

توکنایز کردن (Tokenization) دروازه ورود متون انسانی به دنیای محاسباتی ماشینها در پردازش زبان طبیعی (NLP) است. از آنجا که ماشینها زبان انسان را به شکل طبیعی درک نمیکنند، این فرآیند با تبدیل رشتههای متنی به واحدهای کوچکتر و قابل مدیریتی به نام «توکن» (در سطح کاراکتر یا کلمه)، به الگوریتمها کمک میکند تا ساختار و معنای نهفته در زبان را تحلیل کنند. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیق مکانیزم توکنایزیشن، انواع آن، چالشهای پیشرو و ابزارهای پیادهسازی مدرن میپردازیم.
توکنایز کردن چیست؟
فرض کنید میخواهید به یک کودک خواندن را یاد بدهید. بهجای اینکه مستقیماً سراغ پاراگرافهای پیچیده بروید، ابتدا حروف را معرفی میکنید، سپس هجاها و در نهایت کلمات کامل را آموزش میدهید. در پردازش زبان طبیعی نیز رویکردی مشابه وجود دارد. توکنایز کردن متنهای طولانی را به واحدهای کوچکتر و قابلفهمتری برای ماشینها تبدیل میکند.
هدف اصلی توکنایز کردن این است که متن به شکلی نمایش داده شود که برای هوش مصنوعی معنادار و قابل پردازش باشد، بدون اینکه زمینه (Context) آن از بین برود. وقتی متن به مجموعهای از توکنها تبدیل میشود، الگوریتمها میتوانند الگوهای موجود در زبان را راحتتر تشخیص دهند. این تشخیص الگو بسیار مهم است، زیرا به ماشینها امکان میدهد ورودی انسانی را درک کرده و به آن پاسخ دهند.
برای مثال، وقتی یک ماشین با کلمه “running” مواجه میشود، آن را فقط یک رشته کاراکتری در نظر نمیگیرد، بلکه آن را بهعنوان مجموعهای از توکنها تحلیل میکند تا بتواند معنای آن را استخراج کند.
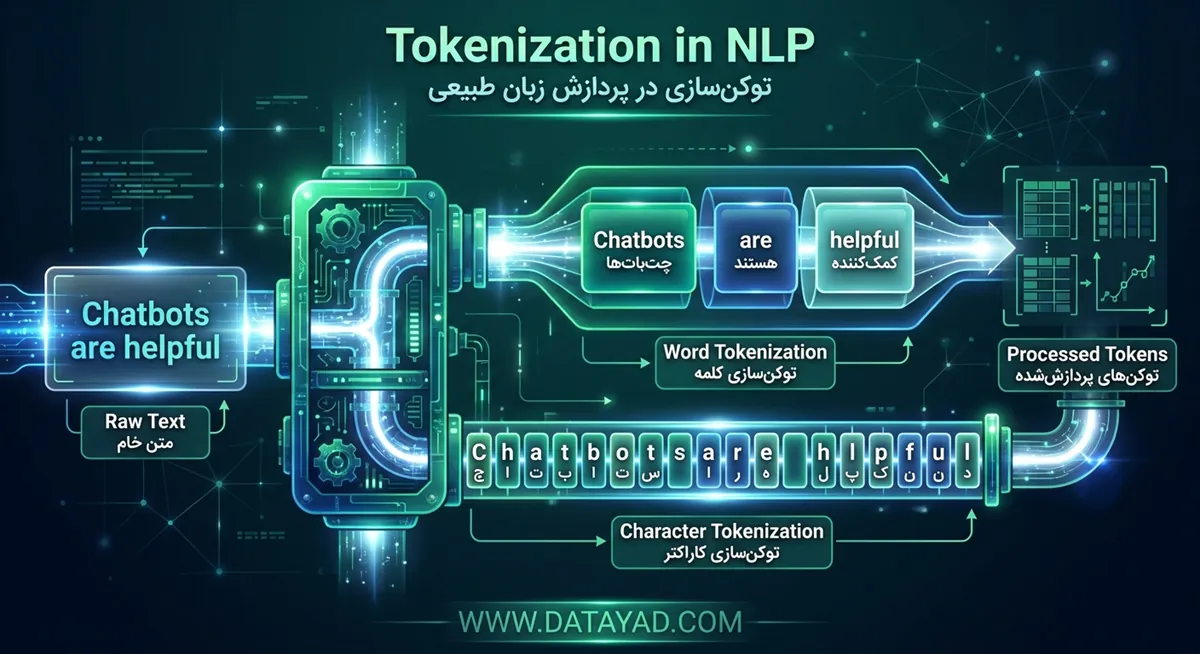
برای درک بهتر نحوه کار، جمله زیر را در نظر بگیرید:
“Chatbots are helpful.”
