

شبکه عصبی LSTM نسخه بهبودیافتهای از شبکه عصبی بازگشتی (RNN) است که برای ثبت وابستگیهای طولانیمدت در دادههای توالیمحور طراحی شده است. این شبکه از یک سلول حافظه برای ذخیره اطلاعات در طول زمان استفاده میکند و محدودیتهای RNNهای سنتی را برطرف میسازد.
- مدیریت وابستگیهای طولانیمدت: یادآوری اطلاعات برای توالیهای طولانیتر
- سلول حافظه: ذخیره و بهروزرسانی اطلاعات مهم در طول زمان
- بهتر از RNN: غلبه بر محدودیتهای حافظه کوتاهمدت
- کاربردها: مورد استفاده در ترجمه زبان، تشخیص گفتار و پیشبینی سریهای زمانی
در این مطلب از بخش آموزش هوش مصنوعی، به بررسی دقیقتر شبکه عصبی LSTM و کاربردهای آن میپردازیم.
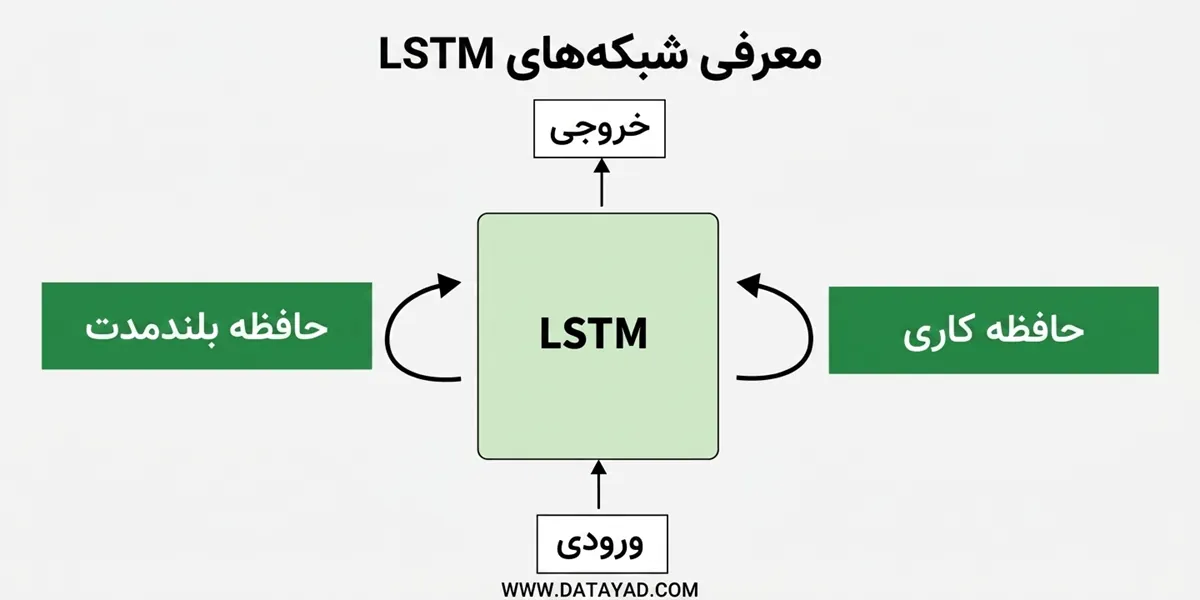
شبکه عصبی LSTM به زبان ساده
اگر شبکههای عصبی اولیه را مانند دانشآموزی در نظر بگیرید که فقط چند صفحه آخر کتاب را به یاد میآورد، LSTM شبیه پژوهشگری است که یاد گرفته نکات مهم کل کتاب را ثبت کند و مطالب کماهمیت را کنار بگذارد. این مدل بهگونهای طراحی شده که بتواند ارتباط بین اتفاقات دور و نزدیک را بهتر از RNNهای ساده درک کند و در محاسبات خود لحاظ کند.
