای مثال، تعداد کتابهای موجود در یک قفسه یا تعداد دانشآموزان در یک کلاس از نوع دادههای گسسته محسوب میشوند.
- برخی از انواع رایج توزیعهای گسسته شامل توزیع دوجملهای (Binomial Distribution)، توزیع پواسون (Poisson Distribution) و موارد مشابه هستند.
توزیعهای پیوسته (Continuous Distributions)
- توزیع پیوسته زمانی استفاده میشود که دادهها بتوانند هر مقداری را در یک بازه مشخص بگیرند، از جمله اعداد اعشاری و کسری.
- این نوع توزیع برای مقادیری به کار میرود که قابل اندازهگیری هستند مانند قد، وزن، دما یا زمان.
- برای مثال، قد یک فرد میتواند 165.3 سانتیمتر باشد یا زمان پایان یک مسابقه ممکن است 12.75 ثانیه باشد.
- از انواع رایج توزیعهای پیوسته میتوان به توزیع نرمال (Normal Distribution)، توزیع نمایی (Exponential Distribution) و موارد دیگر اشاره کرد.
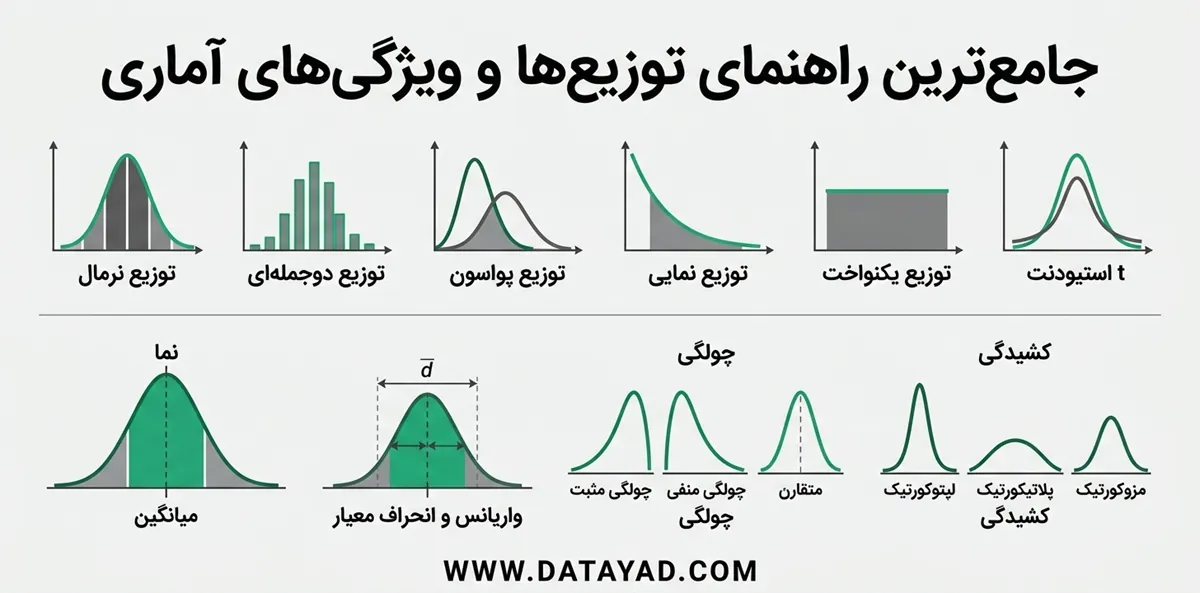
توزیع های آماری متداول
در این بخش، رایجترین انواع توزیعهای آماری معرفی شدهاند؛ توزیعهایی که در علم داده، آمار، مدلسازی، تحلیل داده و یادگیری ماشین کاربرد گسترده دارند. نمایش این توزیع ها با عنوان مصور سازی داده ها شناخته میشود.
1. توزیع آماری نرمال (Normal Distribution)
- توزیع نرمال یکی از رایجترین و مهمترین توزیعهای آماری است که شکل زنگولهای و کاملاً متقارن دارد.
- در این توزیع، بیشترین تعداد نقاط داده به مقدار میانگین نزدیک هستند و هرچه از میانگین دورتر شویم، تعداد دادهها کاهش مییابد.
- برای مثال، اگر قد افراد را بررسی کنیم، معمولاً اکثر افراد در نزدیکی یک قد متوسط قرار میگیرند و تعداد افراد بسیار کوتاه یا بسیار بلند کمتر است.
2. توزیع آماری دوجملهای (Binomial Distribution)
- توزیع دوجملهای زمانی استفاده میشود که یک عمل چندین بار تکرار شود و هر بار فقط دو نتیجه ممکن داشته باشد: موفقیت یا شکست.
- برای مثال، اگر یک سکه را 10 بار پرتاب کنید و بخواهید بدانید چند بار احتمال دارد رو بیاید، توزیع دوجملهای برای محاسبه این احتمال استفاده میشود.
- این توزیع احتمال رخ دادن تعداد مشخصی از موفقیتها (مثل رو آمدن سکه) را در تعداد آزمایشهای ثابت محاسبه میکند.
