
بازشناسی موجودیتهای نامدار (NER)، که در این مطلب از بخش آموزش هوش مصنوعی به بررسی آن میپردازیم، در پردازش زبان طبیعی (NLP) بر شناسایی و دستهبندی اطلاعات مهمی که به عنوان موجودیت (Entity) شناخته میشوند، تمرکز دارد. این موجودیتها میتوانند نام افراد، مکانها، سازمانها، تاریخها و غیره باشند. NER به تبدیل متن بدون ساختار به اطلاعات ساختاریافته کمک میکند که در وظایفی مانند خلاصهسازی متن، ایجاد گراف دانش و پاسخگویی به سوالات مفید است.
بازشناسی موجودیتهای نامدار (NER) چیست و چرا در NLP اهمیت دارد؟
در بسیاری از کاربردهای پردازش زبان طبیعی، هدف این است که از دل متنهای طولانی و بدون ساختار، اطلاعات مهم استخراج شود. برای مثال اگر یک خبر، مقاله یا پست شبکه اجتماعی را بررسی کنیم، ممکن است بخواهیم بدانیم چه افرادی در آن ذکر شدهاند، چه سازمانهایی درگیر هستند یا درباره چه مکانهایی صحبت شده است. اینجاست که بازشناسی موجودیتهای نامدار (Named Entity Recognition یا NER) وارد عمل میشود.
NER در پردازش زبان طبیعی یکی از مهمترین تکنیکها است که به مدلهای هوش مصنوعی کمک میکند تا موجودیتهای مهم مانند نام افراد، سازمانها، مکانها، تاریخها و مقادیر عددی را از متن استخراج و دستهبندی کنند. این قابلیت در سیستمهایی مانند موتورهای جستجو، چتباتها، تحلیل اخبار، سیستمهای پاسخ به سوال و ساخت گراف دانش کاربرد گستردهای دارد.
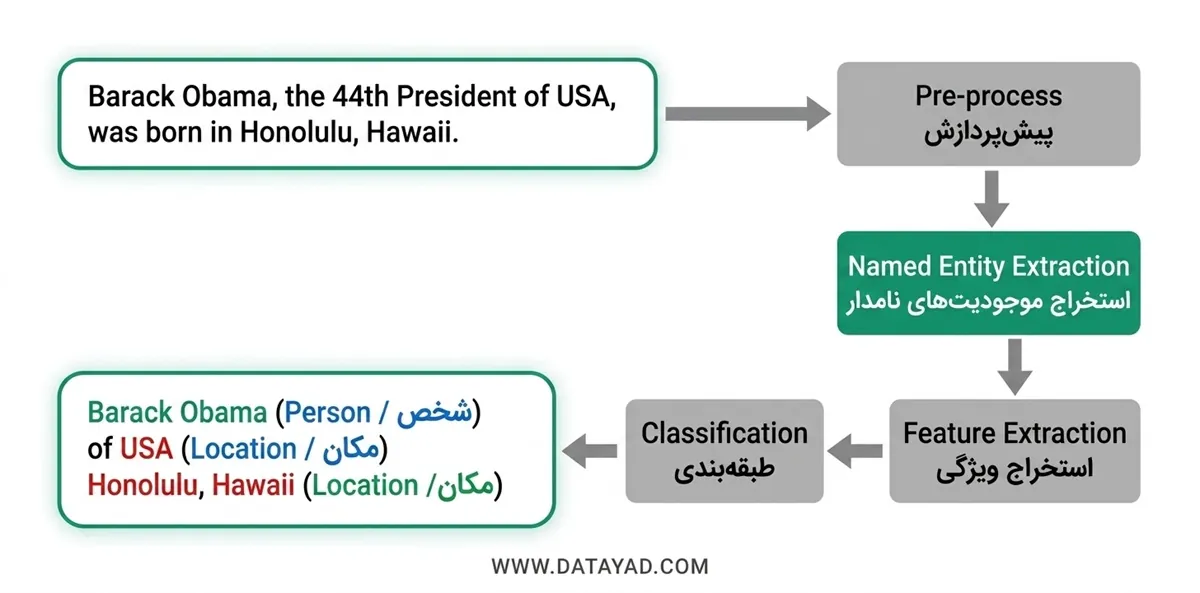
نحوه عملکرد NER در پردازش زبان طبیعی
NER در پردازش زبان طبیعی به شناسایی اطلاعات خاص و دستهبندی آنها در گروههای از پیش تعریف شده کمک میکند. این فرآیند نقش مهمی در بهبود سایر وظایف NLP مانند برچسبگذاری نقش کلمات و تجزیه دستوری ایفا میکند. نمونههایی از انواع موجودیتهای رایج:
- نام افراد: Albert Einstein
- سازمانها: GeeksforGeeks
- مکانها: Paris
- تاریخها و زمانها: 5th May 2025
- مقادیر و درصدها: 50%, $100
NER با تحلیل کلمات پیرامون، ساختار جمله و بافت کلی متن برای انجام طبقهبندی صحیح، به رفع ابهام کمک میکند. این بدان معناست که دستهبندی یک موجودیت میتواند بسته به معنای آن در متن تغییر کند.
