

شبکه عصبی GRU (Gated Recurrent Unit) نوعی شبکه عصبی بازگشتی است که برای پردازش دادههای متوالی طراحی شده و در عین حال، پیچیدگی و محدودیتهای RNNهای سنتی را به میزان قابل توجهی کاهش میدهد. در واقع، شبکه عصبی GRU نسخه سادهشده و سبکتری از شبکههای LSTM است. این معماری به جای استفاده از مکانیزمهای پیچیده، تنها از دو بخش اصلی به نامهای (Update Gate) و (Reset Gate) استفاده میکند تا وابستگیهای بلندمدت را در دادهها به شکلی کارآمد یاد بگیرد و اطلاعات غیرضروری را فیلتر کند.
در این مطلب از بخش آموزش هوش مصنوعی دیتایاد، با نحوه کارکرد شبکه عصبی GRU، وظایف گیتهای آن و اینکه چرا در بسیاری از پروژهها به عنوان جایگزینی بهینه برای LSTM انتخاب میشود، آشنا خواهیم شد.
چرا شبکه عصبی GRU انقلابی در یادگیری ماشین ایجاد کرد؟
شبکه عصبی GRU، مانند یک فیلتر هوشمند برای دادهها عمل میکند. این شبکه عصبی یاد میگیرد که کدام بخش از اطلاعات گذشته واقعاً مهم هستند و کدامها را باید دور بریزد تا بتواند آینده را با دقت بیشتری پیشبینی کند. برخلاف مدلهای قدیمی که در مواجهه با توالیهای طولانی گیج میشدند، شبکه عصبی GRU با ساختاری بهینه، حافظهای کارآمد را برای ماشینها فراهم میکند.
در دنیای امروز که هوش مصنوعی با حجم عظیمی از دادههای متوالی مثل متن، صوت و نمودارهای مالی سر و کار دارد، GRU به دلیل سرعت بالا و نیاز به منابع پردازشی کمتر، به یکی از محبوبترین ابزارها برای
متخصصان علم داده و هوش مصنوعی تبدیل شده است. در ادامه، یاد میگیریم که این مدل چگونه کار میکند و چرا جایگزین مناسبی برای مدلهای پیچیدهتر است.
شبکه عصبی GRU
شبکه عصبی GRU نوعی از RNN است که توسط Cho و همکاران در سال ۲۰۱۴ معرفی شد. آنها از مکانیسمهای گیت برای حفظ انتخابی اطلاعات مهم و حذف جزئیات نامرتبط در طول یادگیری توالی استفاده میکنند.
- نسخه سادهشدهای از معماری LSTM
- استفاده از دو گیت اصلی: (Update Gate) و (Reset Gate)
- یادگیری کارآمد وابستگیهای بلندمدت
- کاهش پیچیدگی در مقایسه با LSTMها
- کاربرد گسترده در دادههای متوالی و سریهای زمانی
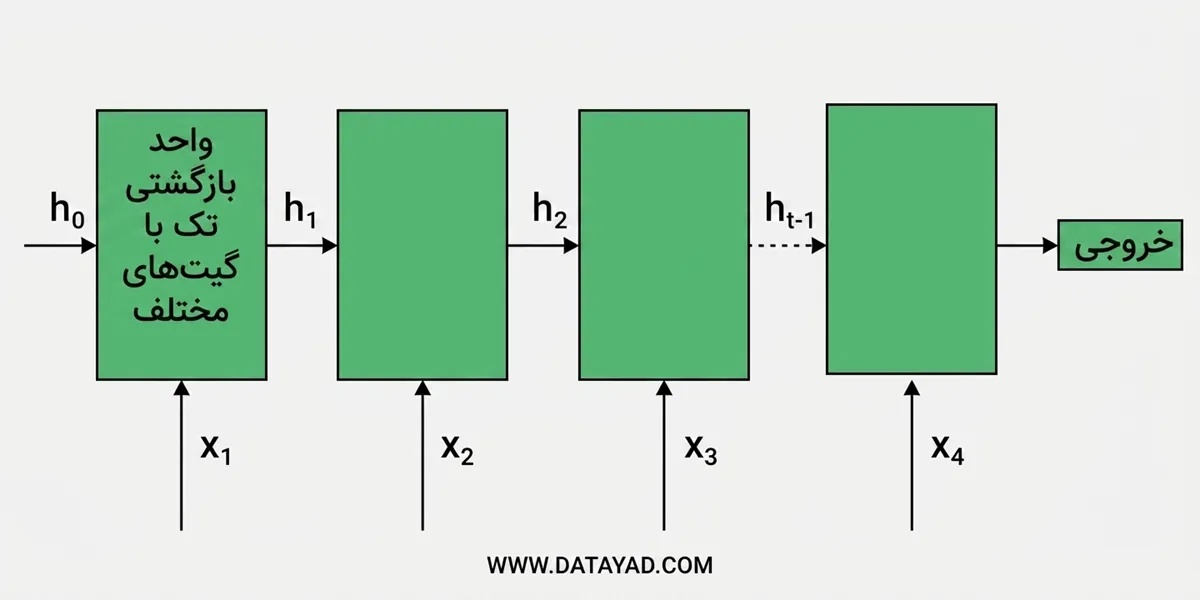
مدل GRU از دو گیت اصلی تشکیل شده است:
- گیت بهروزرسانی (zt): این گیت تصمیم میگیرد که چه مقدار از اطلاعات حالت پنهان قبلی باید برای گام زمانی بعدی حفظ شود.