اگر این جمله را در سطح کلمات (Word Tokenization) توکنایز کنیم، خروجی به صورت زیر خواهد بود:
[“Chatbots”, “are”, “helpful”].
در این روش ساده، فاصلهها معمولاً مرز بین توکنها را مشخص میکنند.
اما اگر همین جمله را در سطح کاراکتر (Character Tokenization) توکنایز کنیم، جمله به شکل زیر شکسته میشود:
[“C”, “h”, “a”, “t”, “b”, “o”, “t”, “s”, ” “, “a”, “r”, “e”, ” “, “h”, “e”, “l”, “p”, “f”, “u”, “l”].
این نوع تجزیه در سطح کاراکتر بسیار ریزتر (Granular) است و برای برخی زبانها یا وظایف خاص در NLP میتواند بسیار مفید باشد.
در اصل، توکنیزه کردن شبیه کالبدشکافی یک جمله برای درک ساختار آن است. همانطور که پزشکان برای فهم یک اندام، سلولهای آن را بررسی میکنند، متخصصان NLP نیز با استفاده از توکنایزیشن ساختار و معنای متن را تحلیل میکنند.
نکته مهم این است که اگرچه در این مقاله درباره توکنایز کردن در پردازش زبان طبیعی صحبت میکنیم، اما این اصطلاح در حوزههای دیگری مانند امنیت داده و حفظ حریم خصوصی نیز استفاده میشود. برای مثال در tokenization کارتهای اعتباری، دادههای حساس با مقادیر غیرحساس (توکنها) جایگزین میشوند. بنابراین باید این دو کاربرد متفاوت با یکدیگر اشتباه گرفته نشوند.
انواع توکنیزه کردن
روشهای مختلفی برای توکنایزیشن وجود دارد که بر اساس میزان ریز بودن تجزیه متن (granularity) و نیازهای خاص وظیفه مورد نظر متفاوت هستند. این روشها میتوانند از شکستن متن به کلمات منفرد شروع شوند و تا تقسیم آن به کاراکترها یا حتی واحدهای کوچکتر ادامه پیدا کنند. در ادامه نگاهی دقیقتر به انواع مختلف آن میاندازیم:
- توکنایزیشن در سطح کلمه (Word Tokenization): در این روش، متن به کلمات جداگانه تقسیم میشود. این متداولترین رویکرد است و بهویژه برای زبانهایی که مرز کلمات در آنها مشخص است، مانند زبان انگلیسی، بسیار مؤثر عمل میکند.
- توکنایزیشن در سطح کاراکتر (Character Tokenization): در این روش، متن به کاراکترهای منفرد تقسیم میشود. این روش برای زبانهایی که مرز مشخصی بین کلمات ندارند مفید است، یا در وظایفی که نیاز به تحلیل بسیار دقیق و ریز دارند، مانند تصحیح املایی (Spelling Correction).
- توکنایزیشن زیرکلمهای (Subword Tokenization): این روش تعادلی میان توکنایزیشن در سطح کلمه و کاراکتر ایجاد میکند. در این حالت، متن به واحدهایی تقسیم میشود که ممکن است بزرگتر از یک کاراکتر اما کوچکتر از یک کلمه کامل باشند. برای مثال، کلمه “Chatbots” ممکن است به شکل “Chat” و “bots” توکنایز شود. این رویکرد بهویژه برای زبانهایی مفید است که معنا را از ترکیب واحدهای کوچکتر میسازند یا زمانی که در وظایف NLP با کلمات خارج از واژگان (Out-of-Vocabulary) مواجه میشویم.