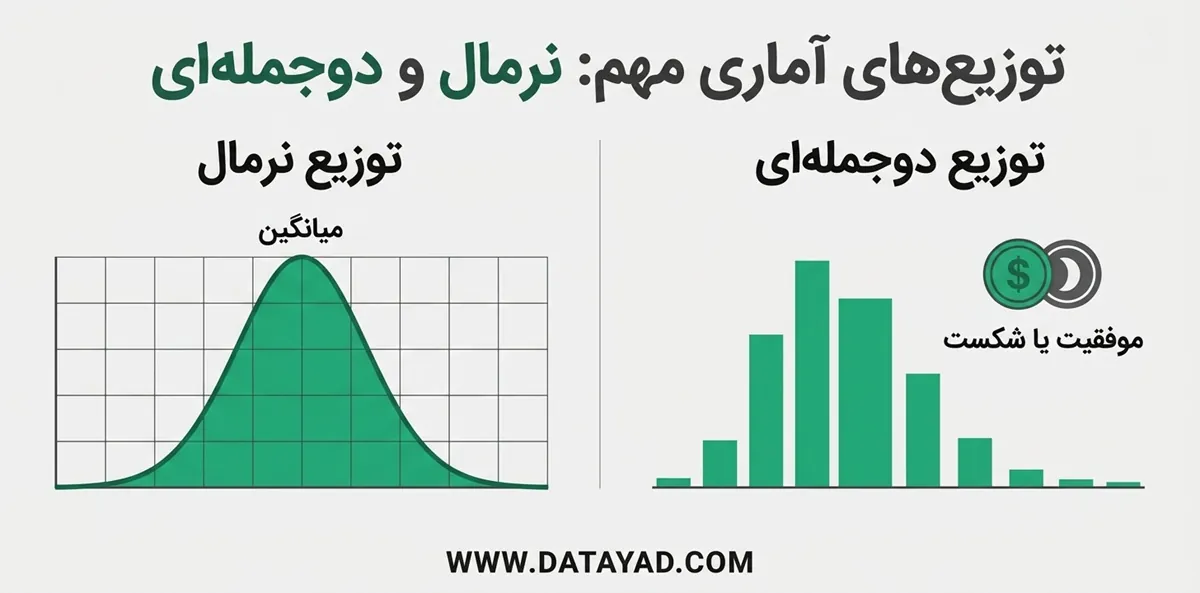
3. توزیع آماری پواسون (Poisson Distribution)
توزیع پواسون برای مدلسازی رخدادهایی استفاده میشود که بهصورت تصادفی در یک بازهی زمانی یا مکانی اتفاق میافتند.
مثالهای رایج:
- تعداد خودروهایی که در یک ساعت از یک عوارضی عبور میکنند
- تعداد ایمیلهایی که در یک روز دریافت میکنید
- این رویدادها معمولاً در فواصل منظم رخ نمیدهند. توزیع پواسون زمانی کاربرد دارد که رخدادها مستقل باشند و با یک نرخ میانگین ثابت اتفاق بیفتند.
4. توزیع آماری نمایی (Exponential Distribution)
توزیع نمایی ارتباط نزدیکی با توزیع پواسون دارد. اما بهجای شمارش تعداد رویدادها، زمان بین وقوع رویدادها را مدلسازی میکند.
مثال: اگر منتظر آمدن اتوبوس باشید، توزیع نمایی میتواند کمک کند تخمین بزنید تا رسیدن اتوبوس بعدی چقدر زمان باقی مانده است.
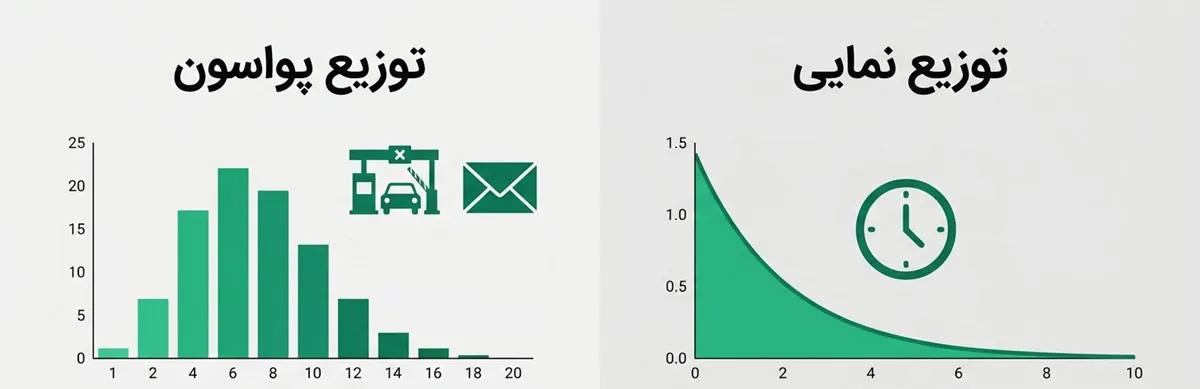
5. توزیع آماری یکنواخت (Uniform Distribution)
در توزیع یکنواخت، همه نتایج احتمال یکسان دارند.