- گیت بازنشانی (rt): این گیت تعیین میکند که چه مقدار از حالت پنهان گذشته باید فراموش شود.
این گیتها به GRU اجازه میدهند تا جریان اطلاعات را به شیوهای کارآمدتر در مقایسه با RNNهای سنتی که صرفاً به حالت پنهان متکی هستند، کنترل کند.
معادلات عملیاتهای GRU
عملکردهای داخلی یک GRU را میتوان با استفاده از معادلات زیر توصیف کرد:
۱. گیت بازنشانی (Reset gate)
![]()
گیت بازنشانی کنترل میکند که چه مقدار از حالت پنهان قبلی در هنگام محاسبه حالت پنهان کاندید استفاده شود.
۲. گیت بهروزرسانی (Update gate)
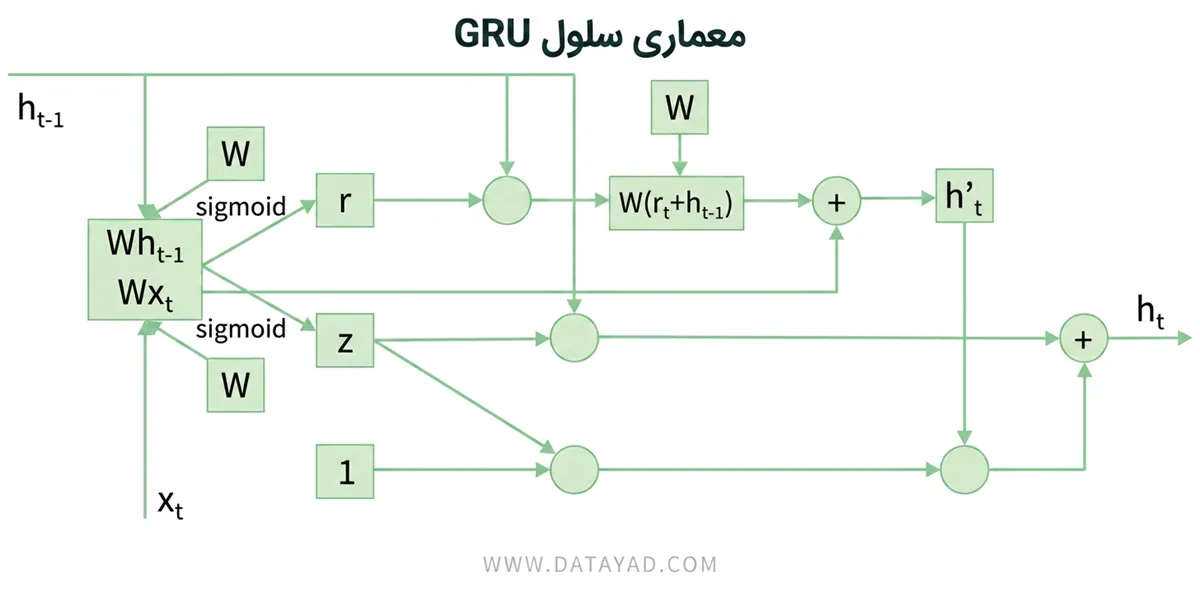
![]()
گیت بهروزرسانی تعادل بین حفظ حالت پنهان قبلی و گنجاندن حالت پنهان کاندید را کنترل میکند.