در جدول زیر تفاوت این روشها توضیح داده شده است:
| نوع | توضیحات | موارد استفاده |
|---|---|---|
| توکنسازی کلمهای | متن را به کلمات جداگانه تقسیم میکند. | برای زبانهایی با مرزهای مشخص کلمات (مانند انگلیسی) مؤثر است. |
| توکنسازی کاراکتری | متن را به تکتک کاراکترها تقسیم میکند. | برای زبانهای بدون مرز مشخص کلمات یا وظایفی که نیاز به تحلیل جزئی دارند، مفید است. |
| توکنسازی زیرکلمه | متن را به واحدهایی بزرگتر از کاراکتر اما کوچکتر از کلمه تقسیم میکند. | برای زبانهایی با ساختار کلمات پیچیده یا مدیریت کلمات خارج از دایره واژگان (OOV) سودمند است. |
کاربردهای توکنایز کردن
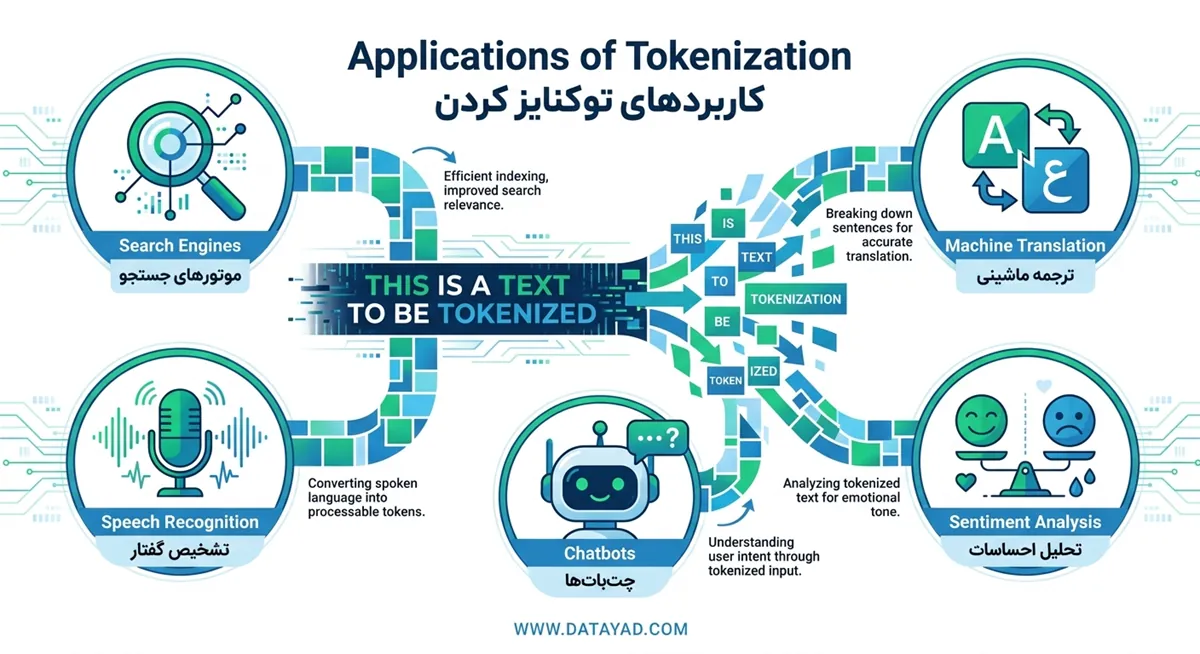
توکنایز کردن به عنوان ستون فقرات (Backbone) بسیاری از کاربردهای دیجیتال امروزی عمل میکند. این فرآیند به ماشینها اجازه میدهد تا حجم عظیمی از دادههای متنی را پردازش کرده و درک کنند. با خرد کردن متن به بخشهای کوچک و قابل مدیریت (تکههای کوچک)، توکنایز کردن تحلیل دادهها را کارآمدتر و دقیقتر میسازد. در ادامه، مهمترین کاربردهای عملی این تکنولوژی را بررسی میکنیم:
۱. موتورهای جستجو (Search Engines)
وقتی یک عبارت را در موتورهای جستجویی مانند گوگل تایپ میکنید، توکنایز کردن در پسزمینه فعال میشود تا ورودی شما را به واحدهای کوچکتری تجزیه کند. این تجزیه به موتور جستجو کمک میکند تا در میان میلیاردها سند و وبسایت جستجو کرده و دقیقترین و مرتبطترین نتایج را به شما نمایش دهد. بدون توکنایزیشن، تطبیق کوئری کاربران با دادههای ایندکس شده غیرممکن بود.