قدرت اصلی LSTM در «مکانیزم گیتبندی» آن است؛ ساختاری که به مدل اجازه میدهد تصمیم بگیرد چه اطلاعاتی را نگه دارد، چه چیزهایی را فراموش کند و چه دادههایی را وارد حافظه بلندمدت خود کند. همین ویژگی باعث شد LSTM نسبت به معماریهای قدیمیتر جهشی مهم ایجاد کند و برای سالها در مسائلی مثل پیشبینی سریهای زمانی، هوش مصنوعی، پردازش زبان طبیعی و ترجمه ماشینی عملکرد موفقی داشته باشد.
با این حال، باید توجه داشت که LSTM بهترین و نهاییترین راهحل نیست. در سالهای اخیر، معماریهایی مانند Transformerها و مدلهای مبتنی بر توجه (Attention-based models) در بسیاری از کاربردها عملکرد بهتری از LSTM ارائه دادهاند؛ بهویژه در مقیاسهای بزرگ و دادههای حجیم. بنابراین LSTM را میتوان یک نقطه عطف مهم در مسیر تکامل شبکههای عصبی دانست، نه پیشرفتهترین گزینه موجود امروز.
مشکل وابستگیهای طولانیمدت در RNN
RNNها برای مدیریت دادههای توالیمحور با استفاده از یک حالت مخفی (hidden state) طراحی شدهاند که اطلاعات گامهای قبلی را ذخیره میکند. با این حال، آنها در یادگیری وابستگیهای طولانیمدت با چالش مواجه هستند. این اتفاق به دلایل زیر رخ میدهد:
- محو شدن گرادیان (Vanishing Gradient): هنگام آموزش مدل در طول زمان، گرادیانهایی که به یادگیری مدل کمک میکنند، میتوانند با عبور از گامهای متعدد کوچک شوند. این امر یادگیری الگوهای طولانیمدت را برای مدل دشوار میکند، زیرا اطلاعات اولیه تقریباً بیاهمیت میشوند.
- انفجار گرادیان (Exploding Gradient): گاهی اوقات گرادیانها میتوانند بیش از حد بزرگ شوند و باعث ناپایداری گردند. این موضوع یادگیری صحیح مدل را دشوار میکند، زیرا بهروزرسانیهای مدل نامنظم و غیرقابلپیشبینی میشوند.
معماری شبکه عصبی LSTM
معماری LSTM (حافظه طولانی کوتاه-مدت) برای یادگیری وابستگیهای طولانیمدت در دادههای توالیمحور با استفاده از سلولهای حافظه و گیتهایی که جریان اطلاعات را در شبکه کنترل میکنند، طراحی شده است.
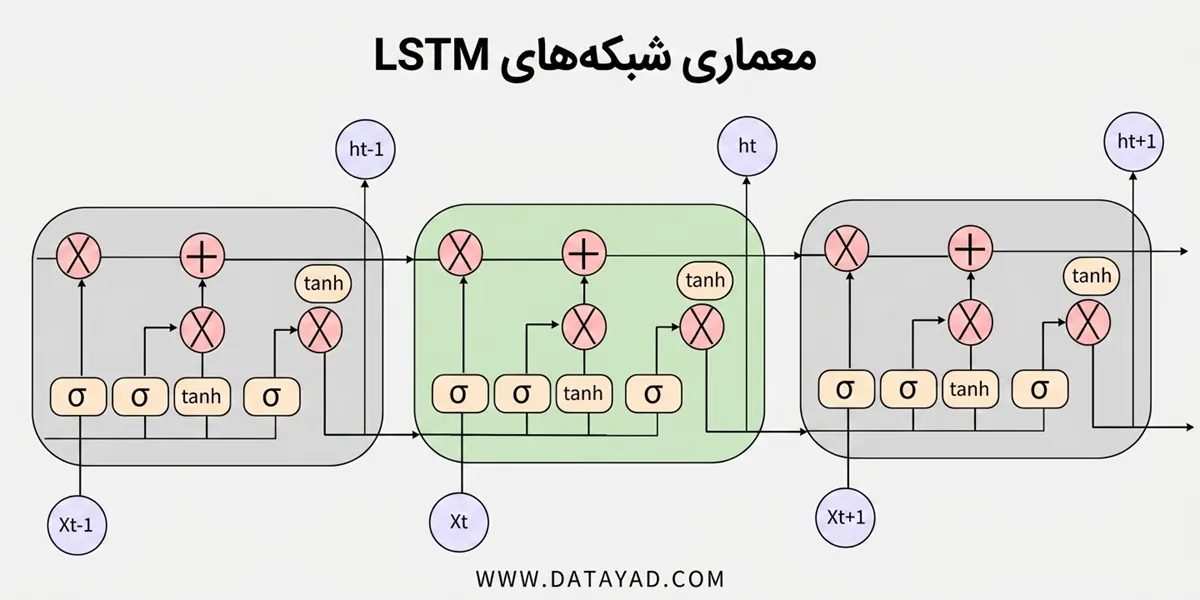
گیتهای اصلی در شبکه عصبی LSTM
- گیت ورودی (Input Gate): تصمیم میگیرد که کدام اطلاعات جدید باید به سلول حافظه اضافه شود.