۳. حالت پنهان کاندید (Candidate hidden state)
![]()
این حالت پنهان جدیدِ بالقوه است که بر اساس ورودی فعلی و حالت پنهان قبلی محاسبه میشود.
۴. حالت پنهان (Hidden state)
![]()
حالت پنهان نهایی، یک میانگین وزنی از حالت پنهان قبلی ht-1 و حالت پنهان کاندید h′t بر اساس گیت بهروزرسانی zt است.
مدیریت مشکل محوشدگی گرادیان
همانند LSTMها، GRUها برای مقابله با مشکل محوشدگی گرادیان که معمولاً در RNNهای سنتی یافت میشود، طراحی شدهاند.
- GRUها از مکانیسمهای گیت برای تنظیم جریان اطلاعات و گرادیانها در طول آموزش استفاده میکنند.
- این گیتها به حفظ اطلاعات مهم در طول توالیهای طولانی کمک میکنند.
- آنها از کوچک شدن بیش از حد گرادیانها جلوگیری کرده و یادگیری بهتر وابستگیهای بلندمدت را ممکن میسازند.
GRU در مقابل LSTM
در این جدول به مقایسه شبکههای GRU و LSTM میپردازیم.
| ویژگی | LSTM (حافظه کوتاهمدت طولانی) | GRU |
|---|---|---|
| گیتها | ۳ (ورودی، فراموشی، خروجی) | ۲ (بهروزرسانی، بازنشانی) |
| حالت سلول | بله، دارای حالت سلول است | خیر (فقط حالت پنهان) |
| سرعت آموزش | کندتر به دلیل پیچیدگی | سریعتر به دلیل معماری سادهتر |
| بار محاسباتی | بیشتر به دلیل تعداد گیتها و پارامترهای بیشتر | کمتر به دلیل تعداد گیتها و پارامترهای کمتر |
| عملکرد | اغلب در وظایفی که به حافظه بلندمدت نیاز دارند بهتر است | در بسیاری از وظایف با پیچیدگی کمتر، عملکرد مشابهی دارد |
پیادهسازی شبکه عصبی GRU
حالا بیایید یک مدل ساده GRU را با استفاده از Keras در پایتون پیادهسازی کنیم. کار را با آمادهسازی کتابخانهها و مجموعهدادههای لازم شروع میکنیم.
۱. وارد کردن کتابخانهها
ما کتابخانههای مورد نیاز برای پیادهسازی مدل GRU خود مانند numpy، pandas، MinMaxScaler، TensorFlow و Adam را وارد خواهیم کرد.
import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense from tensorflow.keras.optimizers import Adam
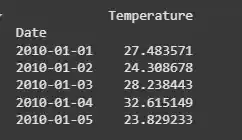
۲. بارگذاری مجموعهداده
مجموعهدادهای که از آن استفاده میکنیم، یک مجموعهداده سری زمانی شامل دادههای دمای روزانه (دیتاست پیشبینی) است. این دادهها بازهای ۸۰۰۰ روزه را از ۱ ژانویه ۲۰۱۰ پوشش میدهند.
- pd.read_csv: یک فایل CSV را در یک DataFrame پانداس میخواند. در اینجا فرض میکنیم که مجموعهداده دارای یک ستون Date است که به عنوان شاخص (index) دیتافریم تنظیم شده است.
- parse_dates=[‘Date’]: اطمینان حاصل میکند که ستون
Dateبه طور خودکار به فرمت datetime تبدیل شود.
df = pd.read_csv('data.csv', parse_dates=['Date'], index_col='Date')
print(df.head())
خروجی:
۳. پیشپردازش دادهها
دادهها با استفاده از MinMaxScaler مقیاسگذاری میشوند تا مقادیر ویژگیها بین ۰ و ۱ نرمالسازی شوند. نرمالسازی به شبکههای عصبی کمک میکند تا به شکل موثرتری آموزش ببینند و از سوگیری ناشی از ویژگیهایی با مقادیر بزرگتر جلوگیری میکند.
- از MinMaxScaler برای نرمالسازی استفاده میکند.
- ویژگیها را به بازه ۰ تا ۱ مقیاسگذاری میکند.
- عملکرد آموزش شبکه عصبی را بهبود میبخشد.