۲. ترجمه ماشینی (Machine Translation)
ابزارهایی مانند Google Translate از توکنایزیشن برای بخشبندی جملات در زبان مبدأ استفاده میکنند. پس از اینکه متن به توکنها شکسته شد، هر بخش بهصورت جداگانه ترجمه و سپس دوباره در زبان مقصد بازسازی میشود. این فرآیند باعث میشود که ترجمه نهایی، زمینه (Context) و ساختار معنایی خود را حفظ کند.
۳. تشخیص گفتار (Speech Recognition)
دستیارهای صوتی مانند سیری (Siri) یا الکسا (Alexa) به شدت به توکنایز کردن وابسته هستند. وقتی شما فرمانی را به صورت صوتی بیان میکنید، ابتدا کلمات گفتاری شما به متن تبدیل (Speech-to-Text) میشوند. سپس این متن توسط سیستم توکنایز شده تا مدل بتواند دستور شما را درک کرده و بر اساس آن اقدام کند.
۴. تحلیل احساسات در بررسیها (Sentiment Analysis)
توکنایز کردن نقش کلیدی در استخراج بینش از محتواهای تولید شده توسط کاربر (مانند نظرات محصولات یا پستهای شبکههای اجتماعی) ایفا میکند. برای مثال، یک سیستم تحلیل احساسات در پلتفرمهای تجارت الکترونیک، نظرات کاربران را توکنایز میکند تا مشخص کند آیا نظر ارسالی مثبت، منفی یا خنثی است.
به مثال زیر توجه کنید:
متن اصلی: “This product is amazing, but the delivery was late.”
پس از توکنایزیشن: [“This”, “product”, “is”, “amazing”, “,”, “but”, “the”, “delivery”, “was”, “late”, “.”]
در اینجا، توکنهای “amazing” و “late” توسط مدل تحلیل احساسات پردازش میشوند تا امتیاز احساسی (Sentiment Label) به کل متن اختصاص یابد؛ این کار به کسبوکارها کمک میکند تا بازخوردهای واقعی مشتریان را تحلیل کنند.
۵. چتباتها و دستیارهای مجازی (Chatbots and Virtual Assistants)
توکنایزیشن به چتباتهای هوش مصنوعی کمک میکند تا ورودی کاربر را به درستی درک کرده و پاسخ مناسبی ارائه دهند. به عنوان مثال، یک چتبات خدمات مشتری، کوئری کاربر را به صورت زیر توکنایز میکند:
پرسش کاربر: “I need to reset my password but can’t find the link.”
خروجی توکنایز شده: [“I”, “need”, “to”, “reset”, “my”, “password”, “but”, “can’t”, “find”, “the”, “link”].
این تفکیک کلمات به چتبات کمک میکند تا «نیت» (Intent) اصلی کاربر (در اینجا: reset password) را شناسایی کرده و پاسخ مناسب (مانند ارائه لینک بازیابی یا راهنما) را برای او ارسال کند.
چالشهای توکنیزه کردن
مدیریت پیچیدگیهای زبان انسانی، با تمام ظرافتها و ابهامهای آن، مجموعهای از چالشهای خاص را برای فرآیند توکنایزیشن ایجاد میکند. در ادامه به بررسی برخی از مهمترین این چالشها و همچنین پیشرفتهای اخیر برای حل آنها میپردازیم.
ابهام در زبان (Ambiguity)
زبان انسانی ذاتاً مبهم است. برای مثال جمله زیر را در نظر بگیرید:
“Flying planes can be dangerous.”
بسته به اینکه این جمله چگونه توکنایز و تفسیر شود، میتواند دو معنی متفاوت داشته باشد:
ممکن است منظور این باشد که خلبانی و پرواز با هواپیما خطرناک است.
یا اینکه هواپیماهایی که در حال پرواز هستند میتوانند خطرناک باشند.
چنین ابهامهایی میتوانند باعث تفسیرهای کاملاً متفاوت شوند و این موضوع یکی از چالشهای مهم در توکنایز کردن و درک زبان طبیعی است.
زبانهایی بدون مرز کلمه مشخص (Languages Without Clear Boundaries)
برخی زبانها مانند چینی، ژاپنی یا تایلندی بین کلمات فاصله مشخصی ندارند. به همین دلیل، تشخیص اینکه یک کلمه کجا تمام میشود و کلمه بعدی از کجا شروع میشود کار بسیار دشواری است.