- گیت فراموشی (Forget Gate): تعیین میکند که کدام اطلاعات باید از سلول حافظه حذف شود.
- گیت خروجی (Output Gate): کنترل میکند که کدام اطلاعات از سلول حافظه به حالت مخفی بعدی و خروجی منتقل شود.
نحوه عملکرد شبکه عصبی LSTM
LSTM شامل یک ساختار زنجیرهمانند تکرارپذیر با سلولهای حافظه و مکانیزمهای گیتبندی (gating mechanisms) است.
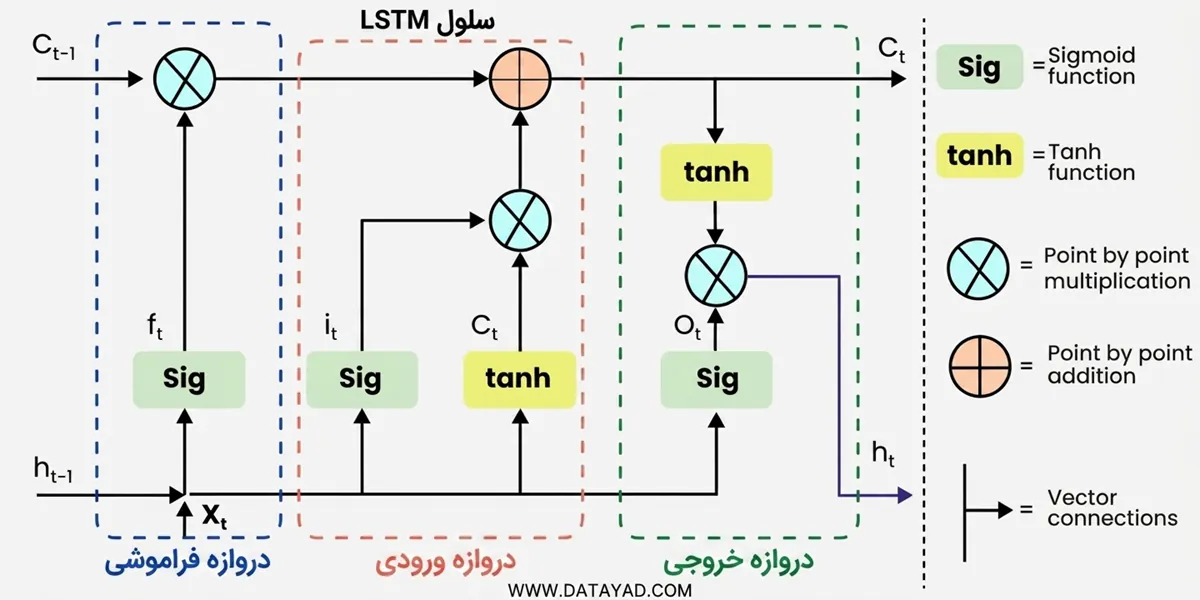
اطلاعات توسط سلولها نگهداری میشوند و دستکاریهای حافظه توسط گیتها انجام میگیرد. سه گیت وجود دارد:
۱. گیت فراموشی (Forget Gate)
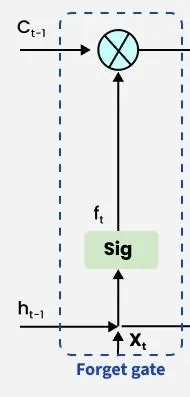
در شبکه عصبی LSTM، گیت فراموشی تصمیم میگیرد که کدام اطلاعات باید در حالت سلول (cell state) باقی بمانند یا از آن حذف شوند. این گیت از ورودی فعلی `x_t` و حالت مخفی قبلی `h_(t-1)` استفاده کرده و سپس یک تابع سیگموئید را برای تولید مقادیری بین ۰ و ۱ اعمال میکند.