مثال ۱:
- آمازون در حال گسترش سریع کسبوکار خود است. (سازمان)
- آمازون بزرگترین جنگل بارانی جهان است. (مکان)
مثال ۲:
- ایران خانم زن موفقی است. (شخص)
- ایران قدرتمندترین کشور خاورمیانه است. (مکان)
نحوه عملکرد بازشناسی موجودیتهای نامدار (NER)
مراحل مختلفی در NER دخیل هستند که به شرح زیر میباشند:
- تحلیل متن: تمام متن را برای یافتن کلمات یا عباراتی که میتوانند نماینده موجودیتها باشند، پردازش میکند.
- یافتن مرزهای جمله: با استفاده از علائم نگارشی و حروف بزرگ، ابتدا و انتهای جملات را شناسایی میکند که به حفظ معنا و بافت موجودیتها کمک میکند.
- توکنبندی و برچسبگذاری نقش کلمات: متن به توکنها (کلمات) تقسیم میشود و هر توکن با نقش دستوری خود برچسبگذاری میشود که سرنخهای مهمی برای شناسایی موجودیتها فراهم میکند.
- تشخیص و طبقهبندی موجودیتها: توکنها یا گروههایی از توکنها که با الگوهای موجودیتهای شناختهشده مطابقت دارند، شناسایی شده و در دستههای از پیش تعریف شده مانند شخص، سازمان، مکان و غیره طبقهبندی میشوند.
- آموزش و بهبود مدل: مدلهای یادگیری ماشین با استفاده از مجموعهدادههای برچسبگذاری شده آموزش میبینند و با گذشت زمان، با یادگیری الگوها و روابط بین کلمات بهبود مییابند.
- انطباق با بافتهای جدید: یک مدل به خوبی آموزشدیده میتواند با یادگیری از بافت متن، به زبانها، سبکها و انواع دیدهنشدهای از موجودیتها تعمیم یابد.
روشهای بازشناسی موجودیتهای نامدار (NER)
روشهای مختلفی در NER وجود دارند که عبارتند از:
1. روش مبتنی بر واژهنامه (Lexicon Based Method)
این روش از یک لغتنامه از نامهای موجودیتهای شناختهشده استفاده میکند. این فرآیند شامل بررسی حضور هر یک از این کلمات در یک متن مشخص است. با این حال، این رویکرد معمولاً مورد استفاده قرار نمیگیرد، زیرا برای حفظ دقت و کارایی، نیازمند بهروزرسانی مداوم و نگهداری دقیق واژهنامه است.