برای حل این مشکل، پیشرفتهایی در مدلهای چندزبانه توکنایز کردن (Multilingual Tokenization Models) به وجود آمده است. برای مثال:
- XLM-R (Cross-lingual Language Model – RoBERTa): از توکنایز کردن زیرکلمهای و پیشآموزش در مقیاس بزرگ استفاده میکند تا بتواند بیش از ۱۰۰ زبان را بهخوبی پردازش کند، از جمله زبانهایی که مرز کلمه مشخصی ندارند.
- mBERT (Multilingual BERT): از روش WordPiece tokenization استفاده میکند و عملکرد قدرتمندی در زبانهای مختلف نشان داده است. این مدل حتی در زبانهایی با منابع داده محدود نیز میتواند ساختارهای نحوی و معنایی را بهخوبی درک کند.
این مدلها علاوه بر توکنایز کردن مؤثر، از واژگان زیرکلمهای مشترک بین زبانها استفاده میکنند که باعث بهبود پردازش زبانهایی میشود که معمولاً پردازش آنها دشوارتر است.
مدیریت کاراکترهای خاص (Handling Special Characters)
متنها معمولاً فقط شامل کلمات نیستند. مواردی مانند آدرس ایمیل، URLها یا نمادهای خاص نیز در متن وجود دارند و توکنایز کردن آنها میتواند چالشبرانگیز باشد.
برای مثال:
john.doe@email.com
سؤال این است که آیا این رشته باید به عنوان یک توکن واحد در نظر گرفته شود یا در نقاطی مانند . یا @ شکسته شود؟
مدلهای پیشرفته توکنایز کردن امروزی از قوانین از پیش تعریفشده و الگوهای یادگرفتهشده استفاده میکنند تا چنین مواردی را به صورت سازگار و دقیق مدیریت کنند.
پیادهسازی توکنایز کردن
در حوزه پردازش زبان طبیعی (NLP) ابزارها و کتابخانههای متعددی برای پیادهسازی توکنایزیشن وجود دارند که هرکدام برای نیازها و سطح پیچیدگیهای متفاوت طراحی شدهاند. در ادامه، برخی از مهمترین ابزارها و روشهای موجود برای انجام توکنیزه کردن معرفی میشوند.
Hugging Face Transformers
کتابخانه Hugging Face Transformers بهعنوان استاندارد صنعتی برای بسیاری از کاربردهای مدرن NLP شناخته میشود. این کتابخانه با PyTorch یکپارچگی کامل دارد و از مدلهای پیشرفته ترنسفورمر پشتیبانی میکند. همچنین از طریق API به نام AutoTokenizer فرآیند توکنایز کردن را بهصورت خودکار انجام میدهد.
ویژگیهای کلیدی این کتابخانه عبارتاند از:
- AutoTokenizer: بهصورت خودکار توکنایزر از پیش آموزشدیده مناسب برای هر مدل را بارگذاری میکند.
- توکنایزرهای سریع (Fast tokenizers): این توکنایزرها با استفاده از زبان Rust ساخته شدهاند و سرعت پردازش بسیار بالایی دارند که باعث میشود پیشپردازش دادههای بزرگ سریعتر انجام شود.
- سازگاری با مدلهای از پیش آموزشدیده: توکنایزرها بهطور دقیق با مدلهایی مانند BERT، GPT‑2، Llama و Mistral هماهنگ شدهاند.
- پشتیبانی از توکنایز کردن زیرکلمهای: این کتابخانه از روشهایی مانند Byte‑Pair Encoding (BPE)، WordPiece و Unigram پشتیبانی میکند که برای مدیریت کلمات خارج از واژگان و زبانهای پیچیده بسیار مؤثر هستند.
spaCy
کتابخانه spaCy یک کتابخانه مدرن و کارآمد در پایتون برای NLP است که بهخصوص در سیستمهای production که به سرعت و تفسیرپذیری بالا نیاز دارند بسیار محبوب است. برخلاف Hugging Face که بیشتر مبتنی بر مدلهای ترنسفورمر است، spaCy از توکنایز کردن مبتنی بر قوانین (rule‑based tokenization) استفاده میکند که برای دقت زبانی بهینه شده است.