- از تسلط مقادیر بزرگتر ویژگیها جلوگیری میکند.
scaler = MinMaxScaler(feature_range=(0, 1)) scaled_data = scaler.fit_transform(df.values)
۴. آمادهسازی دادهها برای GRU
ما تابعی برای آمادهسازی دادههایمان جهت آموزش مدل تعریف خواهیم کرد.
- create_dataset: مجموعهداده را برای پیشبینی سری زمانی آماده میکند. این تابع پنجرههای لغزان (sliding windows) به طول
time_stepایجاد میکند تا گام زمانی بعدی را پیشبینی کند. - X.reshape: شکل دادههای ورودی را تغییر میدهد تا با فرم مورد انتظار برای GRU که سهبعدی است (نمونهها، گامهای زمانی و ویژگیها) مطابقت داشته باشد.
def create_dataset(data, time_step=1):
X, y = [], []
for i in range(len(data) - time_step - 1):
X.append(data[i:(i + time_step), 0])
y.append(data[i + time_step, 0])
return np.array(X), np.array(y)
time_step = 100
X, y = create_dataset(scaled_data, time_step)
X = X.reshape(X.shape[0], X.shape[1], 1)
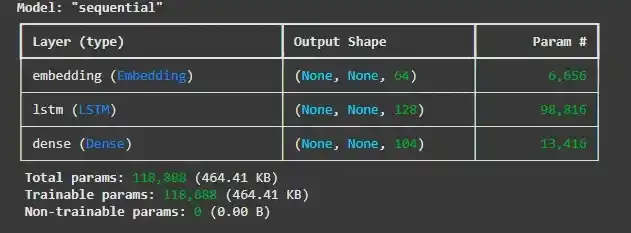
۵. ساخت مدل GRU
ما مدل GRU خود را با اجزای زیر تعریف میکنیم:
- GRU(units=50): یک لایه GRU با ۵۰ واحد (نورون) اضافه میکند.
- return_sequences=True: اطمینان حاصل میکند که لایه GRU تمام توالی را برمیگرداند (برای پشت سر هم قرار دادن چندین لایه GRU الزامی است).
- Dense(units=1): لایه خروجی که یک مقدار واحد را برای گام زمانی بعدی پیشبینی میکند.
- Adam: یک بهینهساز تطبیقی که معمولاً در یادگیری عمیق استفاده میشود.
model = Sequential() model.add(GRU(units=50, return_sequences=True, input_shape=(X.shape[1], 1))) model.add(GRU(units=50)) model.add(Dense(units=1)) model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error')
خروجی:
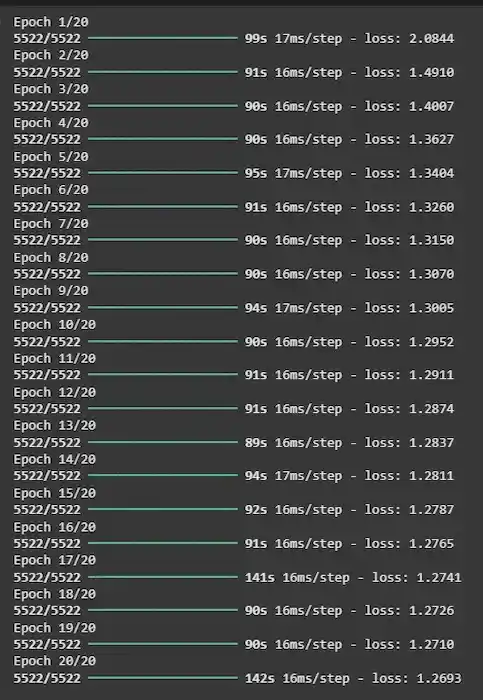
۶. آموزش مدل
تابع model.fit مدل را روی مجموعهداده آمادهشده آموزش میدهد. پارامتر epochs=10 تعداد تکرارها روی کل مجموعهداده را مشخص میکند و batch_size=32 تعداد نمونهها در هر دسته را تعیین میکند.
model.fit(X, y, epochs=10, batch_size=32)
خروجی:
۷. انجام پیشبینیها
مدل GRU آموزشدیده برای پیشبینی مقادیر آینده از توالی ورودی استفاده میشود.
- از ۱۰۰ مقدار دمای مقیاسگذاریشده آخر به عنوان ورودی استفاده میکند.