2. روش مبتنی بر قانون (Rule Based Method)
این روش از مجموعهای از قوانین از پیش تعریف شده استفاده میکند که به استخراج اطلاعات کمک میکنند. این قوانین بر اساس الگوها و بافت متن (Context) هستند. قوانین مبتنی بر الگو بر ساختار و شکل کلمات تمرکز دارند و به بررسی الگوهای صرفی (Morphological) آنها کمک میکنند. از سوی دیگر، قوانین مبتنی بر بافت بر کلمات پیرامون یا بافتی که یک کلمه در آن ظاهر میشود، تمرکز دارند. این ترکیب از قوانین مبتنی بر الگو و بافت، دقت استخراج اطلاعات را در NER افزایش میدهد.
3. روش مبتنی بر یادگیری ماشین
در این دسته دو نوع اصلی وجود دارد:
- طبقهبندی چندکلاسه (Multi-Class Classification): مدل را بر روی نمونههای برچسبگذاری شده آموزش میدهد که در آن هر موجودیت دستهبندی شده است. علاوه بر برچسبگذاری، مدل به درک عمیقی از بافت متن نیز نیاز دارد که این امر آن را به وظیفهای چالشبرانگیز برای یک الگوریتم یادگیری ماشین ساده تبدیل میکند.
- میدان تصادفی شرطی (CRF): این روش توسط هر دو ابزار NLP Speech Tagger و NLTK پیادهسازی شده است. این یک مدل احتمالی است که توالی و بافت کلمات را درک میکند و به دقیقتر شدن پیشبینی موجودیتها کمک میکند.
4. روش مبتنی بر یادگیری عمیق
- جایگذاری کلمات (Word Embeddings): معنای کلمات را در بافت متن استخراج میکند.
- یادگیری خودکار: مدلهای عمیق الگوهای پیچیده را بدون مهندسی ویژگی به صورت دستی یاد میگیرند.
- دقت بالاتر: بر روی مجموعهدادههای بزرگ و متنوع عملکرد خوبی دارد.
پیادهسازی NER در پردازش زبان طبیعی با پایتون
مرحله ۱: نصب کتابخانهها
ابتدا باید کتابخانههای لازم را نصب کنیم. میتوانید دستورات زیر را برای نصب آنها در خط فرمان (command prompt) اجرا کنید.
!pip install spacy !pip install nltk !python -m spacy download en_core_web_sm
مرحله ۲: وارد کردن و بارگذاری دادهها
ما از کتابخانههای Pandas و Spacy برای پیادهسازی این مورد استفاده خواهیم کرد.
import pandas as pd
import spacy
import requests
from bs4 import BeautifulSoup
nlp = spacy.load("en_core_web_sm")
pd.set_option("display.max_rows", 200)
مرحله ۳: اعمال NER بر روی یک متن نمونه
ما محتوایی تصادفی برای پیادهسازی این بخش ایجاد کردهایم؛ شما میتوانید از هر متنی به دلخواه خود استفاده کنید.
- doc = nlp(content): متن ذخیرهشده در content را با استفاده از مدل nlp پردازش کرده و شیء سند حاصل را برای تحلیلهای بعدی در متغیر doc ذخیره میکند.
- for ent in doc.ents: در میان موجودیتهای نامدار (doc.ents) شناساییشده در سند پردازششده پیمایش کرده و عملیات لازم را برای هر موجودیت انجام میدهد.
content = "Trinamool Congress leader Mahua Moitra has moved the Supreme Court against her expulsion from the Lok Sabha over the cash-for-query allegations against her. Moitra was ousted from the Parliament last week after the Ethics Committee of the Lok Sabha found her guilty of jeopardising national security by sharing her parliamentary portal's login credentials with businessman Darshan Hiranandani."