مثال: در یک تاس سالم 6 وجهی، احتمال آمدن هر عدد از 1 تا 6 برابر است.
6. توزیع آماری t استیودنت (Student’s t-Distribution)
توزیع t شباهت زیادی به توزیع نرمال دارد اما دُمهای سنگینتر دارد؛ یعنی احتمال وقوع مقادیر دور از میانگین بیشتر است. این توزیع هنگام کار با نمونههای کوچک بسیار کاربردی است، مخصوصاً هنگامی که انحراف معیار جامعه نامشخص باشد. پژوهشگران در چنین شرایطی معمولاً از توزیع t برای برآورد میانگین استفاده میکنند.
ویژگیهای توزیع آماری دادهها
در آمار، هر توزیع داده دارای ویژگیهایی است که به ما کمک میکند شکل، مرکز و میزان پراکندگی دادهها را بهتر درک کنیم. این ویژگیها برای تحلیل دادهها بسیار مهم هستند و در بسیاری از کاربردها مانند تحلیل اکتشافی دادهها (EDA)، ساخت مدلهای یادگیری ماشین و سایر تحلیلهای آماری استفاده میشوند.
1. میانگین (Mean – μ)
میانگین در واقع متوسط تمام نقاط داده در یک توزیع است.
این مقدار به ما کمک میکند نقطه مرکزی دادهها را پیدا کنیم؛ یعنی جایی که دادهها معمولاً در اطراف آن تجمع دارند.
به بیان ساده، میانگین نشان میدهد که یک مقدار معمولی یا نماینده برای دادهها چه مقداری است.
2. واریانس (Variance – σ²) و انحراف معیار (Standard Deviation – σ)
این دو معیار نشان میدهند که نقاط داده تا چه اندازه در اطراف میانگین پراکنده شدهاند.
- واریانس (Variance): واریانس میانگین مربع اختلاف هر داده با میانگین را محاسبه میکند. این مقدار نشان میدهد که دادهها چقدر از مقدار متوسط فاصله دارند.
- انحراف معیار (Standard Deviation): انحراف معیار در واقع ریشه دوم واریانس است. این معیار درک شهودیتری از میزان پراکندگی دادهها ارائه میدهد، زیرا در همان مقیاس دادههای اصلی بیان میشود.
3. چولگی (Skewness)
چولگی معیاری است که میزان تقارن یا عدم تقارن یک توزیع را اندازهگیری میکند.
- اگر دنباله (Tail) توزیع در سمت راست بلندتر باشد، توزیع چولگی مثبت (Positively Skewed) دارد.
- اگر دنباله توزیع در سمت چپ بلندتر باشد، توزیع چولگی منفی (Negatively Skewed) نامیده میشود.
4. کشیدگی (Kurtosis)
کشیدگی به میزان سنگینی دنبالههای توزیع اشاره دارد و نشان میدهد چه مقدار از دادهها در دنبالهها نسبت به مرکز توزیع قرار دارند.
انواع کشیدگی عبارتاند از:
- Leptokurtic: توزیعهایی با دنبالههای سنگین
- Platykurtic: توزیعهایی با دنبالههای سبک
- Mesokurtic: توزیعهایی با دنبالههایی مشابه توزیع نرمال
5. نما (Mode)
Mode مقداری است که بیشترین تکرار را در یک مجموعه داده دارد.
این مقدار نشان میدهد که دادهها بیشتر در چه نقطهای متمرکز شدهاند و در واقع قله (Peak) توزیع را نشان میدهد.
درک این ویژگیها در کنار شناخت انواع توزیعهای آماری به ما کمک میکند دادهها را بهتر تحلیل کنیم. این مفاهیم در تحلیل داده، تحلیل اکتشافی دادهها (EDA)، ساخت مدلهای یادگیری ماشین و بسیاری از کاربردهای آماری دیگر بسیار مفید هستند.
برای یادگیری عملی توزیع آماری دادهها چه مهارتهایی لازم است؟
اگر قصد دارید توزیع آماری دادهها را فقط در حد تئوری ندانید و بتوانید آنها را در تحلیل داده و پروژههای واقعی استفاده کنید، باید چند مهارت کلیدی را یاد بگیرید:
- آمار و احتمال کاربردی در علم داده
- تحلیل اکتشافی دادهها (EDA)
- کار با پایتون و کتابخانههایی مانند NumPy، Pandas و SciPy
- درک توزیع دادهها در مدلهای یادگیری ماشین
یادگیری این مفاهیم بهصورت پراکنده معمولاً زمانبر است. اگر میخواهید مسیر یادگیری آمار، تحلیل داده و مدلسازی را به شکل ساختارمند یاد بگیرید، دوره جامع آموزش یادگیری ماشین و علم داده میتواند نقطه شروع مناسبی باشد و شما را از مفاهیم پایه تا پیادهسازی عملی مدلها هدایت کند.




