موارد مناسب برای استفاده از spaCy:
- ساخت pipelineهای سنتی NLP مانند تشخیص موجودیت نامدار (NER) و dependency parsing
- پروژههایی که از مدلهای ترنسفورمر استفاده نمیکنند
- سیستمهایی که نیاز به توکنایز کردن بسیار سریع دارند
NLTK
کتابخانه NLTK (Natural Language Toolkit) یکی از کتابخانههای قدیمی و پایهای در پایتون برای NLP است که بیشتر در آموزش و تحقیقات استفاده میشود. با اینکه هنوز قابل استفاده است، اما نسبت به ابزارهای مدرن سرعت بسیار کمتری دارد و برای سیستمهای production توصیه نمیشود.
موارد استفاده مناسب برای NLTK:
- یادگیری مفاهیم NLP
- پروژههای آموزشی
- تحقیقات زبانشناسی
برای کاربردهای واقعی و تولیدی، معمولاً استفاده از spaCy یا Hugging Face Transformers پیشنهاد میشود.
نکته:
ابزار keras.preprocessing.text.Tokenizer از نسخه Keras 3.0 منسوخ (deprecated) شده است و نباید در پروژههای جدید استفاده شود. در پروژههای مدرن Keras باید بهجای آن از keras.layers.TextVectorization استفاده کرد. همچنین برای وظایف NLP، استفاده از Hugging Face Transformers رویکرد توصیهشده محسوب میشود.
تکنیکهای پیشرفته توکنایز کردن
برای کاربردهای خاص یا زمانی که قصد ساخت مدلهای سفارشی دارید، روشهای پیشرفتهتری وجود دارند که کنترل دقیقتری بر فرآیند توکنایز کردن فراهم میکنند:
Byte‑Pair Encoding (BPE)
یک روش تطبیقی برای توکنایز کردن است که بهصورت تکراری رایجترین جفت بایتها را در متن با هم ادغام میکند. این روش توکنایزیشن پیشفرض برای GPT‑2، GPT‑3 و بیشتر مدلهای بزرگ زبانی مدرن محسوب میشود. BPE در مدیریت کلمات ناشناخته و اسکریپتهای متنوع بسیار مؤثر است و نیاز به پیشپردازش وابسته به زبان را کاهش میدهد.
SentencePiece
یک توکنایزر بدون نظارت (unsupervised) است که برای وظایف تولید متن مبتنی بر شبکههای عصبی طراحی شده است. برخلاف BPE، این روش میتواند فاصلهها را نیز بهعنوان توکن در نظر بگیرد و با یک مدل واحد چندین زبان را مدیریت کند. به همین دلیل برای پروژههای چندزبانه و توکنایز کردن مستقل از زبان بسیار مناسب است.
هر دو روش از طریق Hugging Face Transformers یا بهعنوان کتابخانههای مستقل قابل استفاده هستند.
مدلسازی بدون توکنایز کردن
در حالی که توکنایزیشن هنوز برای اکثر سیستمهای NLP ضروری است، تحقیقات جدید در حال بررسی مدلهایی هستند که مستقیماً روی بایتها یا کاراکترها کار میکنند و نیازی به طرحهای ثابت توکنایز کردن ندارند.
برخی از پیشرفتهای اخیر در این حوزه عبارتاند از:
ByT5
ByT5 یک مدل از پیش آموزشدیده است که به جای توکنهای زیرکلمهای، مستقیماً روی بایتهای UTF‑8 کار میکند.
ویژگیهای آن:
- عملکردی قابل مقایسه با مدلهای توکنایز شده سنتی
- مقاومت بیشتر در برابر تغییرات کاراکتری مانند غلطهای تایپی یا تغییرات نوشتاری
CharacterBERT
CharacterBERT نمایشهای سطح کاراکتر را یاد میگیرد و بردارهای کلمه (Word Embeddings) را بهصورت پویا از توالی کاراکترها میسازد.
در نتیجه:
- نیازی به واژگان ثابت (Fixed Vocabulary) ندارد
- مشکل کلمات خارج از واژگان (OOV) کاهش پیدا میکند
Hierarchical Transformers
در این معماریها از استراتژیهای کدگذاری سلسلهمراتبی استفاده میشود تا مدل بتواند بایتهای خام (Raw Bytes) را با کاهش حداقلی در کارایی پردازش کند.