doc = nlp(content)
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
خروجی:
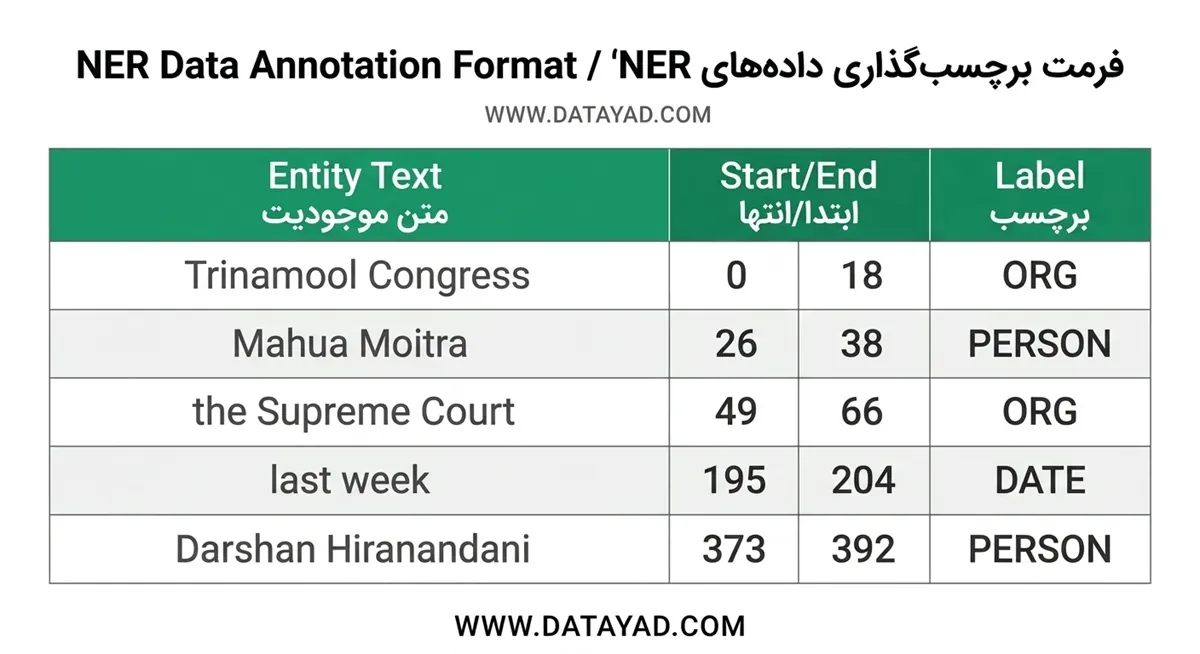
این بخش نام موجودیتها، موقعیت شروع و پایان آنها در متن و برچسبهای پیشبینیشده آنها را نمایش میدهد.
مرحله ۴: بصریسازی موجودیتها
ما برای درک بهتر، متن را با استفاده از تکنیک بصریسازی بر اساس دستهبندیهایشان هایلایت خواهیم کرد.
- displacy.render(doc, style=”ent”): موجودیتهای نامدار را در شیء doc پردازششده با هایلایت کردن آنها در متن همراه با دستهبندیهای مربوطه مانند شخص، سازمان، مکان و غیره بصریسازی میکند.
from spacy import displacy displacy.render(doc, style="ent")
خروجی:

مرحله ۵: ایجاد یک DataFrame برای موجودیتها
- فهرستی از تاپلها ایجاد میکند که هر تاپل شامل متن، برچسب (نوع) و لم (شکل پایه) هر موجودیت نامدار یافتشده در شیء doc پردازششده است.