- مقادیر نزدیک به ۰ اطلاعات را حذف میکنند.
- مقادیر نزدیک به ۱ اطلاعات را حفظ میکنند.
- به حذف اطلاعات غیرضروری گذشته کمک میکند.
- تجمع و نگهداری حافظه را در LSTM کنترل میکند.
معادله گیت فراموشی به شرح زیر است:
![]()
در این معادله:
- `W_f` نشاندهنده ماتریس وزن مرتبط با گیت فراموشی است.
- `[h_(t-1), x_t]` نشاندهنده الحاق (concatenation) ورودی فعلی و حالت مخفی قبلی است.
- `b_f` بایاس مربوط به گیت فراموشی است.
- `σ` تابع فعالساز سیگموئید است.
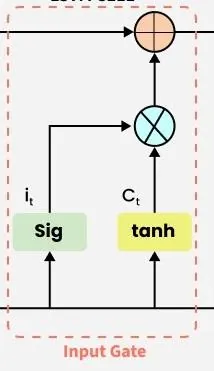
۲. گیت ورودی (Input Gate)
افزودن اطلاعات مفید به حالت سلول توسط گیت ورودی انجام میشود.
- ابتدا اطلاعات با استفاده از تابع سیگموئید تنظیم میشوند و مقادیری که باید به خاطر سپرده شوند، با استفاده از ورودیهای `h_(t-1)` و `x_t` فیلتر میشوند.
- سپس، یک بردار با استفاده از تابع tanh ایجاد میشود که خروجی آن بین ۱- تا ۱+ است و شامل تمام مقادیر احتمالی از `h_(t-1)` و `x_t` میباشد.
- در نهایت، مقادیر این بردار و مقادیر تنظیمشده در هم ضرب میشوند تا اطلاعات مفید به دست آید.
معادله گیت ورودی به شرح زیر است:
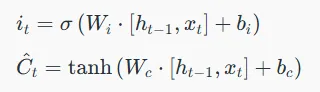
ما حالت قبلی را در `f_t` ضرب میکنیم که بهطور موثری اطلاعاتی را که قبلاً تصمیم به نادیده گرفتنشان گرفته بودیم، فیلتر میکند. سپس `i_t ⊙ C_t` را به آن اضافه میکنیم که نشاندهنده مقادیر کاندید جدید است که بر اساس میزان تصمیم ما برای بهروزرسانی هر مقدار حالت، مقیاسگذاری شدهاند.
![]()
در اینجا:
- `⊙` نشاندهنده ضرب عنصربهعنصر است.
- `tanh` تابع فعالساز است.
۳. گیت خروجی (Output Gate)
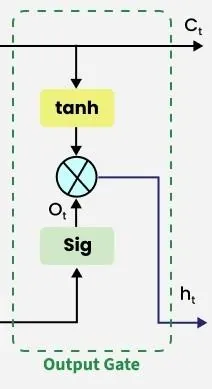
در شبکه عصبی LSTM، گیت خروجی تعیین میکند که کدام اطلاعات از حالت سلول فعلی باید به عنوان حالت مخفی (خروجی) در گام زمانی فعلی منتقل شوند. این گیت از حالت مخفی قبلی `h_(t-1)` و ورودی فعلی `x_t` استفاده کرده و در ادامه یک تابع سیگموئید را برای کنترل جریان خروجی اعمال میکند.
![]()
سپس، حالت سلول فعلی `C_t` از یک تابع فعالساز `tanh` عبور داده میشود تا مقادیر آن بین ۱- تا ۱+ مقیاسگذاری شود. در نهایت، این حالت سلول تغییریافته بهصورت عنصربهعنصر در `o_t` ضرب میشود تا حالت مخفی `h_t` تولید شود:
![]()
در اینجا:
- `o_t` خروجی فعالساز گیت خروجی است.
- `C_t` حالت سلول فعلی است.