با این حال باید توجه داشت:
- این رویکردها هنوز در مقیاس تولیدی (Production) کاملاً آماده نیستند
- بیشتر در حوزه تحقیقات مورد استفاده قرار میگیرند
اما مزیت بالقوه آنها این است که میتوانند:
- وابستگی به پیشپردازش وابسته به زبان را کاهش دهند
- سیستمهای NLP را برای زبانها و اسکریپتهای متنوع مقاومتر کنند
با وجود این پیشرفتها، در حال حاضر توکنایز کردن سنتی همچنان استاندارد اصلی برای کارایی و کاربرد عملی در سیستمهای NLP است.
جمعبندی
توکنایزیشن یکی از بنیادیترین مراحل در تمام کاربردهای مدرن NLP است؛ از موتورهای جستجو گرفته تا مدلهای زبانی بزرگ.
انتخاب روش و ابزار مناسب برای توکنایز کردن میتواند تأثیر مستقیمی بر موارد زیر داشته باشد:
- دقت مدل (Model Accuracy)
- سرعت استنتاج (Inference Speed)
- هزینههای API
به همین دلیل درک تفاوتها و مزایای هر روش توکنایزیشن اهمیت زیادی دارد. با انتخاب استراتژی مناسب توکنایز کردن برای کاربرد خاص خود میتوانید عملکرد و کارایی سیستمهای NLP در محیطهای production را بهطور قابل توجهی بهبود دهید.
قدم بعدی برای یادگیری NLP و مدلهای زبانی
در این مقاله یاد گرفتیم که توکنایز کردن چگونه متن را برای مدلهای زبانی قابل فهم میکند و چرا این مرحله در تمام سیستمهای مدرن NLP نقش حیاتی دارد.
اما توکنایز کردن فقط یکی از مراحل ساخت سیستمهای هوش مصنوعی متنی است. برای ساخت مدلهای واقعی باید مفاهیم مهم دیگری را نیز یاد بگیرید، مانند:
- معماری Transformer
- Embeddingها
- آموزش و فاینتیون مدلهای زبانی
- کار با مدلهایی مثل GPT، BERT و Llama
- ساخت سیستمهای واقعی NLP
اگر میخواهید این مهارتها را بهصورت عملی یاد بگیرید، پیشنهاد میکنیم از آموزش LLM و NLP استفاده کنید. در این آموزشها قدمبهقدم یاد میگیرید چگونه مدلهای زبانی را در پروژههای واقعی پیادهسازی کنید.

سوالات متداول
تفاوت بین Word Tokenization و Character Tokenization چیست؟
Word Tokenization متن را به کلمات جداگانه تقسیم میکند، در حالی که Character Tokenization متن را به کاراکترهای منفرد میشکند.
چرا توکنیزه کردن در NLP مهم است؟
زیرا با شکستن متن به واحدهای کوچکتر، به ماشینها کمک میکند زبان انسانی را پردازش و درک کنند.
آیا میتوان از چند روش توکنایز کردن برای یک متن استفاده کرد؟
بله. بسته به نوع مسئله، ترکیب چند روش توکنیزه کردن میتواند نتایج بهتری ارائه دهد.
رایجترین ابزارهای توکنایزیشن در NLP کداماند؟
محبوبترین ابزارها عبارتاند از:
- Hugging Face Transformers
- spaCy
- NLTK
- SentencePiece
- Byte‑Pair Encoding
هرکدام از این ابزارها برای کاربردهای متفاوتی طراحی شدهاند؛ از سیستمهای production مبتنی بر ترنسفورمر گرفته تا تحقیقات تخصصی.
توکنایزیشن برای زبانهایی مثل چینی یا ژاپنی که فاصله ندارند چگونه انجام میشود؟
در این زبانها از روشهایی مانند:
- تقسیمبندی در سطح کاراکتر
- مدلهای آماری برای تشخیص مرز کلمات
- استفاده میشود تا محتملترین مرز بین کلمات شناسایی شود.
توکنایز کردن چگونه به موتورهای جستجو کمک میکند نتایج مرتبط ارائه دهند؟
توکنایز کردن کوئریها و اسناد را به واحدهای قابل ایندکس تقسیم میکند. این کار باعث میشود موتورهای جستجو بتوانند جستجو و تطبیق سریع و دقیق انجام دهند.




