entities = [(ent.text, ent.label_, ent.lemma_) for ent in doc.ents] df = pd.DataFrame(entities, columns=['text', 'type', 'lemma']) print(df)
خروجی:
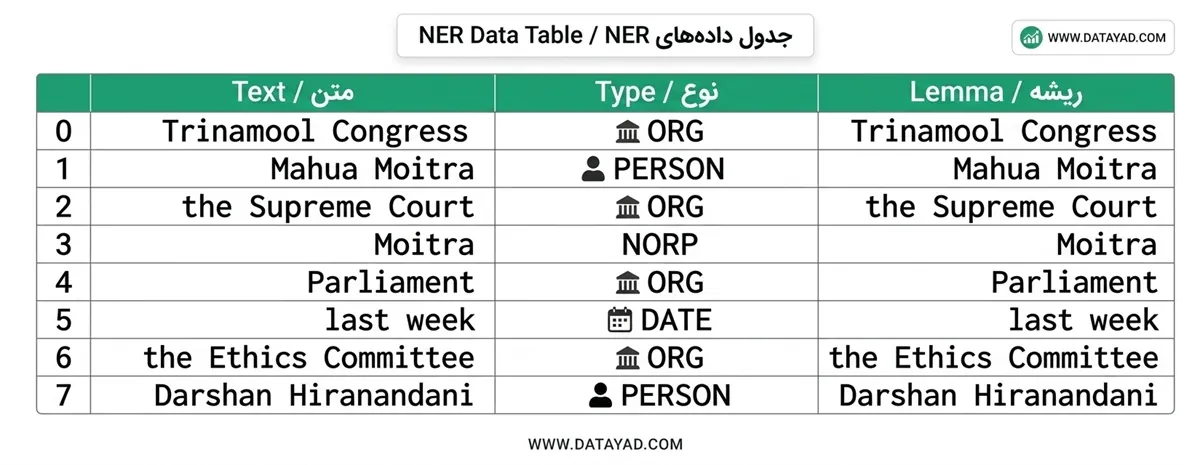
در اینجا دیتافریم یک نمایش ساختاریافته از موجودیتهای نامدار، انواع آنها و اشکال لماتایز شده ارائه میدهد. NER به سازماندهی متنهای بدون ساختار و تبدیل آنها به اطلاعات ساختاریافته کمک میکند و آن را برای طیف گستردهای از کاربردهای NLP مفید میسازد.
برای یادگیری کامل NER چه مهارتهایی لازم است؟
NER در پردازش زبان طبیعی تنها یکی از بخشهای مهم در این حوزه است. برای پیادهسازی حرفهای سیستمهای NER باید با مفاهیمی مانند پردازش زبان طبیعی، یادگیری ماشین، یادگیری عمیق، مدلهای زبانی بزرگ (LLM) و کتابخانههایی مانند SpaCy، Transformers و PyTorch آشنا باشید.
اگر میخواهید به صورت عملی یاد بگیرید چگونه مدلهای استخراج اطلاعات، سیستمهای تحلیل متن و مدلهای زبانی پیشرفته را توسعه دهید، پیشنهاد میکنیم مسیر یادگیری آموزش NLP و LLM را دنبال کنید. در این مسیر با مفاهیم کلیدی پردازش زبان طبیعی، مدلهای ترنسفورمر، استخراج موجودیتها و ساخت پروژههای واقعی هوش مصنوعی آشنا میشوید.

سوالات متداول درباره بازشناسی موجودیتهای نامدار (NER)
بازشناسی موجودیتهای نامدار (NER) چیست؟
NER یکی از وظایف مهم در پردازش زبان طبیعی (NLP) است که در آن مدلهای هوش مصنوعی موجودیتهای مهم مانند نام افراد، مکانها، سازمانها، تاریخها و مقادیر عددی را از متن استخراج و دستهبندی میکنند.
کاربردهای NER در پردازش زبان طبیعی چیست؟
از NER در کاربردهایی مانند تحلیل اخبار، استخراج اطلاعات از متن، سیستمهای پاسخ به سوال، چتباتها، ساخت گراف دانش، تحلیل شبکههای اجتماعی و موتورهای جستجو استفاده میشود.
بهترین ابزارها برای پیادهسازی NER چیست؟
کتابخانههایی مانند SpaCy، NLTK، Hugging Face Transformers و Stanford NLP از محبوبترین ابزارها برای پیادهسازی سیستمهای بازشناسی موجودیتهای نامدار هستند.
آیا مدلهای LLM میتوانند NER انجام دهند؟
بله، مدلهای زبانی بزرگ (LLM) مانند GPT و BERT میتوانند با دقت بالا موجودیتهای نامدار را در متن تشخیص دهند و حتی در وظایف پیچیده استخراج اطلاعات نیز استفاده شوند.




