- `⊙` نشاندهنده ضرب عنصربهعنصر است.
- `σ` تابع فعالساز سیگموئید است.
این حالت مخفی `h_t` سپس به گام زمانی بعدی منتقل میشود و همچنین میتواند برای تولید خروجی شبکه مورد استفاده قرار گیرد.
کاربردهای شبکه عصبی LSTM
- مدلسازی زبان برای ترجمه ماشینی و خلاصهسازی متن
- تشخیص گفتار برای تبدیل صوت به متن
- پیشبینی سریهای زمانی برای قیمت سهام، آبوهوا و مصرف انرژی
- تشخیص ناهنجاری برای شناسایی کلاهبرداری و نفوذ
- سیستمهای توصیهگر برای پیشنهادهای شخصیسازیشده
- تحلیل ویدیو برای تشخیص فعالیت و درک حرکت
سوالات متداول
۱. تفاوت اصلی بین شبکه عصبی RNN و شبکه عصبی LSTM چیست؟
شبکههای RNN معمولی حافظه کوتاهمدتی دارند و در توالیهای طولانی دچار مشکل محو شدن گرادیان میشوند، اما شبکه عصبی LSTM با استفاده از سلولهای حافظه و مکانیزم گیتبندی، میتواند اطلاعات را برای مدت طولانیتری حفظ کند.
۲. گیت فراموشی در LSTM چه نقشی دارد؟
این گیت وظیفه دارد تصمیم بگیرد چه اطلاعاتی از حالت قبلی سلول دیگر مفید نیستند و باید حذف شوند تا فضای کافی برای اطلاعات جدید و مهمتر فراهم شود.
۳. چرا در ساختار شبکه عصبی LSTM از تابع فعالساز Sigmoid استفاده میشود؟
تابع سیگموئید خروجی را بین ۰ و ۱ محدود میکند؛ به همین دلیل برای گیتها ایدهآل است تا مشخص کنند چه درصدی از اطلاعات (از صفر تا ۱۰۰ درصد) باید از گیت عبور کند.
۴. آیا شبکه عصبی LSTM هنوز هم در پروژههای هوش مصنوعی کاربرد دارد؟
بله، با وجود ظهور مدلهای ترنسفورمر، LSTM همچنان در تحلیل سریهای زمانی، پیشبینیهای مالی و برخی کاربردهای پردازش گفتار که دادهها ماهیت توالیمحور دارند، بسیار پرکاربرد و موثر است.
شبکه عصبی LSTM فقط یک بخش از مسیر یادگیری شبکههای عصبی است
شبکه عصبی LSTM یکی از مهمترین معماریهای یادگیری عمیق برای پردازش دادههای توالیمحور است، اما باید توجه داشت که LSTM تنها یک مدل در میان دهها معماری مختلف شبکههای عصبی محسوب میشود.
برای درک عمیق این مدل، لازم است ابتدا با شبکههای پایه مانند Perceptron، شبکههای عصبی کلاسیک، CNN و RNN آشنا شوید و سپس معماریهای پیشرفتهتری مانند Transformer و مدلهای مبتنی بر Attention را نیز یاد بگیرید. در واقع یادگیری هوش مصنوعی بدون درک سیر تکامل و مسیر تاریخی شبکههای عصبی ناقص خواهد بود.
اگر میخواهید بدانید هرکدام از این معماریها چگونه به وجود آمدهاند، چه مشکلی را حل کردهاند و در چه پروژههایی استفاده میشوند، باید این مسیر را بهصورت مرحلهبهمرحله یاد بگیرید.
در آموزش علم داده و آموزش جامع هوش مصنوعی تمام این مفاهیم از پایه تا پیشرفته بهصورت ساختاریافته آموزش داده شدهاند؛ از مبانی یادگیری ماشین و شبکههای عصبی اولیه گرفته تا معماریهایی مثل CNN، RNN، LSTM، Transformer و مدلهای مدرن هوش مصنوعی.
اگر میخواهید یاد بگیرید که این مدلها چگونه کار میکنند و در پروژههای واقعی از آنها استفاده کنید، پیشنهاد میکنیم مسیر کامل آموزش جامع هوش مصنوعی را دنبال کنید.




