- ورودی را برای سازگاری با GRU به شکل
(1, time_step, 1)تغییر میدهد. samples = 1،time_steps = 100وfeatures = 1model.predictپیشبینیها را از مدل آموزشدیده تولید میکند.
input_sequence = scaled_data[-time_step:].reshape(1, time_step, 1) predicted_values = model.predict(input_sequence)
۸. معکوس کردن تبدیل پیشبینیها
معکوس کردن تبدیل پیشبینیها به فرآیند برگرداندن پیشبینیهای مقیاسگذاریشده (نرمالشده) به مقیاس اصلی خود اشاره دارد.
- scaler.inverse_transform: پیشبینیهای نرمالشده را به مقیاس اصلی خود بازمیگرداند.
predicted_values = scaler.inverse_transform(predicted_values)
print(
f"The predicted temperature for the next day is: {predicted_values[0][0]:.2f}°C")
خروجی:
The predicted temperature for the next day is: 24.50°C
کاربردهای شبکه عصبی GRU
شبکههای GRU بهطور گسترده برای یادگیری الگوها از دادههای ترتیبی و وابسته به زمان استفاده میشوند.
- پردازش زبان طبیعی (NLP) برای ترجمه و تولید متن
- بازشناسی گفتار و پردازش صوتی
- پیشبینی سریهای زمانی مانند پیشبینی وضعیت آبوهوا و بورس
- تحلیل احساسات و طبقهبندی متن
- وظایف تشخیص ویدیو و فعالیت
- سیستمهای توصیهگر و تحلیل رفتار کاربر
سوالات متداول در مورد GRU
تفاوت اصلی بین GRU و LSTM چیست؟
تفاوت اصلی در سادگی ساختار است. GRU دارای دو گیت (بهروزرسانی و بازنشانی) است و حالت سلول مجزا ندارد، در حالی که LSTM سه گیت دارد و از یک حالت سلول برای ذخیره اطلاعات استفاده میکند که باعث پیچیدگی بیشتر آن میشود.
آیا GRU همیشه بهتر از RNNهای معمولی عمل میکند؟
بله، در اکثر کاربردها GRU عملکرد بسیار بهتری دارد، زیرا با استفاده از مکانیسم گیتها مشکل محوشدگی گرادیان (Vanishing Gradient) را کاهش داده و میتواند وابستگیهای طولانیمدت را در دادهها حفظ کند.
کدام مدل سریعتر آموزش میبیند: GRU یا LSTM؟
بهطور کلی GRU سریعتر آموزش میبیند. به دلیل داشتن پارامترهای کمتر و معماری سادهتر، محاسبات در هر گام زمانی کاهش یافته و سرعت همگرایی مدل در طول فرآیند آموزش بیشتر است.
در چه شرایطی باید از GRU به جای LSTM استفاده کرد؟
زمانی که با مجموعهدادههای کوچکتر سر و کار دارید یا محدودیت منابع پردازشی و زمان دارید، GRU انتخاب بهتری است. همچنین در بسیاری از وظایف پردازش زبان طبیعی، GRU عملکردی مشابه یا حتی بهتر از LSTM ارائه میدهد.
آموزش جامع شبکههای عصبی و هوش مصنوعی
تسلط بر مکانیزم GRU و یادگیری نحوه مدیریت هوشمندانه دادههای متوالی، یک گام بزرگ در درک یادگیری عمیق است؛ اما برای تبدیل شدن به یک متخصص واقعی که بتواند پروژههای پیچیده را از صفر تا صد پیادهسازی کند، به چیزی فراتر از شناخت یک مدل واحد نیاز دارید. دنیای هوش مصنوعی ترکیبی از ریاضیات، برنامهنویسی پایتون، بینایی ماشین و مدلهای زبانی بزرگ است که یادگیری منسجم آنها کلید ورود شما به بازار کار حرفهای است.
ما در صفحه آموزش هوش مصنوعی، جامعترین دورههای آموزشی را برای شما فراهم کردهایم تا بدون درگیری با منابع پراکنده، تمامی دانش مورد نیاز برای تبدیل شدن به یک فوقتخصص هوش مصنوعی و علم داده را بهصورت گامبهگام و کاربردی بیاموزید.
- آموزش جامع از سطح مقدماتی (پایتون، ریاضیات، تحلیل داده) تا پیشرفته شامل یادگیری ماشین، یادگیری عمیق، پردازش تصویر، بینایی کامپیوتر و پردازش زبان طبیعی
- کسب مهارتهای تخصصی و عملی لازم برای اجرای پروژههای واقعی و موفقیت در بازار کار هوش مصنوعی و علم داده



















